
人種を判別するアプリケーションを機械学習を用いて作ってみた

機械学習を用いた男女識別や物を検出する技術は有名ですが、人種を判別するものはあまり見たことがないので作ってみました。
自己紹介:テキサスの大学のCS学部を卒業→医療機器メーカーで約2年→アイデミー(AIプログラミングスクール)を受講
まずは画像をアップロード
まずはいろんな正面像の顔画像をアップロードして、どういう結果が出るか確かめてみて下さい。下記のように画像をアップすると、顔だけがクロップされて結果が出てきます。結果は、East Asian、Indian、Black、White、Middle Eastern、Latino_Hispanic、Southeast Asianのいずれかです。
注意事項
※対応しているファイル形式は png、jpg、jpeg、gif です。
※データが大きすぎると弾かれます。
人種判別アプリ→https://race-classifier.herokuapp.com/


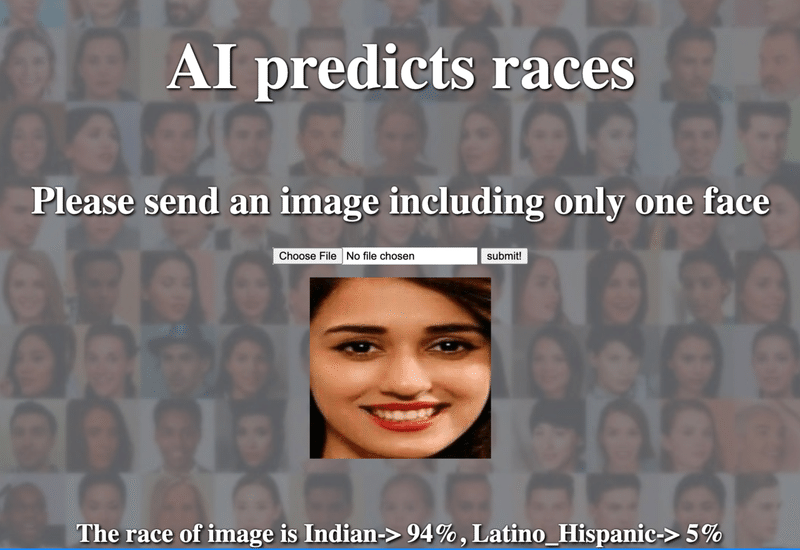
自分の顔画像の結果はいかがでしたでしょうか。
次の項から、どのようにしてアプリを作成したか説明していきます。
アプリ作成手順
①データセットを取得
②データの整形
③モデルの学習、評価
④HTML & CSS
⑤Flask
①データセットを取得
Googleで顔画像のデータセットを探していると、FairFaceという予め性別や人種がラベリングされたデータセットがありましたので、そちらを使用させて頂きました。
FairFace → https://github.com/joojs/fairface
②データの整形
# organizing Dataset
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import random
import pandas as pd
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input, ZeroPadding2D, Convolution2D, MaxPooling2D, Activation
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
from keras_vggface.vggface import VGGFace
from keras_vggface import utils
races = ['East Asian', 'Indian', 'Black', 'White', 'Middle Eastern', 'Latino_Hispanic', 'Southeast Asian']
train_df = pd.read_csv("fairface_label_train.csv") # shape is (86744, 5)
test_df = pd.read_csv("fairface_label_val.csv") # shape is (10954, 5)
print(test_df.head())
#print(train_df.race.unique())
#['East Asian' 'Indian' 'Black' 'White' 'Middle Eastern' 'Latino_Hispanic' 'Southeast Asian']
#[0, 1, 2, 3, 4, 5, 6] respectively
img_train = []
img_val = []
# make y_train and y_test
label_train = []
label_test = []
for i in range(60000): # train label
img = cv2.imread('./fairface-img-margin025-trainval/' + train_df["file"][i])
img_train.append(img)
if train_df["race"][i] == "East Asian":
label_train.append(0)
elif train_df["race"][i] == "Indian":
label_train.append(1)
elif train_df["race"][i] == "Black":
label_train.append(2)
elif train_df["race"][i] == "White":
label_train.append(3)
elif train_df["race"][i] == "Middle Eastern":
label_train.append(4)
elif train_df["race"][i] == "Latino_Hispanic":
label_train.append(5)
elif train_df["race"][i] == "Southeast Asian":
label_train.append(6)
else:
print("error!!!!!!")
for i in range(8000): # test label
img = cv2.imread('./fairface-img-margin025-trainval/' + test_df["file"][i])
img_val.append(img)
if test_df["race"][i] == "East Asian":
label_test.append(0)
elif test_df["race"][i] == "Indian":
label_test.append(1)
elif test_df["race"][i] == "Black":
label_test.append(2)
elif test_df["race"][i] == "White":
label_test.append(3)
elif test_df["race"][i] == "Middle Eastern":
label_test.append(4)
elif test_df["race"][i] == "Latino_Hispanic":
label_test.append(5)
elif test_df["race"][i] == "Southeast Asian":
label_test.append(6)
else:
print("error!!!!!!")
y_train = np.array(label_train)
y_test = np.array(label_test)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
X_train = np.array(img_train) # shape is (x , 224,224,3)
X_test = np.array(img_val) # shape is (x , 224,224,3) 出力

学習データとテストデータはそれぞれ、86744枚と10954枚分の画像データがありますが、全ての画像データを使用すると重くなる為、上限を60000と8000に少し減らしております。
コードの説明をすると、CSV形式のラベルファイルをデータフレーム形式に変換し、画像データを一つずつ img_train や img_val に格納すると同時に、人種ラベルデータを予め決めた数字に変え、label_train と label_test に格納します。
コードの最後の部分は、格納したデータを学習させる時に必要なデータ形式に変換しております。
③モデルの学習、評価
#SGD
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import random
import pandas as pd
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input, ZeroPadding2D, Convolution2D, MaxPooling2D, Activation
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
from keras_vggface.vggface import VGGFace
from keras_vggface import utils
# define model based on VGG-Face
vgg_model = VGGFace(include_top=False, input_shape=(224, 224, 3))
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(7, activation='softmax'))
model = Model(inputs=vgg_model.input, outputs=top_model(vgg_model.output))
for layer in model.layers[:15]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# load weights
model.load_weights('vggface_model_Both.hdf5')
model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=64, epochs=1)
# モデルを保存
model.save_weights('vggface_model_Both.hdf5')
model.save('vggface_model_Both.h5')
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
def pred_race(img):
#img = cv2.resize(img, (112,112))
img = img.reshape(-1, 224,224,3)
prediction = model.predict(img)
return (races[prediction[0].argmax()])
for i in range(10):
img = cv2.imread('./fairface-img-margin025-trainval/' + test_df["file"][i])
print()
b,g,r = cv2.split(img)
img_r = cv2.merge([r,g,b])
plt.imshow(img_r)
plt.show()
print("Actual: " + test_df["race"][i])
print("Prediction: " + pred_race(img)) 出力

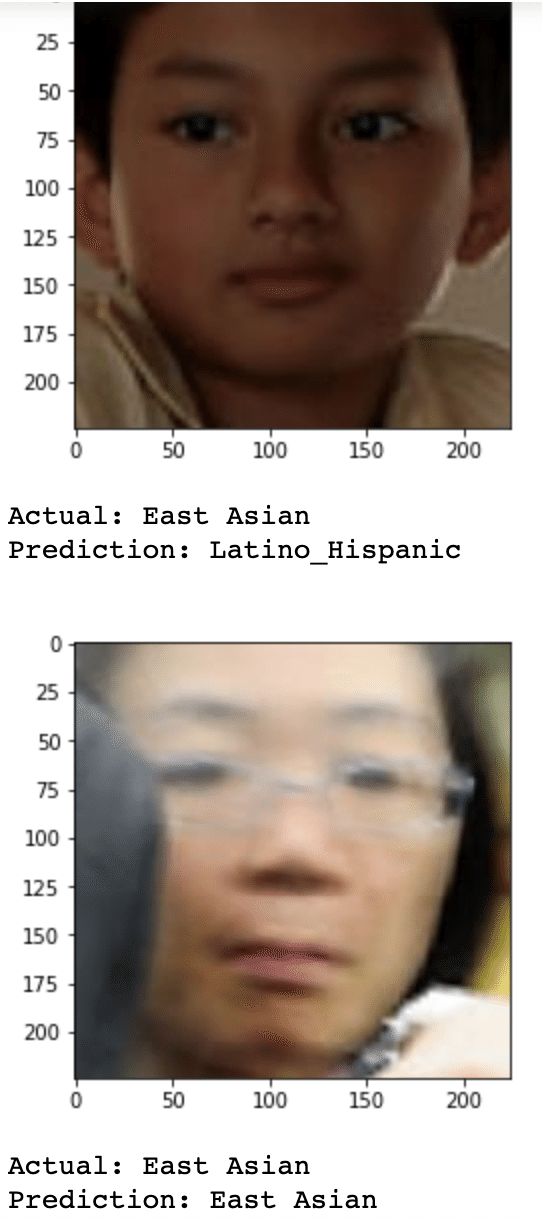

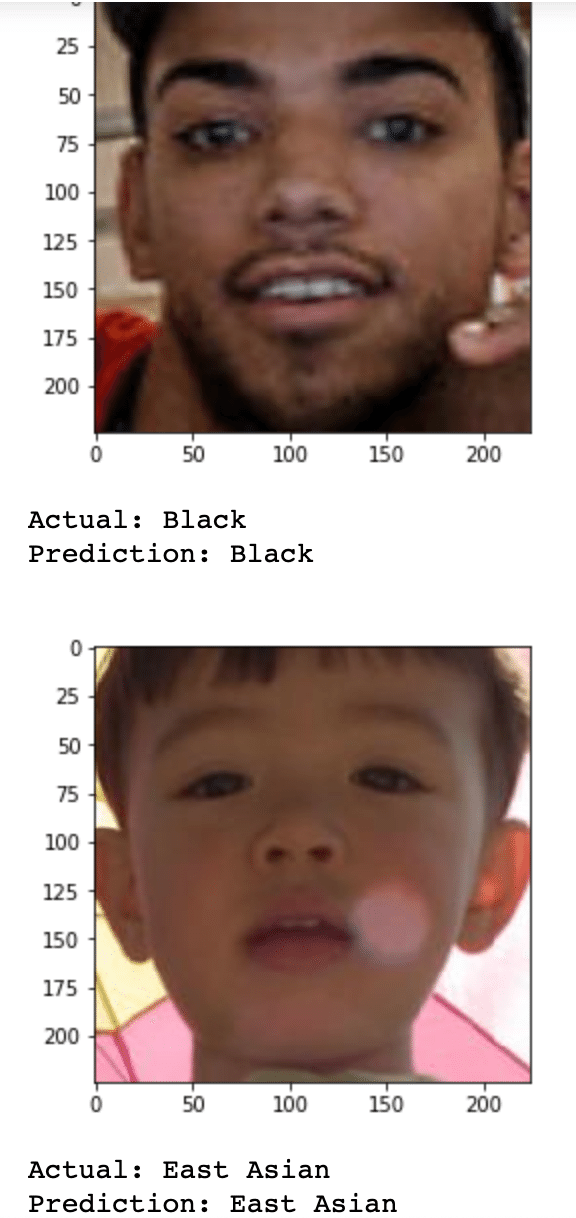
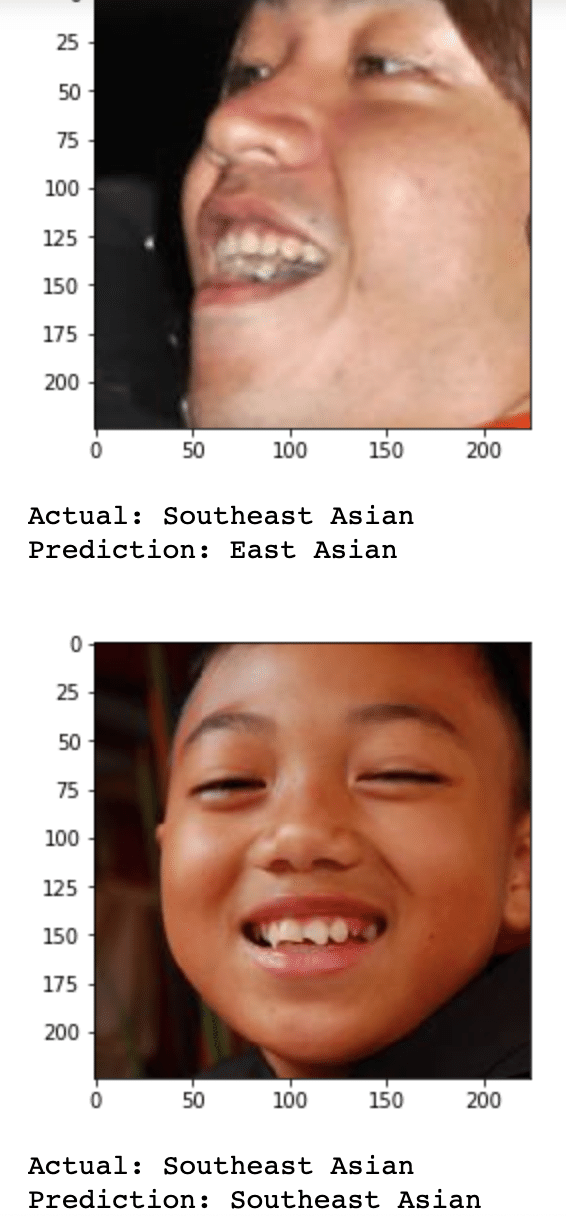
VGG-Face をベースにしたモデルを使用して学習をさせます。出力結果を見ると、最終のTest Accuracyは約60%で、実際の race と予測された race が画像と共に表示されています。
④ HTML & CSS
HTML、コード
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Race Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<a class="header-logo" href="#">Race Classifier</a>
</header>
<div class="main">
<h1> AI predicts races </h1>
<h2>Please send an image including only one face</h2>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<p class="crp_img">
<img src="{{cropped_image}}" >
</p>
<div class="answer">{{answer}}</div>
</div>
<footer>
<small>© 2020 Jumpei Yoshii</small>
</footer>
</body>
</html>CSS、コード
body {
background-image: url('AI_faces.jpg');
background-repeat: no-repeat;
background-attachment: fixed;
background-size: cover;
}
header {
background-color: #0084ff;
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 50px;
}
.header-logo {
color: #ffffff;
font-size: 1.5rem;
margin: 10px 25px;
position: absolute;
left: 0;
}
.main {
height: 370px;
}
h1 {
color: #ffffff;
text-shadow: 0px 0px 2px #000, 2px 2px 3px #000;
line-height: 1.2;
font-size: 5rem;
font-weight: 900;
margin: 90px 0px;
text-align: center;
}
h2 {
color: #ffffff;
text-shadow: 0px 0px 2px #000, 2px 2px 3px #000;
font-size: 3rem;
font-weight: 900;
margin: 70px 0px 30px 0px;
text-align: center;
}
.crp_img {
text-align: center;
}
.answer {
color: #ffffff;
text-shadow: 0px 0px 2px #000, 2px 2px 3px #000;
font-size: 2rem;
font-weight: 900;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
.file_choose {
background-color: #ffffff;
}
footer {
background-color: #0084ff;
height: 30px;
margin: 0px;
position: fixed;
left: 0;
bottom: 0;
width: 100%;
}
small {
color: #ffffff;
margin: 10px 25px;
position: absolute;
left: 0;
bottom: 0;
}⑤ Flask
import os
from flask import Flask, request, redirect, url_for, render_template, flash
from werkzeug.utils import secure_filename
from keras.models import Sequential, load_model
from keras.preprocessing import image
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from mtcnn.mtcnn import MTCNN
from PIL import Image
races = ['East Asian', 'Indian', 'Black', 'White', 'Middle Eastern', 'Latino_Hispanic', 'Southeast Asian']
num_races = len(races)
image_size = 224
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./vggface_model_Both.h5') #学習済みモデルをロードする
graph = tf.get_default_graph() #追加
@app.route('/', methods=['GET', 'POST'])
def upload_file():
global graph #追加
with graph.as_default(): #追加
if request.method == 'POST':
if 'file' not in request.files:
flash('There is no file')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('There is no file')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
pixels = plt.imread(filepath)
detector = MTCNN()
results = detector.detect_faces(pixels)
x1, y1, width, height = results[0]['box']
x2, y2 = x1 + width, y1 + height
face = pixels[y1:y2, x1:x2]
image = Image.fromarray(face)
image = image.resize((224,224))
face_array = np.asarray(image)
#クロップされた画像を保存
image.save('./static/' + file.filename)
crp_path = './static/' + file.filename
data = np.array([face_array])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "The race of image is "
pred_answer = pred_answer + "\n" + races[predicted] + "-> " + str(int(max(result)*100)) + "%,"
temp_pred = sorted(result)
pred_answer = pred_answer + "\n" + races[result.tolist().index(temp_pred[-2])]
pred_answer = pred_answer + "-> " + str(int(temp_pred[-2]*100)) + "%"
return render_template("index.html",answer=pred_answer, cropped_image = crp_path)
return render_template("index.html",answer="", cropped_image="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port) こちらのコードは先ほど学習させたモデルを用いて、ユーザーがアップした画像の人種を判別します。コードを見ると分かると思いますが、アップされた画像の顔部分だけをクロップし、予測結果とクロップされた画像が保存されているfile pathをHTMLファイルに渡します。
最後に
最終のモデルのTest Accuracyは約60%と、少し低い感じがしますが、データセットの中には沢山の粗い画像や横を向いた画像、サングラスをかけた画像等がありましたので精度に関してはまずまずな結果かなと感じました。また、ミックスの方など、母親または父親が自分と違う国籍の方も多くいらっしゃるので、それも精度が下がる一つの要因かなと思います。ちなみに、海外のプログラマーの Sefik さんが同じデータセットを使用し、East AsianとSoutheast Asianをくっつけて学習させると、68%の精度が出たという記事もありましたので、参考にして頂ければと思います。
この記事が気に入ったらサポートをしてみませんか?