
【前半無料】Pythonでマーケティング〜地図に色を塗り分ける

アマゾンの山火事のデータがあったので、↓のnoteで色々見える化して遊んで見ました。
このnoteでやってることの解説です。
↓のような「コロプレス図」の作り方がメインです。
コロプレス図ってナニ?
エリア別の集計データを使って、地図を色分けして表現・分析する手法。
アメリカの大統領選のときによく使われてますよね。

引用:https://socviz.co/maps.html
こんな方におすすめ
・マーケターの方
・特に企業内で、出店戦略、エリアマーケティング、広告・販促戦略、顧客調査などで、地理情報を扱う方が多い方。
・専用ツールがあるが、それが使いづらく、自前で何かできないかな〜、と思ってる方。
・Pythonを学習し始めて、基礎的なことは理解して、何か面白いことできないかな〜と悩んでいる方。
このnoteで出来るようになること
色々なエリア情報を有効活用して、
日々の生活やお仕事の中で、新しく面白い観点で分析することができます。
あと、基本的なデータの前処理もできるようになります


・エリア別に世帯年収を表して、マーケティングに活かしたり
・各国の成長率を表して、海外進出戦略を考えたり
・都道府県別の男女比を色分けして、婚活に活かしたり etc.

◆まず、環境の準備です
環境はなんでも問題ありませんが、おすすめは「Jupyter Notebook」です。
今回が初トライな方は、以下の流れで環境を作っちゃいましょう。
※本noteは、「Jupyter notebook」での使用を前提にしております。
・「Anaconda」をインストールして、
・「Jupyter notebook」を立ち上げます。
とても簡単ですが、迷ったときはこちらの記事がわかりやすいので、ご覧ください。
・データ分析で欠かせない!Jupyter Notebookの使い方【初心者向け】
・【Python】Jupyter notebookの基本的な使い方を分かりやすく説明する
◆地図でアレコレするために「folium」という便利なライブラリを使います
・Macならターミナル(Windowsならコマンドプロンプト)で、
$ pip install folium・インストールが済んだら、「Jupyter notebook」で、
import folium・加えて、データの取り込みや加工に使うため、おなじみのpandasをimportします。
#データの取り込みや加工で使う
import pandas as pd
from pandas import Series,DataFrameこれで、準備はバッチリです。
上記がうまくいかないときは、以下を参考にしてください。
・Jupyterノートブックで気軽にPythonをこね回そう
また、先にこちらのnoteを読まれた方が、より理解が進むかと思います。
・【前半無料】"Python"でマーケティング〜位置情報を地図上にわかりやすく表す〜
では、スタートです。
まずは、グラフとヒートマップ🔥
肩慣らしに、グラフとヒートマップを作ります。
すでに知ってる方は、↓の「コロプレス図を作ってみる」までスキップください。
◆ライブラリとデータの取り込み
①今回使用するライブラリをimport
#データ分析で使う
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
#データの可視化
import matplotlib.pyplot as plt
import seaborn as sns
#seaborn色の設定
sns.set_style('whitegrid')
#matplotlibをインライン表示
%matplotlib inline②ココからデータをダウンロード

df = pd.read_csv("/Users/(パスを設定してください)/amazon.csv",encoding = "ISO-8859-1")
df.head()
◆前処理
①欠損値のチェック
#データの欠損状態を、まず確かめる
def see_lack(i):
print("◆各カラムの型")
print(i.dtypes)
print("")
print("◆列の中に、一つでも欠損値があるかを確かめる")
print(i.isnull().any())
print("")
print("◆欠損値の数を数える")
print(i.isnull().sum())
print("")
print("◆全部の(行,列)")
print(i.shape)
print("")
print("◆全部が欠損している'行'があるデータを削除したら")
data_drop_allna = i.dropna(how = 'all')
print(data_drop_allna.shape)
print("\n◆一つでも欠損している'行'があるデータを削除したら")
data_dropna = i.dropna()
print(data_dropna.shape)
print("\n◆一つでも欠損している'列'があるデータを削除したら")
data_dropna_columns = i.dropna(axis = 'columns')
print(data_dropna_columns.shape)
print("")see_lack(df)
欠損値はなさそうでした。
②ポルトガル語の月名を英語に変換
#monthを英語表記に変える
month_convert={'Janeiro' : 'January',
"Fevereiro":"Feburary",
"Março":"March",
"Abril":"April",
"Maio" : "May",
"Junho" : "June",
"Julho":"July",
"Agosto":"August",
"Setembro":"September",
"Outubro":"October",
"Novembro" : "November",
"Dezembro":"December"}df["month_en"] = df.month.replace(month_convert)
df.head()
右端の列に追加されてたらOK
③あとで使いやすいように、"year"列の型を int → objectに変換
#year列を、categoryに変更する
df.year = df.year.astype("O")これで、前処理終わりです。
◆年次別の山火事の発生件数をグラフ化
①year列で、groupbyしたデータフレームを作る
#yearを軸にしてgroupby
gb_year =df.groupby("year")
#sumで確認
gb_year.sum()

年次別の発生件数の集計表ができました。
②グラフ化
gb_year.sum().plot(kind="bar",figsize=[10,5], color="r")
2003年、2015-16年当たりが相対的には、多いですね。
---✂︎---ご参考---✂︎---
ちなみに、
・king= の引数を変えるとグラフの種類が変わります
・color= の引数を変えると色が変わります
gb_year.sum().plot(kind="line",figsize=[10,5], color="b")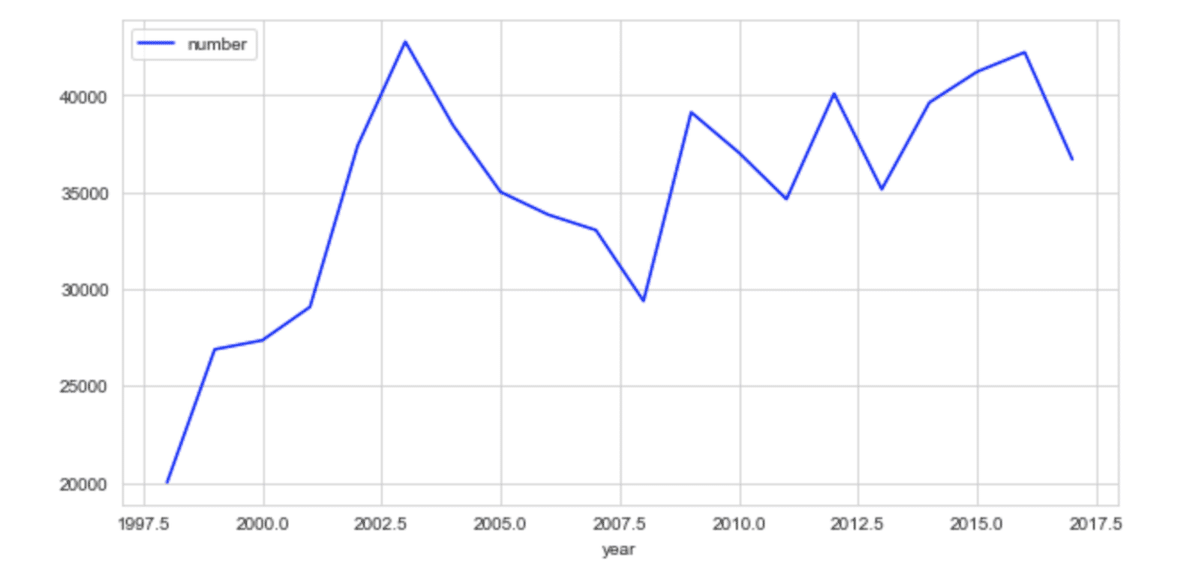
gb_year.sum().plot(kind="area",figsize=[10,5], color="g")
さらに詳しくは、
---✂︎---
◆年月別でヒートマップを作る
①"year"と"month_en"でピボットテーブルを作る
#yearとmonth_enでクロス集計する
#レポート回数合計
pivot_sum = df.pivot_table(values="number",index="year",columns="month_en", aggfunc=np.sum)
#月名の順番を綺麗にする
pivot_sum = pivot_sum.loc[:,['January', 'Feburary', 'March', 'April', 'May', 'June', 'July', 'August','September', 'October', 'November', 'December']]
#確認
pivot_sum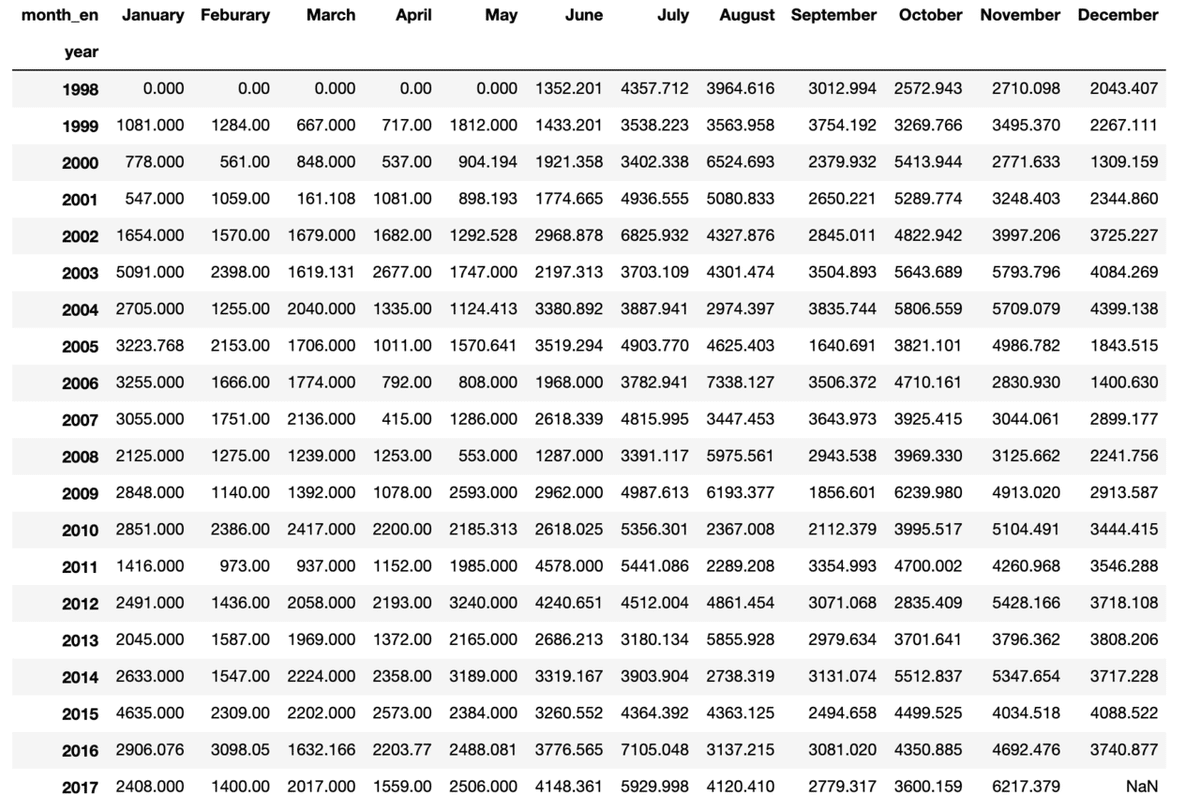
②ヒートマップにする
plt.figure(figsize=(15, 8))
sns.heatmap(pivot_sum,annot=True,fmt="1.2f",cmap='Reds')
縦軸にyear、横軸にmonth_enが並んで、年月での山火事件数が把握できます。
---✂︎---ご参考---✂︎---
ちなみに、
・もっと”燃えてる感”出したい時は、cmap='hot_r'
plt.figure(figsize=(15, 8))
sns.heatmap(pivot_sum,annot=True,fmt="1.2f",cmap='hot_r')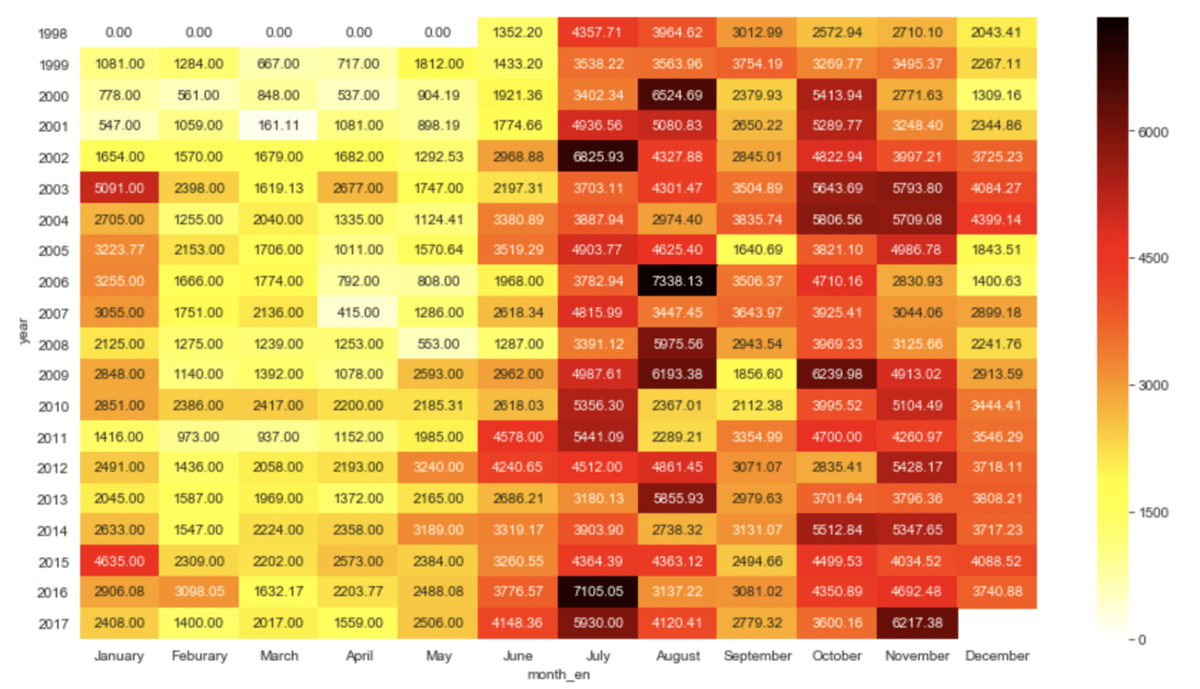
まさに"ヒート"マップ🔥
---✂︎---
前置きが長くなりましたが、ココからが本番です。
これを作ります。
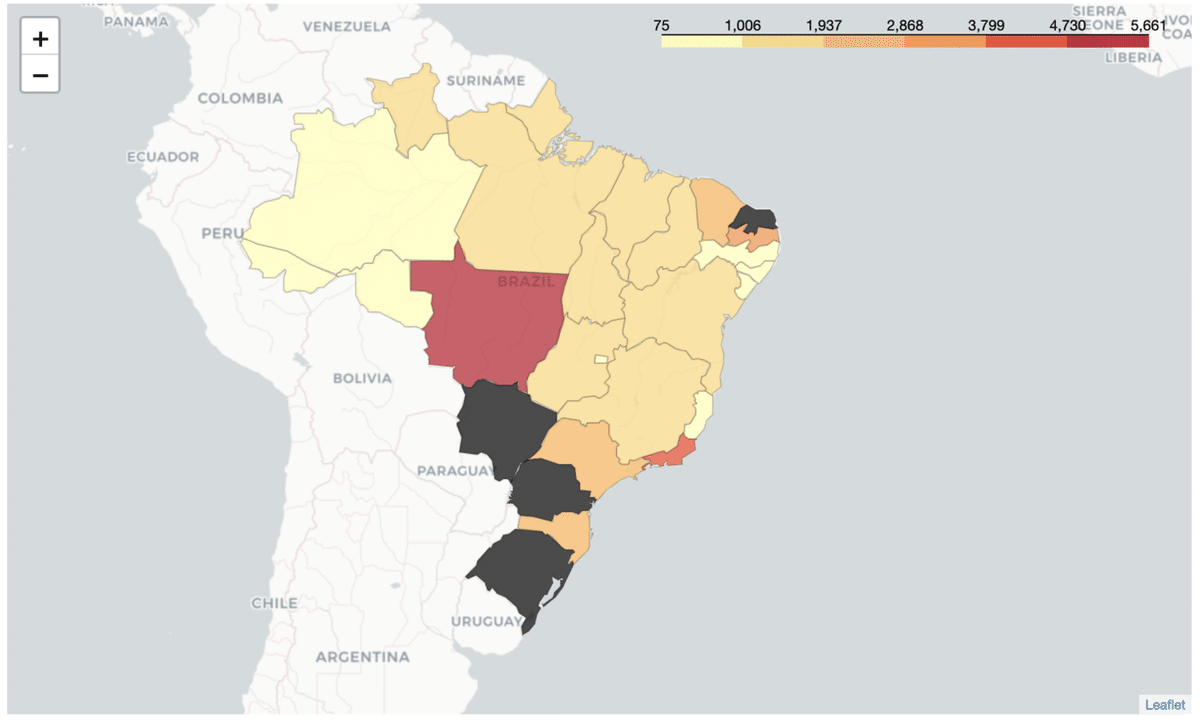
山火事データでコロプレス図を作ってみる🔥
以下があれば、簡単にできます。

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕