
トランプ大統領のツイート分析-やり方-

以前のnoteでトランプ大統領のツイートを色々、分析して遊んでみました。
で、以下のようなことがわかりました。
・火曜日、水曜日のツイートが多い
・夜9〜10時のツイートが多い
・自分の名前をよくツイートしていたり
・ポジティブで主体的なツイートが多かったり
このnoteは、↑のnoteで行ったPythonを使った集計・分析のやり方でございます。
こんなことが出来るようになります

本noteで、以下のようなことが出来るようになります。
①手始めに普通の集計を色々
②レーダーチャートを時計風に使う
③tweetの感情をスコア化する
④tweetをクラスター分けする(k-means法)
⑤ワードクラウドを作って遊ぶ
楽しんでいただけたら幸いです。
⓪まず、準備です
環境はなんでもいいですが、おすすめは「Jupyter Notebook」です。
今回が初トライな方は、このnoteの前半の「◆まず、環境の準備です」をお読みください(無料です)。
データは↓からダウンロードしてください。わからない方は、このnoteの「・データのダウンロード」をお読みください(無料です)。
ライブラリのimport
#いつもの
import pandas as pd
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
#plotly
import plotly
import plotly.express as px
import plotly.graph_objects as go
%matplotlib inline
font = {"family": "Arial"}
matplotlib.rc('font', **font)Plotlyというライブラリを使います。
インストールしてない方は、このnoteの「◆「plotly」という便利なライブラリをインストールします」をお読みください(無料です)。
データの取り込み
df = pd.read_csv("/Users/[データがあるディレクトリ]/trumptweets.csv"))データの確認
df.shape41,122行の大きなデータです
データの加工
#dateを日付データに変える
df.date = pd.to_datetime(df.date)
#dateから["year","quarter","month","day","day_of_week"]を取得します
df["year"] = df.date.map(lambda x : x.year)
df["quarter"] = df.date.map(lambda x : x.quarter)
df["month"] = df.date.map(lambda x : x.month)
df["day"] = df.date.map(lambda x : x.day)
#dateから曜日を取得します
df["day_of_week"] = df.date.map(lambda x : x.strftime('%A'))
#使わない列を削除
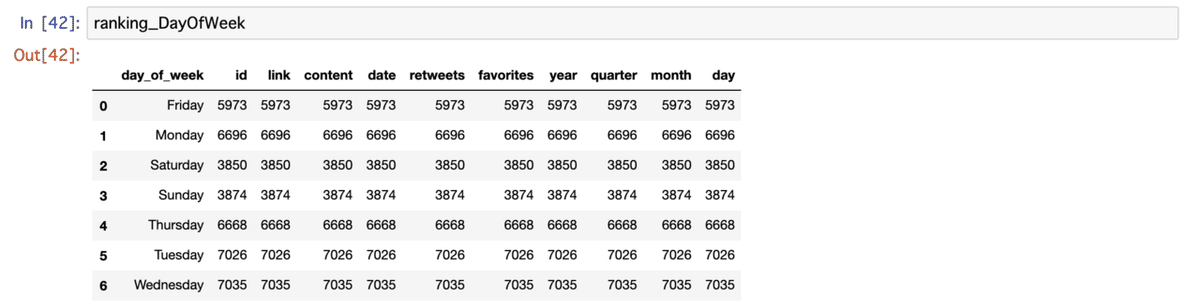
df.drop(columns=["mentions","hashtags","geo"], inplace=True)①手始めに普通の集計を色々
手始めに、↓のようなグラフを作ってみます。

#曜日でgroupbyします
gb_day_of_week =df.groupby("day_of_week")
#曜日別でcountします
ranking_DayOfWeek = gb_day_of_week.count().reset_index()
#曜日の順番を整えて、格納しなおします
sort = ["Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"]
ranking_DayOfWeek = ranking_DayOfWeek.set_index("day_of_week").reindex(sort)
#確認
ranking_DayOfWeek
描画します。
day_of_week_x = list(ranking_DayOfWeek.index)
day_of_week_y = list(ranking_DayOfWeek["id"])
colors = ['#636EFA', '#EF553B', '#00CC96', '#AB63FA', '#FFA15A', '#19D3F3', '#FF6692']
fig_DayofWeek = go.Bar(x=day_of_week_x, y=day_of_week_y, marker_color=colors)
go.Figure(fig_DayofWeek)

曜日別のツイート数の集計ができました。
次は、年別で集計してみます。
#yearでgroupbyします
gb_year =df.groupby("year")
#グラフを作成します
year_x = list(gb_year.count().reset_index()["year"])
year_y = list(gb_year.count()["id"])
#描画します
fig_year = go.Figure([go.Bar(x=year_x, y=year_y, textposition="inside")])
fig_year
クロス集計
年と曜日でクロス集計してみます。
#年と曜日でpivot_table作ります
Year_DaysOfWeek = pd.pivot_table(df, index="day_of_week",columns="year",values="id", aggfunc="size")
#確認
Year_DaysOfWeek.reindex(sort)
years = df.year.unique()
fig_cross = go.Figure(data = [
go.Bar(name="Mon.", x = years, y=list(Year_DaysOfWeek.loc["Monday"])),
go.Bar(name="Tue.", x = years, y=list(Year_DaysOfWeek.loc["Tuesday"])),
go.Bar(name="Wed.", x = years, y=list(Year_DaysOfWeek.loc["Wednesday"])),
go.Bar(name="Thu.", x = years, y=list(Year_DaysOfWeek.loc["Thursday"])),
go.Bar(name="Fri.", x = years, y=list(Year_DaysOfWeek.loc["Friday"])),
go.Bar(name="Sat.", x = years, y=list(Year_DaysOfWeek.loc["Saturday"])),
go.Bar(name="Sun.", x = years, y=list(Year_DaysOfWeek.loc["Sunday"])),
])
fig_cross.update_layout(barmode = "group", title= "年と曜日のクロス集計")
fig_cross.show()

三つのグラフを一つにしてみます
from plotly import tools
import plotly.offline as offline
fig_show = tools.make_subplots(rows=2, cols=2,specs=[[{}, {}],
[{"colspan": 2}, None]], subplot_titles=("年","曜日","年 × 曜日"))
tweet_count_by_year = go.Bar(name= "Year", x=x, y=y,textposition='outside', marker_color= "#1F77B4")
mon = go.Bar(name="Mon.", x = years, y=list(Year_DaysOfWeek.loc["Monday"]), marker_color = '#636EFA')
tue = go.Bar(name="Tue.", x = years, y=list(Year_DaysOfWeek.loc["Tuesday"]), marker_color = '#EF553B')
wed = go.Bar(name="Wed.", x = years, y=list(Year_DaysOfWeek.loc["Wednesday"]), marker_color = '#00CC96')
thu = go.Bar(name="Thu.", x = years, y=list(Year_DaysOfWeek.loc["Thursday"]), marker_color = '#AB63FA')
fri = go.Bar(name="Fri.", x = years, y=list(Year_DaysOfWeek.loc["Friday"]), marker_color = '#FFA15A')
sat = go.Bar(name="Sat.", x = years, y=list(Year_DaysOfWeek.loc["Saturday"]), marker_color = '#19D3F3')
sun = go.Bar(name="Sun.", x = years, y=list(Year_DaysOfWeek.loc["Sunday"]), marker_color = '#FF6692')
tweet_count_by_dayofweek = go.Bar(name = "day_of_week",x=day_of_week_x, y=day_of_week_y, marker_color=colors)
#値を追加する
fig_show.append_trace(tweet_count_by_year, 1, 1)
fig_show.append_trace(mon, 2, 1)
fig_show.append_trace(tue, 2, 1)
fig_show.append_trace(wed, 2, 1)
fig_show.append_trace(thu, 2, 1)
fig_show.append_trace(fri, 2, 1)
fig_show.append_trace(sat, 2, 1)
fig_show.append_trace(sun, 2, 1)
fig_show.append_trace(tweet_count_by_dayofweek, 1, 2)#タイトルを追加して大きさを指定する
fig_show['layout'].update(height=600, width=900, title = "トランプ大統領のtweet(2009~2020)")
#描画する
fig_show

---✂︎---ご参考---✂︎---
ヒートマップもよかったら、どうぞ。
plt.figure(figsize=[20,10])
sns.heatmap(Year_DaysOfWeek.reindex(sort), annot=True,cmap="PuBu",linecolor= "Grey", linewidths=.3)
---✂︎---
②レーダーチャートを時計風に使う
少し邪道ですが、レーダーチャートを時計風にして、何時ごろのtweetをしているかを見える化してみました。

この作り方です。
準備
#hourを置換するために、辞書型で以下を用意
time = {
0:"midnight/noon",
1:"1 am/pm",
2:"2 am/pm",
3:"3 am/pm",
4:"4 am/pm",
5:"5 am/pm",
6:"6 am/pm",
7:"7 am/pm",
8:"8 am/pm",
9:"9 am/pm",
10:"10 am/pm",
11:"11 am/pm",
12:"midnight/noon",
13:"1 am/pm",
14:"2 am/pm",
15:"3 am/pm",
16:"4 am/pm",
17:"5 am/pm",
18:"6 am/pm",
19:"7 am/pm",
20:"8 am/pm",
21:"9 am/pm",
22:"10 am/pm",
23:"11 am/pm",
}
#hourをtimeに置換
df["clock"] = df.hour.replace(time)
#hourから、amかpmかを判断して列を追加
df["am_pm"] = df.hour.map(lambda x : "am" if x <= 11 else "pm")
#確認
df[["hour","clock","am_pm"]].head(10)
何時 × am/pmでクロス集計します
#レーダーチャート用の表示順番
sort_2 = ['3 am/pm','2 am/pm', '1 am/pm','midnight/noon', '11 am/pm','10 am/pm',
'9 am/pm','8 am/pm', '7 am/pm',
'6 am/pm', '5 am/pm', '4 am/pm'
]
#pivot_tableで確認する
df.pivot_table(index="clock", columns="am_pm", aggfunc="size").reindex(sort_2)
amとpmでlistを作ります
#am分の集計用のlist
am_size = list(df.pivot_table(index="clock", columns="am_pm", aggfunc="size").reindex(sort_2).am)
#pm分の集計用のlist
pm_size = list(df.pivot_table(index="clock", columns="am_pm", aggfunc="size").reindex(sort_2).pm)グラフを描画します
Barpolar_am = go.Figure(go.Barpolar(
r = am_size,#集計する値のlist
theta = sort_2,#順番
marker_color=["#709BFF"]* len(sort_2),#グラフ色の指定
marker_line_color="black",#線の色の指定
marker_line_width=1,#線の太さの指定
showlegend = True,#凡例の表示有無を指定
name = "am"#凡例の表示名
))
Barpolar_am.update_layout(
template=None,
polar = dict(
radialaxis = dict(range=[0, 3500], showticklabels=True, ticks=''),#上限と下限を設定
))
AMだと、3時、4時のツイートが多いことがわかります。
Barpolar_pm = go.Figure(go.Barpolar(
r = pm_size,
theta = sort_2,
marker_color=["#FFAA70"]* len(sort_2),
marker_line_color="black",
marker_line_width=1,
showlegend = True,
name = "pm"
))
Barpolar_pm.update_layout(
template=None,
polar = dict(
radialaxis = dict(range=[0, 3500], showticklabels=True, ticks=''),
))
PMだと、9時、10時のツイートが多いことがわかります。
③tweetの感情をスコア化する
続いて、tweetに込められてる感情をスコア化してみます。
TextBlobというPythonのライブラリを使います。
#Jupyter Notebook内で、以下のコマンドを実行。
#textblobがinstallされます。
!pip install textblobライブラリのimport
先ほど、installしたtextblobをimportします
from textblob import TextBlob一つのtweetで試してみます
test_tweet = df.content[0]
print(test_tweet)
print("↓")
test_analysis = TextBlob(test_tweet)
print("【polarity】ツイートがポジティブかネガティブか 【subjectivity】ツイートの主体性")
print(test_analysis.sentiment)
◆TextBob感情解析◆
テキストから「Sentiment」と「Subjectivity」という二つのスコアを算出
「Sentiment」は、テキストを肯定的か否定的かで、スコア化したもので、「-1~+1」の間のスコアになるとのこと。
「Subjectivity」tweetが積極的か消極的か(≒主体性があるか)で、スコア化したもので、「0~1」の間のスコアになるとのこと。
SentimentとSubjectivityを取得する関数を作ります
def sentiment_analysis(text):
analysis = TextBlob(text)
Sentiment = analysis.sentiment[0]
return Sentiment
def subjectivity_analysis(text):
analysis = TextBlob(text)
Subjectivity = analysis.sentiment[1]
return Subjectivityスコアを取得します
#感情スコアを算出
df["Sentiment"] = df.content.map(lambda x:sentiment_analysis(x))
#主体性スコアを算出
df["Subjectivity"] = df.content.map(lambda x:subjectivity_analysis(x))データが4万件ほどあるので、少し時間がかかるかと思います。
#確認
df[["content","Sentiment","Subjectivity"]].head()
各ツイートの、SentimentとSubjectivityのスコアを取得することができました。
先ほど紹介した、棒グラフやレーダーチャートで色々、見える化してみると面白いかと思います。
ちなみに、日本語ツイートの感情分析もできます。
以前、安倍首相のツイートを分析してみました。気になる方はコチラを。
次に、この二つのスコアを使ってツイートをクラスター分けしてみます。
④tweetをクラスター分けする(k-means法)
各ツイートから、ポジネガ(Sentiment)と主体性(Subjectivity)のスコアを取得しました。
これを使って、ツイートを分類分けしてみます。
まずは、散布図でみてみる
px.scatter(df.sample(n=1000), x= "Sentiment", y = "Subjectivity", title="ツイートのSentimentとSubjectivityの散布図")
ランダムで1,000件をプロットしてみました。
本データを全部プロットすると重くなるのでご注意ください。
クラスターに分ける(k-means法)

#k-meansのライブラリをimport
from sklearn.cluster import KMeans
#k-meansに使用する列だけ別のデータフレームに
df_kmeans = df[["Sentiment","Subjectivity"]]
#numpyのarrayの型に変換する
trump_array = np.array(df_kmeans)分析用のデータの準備が整いました。

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕