
noteのビュー数をあげるタイトルキーワードを探す

「もっと自分のnoteを読んでもらいたい!」ってなもんで、自分の過去noteの「ビュー数」と「タイトル」と「タグ」について分析しました↓
で、結論は以下3点でした。
このnoteは、その↑のnoteの解説です。
①タイトルの文字数は31文字以下に抑える
②タグは、5個以下にした方が良さげ
③タイトルには「 Python」「マーケティング」を入れた方が良さげ
※③は、私のケースです。皆様におかれましては、それぞれ「ビュー数」を伸ばせるキーワードがあるかと。
途中までは無料で読めます。楽しんでもらえると幸いです。
このnoteでやること
以下の2つができるようになります。
①ワードクラウドを作る (Pythonを使います)
②決定木分析(ディシジョン・ツリー)をする(Rを使います)
以下のような視点で活かせることができます。
①テキストデータの内容や頻出語句などを直感的に捉えやすくなる。なんか格好いい。
②求めたり高めたい事象に対して、どんな条件が必要そうかわかる。ディシジョンしやすくなる。
※詳しくは後述にて
実務でも、自分のブログやnoteの分析に応用できるかと思います。
それでは、よろしくどうぞ。
環境
①ワードクラウドについては、「Jupyter Notebook」を使います。
②決定木分析については、「R studio」を使います。
どちらもAnacondaという、色々セットになった無料のディストリビューションをダウンロードすれば中に入ってます。
まだダウンロードしてない方は、早くしやがれください。
---✂︎---
◆windowsの方向け
◆macの方向け
---✂︎---
分析用データの準備
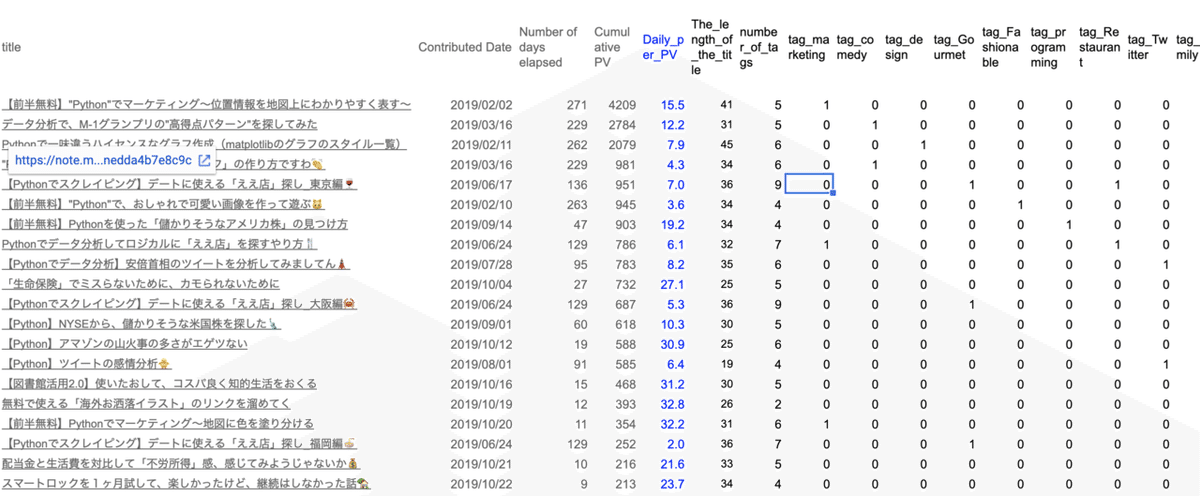
まず、このnoteでは、↓のようなデータセットを用意しました。

(左から)
①title:タイトル
②Contributed Date:投稿日
③Number of days elapsed:経過日数
④Cumulative PV:累積のビュー数
⑤Daily_per_PV:日次のビュー数(★)
⑥The_length_of_the_title:タイトルの文字数(★)
⑦number_of_tags:タグの数(★)
⑧tag_〇〇:〇〇はタグ名で、1/0に変換(★)
※(★)をこの後、使用します
①〜④について
・スプレッドシートでもエクセルでもなんでもいいので用意
・自分のnoteのダッシュボードから「タイトル」「累計ビュー数」をコピペ
・「投稿日」は↓の部分をコピペ(ココは地道に)

・「基準日」と「投稿日」を差し引きして、各noteを公開してからの「経過日数」を出します
⑤について
・④累積のビュー数を③経過日数われば、⑤日次の平均ビュー数が出ます(青字)。

⑥について
・①タイトルを関数「len()」で括れば、文字数が得られます
⑦について
・ココは地道に整理する必要があります。
・まず、↓から自分の各noteの下部にある、↓を地道にコピペします。

↓地道にコピペ

・あとは、「counta()」とかでタグの数を数える列を↑に追加
⑧について
※ココは、今回の分析ではそこまで良い示唆が得られなかったので、飛ばしても良いです
・ココ、少しコツが入ります。
・⑦で整理した各noteのタグを一列に並べます

・重複している項目を削除します
・重複を消したタグたちを、縦を横にして、元のリストに貼り付けます
・「=countif($B3:$D3,"*"&F$2&"*")」のように、ワイルドカードを使って、表頭のタグが含まれてたらカウント1する

出来上がりました
・最後に、表頭を日本語から英語(例:「マーケティング」→「marketing」)にして貼り付け直しておくと、分析時に便利です。
※日本語のままだとエラーが出ることがあります。
ワードクラウド
まず、ワードクラウド を作ってみます。

ってことで、Jupyter Notebookの出番です。
よくわからない方は、↓を。
大きな流れは、
①自分の過去noteの「タイトル文字列」を読み込む
②「タイトル文字列」を形態素解析のうえで、品詞分解して"名詞"だけ抽出する
③取り出した"名詞"をワードクラウドに表す
①自分の過去noteの「タイトル文字列」を読み込む
・品詞分解をするようの「mecab」というライブラリをインストールして、importします。
---✂︎---詰まったときのご参考---✂︎---
もしくは、
---✂︎---
importする
import MeCab試しに一つ
tagger = MeCab.Tagger("-Ochasen")
print(tagger.parse("""すもももももももものうち"""))
もう一個
tagger = MeCab.Tagger("-Ochasen")
print(tagger.parse("""スマートロックを1ヶ月試して、楽しかったけど、継続はしなかった話🏡"""))
イイ感じです。
タイトルを全部コピペして、変数に格納します。
title = """【前半無料】"Python"でマーケティング〜位置情報を地図上にわかりやすく表す〜
データ分析で、M-1グランプリの"高得点パターン"を探してみた
Pythonで一味違うハイセンスなグラフ作成(matplotlibのグラフのスタイル一覧)
"Python"を使った「漫才の盛り上がりグラフ」の作り方ですわ👏
【Pythonでスクレイピング】デートに使える「ええ店」探し_東京編🍷
【前半無料】"Python"で、おしゃれで可愛い画像を作って遊ぶ🐱
【前半無料】Pythonを使った「儲かりそうなアメリカ株」の見つけ方
Pythonでデータ分析してロジカルに「ええ店」を探すやり方🍴
【Pythonでデータ分析】安倍首相のツイートを分析してみましてん🗼
「生命保険」でミスらないために、カモられないために
【Pythonでスクレイピング】デートに使える「ええ店」探し_大阪編🦀
【Python】NYSEから、儲かりそうな米国株を探した🗽
【Python】アマゾンの山火事の多さがエゲツない
【Python】ツイートの感情分析🐥
【図書館活用2.0】使いたおして、コスパ良く知的生活をおくる
無料で使える「海外お洒落イラスト」のリンクを溜めてく
【前半無料】Pythonでマーケティング〜地図に色を塗り分ける
【Pythonでスクレイピング】デートに使える「ええ店」探し_福岡編🍜
配当金と生活費を対比して「不労所得」感、感じてみようじゃないか💰
スマートロックを1ヶ月試して、楽しかったけど、継続はしなかった話🏡"""ココから本番です
②「タイトル文字列」を形態素解析のうえで、品詞分解して"名詞"だけ抽出する
import pandas as pd
class CustomMeCabTagger(MeCab.Tagger):
COLUMNS = ['表層形', '品詞', '品詞細分類1', '品詞細分類2', '品詞細分類3', '活用型', '活用形', '原形', '読み', '発音']
def parseToDataFrame(self, text: str) -> pd.DataFrame:
"""テキストを parse した結果を Pandas DataFrame として返す"""
results = []
for line in self.parse(text).split('\n'):
if line == 'EOS':
break
surface, feature = line.split('\t')
feature = [None if f == '*' else f for f in feature.split(',')]
results.append([surface, *feature])
return pd.DataFrame(results, columns=type(self).COLUMNS)コチラを参考にさせていただきました。ありがとうございます。
品詞分解して、データフレーム化
tagger = CustomMeCabTagger()
test = tagger.parseToDataFrame(title)
test.head(10)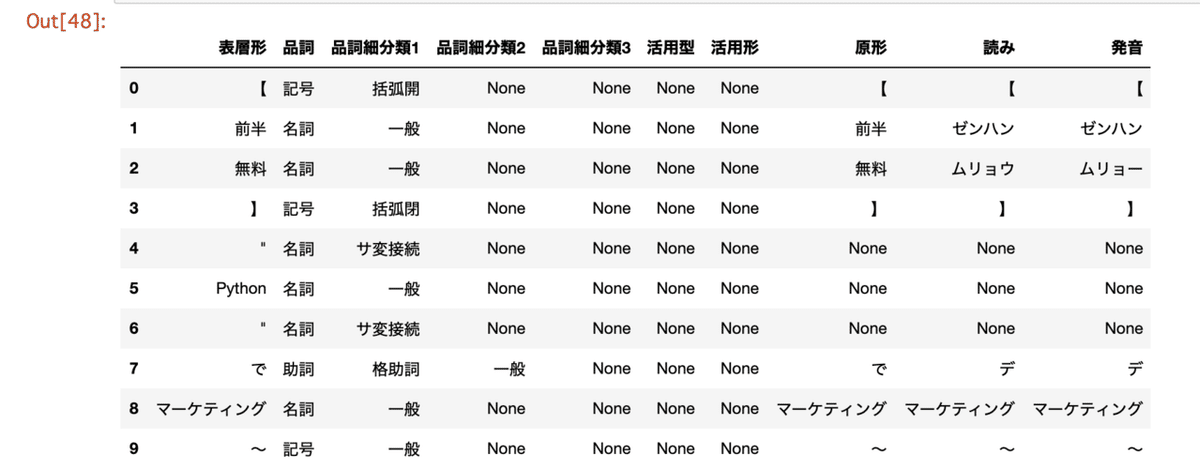
品詞が"名詞"だけ取り出す
#名詞だけにする
test2 = test[test["品詞"].isin(["名詞"])]
#数と接尾後が邪魔なので、"一般","サ変接続","固有名詞"だけにする
test3 = test2[test2["品詞細分類1"].isin(["一般","サ変接続","固有名詞"])]
#リスト方にした上で、string型に変行して格納
title_words = str(list(test3["表層形"]))
#確認
title_words
↓のような名詞が取得できました。これは後の決定木分析でも使います。
前半, 無料, Python, マーケティング, 位置, 情報, 地図, データ, 分析, グランプリ, 得点, パターン, ハイ, センス, グラフ, 作成, スタイル, 一覧, 漫才, 盛り上がり, 作り方, スクレイピング, 店, 画像, 株, やり方, 首相, ツイート, 生命保険, ミス, カモ, アマゾン, 山火事, エゲツ, 感情, 図書館, 活用, 使い, コスパ, 知的, 生活, 海外, お洒落, イラスト, リンク, 色, 配当, 対比, 不労所得, ロック, 継続, 話
あと少しです。
③取り出した"名詞"をワードクラウドに表す
#日本語が表示されるように、フォントのパスを指定
fpath_ja = "/Library/Fonts/Songti.ttc"描画
#ワードクラウドを作る
wordcloud = WordCloud(
background_color="white", #背景色
#colormap='winter',
font_path=fpath_ja, #Macの場合、フォントまでのパスをしているする必要がある
stopwords = STOPWORDS, #ワードクラウドに含まない用語リストを用意する。STOPWORDSがあらかじめ使える
width=900, #横幅
height=500, #縦幅
#mask=abesan_image
).generate(title_words) #ここに、テキストデータを入れます
#作ったワードクラウドを表示する
plt.figure(figsize=(12,10)) #表示サイズを指定する
plt.imshow(wordcloud) #表示させるワードクラウドの変数を入れる
plt.axis("off") #グリッド線のon/off
plt.show()
季節に合わせて色をお楽しみください。

#引数 colormap=""をいじるとできます。
colormap='spring'
colormap='summer'
colormap='autumn'
colormap='winter'もっと楽しみたい方はコチラを。
↓のドナ○ド・ダック的なオシャレが画像を作れます。

決定木分析(ディシジョンツリー)
決定木分析とは何かというと、こんなのです。

「予測」や「判別」、「分類」を目的として使われるデータマイニング手法です。顧客情報やアンケート結果などについて、“従属変数”に影響する“説明変数”を見つけ、樹木状のモデルを作成する分析方法となります。
※下記URLより引用
以下3つの決定木を作ってみます
①「日時平均ビュー数」が多くなる「タイトル文字数」と「タグ数」はいかほどか
②「日時平均ビュー数」が多くなる「タグ」はどんなタグか
③「日時平均ビュー数」が多くなる「タイトルに入れるべきキーワード」は何か
ココからは「R studio」にお世話になります。

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕