
【negocia株式会社/サマーインターン】 広告画像効果推定モデルの精度改善

はじめに
8/2~8/31の3週間、negociaにインターンとして参加した栗岡保です。大学では画像識別タスクにおけるデータ拡張の最適化の研究をしています。
当インターンでは、広告画像効果推定モデルの精度改善という業務に取り組みました。本記事ではインターン自体の様子と、実際に行った業務内容について報告します。
インターン参加の経緯
私は以下の条件を満たすインターン先を探していました。
長期的なインターンであること (雰囲気や業務の進め方などがより理解できると考えたため)
入社後に行う業務と大差のない業務に携われること
報酬の出るインターンであること
そんな折にTrack Jobでnegociaのインターンシップ募集を見つけ、条件に合致していると考えたため、応募するに至りました。カジュアル面談で会社の説明をしてもらい、後日の技術面接を経て採用していただけることになりました。
negociaインターンの流れ
リモート、出社のどちらでも働くことが出来ますが、初日とランチ会の日を除いて、私は1か月間をほぼリモートで働いていました。朝会 → メンターとのミーティング → 業務 が一日の流れになっています。
朝会
同じプロジェクトの人たちと、”以前やったこと”,”今日やること”,”現在困っていること”の3つを15分程度で共有します。
メンターとのミーティング
インターン生に対してメンターが付いて下さり、メンターの方や、たまに他の人たちと、現在の進捗について話し合います。現在困っていることの解決を手伝ってくださる他、今やっていることに対するさらなる改善案や、今後の展望について建設的な議論を行うことが出来たので、とてもためになる時間でした。(神谷さん、石塚さん、ありがとうございましたm(_ _ )m)
業務
タスクをチケットと呼ばれる小タスクに分解し、各チケットの結果をconfluenceという共同作業用 wiki ツール上に纏めたりなどした後に、メンターの方にレビューをしてもらいます。レビュー後、修正事項があれば修正し、なければ別のチケットに取り掛かるという流れになります。

最初の1,2日は慣れておらず戸惑いましたが、慣れた後は、自分が今何に取り組んでいるのかがすぐに理解でき、マルチタスク作業などもやりやすいなと感じました。
勉強会
社員の方同士で毎日、機械学習に関する勉強会が行われています。インターン生も参加自由なので、興味がある分野があれば参加してみるといいと思います。(英語で書かれたしっかりした参考書の輪読などが行われています)
Input Day
隔週で金曜日に行われており、業務に関係なく自分の勉強したいことを自由に勉強することができる日です。自身は広告に関する知識が0だったので、広告の評価指標にどのようなものがあるのかについて調べたりをしていました。
具体的な業務内容
精度改善するタスク
広告画像の評価を行うモデルの精度改善を目指します。ベースラインとなるモデルは、こちらの論文を参考にしています。
広告の配信金額の日単位平均を広告効果を表す値(以下、rewardと呼びます)として扱い、画像からrewardの順位予測を行います。具体的には、モデルは画像を入力として、1次元のスコアを出力し、そのスコアが高い順に画像を順位付けします。画像のデータセットから抽出できる全ての画像ペアx_i,x_jについて、それらのrewardの大小関係が正しく推測出来れば、全ての画像のrewardの順位を正しく決定できます。よって、モデルには任意の画像ペアx_i,x_jのrewardの大小関係を推論できるように要請します。
学習の方針は以下です
画像ペアx_i,x_jをモデルに入力して得られるスコアf(x_i),f(x_j)から、(x_iのreward) > (x_jのreward) となる確率P_i,jを算出する。
P_i,jを、真の(x_iのreward) > (x_jのreward) となる確率P*_i,jに近づける。すなわち、P_i,jとP*_i,jの不一致度を表す損失関数L(x_i,x_j)を作成し、誤差逆伝搬法によってモデルを最適化する。
P*_i,jはrewardの大小を調べて決定します。
x_iの方がrewardが大きい → P*_i,j = 1
x_iの方がrewardが小さい → P*_i,j = 0
rewardが等しい → P*_i,j = 0.5
また、P_i,jはスコアの差をシグモイド関数に与えて計算し、L(x_i,x_j)としてクロスエントロピー損失を用います。式は以下のようになります。

今回ベースラインとなるモデルは、rewardとして広告の配信金額の日単位平均の代わりにimpression数を採用しています。
(上記の学習手順や、学習に用いられたモデルのアーキテクチャは、奥田さんの記事 に詳しく纏められていますので、気になる方はそちらもご覧ください。)
この手法には以下の2つの課題があると考えました。
真の(x_iのreward) > (x_jのreward)である確率*P_i,jが離散的な値を取る。impression数がほぼ等しい(どちらの広告効果が高いかは定かではない)ペアに対して1または0に確率が決定される。学習データセットに対して極端な推論を行うため、汎化性能が低い可能性がある。
学習データセットに対してデータ拡張を行っていない。データ拡張はモデルの汎化性能向上のために広く用いられている手法であり、本タスクにおいても導入することで、汎化性能が向上する可能性がある。
そこで、ソフトな確率ラベルの作成と、本タスクに適したデータ拡張の実装に取り組みました。
ソフトな確率ラベルの作成
二枚の画像のうち、どちらの方がimpression数が大きいかを表すP*_i,jですが、以前は下のように決定されていました。

このような真の確率の定義では、例えば、impressionが(100,100)と(100,99)の2つのペアがあった場合に、確率は0.5と1になります。前者と後者はほぼ同じimpression数のペアであるため、この2つのペアで算出される確率を近づけたいです。
そのために新しいP*_i,jの算出方法を提案します。
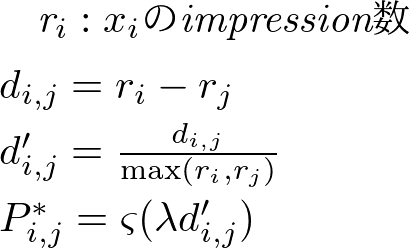
d’は、impression数の差をスケールを考慮して表現したものになります。|d'|が大きければ、確率は1または0に近くなりますが、|d'|が小さい(どちらが優れた広告であるかは、判断しにくい)場合には0.5に近い値になるようにします。3つ目の式のd'の係数λは、シグモイド関数のy=0.5付近のステップの急激さを調節する値です(今回は12を用いました)
(100,100)と(100,99)のペアについてP*_i,jを計算すると、前者は0.5、後者は0.53となり、ほぼ同じ確率になっているのが分かります。
データ拡張の実装
画像を入力とするタスクでは、画像に色変換や幾何変換を加え、元のデータセットには存在しなかった入力を作り出すことでモデルの汎化性能向上を図る、データ拡張がよく用いられています。しかし、今回のタスクでは以下の理由によってデータ拡張を行っていませんでした。
広告画像を扱う関係上、多少の色変換や回転などで予想されるimpression数が大きく異なってきそうである
2枚の画像を比較する方法で学習を行う以上、2枚の画像の条件が同じでなければ正当な判断が出来ない
これらをクリアするために、データ拡張に以下の制約を加えることにしました。
行うデータ拡張は、弱いものに制限する
2枚の画像に対して同一のデータ拡張を施す
同じデータ拡張でも、2枚の画像間で均衡が崩れそうなデータ拡張を行わない
例えば画像の拡大は、画像によっては文字がはみ出たりしてしまい、本来存在した情報が損なわれてしまうので行わないことにしました。
具体的には、色相変換を除いたColorJitter、HorizontalFlip、画像の縮小(0.75~1.0倍、アス比固定)と画像の回転(-3~3度)の3種類を、それぞれ60%、40%、80%の確率でランダムに行われるようにして実装しました。
実験結果

行はデータセット、列は学習条件を表しています。
テストデータセットのknown、unknownはペアの画像がtrainingデータセットに含まれているか否かでテストデータセットを分割したものです。trainとtestでは別の時期の広告を採用することで異なるデータセットにしていますが、広告の性質上、時期が違っていても同じ画像が存在することも多いです。そのため、このような措置を取っています。
表中の数値は、データセット内のすべての2枚の画像ペアに対して、どちらがimpression数が大きいかを正答できた割合を表しています。
考察
test/unknown(未知画像データセット)において、ベースラインと比較して、ソフトラベル導入後は精度が0.024ほど上昇し、さらにデータ拡張によって0.011ほど上昇しました。
今回提案した2つの案が、汎化性能を向上させる効果があることを示唆しています。加えて、ソフトラベル導入後はtest/knownにおいても精度が向上しています。一方で、データ拡張導入後はtest/knownにおいて精度が0.005ほど下がっています。これを解消するための、データ拡張のハイパーパラメーターチューニングが今後の展望です。
業務のまとめ
ソフトなラベルの作成
今回のタスクに適したデータ拡張の実装
により、未知データセットに対する精度を、ベースラインから0.03向上させることが出来ました。
今回実装したのは、モデルのアーキテクチャに依らない部分なので、今後モデルの変更などの改修があっても応用できるのが強みだと考えています。
インターンを通して
学んだこと
negociaで実際に業務を行う過程が参考になりました。タスクを細かく分解することで、マルチタスクが容易になり、結果をまとめてレビューしてもらう過程では、より議論が円滑になるように、出来るだけ見やすく纏めようという意識を持てるようになりました。
また、メンターとのミーティングは、自分が思いつかない改善案や知らない知識などを教えていただけたので、得るものが多かったです。そのアイデアの実現に取り掛かることが実際の業務にも生かせるので、非常に良いインプットの機会だったと感じています。
よかったこと
対面、リモート問わず、コミュニケーションが取りやすかったです。対面では、初日に業務のための環境構築などで困った際に、社員の方がすぐに手伝ってくださりました。リモートでも相談のしやすさは変わらず、slackで困ったことを書き込むと、かなり速くメンションが来て非常に助かりました。
slackにおいては、timesと呼ばれる個人の独り言のようなチャンネルが作られており、そのチャンネルを利用して、社員さん同士で気楽にコミュニケーションが行われているように感じました。私も、”困っているほどじゃないけど少し気になるな”程度のことを書き込んでいると、たまにメンションが来て参考になりました。
slack上での議論や勉強会などに見られるように、エンジニアの人たちの技術向上へのモチベーションが高いように感じました。このような雰囲気は、自身のモチベーションの維持へもよい影響を与えてくれると思います。
悪かったこと・気になったこと
ジョブが混雑する状況が多々あり、計算資源が不足しているなとは感じました。ただ、計算資源を増やすモチベーションが社員の方々にもあるので、今後は改善されていくのではないかと期待しています。
まとめ
メンターの神谷さん、MTGでお世話になった石塚さんはじめ、社員の皆さん1か月間ありがとうございました。自身の研究で得た知識が、広告画像の評価という、普段とは全く違うタスクで生かすことが出来たので良かったです。また、広告画像は普段扱っている画像とかなり様子が異なってくるので、特別なアプローチを考えたりすることは非常に新鮮でした。今回得た経験は、必ず今後も生かせると思っています。
最後に
negociaでのインターンはしっかりと業務に取り組むことが出来、得るものが多いと思います。
インターン等に興味を持った方は、是非 応募フォーム から応募してみてください!