
PythonでKickstarterの成功/失敗分析

財布とかカバンとかの日用品をkickstarterで買うことにハマっておりまして。
こんな分析をしてみました。
このnoteのやり方編です。
こんな方におすすめ
・マーケターでプログラミングを勉強中の方
・エクセルではできない分析手法に興味がある方
・Pythonを学習し始めて、基礎的なことは理解して、何か面白いことできないかな〜と思っておられる方
このnoteできるようになること
このあとは、下記のようなアウトプットを出してます。

pandas-profiling、plotly、seaborn、scikit-learnを使用してます。
また、イカしたアウトプットのためにdtreeviz、textblob、wordcloudというライブラリも使ってます。これが使えると会社で少しイキれるかもです。
準備
分析環境の準備
まず、分析環境の構築です。分析には、「Jupyter Notebook」を使います。コチラのnoteの前半の無料部分の「◆まず、環境の準備です」をご覧ください。
ライブラリのimport
#使用するライブラリのimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#seaborn色の設定
sns.set_style('whitegrid')
#matplotlibをインライン表示
%matplotlib inlineデータの取り込み
#データの取りこみ
df = pd.read_csv("/[あなたのディレクトリ]/ks-projects-201801.csv")
#行と列の確認
df.shape#head確認
df.head()欠損値の確認
#欠損値の確認と前処理
import missingno as msno
#描画して欠損値を視覚的に確認
check_MV = msno.nullity_sort(df)
msno.matrix(check_MV, color=(0.10, 0.10, 0.80))
欠損値は少ないデータでした。usd pledged列が欠損してそうです。
#欠損値の集計
df.isnull().sum()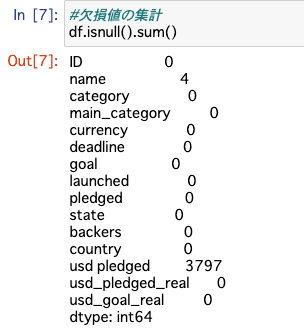
name列の一部、欠損値がありました。それぞれ処理します。
#nameの欠損値はunknownに
df.name =df.name.fillna("unknown")
#usd pledgedは使わないので削除
df = df.drop(["usd pledged"],axis=1)データの前処理
#日付データの列をto_datetimeする
df.deadline = pd.to_datetime(df.deadline)
df.launched = pd.to_datetime(df.launched)
#launchedを日付だけにする
df.launched= df.launched.dt.date
#launchedのデータを日付だけにしたことで、objectに戻っちゃったので、再度to_datetimeする
df.launched = pd.to_datetime(df.launched)前菜🥗データの概観
こちらの書籍で紹介されていた、こちらのライブラリを使います。超絶便利です。
ライブラリのinstall

↑でターミナルを開き、下記を実行してインストールします。
pip install pandas-profilingインストールが上手くいかない時はこの辺りをお試しください。
無事インストールが済んだら、Jupyter Notebookに戻って下記でimport。
#EDA用のライブラリをimport
import pandas_profiling as ppプロファイルを作る
profile = pp.ProfileReport(df, title = "ks-projects-201801")
#出力
profile.to_notebook_iframe()こんな感じで作成が進み、

出力されます。
タブを切り替えたりと色々、心ゆくまでデータを探索ください。

html形式で保存もできます。
profile.to_file("ks-projects-2018.html")募集期間のデータ列を追加する
#deadlineとlaunchedの差分を出す
df["period"] = df.deadline - df.launched
#timedeltaの型からintに変換しておく
df["period_int"] = df.period.dt.days
#確認
df["period_int"].describe()
すごい外れ値があるので処理します。
外れ値の処理
#外れ値の境界を決める
q1 = df["period_int"].quantile(q = 0.25)
#q2 = df["period_int"].quantile(q = 0.50)
q3 = df["period_int"].quantile(q = 0.75)
#第1四分位値 と 第3四分位値 の範囲
iqr = q3 - q1
#上限
upper = q3 + 1.5*iqr
#下限
lower = q1 - 1.5*iqr
#外れ値を外したdfを用意する
df_iqr = df[(df["period_int"] >= lower) & (df["period_int"] <= upper)].dropna()
#確認
df_iqr["period_int"].describe()
箱ひげ図を作る
#箱ひげ図にしてみる
plt.figure(figsize=(10, 10))
sns.boxplot(y="period_int", data = df_iqr)
ヒストグラムを作る
#ヒストグラムの最適な山の数を計算
import math
sturges = lambda n: math.ceil(math.log2(n*2))
bins = sturges(len(df_iqr['period_int']))
#ヒストグラムにする
plt.figure(figsize=(20,10))
sns.histplot(df_iqr.period_int, kde = True, bins = bins)
参考:Pythonのseabornで手軽なのに美しいヒストグラムを作成する方法
箱ひげ図を作る2:usd_goal_real
#外れ値の境界を決める
q1_g = df["usd_goal_real"].quantile(q = 0.25)
q2_g = df["usd_goal_real"].quantile(q = 0.50)
q3_g = df["usd_goal_real"].quantile(q = 0.75)
iqr_g = q3_g - q1_g
upper_g = q3_g + 1.5*iqr_g
lower_g = q1_g - 1.5*iqr_g
#外れ値を外したdfを用意する
df_iqr_goal = df[(df["usd_goal_real"] >= lower_g) & (df["usd_goal_real"] <= upper_g)]#箱ひげ図にしてみる
plt.figure(figsize=(10, 10))
sns.boxplot(y="usd_goal_real", data = df_iqr_goal)
ヒストグラムを作る2:usd_goal_real
#import math
sturges = lambda n: math.ceil(math.log2(n*2))
bins_goal = sturges(len(df_iqr_goal['usd_goal_real']))
#描画
plt.figure(figsize=(20,10))
sns.histplot(df_iqr_goal["usd_goal_real"], kde = True, bins = bins_goal)
項目別の箱ひげ図
#pxのimport
import plotly.express as px
#重そうなのでサンプル抽出する
n = 20000
#集計軸
axis = "main_category" #任意の項目の列名をいれる
box = "period_int"#図示したい列を入れる
#箱ひげ図の生成
fig = px.box(
df_iqr.sample(n=n),
x=axis,
y=box
)
#描画
fig.update_layout(
title=str(axis)+"別の募集期間(n="+ str(n) +")",
width=1500,
height=500,
plot_bgcolor="rgba(0,0,255,0.1)" #お好みで背景色の調整
)
#描画
fig.show()
main_category別の募集期間件数と平均
ライブラリのimport
#plotlyで描画してみる
import plotly.graph_objects as go
from plotly.subplots import make_subplots描画のための準備
#集計軸と集計項目をセット
axis_2 = "main_category"
values = "period_int"
#groupby
df_iqr_GB_mean = df_iqr.groupby(axis_2).mean()
#plotly用にlistを用意
df_iqr_GB_mean_list = df_iqr_GB_mean[values].values.tolist()
df_iqr_GB_unique = df_iqr_GB_mean[values].index.tolist()
#plotly用にlistを用意
df_iqr_GB_count = df_iqr.groupby(axis_2).count()
df_iqr_GB_count_list = df_iqr_GB_count[values].values.tolist()
#plotly用にlistを用意
title = axis_2 + "別の募集期間平均"
labels = list(df_iqr_GB_mean[values].sort_values().index)
line_size = list(round(df_iqr_GB_mean[values].sort_values(),2))
line_text = list(round(df_iqr_GB_mean[values].sort_values(),2))グラフの描画
#描画エリアの用意
fig = make_subplots(
rows=1,
cols=2,
specs=[[{}, {}]],
shared_xaxes=True,
shared_yaxes=False, vertical_spacing=1
)
#グラフの追加
fig.append_trace(
go.Bar(
x=df_iqr_GB_count_list,
y=df_iqr_GB_unique,
marker=dict(
color='rgba(0,0,255,0.5)',
line=dict(
color='rgba(0,0,255,0.5)',
width=1),
),
name='count',
orientation='h'
), 1, 1)
fig.append_trace(
go.Scatter(
x=df_iqr_GB_mean_list,
y=df_iqr_GB_unique,
marker=dict(
color='rgb(0,0,255,0.5)',
line=dict(
color='rgba(0,0,255,0.5)',
width=1),
),
name='ave.',
orientation='h',
), 1, 2)
#グラフタイトルの追加
fig.update_layout(
title=axis_2 + "別" + values + "の件数と募集期間Ave.",
plot_bgcolor="rgba(0,0,255,0.1)"
)
#描画
fig.show()
メイン🥩成功/失敗分析
①successとfailのクロス集計
#goalの外れ値を外したdfの中で、stateの成功と失敗だけ抽出する
df_SandF = df_iqr_goal [(df_iqr_goal["state"] == "successful") | (df_iqr_goal["state"] == "failed")]#集計軸となる列名をセット
analysis_axis = "main_category" #currency, main_category, category or country
#セットした集計軸でgroupbyする
count_SandF = pd.pivot_table(df_SandF,index= analysis_axis, columns="state",values="ID", aggfunc="count")
#成功、失敗、その他の合計を出す
SandF_sum = count_SandF.successful + count_SandF.failed
count_SandF["ttl"] = df_iqr_goal.groupby(by=analysis_axis).size()
count_SandF["others"]= count_SandF.ttl - (count_SandF.successful +count_SandF.failed)
#順番を整える
count_SandF = count_SandF.reindex(columns=["successful","failed","others","ttl"])
#別のdfを用意して、構成比を計算する
ratio_SandF = pd.DataFrame()
ratio_SandF["successful_%"] = round(count_SandF.successful / count_SandF.ttl *100, 2)
ratio_SandF["failed_%"] = round(count_SandF.failed / count_SandF.ttl *100, 2)
ratio_SandF["others_%"] = round(count_SandF.others / count_SandF.ttl *100, 2)
ratio_SandF["ttl_%"] = round(count_SandF.ttl / count_SandF.ttl *100, 2)
#成功の割合で降順にする
ratio_SandF.sort_values("successful_%", inplace = True)#plotly用のlistを用意
success = list(ratio_SandF["successful_%"])
failed = list(ratio_SandF["failed_%"])
others = list(ratio_SandF["others_%"])
names = list(ratio_SandF.columns)
labels = list(ratio_SandF.index)
#グラフの用意
fig = go.Figure(data=[
go.Bar(
name='success',
y=labels,
x=success,
orientation="h",
marker=dict(
color = 'rgba(255, 0, 127, 0.5)',
line =dict(color= 'rgba(255, 0, 127, 1)',
width=3)
)
),
go.Bar(
name='failed',
y=labels,
x=failed,
orientation="h",
marker=dict(
color = 'rgba(58, 0, 183, 0.1)',
line =dict(color='rgba(58, 0, 183, 1)',
width=1)
)
),
go.Bar(
name='other',
y=labels,
x=others,
orientation="h",
marker=dict(
color = 'rgba(64, 68, 77, 0.1)',
line =dict(color='rgba(64, 68, 77, 1)',
width=1)
)
),
])
#表示用件
fig.update_layout(title = str(analysis_axis)+"別の構成比",
barmode='stack',
plot_bgcolor="rgba(0,0,0,0)",
width=900, height=len(df_SandF[analysis_axis].unique())*40
)
#描画
fig.show()
analysis_axis = に列名を指定するとクロス集計ができます(カテゴリ変数のみ)。
②ロジスティック回帰と決定木
ロジスティック回帰_ライブラリのimport
#まず、ロジスティック回帰をする
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression as LRデータの準備
#レコード数が多いのでサンプルを抽出する
sample = 10000
#sampleの件数分を元のdfからランダム抽出する
df_SandF_sample = df_SandF.sample(n=sample).sort_index()
#確認
print(df_SandF_sample.shape)データが多いのでサンプル抽出する
#レコード数が多いのでサンプルを抽出する
sample = 10000
#sampleの件数分を元のdfからランダム抽出する
df_SandF_sample = df_SandF.sample(n=sample).sort_index()
#確認
print(df_SandF_sample.shape)目的変数を用意する
#successfulを1、failedを0にして目的変数にする
Y_LogReg = df_SandF_sample["state"].map(
{
"successful":1,
"failed":0
}
)
#確認
Y_LogReg.head()説明変数を用意する
#説明変数にならなそうな変数の列を削除
df_LogReg = df_SandF_sample.drop(columns = [
"ID",
"name",
"deadline",
"launched",
"pledged",
"state",
"period",
"backers",
"usd_pledged_real",
"usd_goal_real"
])
#確認
df_LogReg.head()
分析実施
#ロジスティクス回帰用にカテゴリ変数をダミー化する
X_LogReg = pd.get_dummies(df_LogReg)
#モデル作成用にデータを分割する
X_train, X_test, y_train, y_test = train_test_split(
X_LogReg,
Y_LogReg,
test_size=0.2,
random_state=1234
)
#インスタンスの作成
clf_LogReg = LR()
#学習
clf_LogReg.fit(X_train, y_train)
#モデルの評価
print("教師データを使った正解率")
print(clf_LogReg.score(X_train, y_train))
print("テストデータを使った正解率")
print(clf_LogReg.score(X_test, y_test))
係数の確認
#モデルの係数を表示する
coeff_LogReg = pd.DataFrame([X_LogReg.columns, clf_LogReg.coef_[0]]).T
#列名を整える
coeff_LogReg.rename(columns={0:"variable",1:"coefficient"}, inplace = True)
#係数の大きさ順に並び替え_top10
coeff_LogReg.sort_values(by = "coefficient", ascending= False).head(10)
決定木_ライブラリのimport
#決定木のライブラリをimport
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
#決定木の可視化用のライブラリをimport
from dtreeviz.trees import dtreeviz
import pydotplus
from IPython.display import Image
from graphviz import Digraph以下、有料にしてますが返金可能なのでお気軽にお楽しみください^-^

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕