【ローカルLLM】llama.cppの量子化バリエーションを整理する

【追記】
この記事の内容はかなり古くなっているのでご注意ください。ブログに新しい記事(https://sc-bakushu.hatenablog.com/entry/2024/02/26/062547)も上げてます。
「llama.cpp」はMacBookなどでLlamaベースの大規模言語モデルを動かすことを目標とするアプリケーション。一応CPUのみでも実行でき、GPUの非力な環境でも動かしやすい。
llama.cppの量子化モデル
llama.cpp(GGML)では量子化によるモデルサイズ縮小が進んでいる。例えば、下記のHuggingFaceのRepoを見ると、GGML量子化モデルは「q4_0, q4_1, q5_0, q5_1, q8_0, q2_K, q3_K_S, q3_K_M, q3_K_L, q4_K_S, q4_K_M, q5_K_S, q5_K_M, q6_K」と多岐にわたる。
Model cardに解説があるものの、専門的で素人にはサイズ以外の違いが分からない。もう少しやさしい説明がないか調べたところ、llama.cppの"quantize"コマンド内に整理されていると知ったので、和訳して掲載する。
llama.cppモデルのバリエーション一覧(7Bの例)
種類 : サイズ : Perplexity Loss(ppl) - 説明
Q2_K : 2.67G : +0.8698 - 最小型、極端な質低下<非推奨>
Q3_K_S : 2.75G : +0.5505 - 超小型、かなり大幅な質低下
Q3_K_M : 3.06G : +0.2437 - 超小型、かなり大幅な質低下
Q3_K_L : 3.35G : +0.1803 - 小型、大幅な質低下
Q4_K_S : 3.56G : +0.1149 - 小型、明確な質低下
Q4_K_M : 3.80G : +0.0535 - 中型、マイルドな質低下【推奨】
Q5_K_S : 4.33G : +0.0353 - 大型、わずかな質低下【推奨】
Q5_K_M : 4.45G : +0.0142 - 大型、かなりわずかな質低下【推奨】
Q6_K : 5.15G : +0.0044 - 超大型、ごくわずかな質低下
Q4_0 : 3.50G : +0.2499 - 小型、かなり大幅な質低下<レガシー>
Q4_1 : 3.90G : +0.1846 - 小型、大幅な質低下<レガシー>
Q5_0 : 4.30G : +0.0796 - 中型、マイルドな質低下<レガシー>
Q5_1 : 4.70G : +0.0415 - 中型、わずかな質低下<レガシー>
Q8_0 : 6.70G : +0.0004 - 超大型、ごくわずかな質低下<非推奨>
F16 : 13.00G : - - 極大型、事実上の質低下なし<非推奨>
F32 : 26.00G : - - クソデカ、質低下なし<非推奨>
Kのついたものが「k-quantメソッド」なる新方式による量子化モデル。Kのない4bit/5bit量子化(q4_0, q4_1, q5_0, q5_1)は旧方式のレガシーなので基本的に選ばない。
Perplexityはモデルによる単語の予測力を示す指標で、低いほどいいらしい。Perplexity Lossの値が大きいほど、量子化による劣化も大きい。
例えば、2bitのk-quant量子化モデル(Q2_K)は、サイズは最小だが質の低下が著しく「非推奨」。一方で、Q4_K_M~Q5_K_Mはサイズと質のバランスがよく「推奨」と記されている。
k-quantメソッドによる量子化(サイズ圧縮)と質の劣化の関係を示すグラフは以下。モデルサイズを圧縮していくとPerplexityが非線形に上昇するので、中程度の量子化にとどめた方がいいことが分かる。
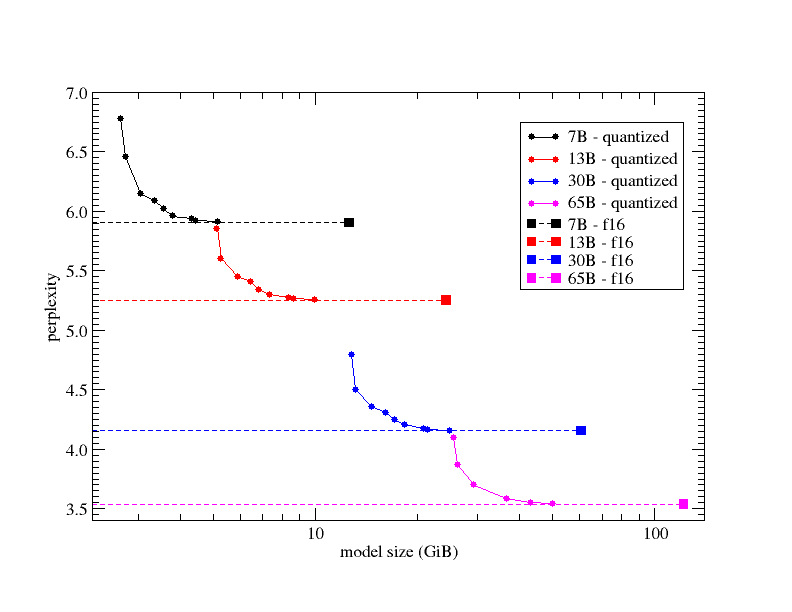
感想
llama.cppの場合、4bitまたは5bitくらいのk-quant量子化を選んでおくのが無難ということが分かった。
ただ、それだとGPTQによる量子化モデル(4-bit)とサイズが変わらないので、llama.cppを選ぶメリットが減ってしまう気もする(CPUで動かせる利点は残るものの)。
なお個人の使用実感でいうと、量子化によるテキストの劣化はあまり感じられない。正直、Q2_KもQ4_K_Mも大差ない印象。むしろモデルサイズが大きいことによる生成速度低下のほうが全然ストレスフルだったりする。