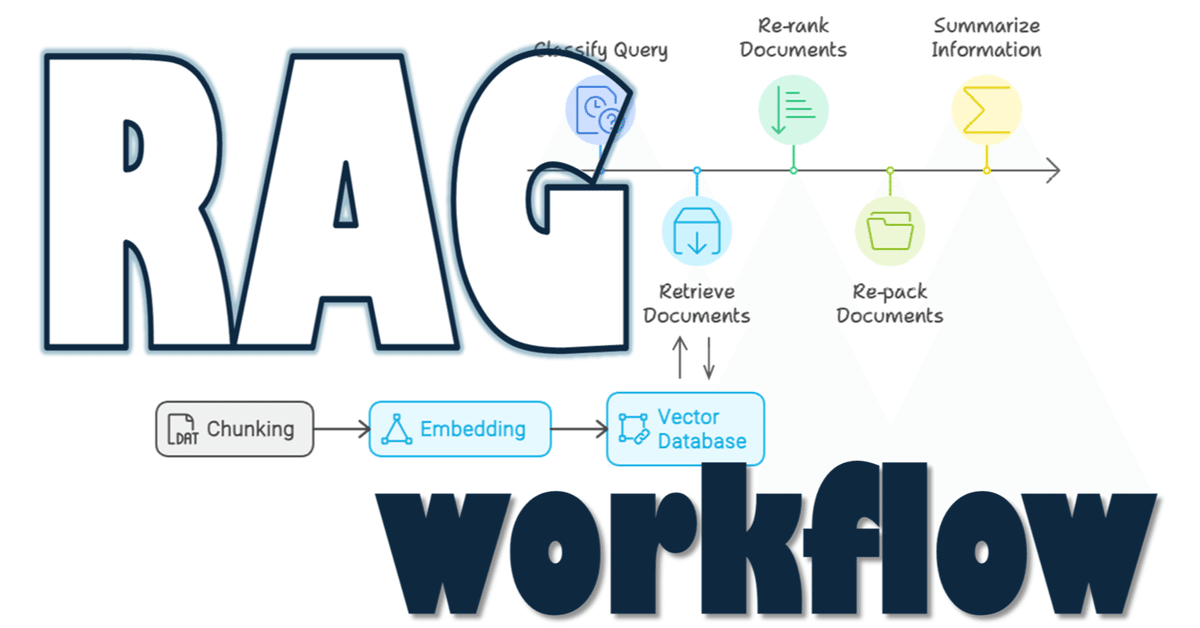
一般的なRAGのworkflow, RAG series 5/n

RAGシリーズ5回目。
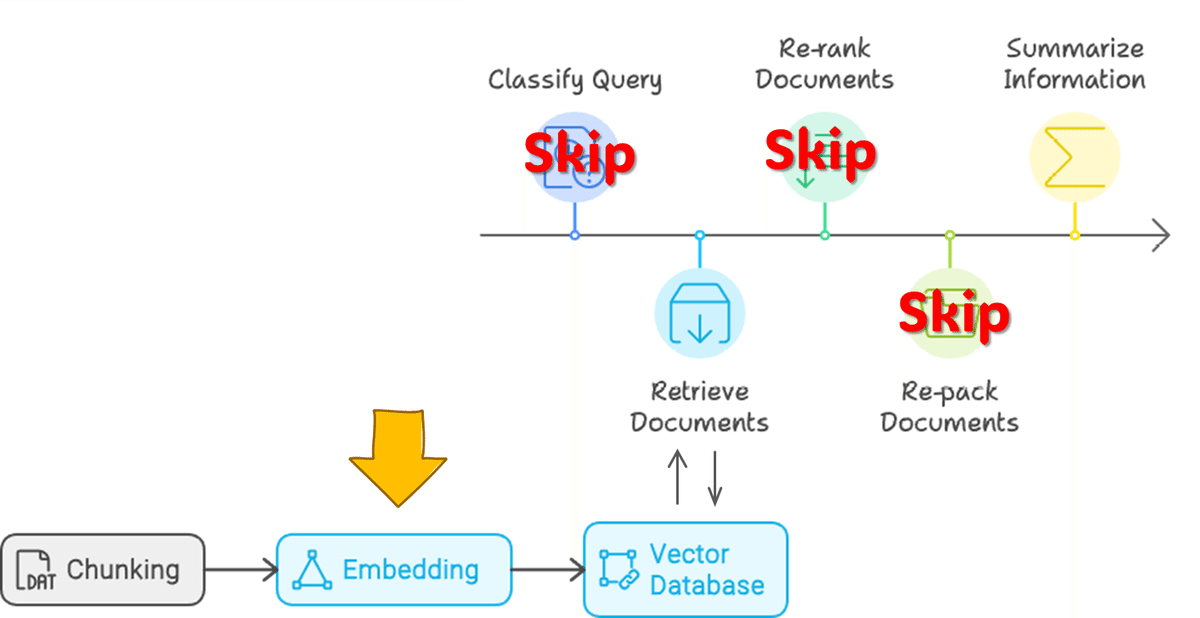
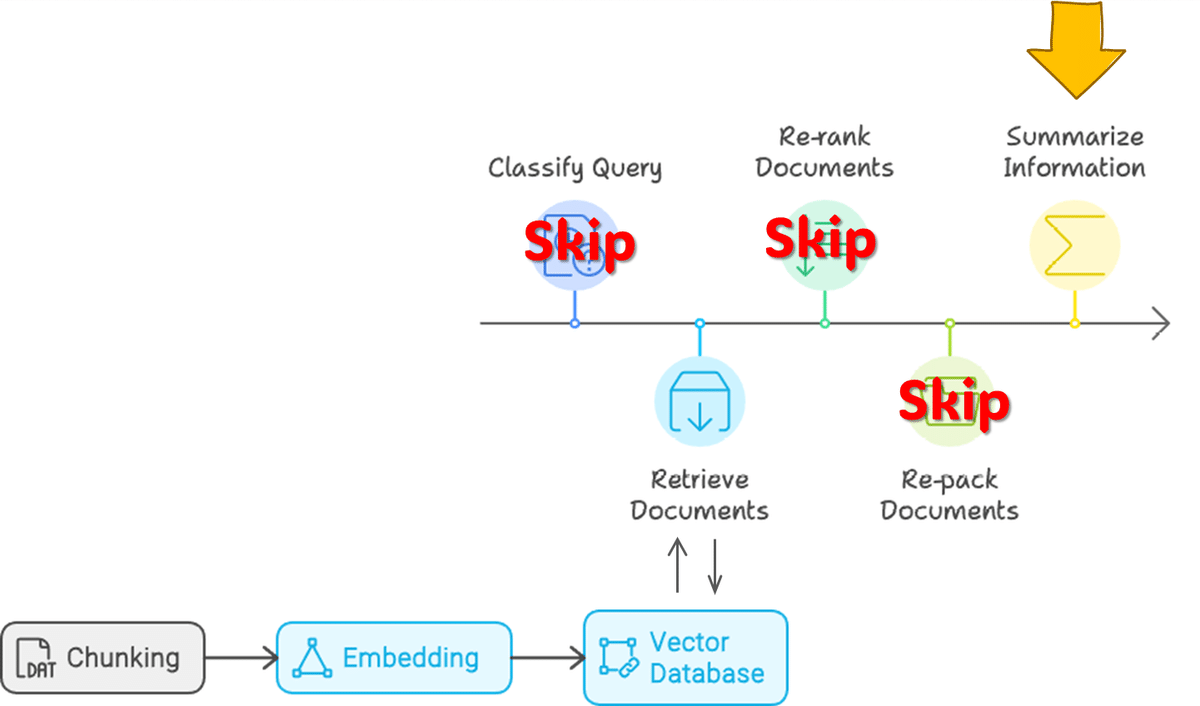
本稿にはあまり関係ないのですが、下の図がわかりやすくて良いなと感じたので、下図に則ってメモを残していこうと思いました。
RAGのフローを5つのStepに分割しています。
① Query Classification:RAGの要否判断
② Retrieval:情報源の取得
③ Reranking:取得情報の順序最適化
④ Repacking:構造化
⑤ Summarization:要約
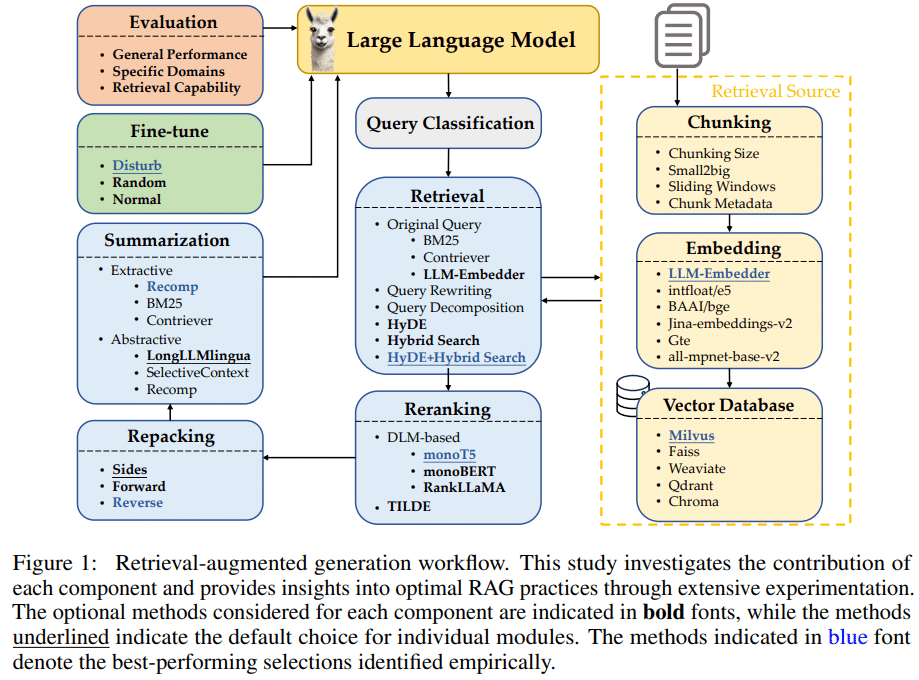
この記事で紹介した、TOYOTAの出願特許の中で近年出願件数が増加している"Smart”や"Auto", "Management"などがkeywordとなるSystem関連topic群の特許をもとにフローを整理してみます。

概要
上記フローの②、⑤のみのフローで進めます。
実施内容
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090 (24GB)
1. Retrieval Source
1-0. Data読込
# 特許Data読み込み(過去作成Dataframeを使用)
import pandas as pd
test_df = pd.read_pickle(f"{path}/test_df.pkl") #準備したデータ
# langchainのDataFrameLoaderでload
from langchain_community.document_loaders import DataFrameLoader
loader = DataFrameLoader(test_df, page_content_column="description") #明細文を使用
documents = loader.load()
1-1. Chunking
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
separators=[
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # Zero-width space
"\uff0c", # Fullwidth comma
"\u3001", # Ideographic comma
"\uff0e", # Fullwidth full stop
"\u3002", # Ideographic full stop
"",
],
chunk_size=500,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.split_documents(documents)1-2. Embedding
modelは性能そこそこ、sizeもコンパクトなBAAI/llm-embedderを使用
import langchain.embeddings
embedding = langchain.embeddings.HuggingFaceEmbeddings(
model_name="BAAI/llm-embedder"
)1-3. Vector DataBase
冒頭で紹介した論文によればMilvusがよいのだそうです。使いなれたchromaを使用。

from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embedding
)「電子制御ユニット(ECU)のOTA(Over-the-Air)ソフトウェアに関連する技術は何のために開発されたのか?」でhitするtextを確認します。
query = "What is the technology associated with electronic control unit (ECU) over-the-air (OTA) software developed for?"
docs_ = vectorstore.similarity_search(query=query, k=3)
for index, doc in enumerate(docs_):
print("%d:" % (index + 1))
print(doc.page_content)1: memory (RAM), and a non-volatile storage unit such as a flash read-only memory (ROM). The processor executes software stored in the non-volatile storage unit to realize the control function of the ECU. The software stored in each ECU is rewritable, and by updating the software to a newer version, it is possible to improve the function of each ECU or add a new vehicle control function. An example for a technology for updating the software of the ECU is an over-the-air (OTA) technology, in which 2: provided in a center in a manner such that OTA software is installed. On the other hand, the software update device mounted on the vehicle uses client software corresponding to the OTA software executed by the server to request the server to confirm update data and download the update data. The OTA software used on the server may be changed during a period in which the vehicle is used. When the OTA software used on the server is changed and vendors that provide the OTA software differ between 3: data which is transmitted and received between a plurality of networks can cause electronic control units (ECUs) connected to the networks to sleeping when the ECUs are in a sleeping-enabled state is known (for example, see Japanese Unexamined Patent Application Publication No. 2009-296280 (JP 2009-296280 A)). OSEK/VDX (Offene Systeme and deren schnittstellen fur die Elektronik im Kraftfahrzeug/Vehicle Distributed eXecutive) is known as a specification for controlling an onboard ECU. In this
2. LLM
modelの設定
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
import langchain.llms
model_id = "HODACHI/Llama-3.1-8B-EZO-1.1-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=500
)
llm = langchain.llms.HuggingFacePipeline(
pipeline=pipe
)3. Retrieval
3-1. retriever : MMR(Maximal Marginal Relevance)
単純なretrieverを用いた場合の応答を確認します。
import langchain.chains
retriever=vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": 5})
qa = langchain.chains.RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type='stuff',
)
answer = qa.invoke(query)回答:ECUのOTA(Over-the-Air)ソフトウェアに関連する技術は、車両のECUのソフトウェアを更新するために開発されたもので、車両に物理的にアクセスすることなく、リモートでECUの機能を改善したり、新しい車両制御機能を追加したりすることができます。これによりベンダーは、異なるネットワークに接続されたECUの機能を中断することなく、更新されたOTAソフトウェアを提供することができます。
3-2. +BM25 ensemble retriever
技術文書はkeywordの重要性が一般文書に比べて高いことが多く、keyword検索に強いBM25とのensemble, hybridで使用します。
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 5
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, retriever],
weights=[0.4, 0.6])
qa = langchain.chains.RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=ensemble_retriever)
answer = qa.invoke(query)回答:ECU OTAソフトウェア開発に関連する技術は、非侵襲的な方法でソフトウェアを更新することにより、ECUの機能を向上させたり、新たな車両制御機能を追加したりすることを主な目的としています。これは、中央サーバーから車両のECUへのソフトウェア更新のダウンロードを可能にするOTA技術の使用によって達成される。主な目的は、物理的な介入やECUの交換を必要とせずに、車両の制御能力を強化することである。 この技術は、サーバー上で使用されるOTAソフトウェアが時とともに変化する状況に対応するように設計されており、異なるベンダーのプラットフォーム間で互換性を確保し、アップデートを成功させる。 そのため、この技術は自動車ECUの効率的かつ柔軟なソフトウェア更新を目的として開発された。 OTAと説明されている以上、この技術の具体的な名称はわからない。 しかし、サーバーが使用するOTAソフトウェアの変更やベンダーの違いに関係なく、ソフトウェアのアップデートを車両のECUにシームレスに統合できるようなシステムを指している。 この技術の名称や具体的な機能などの詳細な実装は、与えられた文脈では提供されていない。 注目すべきは、その機能性と、自動車ソフトウェア更新の文脈で解決する問題である。 OTAソフトウェアの変更に適応し、ベンダー間の互換性を確保するシステムの能力は、その開発の重要な側面である。 これは、車両の運転を中断したり、物理的な介入を必要としたりすることなく、ECUを最新のソフトウェアに更新するという課題に対する解決策を示すものである。 そのため、この技術の具体的な名称は明らかにされていないが、その目的と機能は明確に説明されている。 この技術は、ECUのソフトウェア更新をスムーズに行い、車両の制御システムが最新かつ効率的な状態を維持できるように設計されている。 これは現代の自動車技術にとって極めて重要な側面であり、メーカーは定期的なソフトウェア更新を通じて、車両の性能、安全性、そして全体的なユーザー・エクスペリエンスを向上させることができる。 この技術の開発は、自動車分野における柔軟で適応性のあるソフトウェア管理の必要性を反映している。 この記述は、自動車の機能と性能を維持する上でOTAソフトウェア更新が重要であることを強調している。 これは、ソフトウェアがますます重要な役割を果たすようになった自動車技術における継続的な技術革新の証である。 そのため、技術の正確な名称は示されていないが、自動車産業におけるその目的と意義は明確に説明されている。 変化するOTAソフトウェアに対応し、ベンダーの互換性を確保するシステムの能力は、自動車ソフトウェア管理における重要な進歩である。 これは、より効率的で信頼性の高い車両制御システムへの一歩を意味する。
3-3. Query Rewriting, Decomposition
複雑な質問を 1 回の検索で正しく回答するのは困難であることが多いため、複数の質問に分割し、それぞれにcontextを探してそれらを統合し、微妙な違いのある出力を返すことで改善します。
最初の質問、queryを3つに分解します。
from langchain.prompts import ChatPromptTemplate
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into sub-questions that can be answers in isolation. \n
Do not do anything other than that.\n
Generate multiple search queries related to: {question} \n
Output (3 questions):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
prompt = prompt_decomposition.format(question=query)
questions = llm.invoke(prompt)
questions = questions.split("\n")分割された質問:
1. 電子制御ユニット(ECU)のOTA(Over-the-Air)ソフトウェアアップデートの目的は何か
2.ECUのOTAソフトウェアアップデートを可能にする技術は何か
3.自動車アプリケーションのECU OTAソフトウェア開発の主な特徴は何か
分割した質問を個別に回答を生成し、質問と回答のペアを作成します。
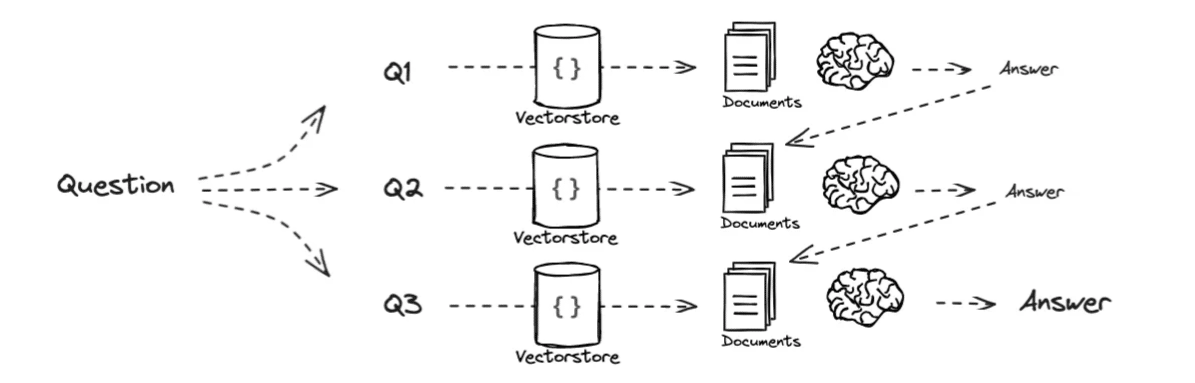
sequential_prompt = """You are a helpful assistant.Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.\n
Here is the question you need to answer:
\n --- \n {query} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: \n {query}
"""
seq_decomposition_prompt = ChatPromptTemplate.from_template(sequential_prompt)
def format_qa_pair(query, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {query}\nAnswer: {answer}\n\n"
return formatted_string.strip()
q_a_pairs = ""
for q in questions:
context = ',.,'.join([i.page_content for i in ensemble_retriever.invoke(q)])
answer = qa.invoke(seq_decomposition_prompt.format(query=q,q_a_pairs=q_a_pairs,context=context))
q_a_pair = format_qa_pair(q,answer['result'][answer['result'].index('Helpful Answer')+len('Helpful Answer'):])
q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair4. Reranking
5. Repacking
skip
6. Summarization
【3-3. Query Rewriting, Decomposition】で分割した3つの質問とその回答、それらと最初の質問から最終回答を生成します。
context = ',.,'.join([i.page_content for i in ensemble_retriever.invoke(query)])
answer = qa.invoke(seq_decomposition_prompt.format(query=query,q_a_pairs=q_a_pairs,context=context))最終回答:
電子制御ユニット(ECU)のOTA(Over-the-Air)ソフトウェアに関連する技術は、主に車両ECUの遠隔自動ソフトウェア更新のために開発された。OTAとして知られるこの技術は、中央サーバーからECUソフトウェアを直接更新することを可能にし、ECUへの物理的なアクセスを必要とせずに、車両が新機能やバグ修正を受けられることを保証する。本開示は、この技術をさらに強化し、サーバ上のOTAソフトウェアが変更された場合でもOTAを介してソフトウェアを更新できるソフトウェア更新装置、更新制御方法、および非一時的記憶媒体を提供することで、異なるベンダー間での互換性を確保する。これにより、ECUの機能向上、車両制御の新機能追加、各種システムのシームレスなソフトウェア更新を実現する技術を開発した。
所感
この1年でRAGの工夫が大量に出てきています。
冒頭の図のようにフローを区分するとわかりやすくなりますね。
この記事が気に入ったらサポートをしてみませんか?