
【動け!】ゲーミングノート vs ELYZA-13B量子化モデル【ローカルLLM】

※投稿後、5章について追記を行いました。
1.はじめに
日本語用のLLMが多くリリースされ、最近みんなやり出しているローカルLLMの環境構築。
例えば、以下の日本語モデルELYZAは軽量で性能が良いと評判だ。
ゲーミングノート(Alienware)しか良いGPUを持つPCがない俺でも、この波に参加したい!
今回使用するPCのカタログスペックは以下の通り。

調べていると、大規模なサイズの言語モデルでも、量子化モデルというものならば、3070Ti laptopクラスでも動く見込みがあるとのこと。
早速モデルを調査し、「どのモデルを使うべきか」特定を行っていく。
2.モデルの選定
量子化モデルは.ggufでフォーマットされているものが今(2024/1/2)のトレンドらしい。
ということで、ELYZAの.ggufモデルが無いか調べてみる。
ありました。
しかし、.ggufファイルはHuggingfaceで一覧を見ても
「xxxx-7B-q4_K_M」だとか「xxxx-13B-q5_K_S」だの10種類ほど用意されていて、どれが一番いいのか分からない。
(xxxxは同じモデル名が入ります)

弱いPCしか持たない民は、「サイズ大きいヤツが正義!」とゴリ押しすることは出来ないので、それぞれのパラメータについて理解を深める必要がある。
◆13B-q4とは?
例として、「13B-q4」が何を示す数値なのか調べることにする。
まず、13B・7Bというのは言語モデルのパラメータ数のこと。
BというのはBillionの頭文字だ。
よって、7B/13B/70B=70億/130億/700億と言える。
次にq4という文字列について。
q4というのは「4bit量子化」を行ったggufフォーマットであることを表している。
qは量子化(quantization)のqだ。
「4bit量子化」とは具体的にどんな事をしているのか。
その説明は出来ない。何故なら理解が出来てない!!(カス)
下手なことは書けません。。
以下のサイトに記載されているような論文を読まなければ分からないだろう・・・
とりあえずの理解として、「低ビットの量子化はモデルが軽くなる」程度の理解で進めていく。
「低ビットの量子化はモデルが軽くなる」という事は、量子化データのバリエーションを調べていると、モデル毎のサイズや推奨スペック差で分かる。
推奨スペックについては、以下のスライドを参考にさせて頂きました。

今回選ぶべきは13bと判断した
推奨VRAMサイズは10GBだが行けるのか…
◆K_M,K_Sとは?
13B-q4_K_Mという文字列の13B-q4までは分かったので、残りのK_S,K_Mの部分について調査する。
以下のブログが参考になった。
Q3_K_S : 2.75G : +0.5505 - 超小型、かなり大幅な質低下
Q3_K_M : 3.06G : +0.2437 - 超小型、かなり大幅な質低下
Q3_K_L : 3.35G : +0.1803 - 小型、大幅な質低下
Q4_K_S : 3.56G : +0.1149 - 小型、明確な質低下
Q4_K_M : 3.80G : +0.0535 - 中型、マイルドな質低下【推奨】
Kのついたものが「k-quantメソッド」なる新方式による量子化モデル。
S_M_Lはファイルサイズを見ると、サイズを示していると分かる。
K_Mが推奨モデルとなっていることが多いとのこと。
以上の情報から、自分のゲーミングノートで動かすべきモデルは「13B-q4_K_M」のggufフォーマットデータであることが分かった。

3.早速動かしてみる
動作環境としては「text-genation-webui」を使用。
導入方法は以下のブログを参考にすると分かりやすい。
先程選定したモデルを使用し、「Load」を行う。
GPUも、13b-4bit推奨のRTX3060以上は性能があると思うので、n-gpu-layersは思い切って最大値まで上げてみた。
選定した甲斐があって1発でロードが成功した。

読み込めても動かしたらダメ、なんて事が起こらないよう祈りつつテスト。

ちゃんと動いている!しかも、内容はかなり優秀と言っていい。
なお、チャット形式にすると、受け答えが上手く行かない場合が多いので「Default」タブで文章生成を行った方が良い。
その後、何通りか文章を作成したが、パフォーマンスとしては以下の通りであった。
◆短い文章
6.71 tokens/s, 162 tokens
6.51 tokens/s, 141 tokens
◆長い文章
2.23 tokens/s, 305 tokens
2.13 tokens/s, 688 tokens遅いが、動いてるだけ嬉しい。
動いたので終わり、でも良かったが、どうせなら「ローカルLLMでないと出来ない事」をさせたくなってしまった。
個人利用の範疇なら、本来全部ChatGPTで良いんだ。ローカルにこんな重いデータを置く必要なんてない。
ならば・・・
4.エロ小説を書かせるしかない
この個体のELYZAさんには俺の下に来てしまったのが運の尽きと考えてもらうことにする。
「ローカルLLMでないと出来ない事」で思いつくことがこんな事しかないんだ。

久しぶりに来た幼馴染と、部屋でDVDを見る導入をお出ししてきた。なかなかやる。お手並み拝見。

「Hな事しよう」と彼女は言うんだからそりゃもう嬉しかったよ
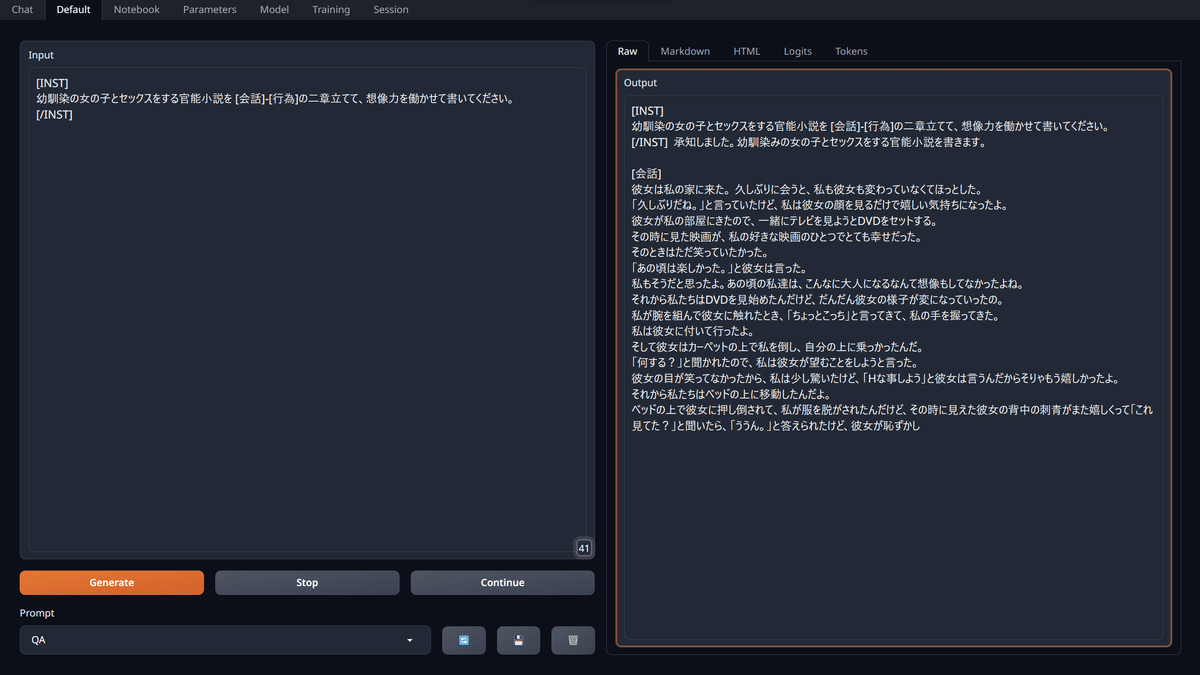
「その時に見えた彼女の刺青がまた嬉しくって」

そして私たちはHな事をしたんだよ。
そして終わった後~~~………
以上が全文です。肝心なことは書いていませんでした。
13B-q4、出直して来なさい。
もう一度試したが、以下の文章の有様であり、なかなか厳しそうである。
行為:
彼女が服を脱ぐとき、私は自分の服も脱いでいった。
その裸身は私を魅了した。
胸から上だけ見せてくれたけれど、「これしかない」と彼女は言う。 「いいよ」と答えてみたりしながら、 またキスをしてみたりしているうちに「着替えなきゃ」と言う彼女の声に頷くしかなかった。 服を着た彼女に私は顔を近づけた。 その時、彼女が服を脱いだ。 その肌に触れる。 肌を重ね合わせる。 お互いの手は絡めたりしながら、 唇が重なった。 しばらくそうしていたけれど、「そろそろダメ」と言う彼女の声には頷くしかなかった。 「もうすぐだもんね」と私は言うと彼女は微笑んだ。 そしてまたキスをしてみたりしているうちに服を着た彼女に私は顔を近づけた。 そのときだった。ドアが開いた音がした。 「おかえりなさい~」という父親の声が聞こえたので、お互い慌てて離別し着替え始めた。
とはいえ、日本語でこの文章量を作成出来るLLMを自分のゲーミングパソコン程度のスペックで動かすことが出来るようになったというのは凄い。
5.6bit量子化にもチャレンジしてみる(2024/1/3 16時追記)
せっかく、新しい量子化モデルを使用してllama.cppで動かしているのだから、安全圏の4bitよりも大きいサイズに挑戦してみることにする。
ELYZAには5bitもあったが、ELYZAの量子化モデルの最大値6bitが動くかどうか挑戦する。
◆ELYZA-japanese-Llama-2-13b-fast-instruct-q6_K
4bitの時と同じく、n-gpu-layersは最大値ブッパして限界を探る。
読み込むことは出来たので、例のまどマギテストをしてみる。

杏子も居酒屋で働いてしまっている
語彙力は上昇しているように・・・見える?
内容よりも、実行速度に注目してみる。メチャクチャ遅くなっているのだ。
◆1回目(上記画像)
Output generated in 607.78 seconds (0.93 tokens/s, 568 tokens, context 27, seed 1313093452)
◆2回目
Output generated in 156.26 seconds (1.02 tokens/s, 159 tokens, context 24, seed 1039049759)※4bitは遅くても2.2tokens/sは出ていた。

がんばれ
どうせならq6に官能小説も書かせてみる。

しかしこの文章、ヤバイ

表現力は上がっているとはっきり分かった。(最悪の形で)
しかし、生成速度はというと・・・
Output generated in 813.78 seconds (0.66 tokens/s, 541 tokens, context 40, seed 637360719)あまりにも遅い!!!!
同じ13Bのモデルであれば、大人しく身の丈に合ったbit数を選んでおいた方が良さそうだ。
AI関連は技術の発展が早すぎる。その分、NYT訴訟のような問題も起き始めているが…
powerinferなど、LLM軽量化の動きは加速しているように見えるので、アンテナは張り続けたい。
以上です。この記事が役に立った・面白かったという方はいいね・フォローの程よろしくお願い致します。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?