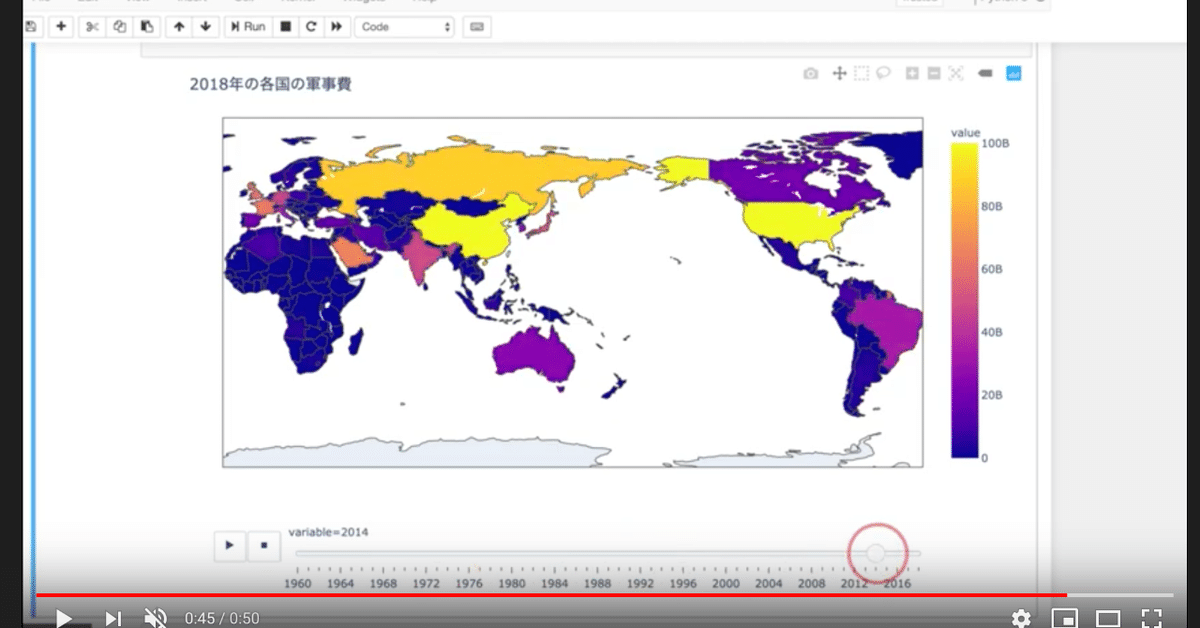
【Python】動くグラフを作ったり、地図に色を付けたり

世界の軍事費のデータをみてたら、「アメリカがダントツ」だったり「近年の中国の追い上げがすごい」ことが分かりました。
このnoteは、↑のnoteでやっているPythonを使った集計・分析の解説でございます。
こんな方におすすめ
・マーケターの方
・特に企業内で、出店戦略、エリアマーケティング、広告・販促戦略、顧客調査などで、データ分析を行う方
・専用ツールがあるが、それが使いづらく、自前で何かできないかな〜、と思ってる方
・Pythonで、何か面白いことできないかな〜と思っている方
このnoteで出来るようになること
「Plotly」というPythonで使えるライブラリを用いて、
↓のようなグラフを作ったり、

↓のような「色付きの地図を動かす」ことをやったりしてます。
ということで、楽しんでいただけたら幸いです。
◆まず、環境の準備です
環境はなんでもいいですが、おすすめは「Jupyter Notebook」です。
今回が初トライな方は、以下の流れで環境を作っちゃいましょう。
※本noteは、「Jupyter notebook」での使用を前提にしております。
・「Anaconda」をインストールして、
・「Jupyter notebook」を立ち上げます。
迷ったときはこちらの記事がわかりやすいので、ご覧ください。
・データ分析で欠かせない!Jupyter Notebookの使い方【初心者向け】
・【Python】Jupyter notebookの基本的な使い方を分かりやすく説明する
◆「plotly」という便利なライブラリをインストールします
Anaconda上で、「Environments」→「▶︎」→「Open Terminal」でターミナル(黒いやつ)を立ち上げます。
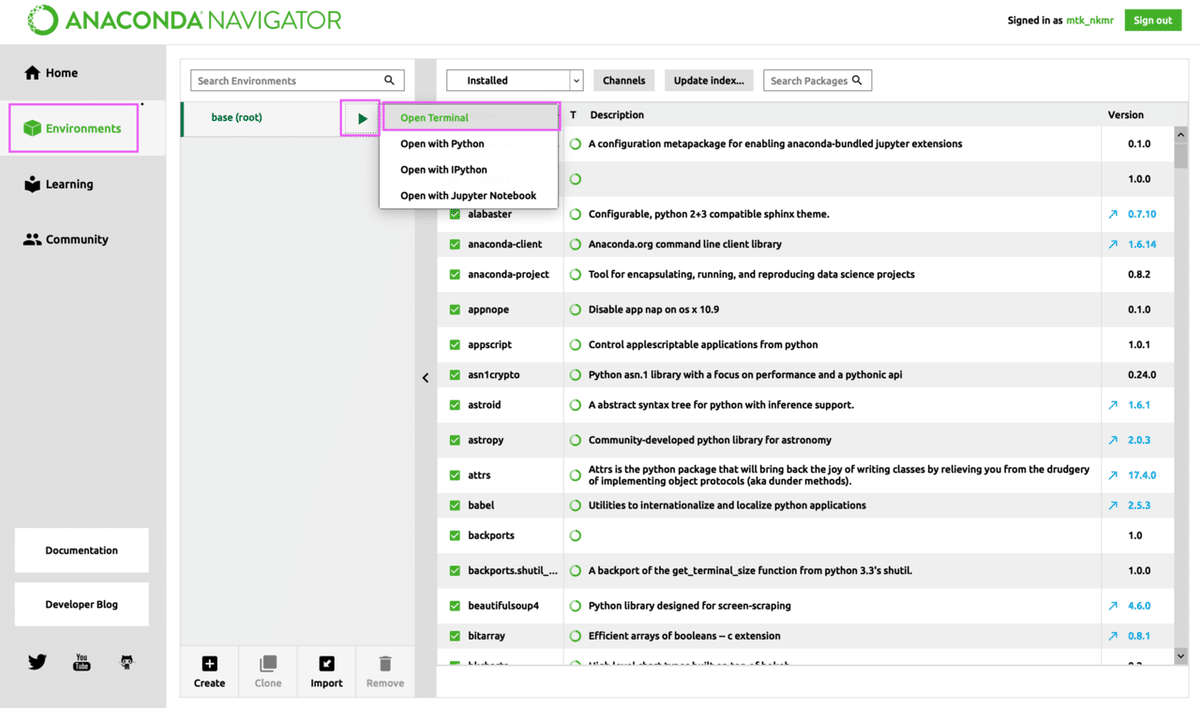
・で、ターミナル上で以下を実行してインストールしておきます。
pip install plotly・インストールが無事済んだら、「Jupyter notebook」に戻って、使うライブラリをimportしておきましょう。
import pandas as pd
import numpy as np
import plotlyこれで準備はバッチリです。うまくいかない時は、以下を参考にしてみてください。
・Jupyterノートブックで気軽にPythonをこね回そう
📊動くグラフを作る
こんな感じのグラフを作ってみます。

・データのダウンロード
ここからデータをダウンロードしてください。
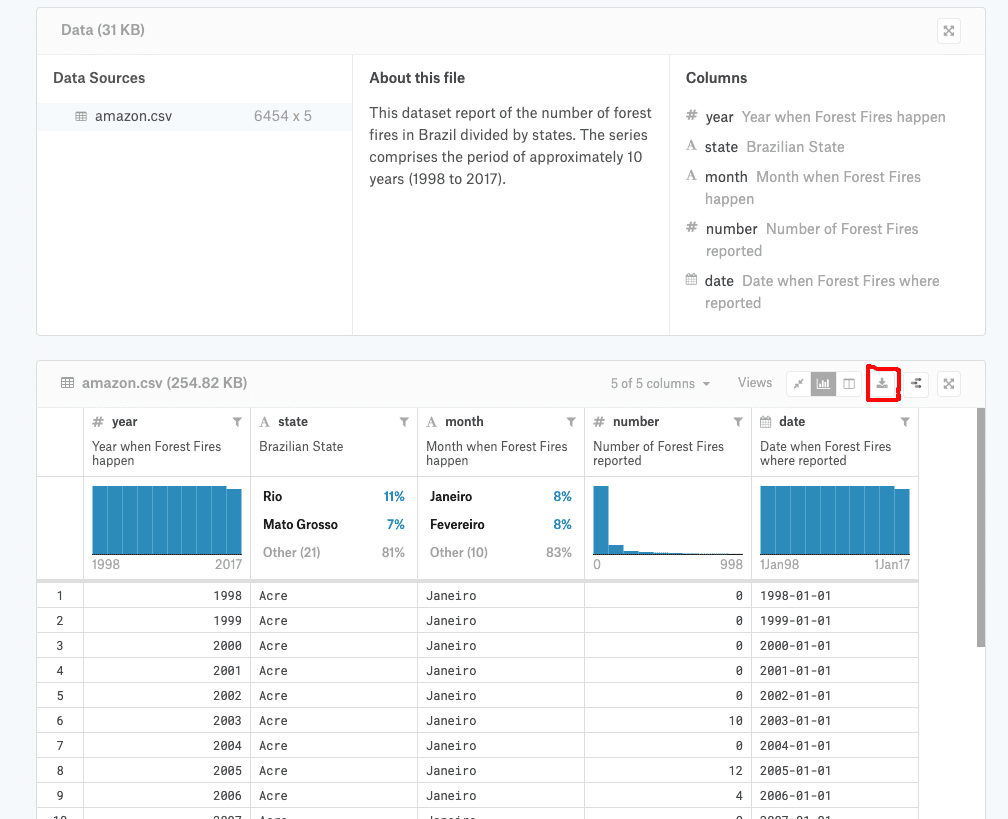
(赤枠のDLボタンを押すとダウンロードできます)
・さくっと、欠損値の有無を確かめます
※この項はご参考です。飛ばしてもらっても問題ありません。
上記のように、ターミナル上で以下のライブラリをインストールして、jupyter notebook上で使えるようにimportします。
pip install missingnoデータフレームの中の欠損値を視覚的にわかりやすい図にしてくれます。
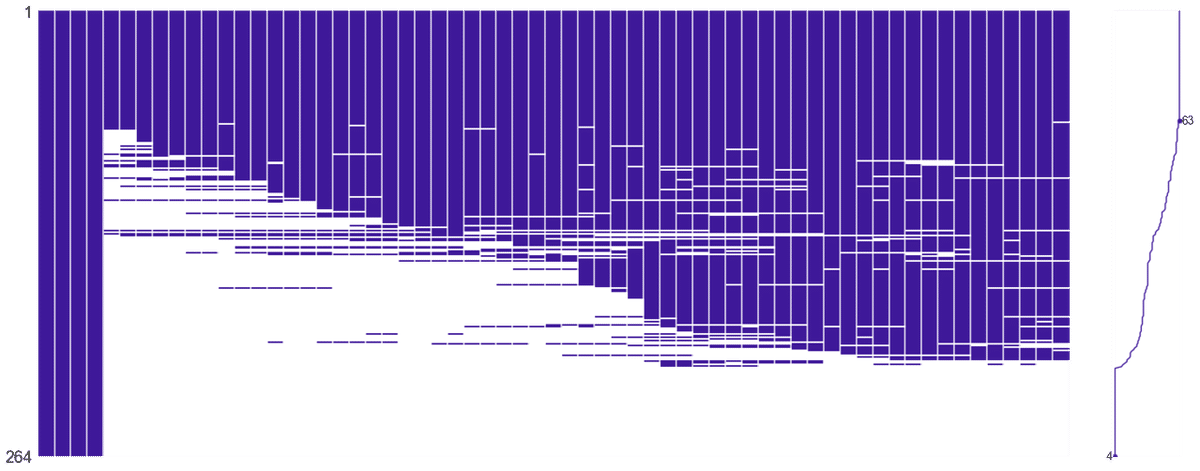
「色がついていないところ」=「データがない」ということになります。
#データの読み込み
df = pd.read_csv("/Users/[データがあるディレクトリ]/Military Expenditure.csv")#ライブラリのインポート
import missingno as msno
#Missing Value(欠損値)のチェック
check_MV = msno.nullity_sort(df, sort="descending")
msno.matrix(check_MV, color=(0.25, 0.1, 0.6))↑のような、グラフが出てきたらOKです。
データフレームのなかで、欠損値がどのくらいあるかをざっくり掴むことができます。
今回は特に欠損値処理は行わないので、このまま進めます。
・日本の軍事費をみてみる🇯🇵
#Japanだけ取り出す
japan = df[df["Name"] == "Japan"]
#不要な列を削除して、列と行を入れ変える
japan_ME = japan.drop(labels=["Name","Code","Type","Indicator Name"], axis=1).transpose()
#列の名前を変えて、indexをリセットする
japan_ME.rename(columns={117:"Military_expenses"}, inplace=True)
japan_ME.reset_index(inplace=True)#確認
japan_ME.head()
#累積の金額を入れておきましょう
japan_ME["accumulate"] = japan_ME.Military_expenses.cumsum(axis = 0)
japan_ME.head()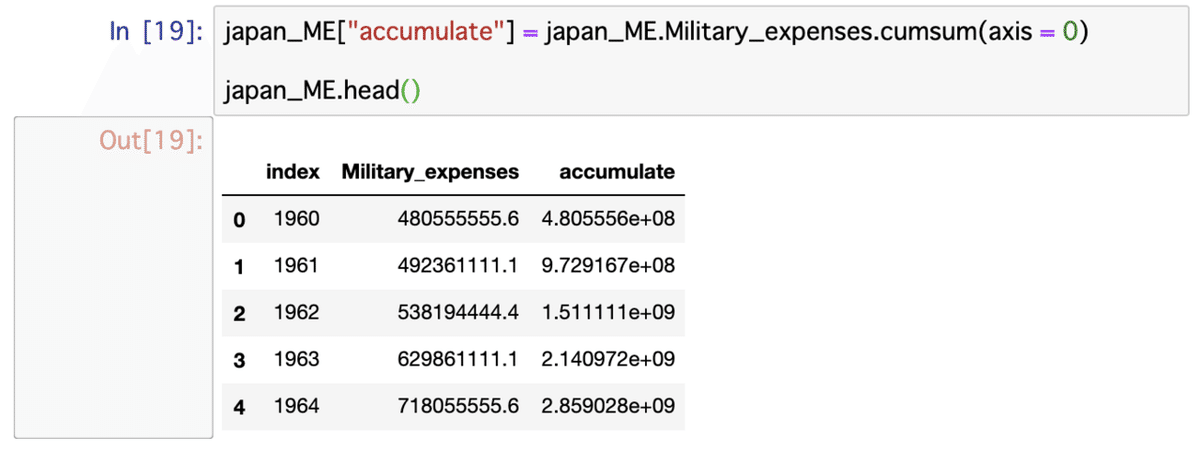
#必要なライブラリをimport
import plotly.graph_objs as go
#日本の各年の軍事費を描画するためのデータ
trace0 = go.Bar(x=japan_ME["index"],y=japan_ME.Military_expenses,name="Military_expenses",yaxis="y1")
#累積を描画するためのデータ
trace1 = go.Scatter(x=japan_ME["index"],y=japan_ME.accumulate,name="accumulate",yaxis="y2",mode='lines+markers')
#二つのデータを一つのlayoutにまとめる
layout = go.Layout(xaxis=dict(title="日本の軍事費(年次と累積)", range=[min(japan_ME["index"]),max(japan_ME["index"])]),
yaxis=dict(title="Military expenses",side="left",showgrid=False, range=[0,max(japan_ME.Military_expenses*1.5)]),
yaxis2=dict(title="accumulate",side="right",overlaying="y",range = [0, max(japan_ME.accumulate*1.5)], showgrid=False))
#描画する
import plotly.offline as offline
offline.init_notebook_mode()
fig = dict(data=[trace0,trace1],layout=layout)
offline.iplot(fig)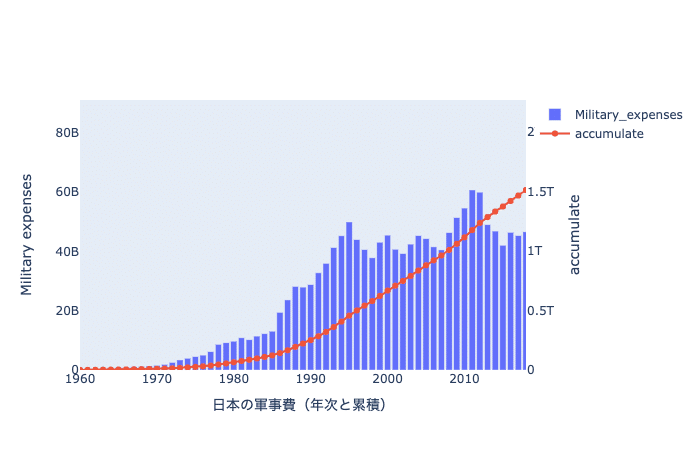
上記のように映し出されたら成功です。マウスオーバーすると、数値が表示されるかと思います。
1987~1989あたり方の伸びがありますね。

日本以外の国でもやってみて、お楽しみにください。
・軍事費TOP3国と日本の違いを感じてみる🇯🇵🇺🇸🇨🇳🇫🇷
軍事費TOP3国を整理して、日本との違いを感じてみようと思います。
Python初学者の方がわかりやすいように、少々刻みながらやっていきます。
#数値データを合算して、sum列にいれる
df["sum"] = df.sum(axis=1, skipna=True, numeric_only=True)
#TypeでCountryだけ取り出す
df_country = df[df["Type"]=="Country"]
#sumで多いもん順にして、そのTOP3だけ取り出す
df_top3 = df_country.sort_values(by="sum", ascending=False).head(3)
#不要な列を削除
df_top3.drop(labels=["Code","Type","Indicator Name","Name"], axis=1, inplace=Tru
#列と行を入れ替えたもので新しくdfを作成
df_top3_transpose = df_top3.transpose()
#列名を整える。sum列は削除。
top3 = df_top3_transpose.rename(columns={249:"United States",38:"China",75:"France"})
top3.drop(labels="sum",axis=0, inplace=True)#確認
top3.head()
TOP3国(アメリカ、中国、フランス)の各年の軍事費が整理されました。これを先ほどの日本のデータと合わせます。
#年をindexにしてデータフレームを結合する
#列名も修正する
top3_and_japan = japan_ME.set_index("index").join(top3).rename(columns={"Military_expenses":"Japan"})
#日本のaccumulate列を削除
top3_and_japan.drop(columns="accumulate", axis=1, inplace=True)
#確認
top3_and_japan.head()
#グラフ描画に合うように、データフレームをmeltします。
data = pd.melt(top3_and_japan.reset_index(), id_vars="index")
#確認
data.head()
#ライブラリのimport
import plotly.express as px
#グラフを描画
fig = px.line(data, x="index", y="value", color="variable", line_group="variable", hover_name="variable",line_shape="spline", render_mode="svg")
fig.show()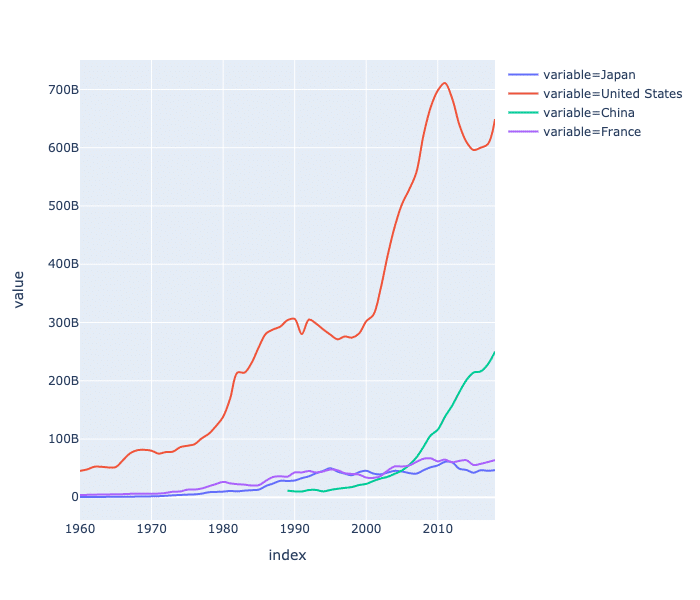
このようになればOKです。先ほどと同じように、マウスオーバーすると値が出てくるかと思います。
「アメリカが常にダントツである」ことや、「中国の近年の追い上げ」を感じます。
・TOP20国を整理して、日本だけ目立たせてみる🇯🇵
グラフの特定の部分だけ、色を変えることができます。ここでは日本のデータだけ色を変えてみます。
まず、TOP20国のデータを整理します。
#sum列の値で降順に並び替えて、TOP20を取得、
ranking_top20 = df_country.sort_values(by="sum", ascending=False).head(20)
#確認
ranking_top20.head()

これをグラフに表してみます。
#アメリカをいれると、他が全然見えない
px.bar(ranking_top20, x= "Name", y="sum", title="1960-2018 ranking without USA")
日本だけを目立たせて見ます。
#アメリカをいれると、他が全然見えない
colors = ['lightslategray'] * 20
colors[5] = 'crimson' #0からスタートして5番目が日本
japan_graph = go.Figure(data = [go.Bar(
x= ranking_top20["Name"],
y= ranking_top20["sum"],
marker_color= colors
)])
japan_graph.update_layout(title = "Japan is No.5")
japan_graph.show()
マウスのカーソルを合わせると、国名とsumの数値が出てくると思います。
・TOP20国の1960〜2018年の累積を動くグラフで表してみる
続いて、動画のように動くグラフを作ってみます

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕