
Lens.orgの特許Data活用(TOYOTA 1/n)

企業がその特許にどれ程力を入れているかを示す指標のひとつとしてファミリー数があります。Lens.orgはそのファミリー数を簡単に取得できます。
ユーザー登録だけすれば、50,000件の特許の基本的なDataをファミリー数(Simple family, Extended family)とともに出力できます。
例えばLens.orgで出力したTOYOTAの特許を分類し、以下のような最近特に出願件数の多い"Smart Facility and Vehicle Navigation Systems"の特許群(赤線)を見つけたとします。

いくつかの特許に目を通したくなりますが、その際にはファミリー数の多いものから目を通しておけば間違いはないと思います。

以下、具体例です。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
1. Lens.orgからData出力
応募者で "Toyota Motor Co Ltd" を選択、国・管轄庁で "US" を選択し、ひとつのフォルダに出力しました。

出力したファイルをDataframeにします。
path = r"C:\Users\Documents\Patent\Company\lens" #保存フォルダ
import pandas as pd
import glob
files = glob.glob(f"{path}/*.csv")
df = pd.DataFrame()
for file in files:
df_a = pd.read_csv(file)
df = pd.concat([df, df_a])文献数は 67,848件でした。
今回は要約文で分類するため、要約がないDataは削除します。
df = df.dropna(subset=['要約'])
df = df.reset_index()2. 要約文をもとに分類
基本的には
Bertopicが便利なので、Bertopicを使用。
embeddingにはBAAI(北京智源人工智能研究院)のbge-large-en-v1.5を使用。
docs = df['要約'].values
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired, MaximalMarginalRelevance
main_representation_model = KeyBERTInspired()
aspect_representation_model = [KeyBERTInspired(top_n_words=30),
MaximalMarginalRelevance(diversity=.5)]
representation_model = {
"Main": main_representation_model,
"Aspect": aspect_representation_model
}
embedding_mode = 'BAAI/bge-large-en-v1.5'
topic_model = BERTopic(verbose=True, embedding_model=embedding_model,
min_topic_size = 30,
representation_model = representation_model
)
topics, ini_probs = topic_model.fit_transform(docs)結果
topic_model.get_topic_info()
300件を超えるtopicに分類され、一見多すぎてビジーに感じるかもしれませんが、あとで適切なtopic名をつけることで案外大した数ではないことが実感できます。
3. Topic名
それぞれのTopicの名称をLLMに決めてもらいます。
modelは、最近様々なmodelの日本語性能を大きく向上させることで有名なHODACHIさんのHODACHI/Llama-3.1-8B-EZO-1.1-itを使用しました。
modelを設定
import transformers
import torch
model_id = "HODACHI/Llama-3.1-8B-EZO-1.1-it"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)分類時に設定したそれぞれのtopicのkeywordsと代表文をもとにtopic名を考えてもらいます。
from tqdm import tqdm
topic_names = []
for i in tqdm(range(len(topic_model.get_topic_info()))):
# for i in tqdm(range(3)):
DOCUMENTS = []
for j in topic_model.get_topic_info()["Representative_Docs"][i]:
DOCUMENTS.append(j[:1000])
"\n".join(DOCUMENTS)
KEYWORDS = topic_model.get_topic_info()["Aspect"][i]
system_prompt = """
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant for labeling topics.
<</SYS>>
"""
example_prompt = """
I have a topic that contains the following documents:
- Traditional diets in most cultures were primarily plant-based with a little meat on top, but with the rise of industrial style meat production and factory farming, meat has become a staple food.
- Meat, but especially beef, is the word food in terms of emissions.
- Eating meat doesn't make you a bad person, not eating meat doesn't make you a good one.
The topic is described by the following keywords: 'meat, beef, eat, eating, emissions, steak, food, health, processed, chicken'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST] Environmental impacts of eating meat
"""
main_prompt = f"""
[INST]
I have a topic that contains the following documents:
{DOCUMENTS}
The topic is described by the following keywords: '{KEYWORDS}'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST]
"""
prompt = example_prompt + main_prompt
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
outputs = pipeline(
messages,
max_new_tokens=512,
)
idx = outputs[0]["generated_text"][-1]['content'].find("\n")
topic_name = outputs[0]["generated_text"][-1]['content'][:idx]
topic_names.append(topic_name)
print(topic_name)命名
topic_model.set_topic_labels(topic_names)4. 系統樹
それぞれのtopicの系統樹を作成し、わかりやすくします。
fig = topic_model.visualize_hierarchy(width=1300, color_threshold=0.98, custom_labels=True, hierarchical_topics=hierarchical_topics)
fig.show()
それなりにいい感じで命名されているようにみえます。
5. topicのtrend
各topicの過去の出願数の推移を確認します。
years_list = df['発行年'].unique()
years_list.sort()
chart_df = pd.DataFrame()
for year in years_list:
a = df['topics'][df['発行年']==year].value_counts()
a_df = pd.DataFrame.from_dict(a.to_dict(), orient="index", columns=[year])
chart_df = pd.concat([chart_df, a_df], axis=1)過去全体で最も出願件数が多いtopicと、ここ数年で最も多いtopicをplotしてみました。
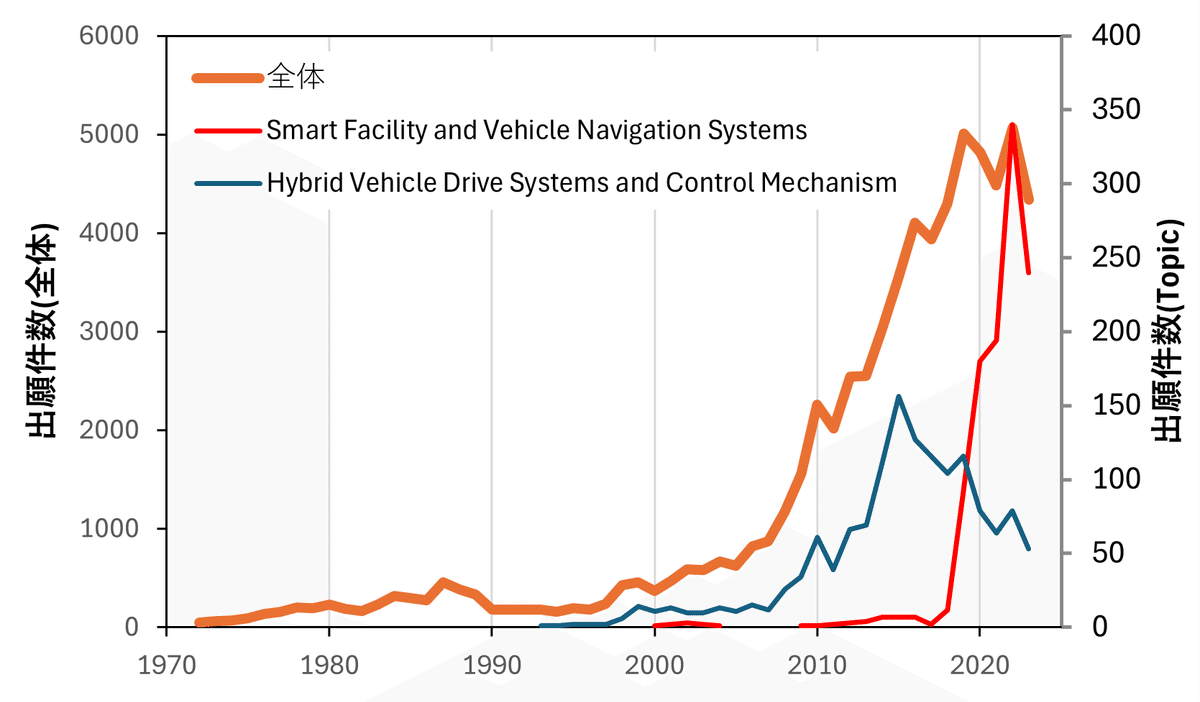
ハイブリッド車のドライブシステムに関する特許が過去最も多く、そのpeakが2015年ごろで今は低下傾向です。
2020年直前から急にスマートファシリティ・ナビシステムが急増しています。
スマートファシリティ・ナビシステムの特許の中でファミリーの大きいものを確認します。
family_size = df['シンプルファミリーサイズ'][xlist]
pat_abst = df['要約'][xlist].values
pat_year = df['発行年'][xlist].values
pat_no = df['表示キー'][xlist].values
df_a = pd.DataFrame()
df_a['シンプルファミリーサイズ'] = family_size
df_a['要約']= pat_abst
df_a['発行年']=pat_year
df_a['no'] = pat_no
df_a.rename(columns={0:'要約'})
df_a=df_a.sort_values(by='シンプルファミリーサイズ' ,ascending=False)
df_a.head()
2020年前後と最近の特許でもファイミリー数は20近く、結構力を入れていそうです。
それぞれの要約をLLMに咀嚼してもらいます。
for abst in pat_abst[:5]:
system_prompt = """
<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです。原則日本語で回答してください。.
<</SYS>>
"""
prompt = f"""
[INST]
次の文章はある特許の要約です。わかりやすく簡単に説明してください。:
{abst}
[/INST]
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
outputs = pipeline(
messages,
max_new_tokens=512,
)
output = outputs[0]["generated_text"][-1]['content']
print(output)・US 6094618 A
この特許は、パーキングロットなどの施設の位置情報をターミナルから要求されたときに、情報センターが近隣の道路などのランドマークを使用して相対的な位置情報をターミナルに提供する仕組みです。 ターミナルは、ローカルマップデータベースとマップマッチングプロセッサを使用して、ランドマークの位置と受信したランドマークの位置の差分(シフト)を計算し、施設の正確な位置情報を修正します。 ただし、ターミナルにランドマークが登録されていない場合、別の道路を基準とする相対データを再送信することにより、施設の位置情報を正確に提供するためのバックアップメカニズムが実装されています。
・US 11823552 B2
この特許の要約は次のようになります。 このシステムは、クライアント端末からネットワークを通じて、素材、使用方法、使用量のデータを受信し、データベースに格納します。
1. 素材をキーとして、素材成分データベースを検索し、素材中に含まれる化学物質とその量を特定します。
2. その化学物質と使用方法をキーとして、素材バランス係数データベースを検索し、化学物質が各場所で放出・移行する割合を取得します。
3. これらの情報を用いて、使用量、含まれる量、放出・移行割合を組み合わせて、各場所での化学物質の放出・移行量を計算します。
4. 最後に、計算された結果をクライアント端末にネットワークを通じて送信します。
このシステムは、化学物質の放出・移行を分析し、環境影響を予測するために使用されるようです。
・US 2022/0101716 A1
この特許は、車両とユーザーとの情報の共有を可能にするシステムです。
**概要**
1. 車両の生産工場では、車両の番号(シャーシナンバー)や、車両内の通信機器(MACアドレス)の情報が、情報提供センターに送信されます。
2. 車両販売店では、車両の番号とナンバープレートの情報が、センターに送信されます。
3. 情報提供センターでは、送信された情報を、車両を特定する情報(movable-body-specifying information)と、ユーザーを特定する情報(user-specifying information)として、データベースに登録します。
4. ユーザーは、特定の車両と関連する情報を取得するために、情報提供アプリ(apparatus 10)を使用して、センターにリクエストを送信します。
5. センターでは、ユーザーが送信した情報を検証し、車両が現在の位置が、予め登録された位置と一致するかどうかを確認します。
6. 位置が一致し、ユーザーが正当である場合、センターは、指定されたユーザーに情報を提供します。
このシステムは、車両の安全性や管理性を向上させるために、車両とユーザーとの情報の共有を可能にします。
とても"スマート"感があります。
最近急増化しているtopicを抽出すると下記のようになりました。
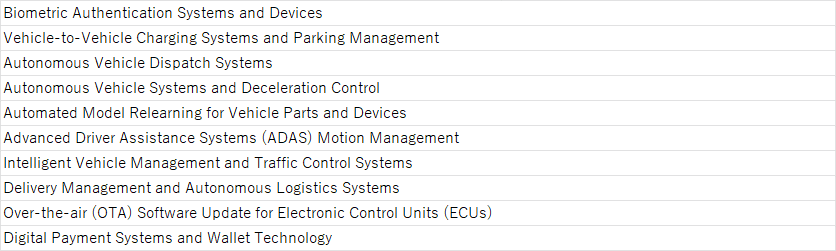
やはりとても"スマート"感があります。
Woven Cityですね。
6. 参考
この記事が気に入ったらサポートをしてみませんか?