
VRChatの3DアバターでLoRAを作ってみた

こんにちは。NAYUです。
今回の記事は、Stable DiffusionとLoRAを使用して、3Dアバターを追加学習させ、髪型や服装、表情、背景などを自由自在に変えられるイラストを作ってみたという記事です。
特にVRChatやclusterの3Dアバターや、Vtuberが使用している3Dアバターなどに対して使える手法です。アバターの表現の幅を広げることで自分をさらに表現したり、単に楽しんだりすることや、個人Vtuberならサムネイル作成といった活動などに使えるかと思います。また、アバターの衣装を制作されている方にとってもアイデア出しとして有用かと思います。
【注意事項など】
※本記事は主にVRChatのクリエイター向けです。VRChatter以外の方でも同様の手法でできそうですが、理解が難しかったりするかもしれません。VRChat用のアバター以外は動作未確認ですが、アバターの拡張子がVRMならいけるかもしれません。
※アバターの利用規約にもよりますが、原則、二次創作物の公表や学習について、それぞれ著作権者から許諾を得る必要があります。記事で紹介する手法を試す場合は許諾を得てください。
※本記事で使用するアバターの利用については、個別に著作権者から許諾を得ています。
※もし改変アバターを使用して機械学習を行う場合は、改変に使った全てのパーツの著作権者に許可を得るようにしてください。
※著作権者にとって不利益となる利用をしないでください。
※許可なく学習済みモデルを第三者に提供するのはやめましょう。
※本記事で紹介する内容によって生じた損害などに対して、私は一切の責任を持ちません。自己責任、自己判断でお願いします。
活動の背景と目的
本活動の目的は、画像生成AIにおける3Dアバターの追加学習の手法を確立し、将来的に一次創作や二次創作を支援することです。現在、多くの人が追加学習の方法を模索していますが、過学習の防止や高い再現度を実現する最適なパラメーターの特定は大きな課題です。特に3Dアバターの追加学習に関するパラメーターを公開している人はほとんどいません。また、メタバースやVtuber時代の到来により、個人が自身を表現するためのアバター文化が急速に発展しています。さらに、画像生成AIのオープンソース化により、誰でも指定した画像を生成することが可能になりました。これらの背景から、画像生成AIを使用することで、所有する3Dアバターの表現の幅を広げることができ、個性的で独自性のあるアバター画像を生成できるようになりました。したがって、画像生成AIにおける3Dアバターの追加学習の手法を確立することで、主に将来的に所有するアバターの表現力を向上させ、自己表現や創作を支援することを目標としています。
生成した画像



本記事で紹介する手法で、夏っぽい画像を生成しました。背景や服装、髪型を自由に変えることができています。一次創作や二次創作として十分使えるレベルだと思います。トーンは少し調整しています。
今回は有坂様の「Nayu」という3Dアバターを使用させていただきました。
使用スペック(3種類試しました)
パターン1:CPU-12th Intel i7, GPU-RTX 3070, メモリ-96GB
パターン2:CPU-13th Intel 79, GPU-RTX 4090, メモリ-64GB
パターン3:Google Colab
課金は必要ですがGoogle Colabでも追加学習と画像生成ができたので、Macや低スペックPCでもできるはずです。今回の記事では、Windowsでの追加学習の手法のみ取り上げていますが、もし需要がありそうだったらMacや低スペックPCで活用できるGoogle Colab等での手法も取り上げます。
ローカル環境はGPUのVRAMが8GB、メモリが32GBあれば十分追加学習はできるかと思います。もしできなかったらコメントなどで教えて下さい。なお、GPUを積んでいないと基本的に学習はできません。
これは余談ですが、RTX4090はRTX3070の3倍の処理速度で動きました。12000ステップで1時間です。速すぎる。
全体の簡単な流れ
※間違っている部分があるかもしれません。コメントで教えていただけると幸いです。
Stable Diffusionを導入する
Kohya GUIを導入する
Unityでアバターに色々なポーズをとらせて学習用画像にする
Stable Diffusionの拡張機能で3で撮った画像にタグ付けをする
Kohya GUIにパラメーターを入力して追加学習モデルを生成
Stable Diffusionに5で生成した追加学習モデルを読み込ませて画像生成
Stable DiffusionやKohyaGUIを導入したことがある人は手順1, 2は不要なので飛ばして下さい。また、ここでは導入については端的に説明します。
1. Stable Diffusionを導入する
まず、以下のリンクをクリックしてPython3.10をインストールしてください。
https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
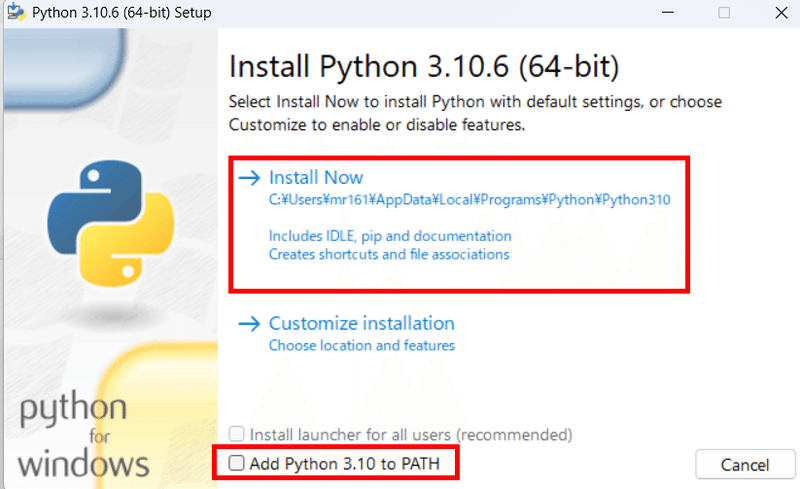
下の画面のようなものが表示されるので、"Add Python to PATH"にチェックを入れて"Install Now"を選択しましょう。
次に以下のURLからgitというツールをインストールします。これはGithubというサービスをCUI(コマンド)で利用するために必要です。セットアップを始めると色々設定項目がありますが、デフォルトの設定のままでも構いません。
次にPowerShellを起動してコマンドを実行できるようにします。ポリシーに変更を加えるので自己責任でお願いします。PowerShellはWindowsのスタートメニューで検索すると出てきます。PowerShellのアイコンを右クリックして「管理者権限で実行」し、以下のコマンドを入力してEnterを押しましょう。警告が出ますが「Y」と入力してEnterを押しましょう。一旦PowerShellを閉じて開きなおしてください。
Set-ExecutionPolicy UnrestrictedいよいよStable Diffusionをインストールします。以下のコマンドを1行ずつ入力してEnterを押して実行してください。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd .\stable-diffusion-webui\
.\webui-user.batしばらく待つと「Running on local URL:」と出てくるので、その後ろのURLをctrlを押しながらクリックしてください。何も起きなければ、URLをコピペしてChromeで開いてください。そうすると、以下のような画面が出てきます。これでStable Diffusionの導入は完了です。

2回目以降、Stable Diffusionを起動する場合はPowerShellに以下のようにコードを入力するか"C:\Users\ユーザー名\stable-diffusion-webui"というフォルダの中にあるwebui-user.batをダブルクリックすれば起動します。
cd .\stable-diffusion-webui\
.\webui-user.bat2.Kohya GUIを導入する
使用するリポジトリはこちらです。本家はCUI(コマンド)だけで動きますが、こちらはGUI(Web UI)で動きます。導入も簡単です。
PowerShellを起動して、以下のコマンドを1行ずつ入力して実行してください。
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
.\setup.batセットアップ中色々、聞かれます。以下のように回答して下さい。
(2024年2月の時点では、確認事項が異なっています。Install kohya_ss gui→Start Kohya_ss GUI in browserを選択してください。)
Kohya_ss GUI setup menu:
1. Install kohya_ss gui
2. (Optional) Install cudann files (avoid unless you really need it)
3. (Optional) Install specific bitsandbytes versions
4. (Optional) Manually configure accelerate
5. (Optional) Start Kohya_ss GUI in browser
6. Quit
Enter your choice: 1 # ここで1を入力してEnter
1. Torch 1 (legacy, no longer supported. Will be removed in v21.9.x)
2. Torch 2 (recommended)
3. Cancel
Enter your choice: 2 # ここで2を入力してEnter上記を入力したらしばらく処理が行われ、また質問されます。以下の順番で回答してください。
- This machine # そのままEnterキーを押す
- No distributed training # そのままEnterを押す
- NO # NOと入力してEnterを押す
- NO
- NO
- all # allと入力してEnterを押す
- fp16 # 1を入力してEnterを押す
# すべて回答を終えると、またメニューが出てくるのでQuit
Kohya_ss GUI setup menu:
1. Install kohya_ss gui
2. (Optional) Install cudann files (avoid unless you really need it)
3. (Optional) Install specific bitsandbytes versions
4. (Optional) Manually configure accelerate
5. (Optional) Start Kohya_ss GUI in browser
6. Quit
Enter your choice: 6 # ここで6を入力してEnter処理が終わったら、以下のコードを入力して実行してください。
.\gui.batしばらく待つと「Running on local URL:」と出てくるので、その後ろのURLをctrlを押しながらクリックしてください。何も起きなければ、URLをコピペしてChromeで開いてください。そうすると、以下のようなUIが出てきます。これでKohya GUIの導入は完了です。
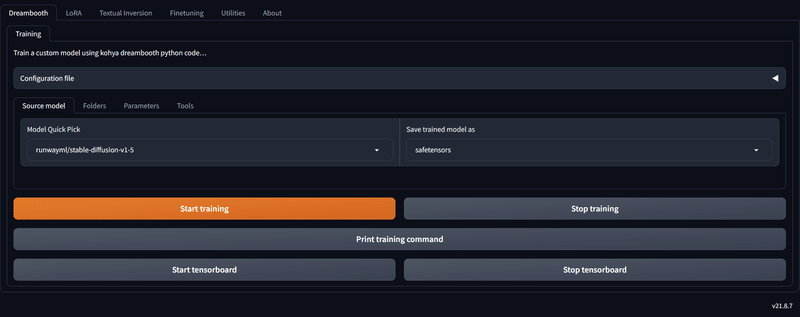
2回目以降、Kohya GUIを起動する場合はPowerShellに以下のようにコードを入力するか、"C:\Users\ユーザー名\kohya_ss\"というフォルダの中にあるgui.batをダブルクリックすれば起動します。
cd .\kohya_ss
.\gui.bat3.Unityでアバターに色々なポーズをとらせて学習用画像にする
このセクションでは、Unityで3Dアバターを撮影する方法について解説します。
そもそも、Unityを使わずともVRChatユーザーの方はMMDワールドで躍ったり、ワールドで自撮りしたりすればいいと考える方もいらっしゃるとは思います。私はその方法で2時間くらいかけて学習用画像を撮りましたが、意外と大変でしたし破綻した画像ばかり生成されました。そもそも、いい画像を撮るのは難しいし、服が貫通したりしていると学習結果が悪くなります。また、フィルターで背景を除去しないと写真を撮った時の背景が中途半端に出力されるようになります。なので、私はUnityを使って学習用の画像を作ることをおすすめします。
※特にUnityを触ったことがない人やVRChatをやっていない人、Vroidアバターを持っている人は3teneやVroid Studioなどの、ポーズを取らせて撮影できるアプリケーションを使った方が楽かもしれません。特にVroidアバターならVroid Studioで写真を撮った方がいいでしょう。規約を確認したうえで使ってください。ただ、ポーズや表情のバリエーションが少なかったり、アバターが若干ガビガビしたり、拡張性が低かったりするので、私はUnityを使っています。
①必要なツール一覧
必要なツールやアセットは以下のリストの通りです。下線が入っている項目はクリックするとインストールできます。上から順にインストールする必要があります。
※一気に全部インストールしないでください。セットアップが完了したら次のツールをインストールするようにしてください。
使用ツールとアセット
・Unity Hub
・Unity本体 2019.4.31f1
・UniVRM v0.99.0
・Unity Recorder
・3Dモデル
・【ポーズ詰め合わせ】Unity Humanoid AnimationClip - PoseCollection
②Unity HubとUnity
まだUnityを触っていないという人は、Unity Hubをインストールしてセットアップを完了してからUnity 2019.4.31f1をインストールしてください。Unity Hubをインストールした後は「Create account」からアカウントを作成してください。
ライセンスについて確認を求められたら、「Agree and get personal edition License」を選択してください。

この後に何かしらのUnityバージョンのインストールを求められることがありますが、ここでは「Skip Installation」を選択します。
Unity 2019.4.31f1はリンク先の「Install this version with Unity Hub」の"Unity Hub"をクリックするとインストールできます。
追加するモジュールの画面が出てきますが、その際に「Microsoft Visual Studio Community 2019」「日本語」「Documentation」にチェックを入れておきましょう。他のモジュールはあってもなくても構いません。セットアップが完了したら、Unity Hubは閉じても大丈夫です。

③UniVRM v0.99.0
リンク先からダウンロードし、拡張子が「.unitypackage」のものをダブルクリックすればUnityにインポートできます。
UniVRM v0.99.0は、VRM形式のアバターをUnityで扱えるように変換するために使います。導入後にVRMファイルを取り込むと、自動的にプレハブというものに変換してくれます。VRChat用に開発されているアバターだと、既にプレハブ化されていると思うので、基本的にインストール不要だと思います。
④Unity Recorder
Unity RecorderはUnity内のカメラを使用し再生シーン上の動画・静画をキャプチャし保存してくれるアセットになります。導入はまず、Unityの上部の「Windows」から「Package Manager」を選択します。
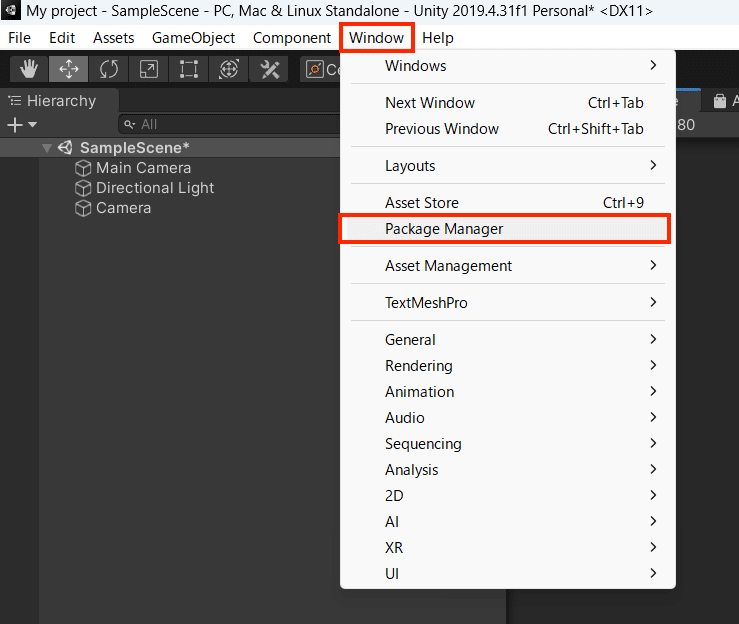
次に、Unity Registryに切り替え、表示されたリスト一覧から「Recorder」を検索し、「Install」を選択します。これで導入が完了しました。
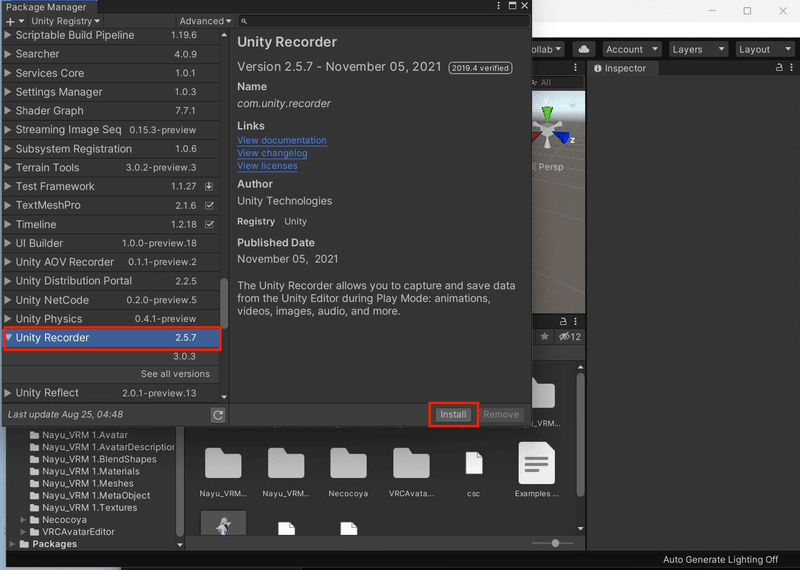
Unity Recorderの設定をします。「Window」→「General」→「Recorder」→「Recorder Window」を選択して、Unity Recorderのウインドウを表示してください。
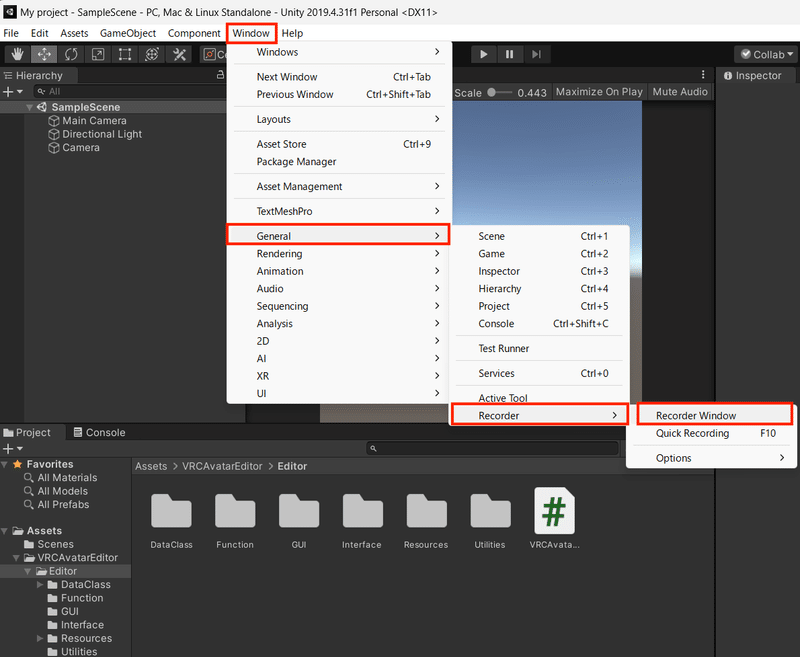
次に、再生画面の解像度を1080×1080などに設定し、Unity Recorderの「+ADD Recorder」→「Image Sequence」を選択します。

以下のような画面が出てくるので、画像のように設定してください。なお、撮影した画像は画面下の「Output File」の「Path」に記載されたディレクトリに出力されます。

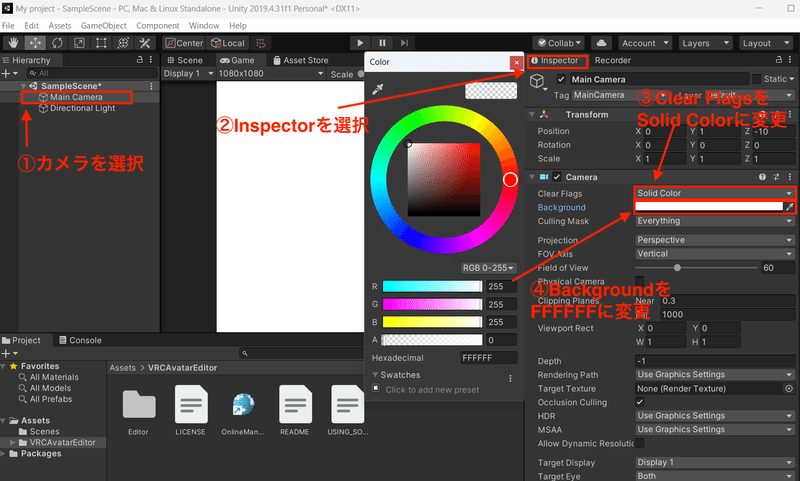
最後に、ヒエラルキーでカメラを選択し、インスペクターから「Camera」の「Clear Flags」を「Solid Color」に変更し、「Background」を「FFFFFF」に変更します。これで、Unity Recorderの下準備は完了です。
⑥3Dモデルの読み込み
3DアバターはVRChat用のアバターの場合、「.unitypackage」のファイルをダブルクリックして読み込み、アバターをヒエラルキーに持っていくだけです。
一方で、VRMファイルの場合はVRMファイルをWindowsのエクスプローラーからUnityのAssetsフォルダーにドラッグアンドドロップして読み込んでください。UniVRMを既に導入しているので自動的にUnityで扱えるように変換されます。その後は、生成されたプレハブ(アバター)をヒエラルキーに持っていくだけです。

⑦AnimationClipの導入
アバターにポーズを取らせるためのアニメーションファイルを用意します。ここでは、例として以下のアニメーションファイルを使用していますが、他のものでも構いません。こちらは、分かりやすいマニュアルが付属しており、無料版ファイルも沢山含まれているのでおすすめです。なお、ダウンロードするにはBoothのアカウントを作成する必要があります。
ポーズの取らせ方については、上記の商品に同梱するマニュアルを読んでいただけたら分かりやすいかと思います。マニュアルの「020_基本的な使い方.html」に詳細に記載されています。
簡単に説明すると、まずヒエラルキーのアバターを選択してインスペクター(右側の領域)を出し、商品のアニメーターコントローラーをアバターの「Animator」の「Controller」にドラッグしてアタッチします。
※アニメーターコントローラーは四角のアイコンです。拡張子は「.control」。三角のアイコンではありません。

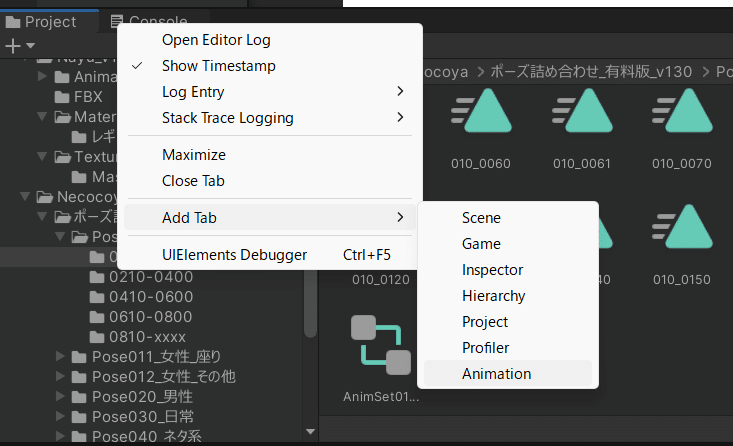
次に、「Project」を右クリックし「Add Tab」→「Animation」を選択して、アニメーションタブを表示します。
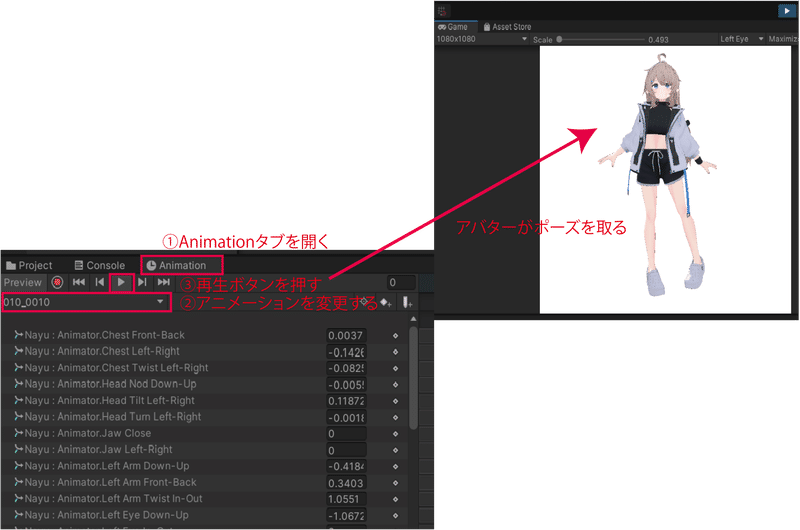
アニメーションタブを開き、アニメーション欄をクリックしてアニメーションを変更し、再生ボタンを押せばアバターがポーズを取ります。
基本的に他の商品のアニメーションファイルでも同様の方法でアバターにポーズを取らせることができます。
⑧写真を撮る
デフォルトだとカメラにアバターが映っていないのでカメラの位置を変える必要があります。カメラの位置を変えるには、Sceneモードになっていることを確認して、Hierachyのカメラを選択し、インスペクターの「Transform」の「Position」をアバターの位置に合わせましょう。また、カメラのアングルは豊富な方がいいので、正面だけでなく様々な角度から撮るようにしましょう。
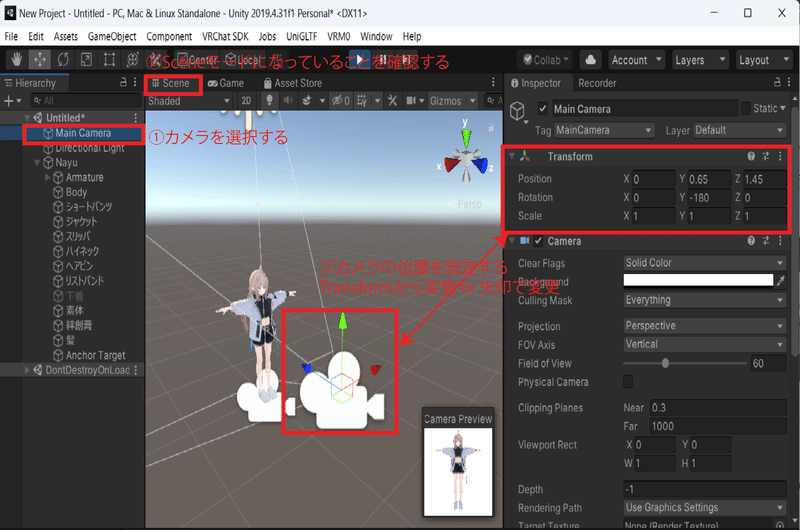
あと、アバターの表情が変えられるものは大抵、ヒエラルキーの「Body」などを選択して、インスペクターの「Blendshapes」をいじれば、Unity上でも表情を変更できます。表情は色々変えてAIに学習させた方が偏らないので、変えることを意識して撮影してください。

撮影方法についてですが、画面上部の再生ボタンを押し、⑦で解説したようにアバターのアニメーションを変えつつ、表情やカメラのアングルを変え、Unity Recorderの赤い再生ボタンを押してアバターの画像を撮ります。

説明が難しいので、動画にしました。分かりにくかったらすみません。画像の出力先は、④Unity Recorderで説明した通りです。
★撮影時に押さえておくべきポイント
・画像の背景は白色にする。
・画像は80枚程度用意する。
・服が貫通しているなど変な画像は省く。
・座っているポーズやジャンプしているポーズは撮影しない。
・表情は変える。
・画像の解像度は高めにしておく。(1024*1024)
・服を着ていない状態のアバターも撮る。
色んな背景で撮影すると良いというサイトがありましたが、私の場合は全くいい画像が生成できませんでした。中途半端に学習時の背景も出力されてしまいました。また、画像の枚数は10枚程度の方がいい結果が出せたというサイトがありましたが、80枚撮った方がいい結果が出せました。そもそも一般的な話ですが、学習枚数を増やせば過学習を防ぐことにもつながります。あと、座ったポーズを含めた場合と含めなかった場合では、前者は100枚生成すると32枚破綻した画像が生成されたのに対して、後者は18枚しか破綻した画像は生成されませんでした。表情については、表情を変えなかった場合だとデフォルトの表情をしたアバターの画像ばかり生成されるようになりました。表情が異なる画像を学習させると、その問題は解決しました。
上記は私の試行錯誤した結果、分かったことになります。必ず正しいというわけではありません。たまたまだったり、間違っている可能性はあります。
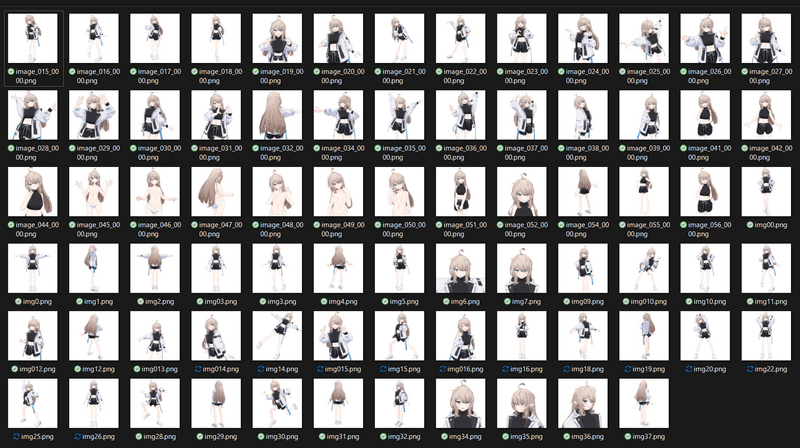
撮影した学習用画像のデータセットはこんな感じです。上半身と全身を多めに、裸を少しといった感じで約80枚撮っています。
以上で、学習用画像の撮影方法についての解説を終わります。お疲れ様でした!
4.学習用画像にタグ付けをする
このセクションでは、Stable Diffusionの拡張機能を使って学習用画像にタグ付けを行う方法について紹介します。
使用する拡張機能は、TaggerとDataset Tag Editorです。Taggerはタグ付けを複数の画像に対して自動で行うために使います。Dataset Tag EditorはTaggerによってタグ付けされたものから、不要なタグなどを除去したりするために使います。
①拡張機能のインストール
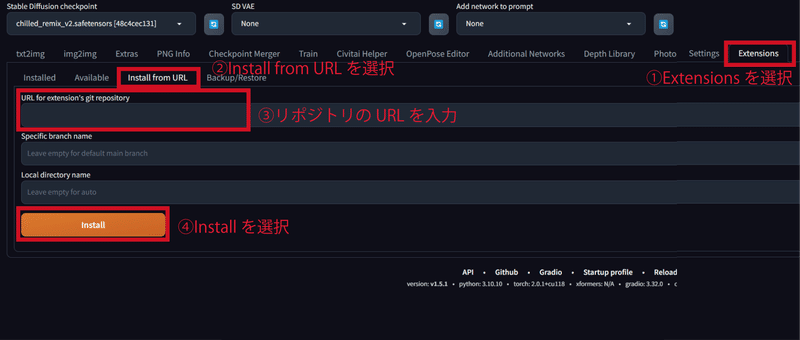
まずStable Diffusionを起動して「Extensions」のタブを選択し、「Install fron URL」を選択します。その下に拡張機能のリポジトリのURLを入力するところがあるので、「https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git」を入力して、「Install」を選択します。これでTaggerのインストールが完了しました。
同様に「https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git」を入力して、「Install」を選択します。これでDataset Tag Editorのインストールが完了しました。
拡張機能のインストール後は、Stable Diffusionを再起動するか、「Install fron URL」の左側にある「Installed」から「Apply and restart UI」を選択して拡張機能を適用してください。
②Taggerでタグ付けを行う
拡張機能の適用後、まずはTaggerで画像にタグ付けを行います。「txt2img, img2img,…」などの並びに「Tagger」があるので選択してください。そして、以下の画像のように設定してください。なお丸番号が、行う順番となるので注意してください。トリガーワードについて補足すると、scs girlなど学習に使われにくいタグを使うことが推奨されています。もし、タグをcat girlなどにしてしまうとAIが正しく学習できない可能性があります。

③Dataset Tag Editorでタグを削除する
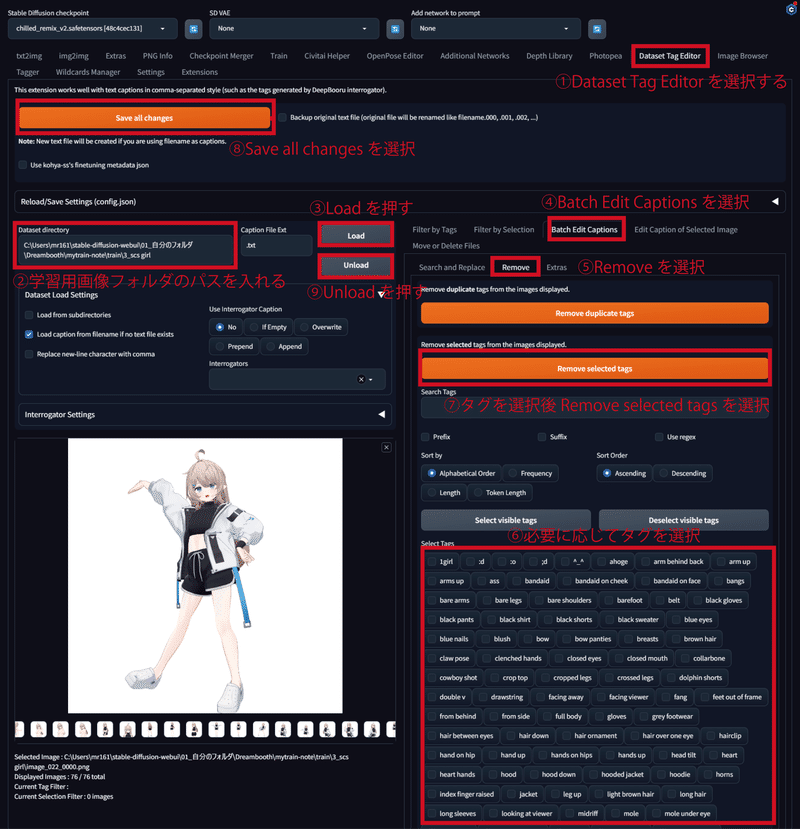
「txt2img, img2img,…」などの並びに「Dataset Tag Editor」があるので選択してください。そして、以下の画像のように設定してください。なお丸番号①から⑨が、行う順番となるので注意してください。こっちは設定項目が多く複雑です。お間違えのないように気をつけてください。
⑥の「必要に応じてタグを選択」について補足します。学習させたいものを選択して削除するようにしてください。直感とは逆なのでややこしいかもですが、単純です。学習させたいものを選択してください。
例えば、学習させたい顔つき、アホ毛、瞳の色に関する単語は選択して削除するようにし、学習させたくないポーズや画角、髪型、開いた口や笑顔、一人であること、背景、今着ている服については選択せずに残すようにします。
選択せずに残したタグの例
scs girl, 1girl, black shorts, solo, long hair, jacket, shorts, white footwear, white jacket, short shorts, full body, open clothes, open jacket, navel, shirt, white background, black shirt, simple background, midriff, long sleeves, crop top, standing, open mouth, very long hair, bangs, hood, hooded jacket, puffy sleeves, hood down, drawstring, puffy long sleeves, shoes
以上で、タグ付けの解説を終わります。お疲れ様でした!次はいよいよ学習に入ります。
5.Kohya GUIにパラメーターを入力して追加学習モデルを生成
このセクションでは、Kohya GUIを使って追加学習モデル(LoRA)を生成する方法について紹介します。
最近はKohya GUIのUIが大きく変わったりしているので、バージョンによっては同じUIではないかもしれません。
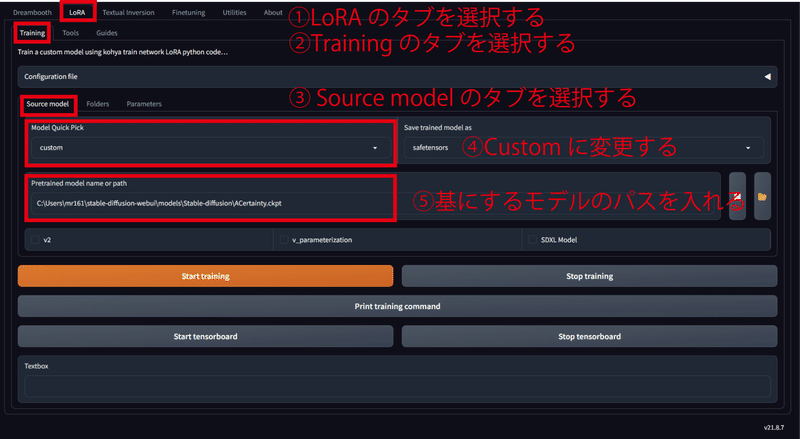
今回使うのは「LoRA」のタブの「Training」タブだけ使います。設定するのは「Training」タブの中の「Source model」、「Folders」、「Parameters」の3つです。
まずは、「Source model」の設定を以下の画像のように行ってください。⑤の基にするモデルについてですが、何種類か試行したところACertaintyがよさげでした。モデルのリンクを貼っておきます。
https://huggingface.co/JosephusCheung/ACertainty/resolve/main/ACertainty.ckpt
ここで、フォルダパスについて整理します。例として、以下の画像のようなフォルダ階層を作っておくと分かりやすくて良いです。学習用画像は3_scs girlに格納してください。フォルダ名は「リピート回数_トリガーワード」という感じでつけてください。リピート回数は生成画像の出来栄えを見て、調整していく必要があります。今回は例として3にしています。(なお、本当はキャプションを用意しているのでフォルダに付けたトリガーワードは無視されます)
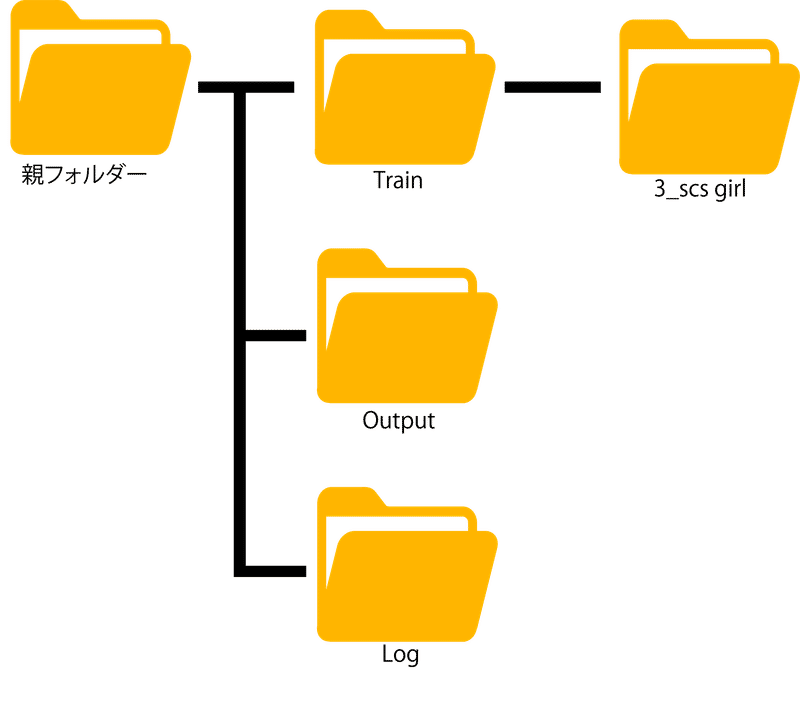
次に、「Folders」を選択して学習用画像のフォルダパスなどを入力していきます。以下の画像を参考にして、それぞれのフォルダパスを入力してください。ややこしいのは②の学習用画像フォルダのパスだと思います。学習用画像が格納されている3_scs girlではなく、その前のTrainというフォルダを指定しなければなりません。なお、LoRAを作るときは正則化画像を用意すると良いというサイトがありますが、特定のキャラクターを生成したいときは不要です。Kohya氏のGithubに書かれていますし、実際ない方がキャラクターの再現度が高かったです。

最後に「Parameters」を選択して学習のパラメーターを設定し、学習を開始します。以下の2枚の画像のように設定してください。赤枠で囲っているところが、変更したところです。なお、アバターによってパラメーターを若干変える必要はあるかもしれません。許諾を得た他のアバターでも試しましたが、そこそこいい感じにできました。パラメーターを入力し終えたら、「Start training」を選択して学習を開始してください。

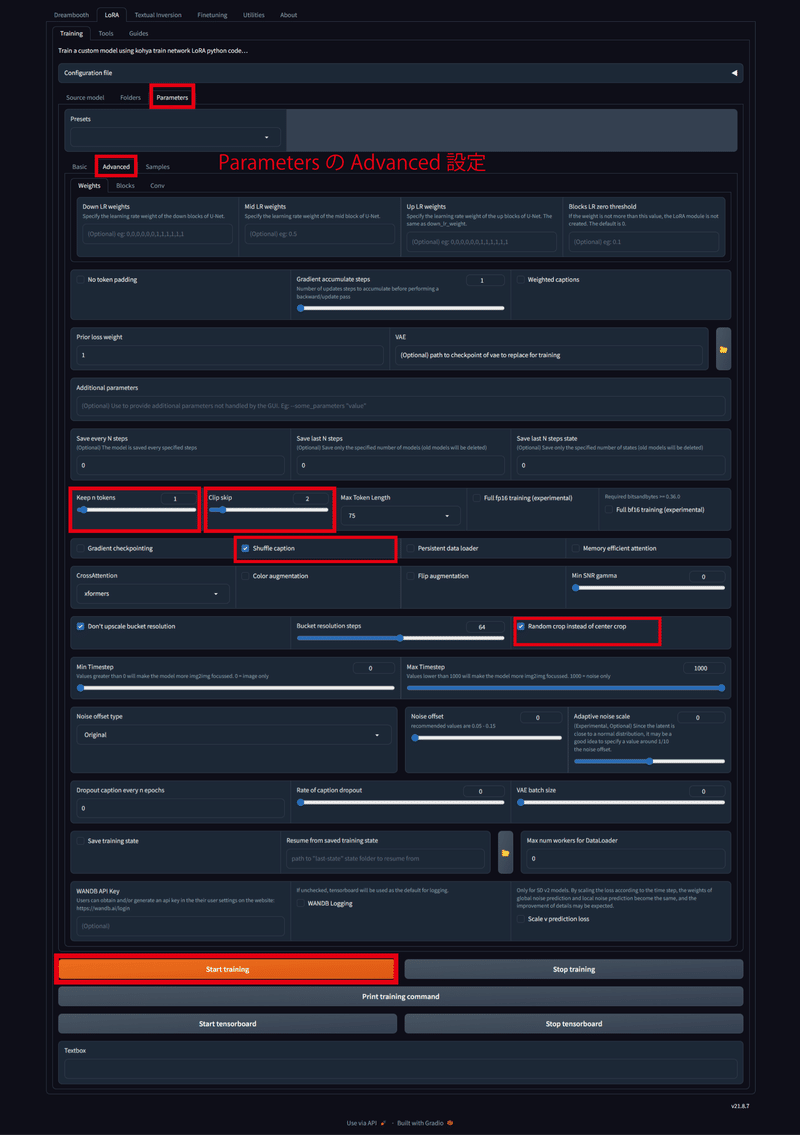
各パラメータについて解説されている記事があったので載せておきます。
以上で、追加学習モデルを生成する方法の解説を終わります。お疲れ様でした!
6.Stable Diffusionに生成した追加学習モデルを読み込ませて画像を生成する
このセクションでは、Stable DiffusionでLoRAを適用させて画像を生成する方法について解説します。
①追加学習モデルの配置
まず、生成した追加学習モデルは「5.Kohya GUIにパラメーターを入力して追加学習モデルを生成」で設定した「Folders」タブの「Output Folder」のパスに出力されるので、生成した追加学習モデルを「/stable-diffusion-webui/models/Lora」にコピーして配置します。この記事の通りにパラメーターを設定していると、20個ぐらいモデルがあると思いますが、とりあえず全部コピーして配置しましょう。
②生成に使うモデルの配置
次に、生成に使うイラスト系のモデルをダウンロードします。今回はAnything v4を使用します。以下のサイトからダウンロードできます。
ダウンロードしたら「/stable-diffusion-webui/models/Stable-diffusion」に格納します。なお、アバターの再現度に影響するので、再現度が低かったらモデルを変えてみるといいかもしれません。以下にモデルを紹介されているリンクを貼っておきます。
③VAEの配置
VAEを使わずに生成すると色が薄い画像が生成されることがあります。それを防ぐために使用します。参考までにVAEについて紹介しているサイトを載せておきます。ダウンロードしたら、「/stable-diffusion-webui/models/VAE」に格納します。
④画像を生成する
Stable Diffusionを起動してGenerateボタンの下にある花札マーク(🎴)をクリックして「Lora」の適用画面を出し「Refresh」をクリックします。すると、自分が生成したモデルが表示されるので選択します。選択すると、プロンプトに<lora:LoRAの名前:1>が入力されます。数字の部分がLoRAの適用強度となります。デフォルトの1だと画像が破綻しやすいので0.4~0.7に設定しましょう。設定後、花札マーク(🎴)をもう一度クリックするとLoRAの適用画面が閉じます。

追加学習した特徴を呼び出すために、トリガーワードをプロンプトに記述します。本記事では,「scs girl」をトリガーワードとして使っています。<lora:LoRAの名前:数値>、トリガーワードをプロンプトに加えた状態で「Generate」をクリックするとLoRAを反映した画像を生成できます。また、本記事の通りにパラメーターを入力すると20個の追加学習モデルができます。それぞれ出来栄えが若干異なるので、よさそうなモデルを、画像生成しながら見極めましょう。
今回生成した画像はこちらです。

プロンプトのベースは以下のような感じです。プロンプトによっては、大きく品質が変わるので、低クオリティな画像が出てきても直ぐにモデルが悪いと判断しないようにしましょう。なお、著作権的に特定のイラストレーター等の名前を入力して生成することはやめましょう。
プロンプト:(best quality, masterpiece:1.2), ((best quality)),scs girl, full body, super fine illustration, an extremely cute and beautiful scs girl, highly detailed beautiful face and eyes, beautiful hair, solo, dynamic angle,(school uniform1.3), upper body, (masterpiece:1.5), (best quality:1.2), (looking at viewer:1.2), (cityscape:1.2),<lora:Nayu-000007:0.7>,short hair,
ネガティブプロンプト:flat color, flat shading, retro style, poor quality, bad face, bad fingers, bad anatomy, missing fingers, low res, cropped, signature, watermark, username, artist name, text, white background, simple background, jacket,hairband, hair ornaments, bandaid, long hair,
Stable Diffusionの基本的な使い方については、こちらの記事を参照してください。
以上で、LoRAを適用した画像を生成する方法についての解説を終わります。お疲れ様でした!
今後の展望
今回解説したのは、1系におけるLoRAの作り方です。しかし、1系にはNovelAIのデータが使われている可能性のあるモデルが非常に多いです。Anything等は法的に使用するのは問題ないと考えられていますが、技術的にNovelAIのデータを組み込むことが難しいとされる、最近登場した2系やSDXLを用いたLoRAを作る方法を研究したいと考えています。
また今回の手法では、アバターが身に着けている細かい物(髪飾りなど)を再現することが困難であることを感じています。技術的には再現できそうなので、改善する方法を模索したいと考えています。
追記:SDXLでLoRAを作成する方法は研究できました。
感想
LoRAの生成を通して、自分で試行錯誤することは非常に重要だと感じました。また、初期の技術だとネット上には誤った情報も多く存在することに気づきました。当時は情報が不足しており、GitHubや多くの情報を参考にしましたが、うまくいかなかったため、自身の仮説を立てて異なる手法や設定を試しました。そして、パラメーターを変えながら実験し、結果への影響を観察し、改善していくことができました。問題に取り組み、失敗から学び、新たなアイデアを試すことで、技術スキルや問題解決能力を向上させることが出来たと思います。
AIはモデル開発段階でクリエイターのリスペクトを欠いていたり、著作権問題があったり、一部の「AI絵師」による問題行動があったりするため、利用が制限される風潮がありますが、注視しながらどういったことに活用できるのか、今後も考えていきたいと思います。
今回の記事を執筆するにあたって、有坂様のNayuというアバターやその他様々なツールを使用させていただきました。制作者の皆様に感謝申し上げます。
本研究を通して、様々な人が自身をより表現しやすくなることに貢献できれば幸いです。
余談ですが、記事の文字数が15000字を超えました。ここまで一度に書いたのは初めてです。長い記事になってしまいましたが、読んでくださってありがとうございました。もし分からないことや記事の誤りなどがありましたら、コメントかXのDMで気軽に教えてくださると幸いです。
編集履歴
2023年11月 拡張機能の「Tagger」のURLを修正しました。
2024年2月17日 法律を研究されている方にご相談させていただき、一部追記いたしました。ありがとうございます。
この記事が気に入ったらサポートをしてみませんか?