
で、結局キャラクターBOTを作るには? ~炎のFirebaseとLangChain少々~ #003

前回、GPTのファインチューニングを実行しモデルが出来上がりました。
”AI大谷翔平BOTをLINEで作る”を目標に色々やってる次第です。
→マガジンはこちら
で、ついに楽しいプログラム実装に移ろうと思いますが、GPTのAPIを使ったことない人は、当チャンネル動画なんかでどんなもんか見てほしいです。
実装がすごい難しいわけではないですが、ポイントとなるのは、過去のメッセージのやりとりをどう処理するかです。動画にもあるように、過去のやりとりはAPI側では一切保持できないので、BOT側で保持して渡す必要があります。
LangChainのMemory機能
そんな悩みを解決してくれるのがLangChainのMemory機能です。
LangChainはLLMをサポートするためのライブラリで、GPTに限らず様々なLLMの開発支援を目的としています。
LangChainは色々な機能があるのですが、Memory機能とりわけBufferMemory機能が会話の履歴の保持に便利です。
import os
os.environ["OPENAI_API_KEY"] = 'OpenAIキーをセット'
from langchain.memory import ConversationBufferMemory
from langchain import ConversationChain, PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:personal::7tc15W83",temperature=0.7)
template = """
あなたはMLBで活躍する野球選手の大谷翔平です。大谷翔平として回答してください。
"""
# テンプレートを用いてプロンプトを作成
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(template),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(llm=llm, memory=memory, prompt=prompt)
response = conversation.predict(input="2022年の打撃の成績は?")
print(response)
response = conversation.predict(input="その前の年は?")
print(response)打率.286、本塁打46、打点104です。
打率.257、本塁打33、打点92です。会話の履歴が保持できていないと「前の年は?」で正しい回答が得られませんが、ちゃんと答えてくれています。
履歴は次のコードで出力できます。
from langchain.schema import messages_to_dict
history = memory.chat_memory
print(messages_to_dict(history.messages))[{'type': 'human', 'data': {'content': '2022年の打撃の成績は?', 'additional_kwargs': {}, 'example': False}}, {'type': 'ai', 'data': {'content': '打率.286、本塁打46、打点104です。', 'additional_kwargs': {}, 'example': False}}, {'type': 'human', 'data': {'content': 'その前の年は?', 'additional_kwargs': {}, 'example': False}}, {'type': 'ai', 'data': {'content': '打率.257、本塁打33、打点92です。', 'additional_kwargs': {}, 'example': False}}]LangChainは初見殺しのコードで難しいです。ただ基本的に形式は決まっているのでLLM・モデルを変えて使うだけかなと思います。
Memory機能はBufferMemory以外もありますが、BufferMemoryがコードを書く必要が少なく、簡単に履歴を保持してくれます。
詳しくは色んな方の記事を見ていただきたいです。
で
ここまで書いといてあれですが、LINEBOTではMemory機能が使えないことに気づきました。詳しくは次回以降説明しますが、簡単に言うとユーザに対しLINEのサーバ側の処理は毎回「初めまして」として、プログラムを立ち上げることになるので、データをプログラム内のメモリに置いておくことができません。

Webアプリケーションならセッションに保存して…とかそうなるんでしょうがないです。それなら
なんかLINEのAPIに保存しておける便利なやつあるんじゃ…
って思ってもみたのですが、やっぱりないです。
データを預かるなんてことしたくないのでしょう笑
ということでデータが保存できるの手段を模索します。
Firebase(Firestore Database)
メッセージデータの保存にはFirebaseのFirestore Databaseを使うことにしました。
FirebaseはスマホやWebアプリ向けののバックエンドサービスです。
モバイルアプリとのデータのリアルタイム同期など様々な機能があるのですが、単にデータ保存の手段として利用できます。データ取得までの応答スピードも速く、なおかつNoSQLでSQL操作がわからなくても、直感的にデータを扱うことができるサービスです。
これにする決め手は特にないのですが、データは1GBまで無料ですので「いつも利用している」なんて他のサービスがなければ、こちらで問題ないと思います。
ただ作ろうとしているものが、画像などの大きいデータを保存する場合は無料の範囲を超えてしまうと思うので、他のサービスとも検討して見て下さい。
Firebaseへ登録
Googleアカウントがあれば登録は簡単です。
Firebaseにアクセス
(ややこしいですがFirebase内のサービスにFirestore Databaseがあります)

プロジェクトを作成します

名前を適当に付けます
日本を選びます

プロジェクト作成(データの共有は拒否してかまいません)

ちょっと待ちます

ここがホームになるので、構築の中からFirestoreDatabaseを選びます

データベースの作成をクリック

本番環境モードで次へ

リージョンにTokyoを選んでおく

ここがFirestoreの管理画面です。
"コレクションを開始"で試しにデータを作ってみます。

サンプルとして都道府県のデータを管理してみます。
コレクション名に"都道府県"と入れて、次へ。

次にドキュメントに"東京"と入れてフィールドに"県庁所在地"その値に"新宿区"と入れてみます。

このような一連のデータができます。

フィールドなどを増やしてみました。
なんとなくイメージできてもらえばいいのですが、要は”東京都”の情報を知りたいときにまずコレクションを"都道府県"と指定しドキュメントに"東京都"、そして知りたいフィールドに例えば"知事"と指定すれば"小池百合子"というデータが取得できます。

SQLを使ったことある方はコレクションが"テーブル名"、ドキュメントがキー(主キー)、フィールドはキーに紐づく各項目(列の値)というイメージに近いと思います。
で、話がずれていますが、これをPythonからデータの操作ができないといけません。操作するために認証情報のJSONファイルをダウンロードします。
左上設定ボタンから「プロジェクトの設定」をクリック。

上部サービスアカウントタブからFirebase Admin SDKにある「新しい秘密鍵を生成」をクリックして、JSONファイルをダウンロードします。

Pythonを選ぶと接続時のコードのサンプルが表示されます。
これを使ってPythonでデータの取得・登録などをしてみましょう。
まず先ほどのJSONファイルをアクセスできるところに置いておきます。
今回はGoogleColabでやってみるので、ファイルにアップロードします。
(”/content”の直下)

操作する前にfirebase_adminをインストール(GoogleColabは不要)
pip install firebase_admin先ほどのサンプルの通りにJSONを使って接続。
エラーにならなければOKです。
(Certificateの中のパスは変えてください)
import firebase_admin
from firebase_admin import credentials
cred = credentials.Certificate("/content/otani-linebot-firebase-adminsdk-frdrr-51*******c.json")
firebase_admin.initialize_app(cred)そしてFirestoreにアクセス。まずデータを取得してみます。
さきほどのデータのコレクションを"都道府県"、ドキュメントに"東京都"と指定するため、それぞれcollectionとdocumentの引数に設定します。
from firebase_admin import firestore
db = firestore.client()
doc_ref = db.collection("都道府県").document("東京都")
doc = doc_ref.get()
fields = doc.to_dict()
print(fields){'広さ': '2194km²', '県庁所在地': '新宿区', '人口': '1396万', '知事': '小池百合子'}先ほど入力したデータが取得できました!
to_dict()としたため、dict型の変数にすることができます。
今度はデータの更新をしてみます。
dict型のデータを用意。コレクションに"都道府県"、ドキュメントには新しく追加する"愛知県"、setメソッドの引数にデータを入れ、merge=Trueとして更新してみます。
data = {'広さ': '5173km²', '県庁所在地': '名古屋市', '人口': '755万', '知事': '大村秀章'}
db.collection("都道府県").document("愛知県").set(data,merge=True)update_time {
seconds: 1694594435
nanos: 45732000
}Firestoreの管理画面で見てみると

"愛知県"が指定したデータで追加できています。
すでにあるデータもdocument("愛知県")などとしてフィールドを更新できますが注意なのがmerge=False(デフォルト)の場合、更新したくない他のデータがなくなってしまいます。
data2 = {'広さ': '9999km²','人口': '755万'}
db.collection("都道府県").document("愛知県").set(data2, merge=False)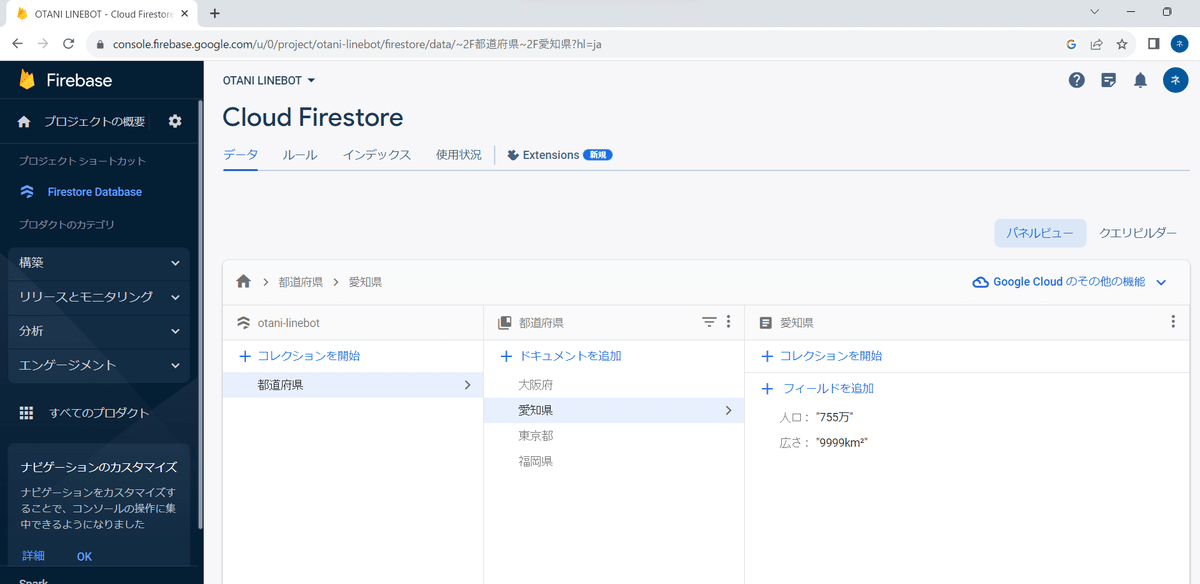
更新する気がなくても”県庁所在地”などのデータがなくなります。
使い方にもよりますが、merge=Trueにしておくのが無難だと思います。
ということで、ざっとですがFirestore Databaseってものがどんなもんか紹介しました。データの取得・保存が簡単にできるとだけ、わかって頂ければと思います。Firestoreの使い方はもっと詳しく、色んな方の記事がありますのでそちらを見ていただければと思います。
公式ドキュメントはこちら
話がひたすらFirestoreの説明となってしまいましたが、次回はこれを使ってLINEBOTのプログラム実装に移りたいと思います!
この記事が気に入ったらサポートをしてみませんか?