
1から近未来の検索システムを構築しよう!!

こんにちは,Nakaroです
今回は,プログラミング初心者である私が自作の検索システムを作成したのでそちらをご紹介します!
初心者でもわかりやすく詳細に記載されているので,手順に従えば,どなたでもシステム構築が可能になります!
私も実際に初心者ですし....
私が今回作成したのは,既存の国立国会図書館サーチという検索システムに,近未来という要素を加えて新規性を持たせた検索システムであります!
(下記に国立国会図書館サーチについて記載します.)
これを作成した経緯としては,10代〜20代の若者の読書活動が減少しているという問題に対処するため,読書活動の推進を目的とした新たなサービスがあれば面白いなぁと思い、今回このサービスを作りたいと思いました!
この検索システムでは、遊び心のある検索により若者が自発的に検索したくなるように,キューブを回転させたり,近未来のUI/UXにもこだわりました.完成した検索システムのデモ動画としては以下のもの(完成版.mp4)になります!!
概要
本講義では,SQLite3を用いて書誌レコードをデータベースに格納し,そのデータベースを検索するためのプログラムをpythonで作成し,Webブラウザから利用できるOPACシステムを作成する.
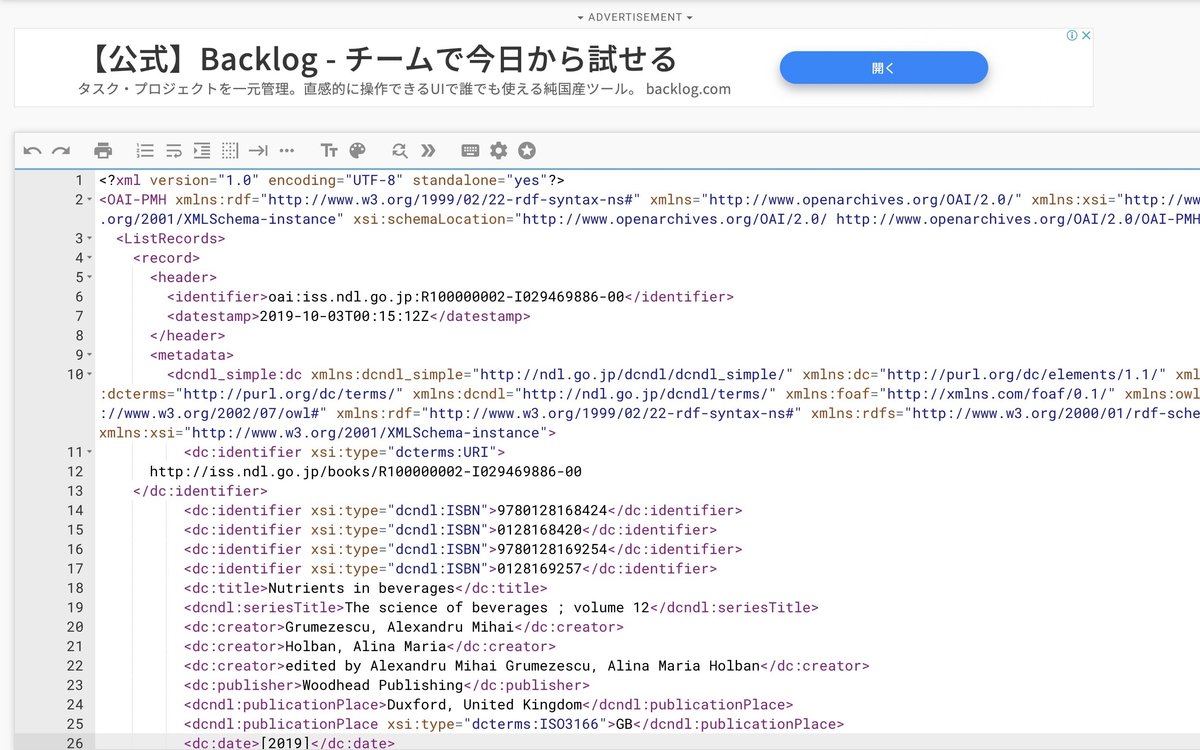
ちなみに今回は,OPACシステムというXML(図1 dcndl large.xml)に書誌データが入っているので書誌の検索となるが,ラーメンの食べログ情報(店舗名,ラーメンの名前,評価など)のXMLだったり,宿泊の情報(旅先,値段,評価など)のXMLを作成することでオリジナルの検索システムを作ることも可能です.
ただ、テーブル列名の変更やXML, HTMLなどに
多少の変更は必要になります。
図1にdcndl large.xml(書誌データ)を、図2に私が作成した架空のラーメン屋ramen_shops.xmlを示す。
今回取り扱うのは、図1 dcndl large.xml(書誌データ)です。

以下の5つのファイルで書誌検索システムを作成しました.
作成ファイル
XML: dcndl_large.xmlファイル
python: Google colab内のpythonファイル
HTML: detail.html, search.html, result.html ファイル
下準備(Google colab, Google drive)
Google driveで新規フォルダ(cje1s2413892) を作成し,google colabをそのファイル内で作成する.そのファイル名をfinal.ipynbとする.
さらに下記のdcndl_large.xmlファイルを解凍して,cje1s2413892ディレクトリ内に入れる
もし,google colabがインストールされていない場合はインストールをすること. 以下を参考にすると良い.
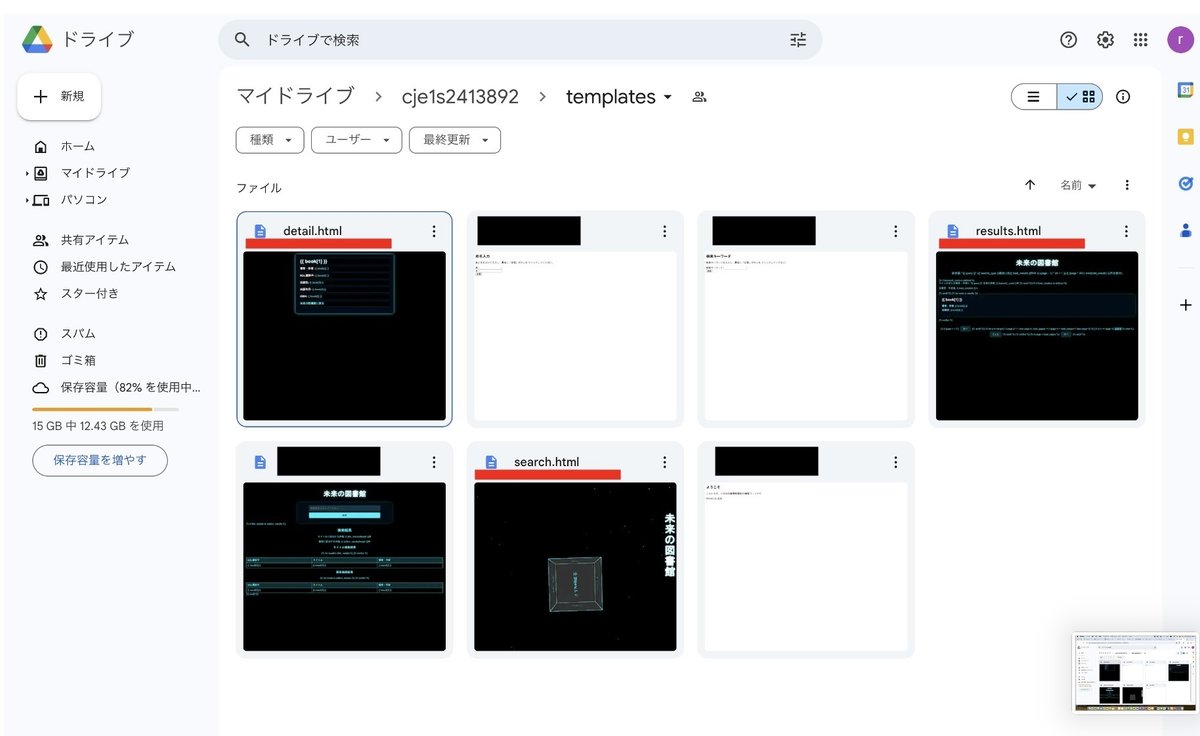
2.さらにGoogle driveで作成したcje1s2413892ファイル内にtemplatesファイルを作成する.この作成したファイル内にdetail.html, result.html, search.htmlを入れる.
※detail.html, result.html, search.htmlファイルはのちほど公開する
図3にdetail.html, result.html, search.htmlファイル(templates内)を示す.
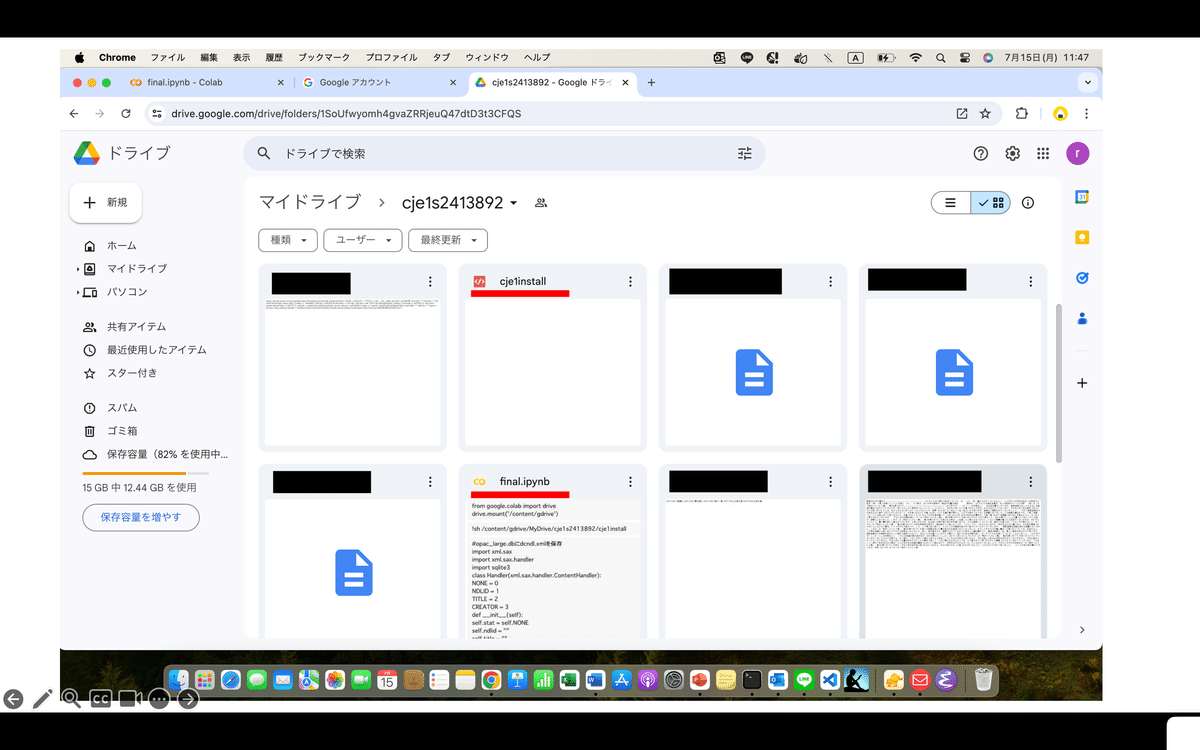
1.のcje1install, final.ipynbがcje122413892ディレクトリファイルに入っているかを確認してほしい.
追記d
ここで私は皆さんに謝らなければならないことがあります.
cje1istallを用意しましたが,リモートサーバーの関係上今回は用いないことにしました.
なので急遽,ngrokを使用して外部からFlaskアプリケーションにアクセスする形でウェブアプリケーションを動作させるという形に変更しました.
ただ,この変更により実行できないことはないので安心してほしいです.
図4にfinal.ipynbファイルを示す.
3.Google Drive を Colab からマウントする.
Google Drive 上に保存されているデータ (ファイル) を Colab で実行するプログラムから読み書きするた めには「マウント」という準備が必要になる。
以下のコードをgoogle colabの作成したfinal.ipynbの1個目のセルで実行する.
#google drive を colab からマウントする.
from google.colab import drive
drive.mount('/content/gdrive') すると、アクセス許可を求めるウィンドウが表示されるので、「Google ドライブに接続」 をクリックする。
次に『「○○」のアカウントを選択して下さい』というウィンドウが表示さ れるので、今使っている Google アカウントのメールアドレスを選ぶ.
「次へ」をクリッ クする。
すると「Google Drive for desktop が Google アカウントへのアクセスを
求めています」と出る。 この画面の右の「すべて選択」のチェックを入れ てから 、最下部までスクロールして「続行」をク リックする。
Google colabインストール
google DriveをColabにマウントする方法
下準備はこれで終わり.お疲れ様です.
本編
さて,いよいよfinal.ipynbを作成していく.
以下の手順(1)~(3)で進める.
(1)sqlite3でopac_largeテーブルを作成する.
(2)書誌データdcndl_large.xmlをパースしてデータをopac_large.db内にデータを挿入する.
(3)Flaskを用いてfinal.ipynbを作成する.
詳しい説明を下記で行う.
(1)SQLite3でopac_largeテーブルを作成する
opac_largeテーブルを作成する前にcje1s2413892のディレクトリファイル内にopac_large.dbというデータベースを作成してほしい.(図2で
このデータベースを作成することで,
con = sqlite3.connect("/content/gdrive/MyDrive/opac_large.db")というコードからわかるようにopac_large.dbというデータベースに接続し,そのデータベース内でopac_largeというテーブルを作成できる.
今回,NDL識 別子 (ndlid),タイトル (dc:title),著者・作者 (dc:creator), 出版社 (dc:publisher), 出版年月 (dc:date), ISBN 番号(dc: isbn)を列名としてテーブルに取り込んでいる.
#opac_largeテーブルを作成
import sqlite3
con = sqlite3.connect("/content/gdrive/MyDrive/opac_large.db")
cur = con.cursor()
cur.execute("create table opac_large(ndlid text, title text, creator text, publisher text, date text, isbn text);")
con.close()(2)書誌データdcndl_large.xmlをパースしてデータをopac_large.db内にデータを挿入する
下記のコードでopac_large.dbにdcndl_large.xml内の6つのデータ
NDL識 別子 (ndlid),タイトル (dc:title),著者・作者 (dc:creator),
出版社(dc:publisher), 出版年月 (dc:date), ISBN 番号(dc: isbn)
を取り込んでいる.
#opac_large.dbにdcndl_large.xmlを保存
import xml.sax
import xml.sax.handler
import sqlite3
class Handler(xml.sax.handler.ContentHandler):
NONE = 0
NDLID = 1
TITLE = 2
CREATOR = 3
PUBLISHER = 4
DATE = 5
ISBN = 6
def __init__(self):
self.stat = self.NONE
self.ndlid = ""
self.title = ""
self.creator = ""
self.publisher = ""
self.date = ""
self.isbn = ""
def startElement(self, name, attrs):
if name == "identifier":
self.stat = self.NDLID
elif name == "dc:title":
self.stat = self.TITLE
elif name == "dc:creator":
self.stat = self.CREATOR
elif name == "dc:publisher":
self.stat = self.PUBLISHER
elif name == "dc:date":
self.stat = self.DATE
elif name == "dc:identifier":
self.stat = self.ISBN
def characters(self, content):
if self.stat == self.NDLID:
self.ndlid = content
elif self.stat == self.TITLE:
self.title = content
elif self.stat == self.CREATOR:
self.creator = content
elif self.stat == self.PUBLISHER:
self.publisher = content
elif self.stat == self.DATE:
self.date = content
elif self.stat == self.ISBN:
self.isbn = content
def endElement(self, name):
self.stat = self.NONE
if name == "record":
#出版社、出版年月、ISBN番号の重複を取り除いて結合
self.publisher = ";".join(set(self.publisher.split(";")))
self.date = ";".join(set(self.date.split(";")))
self.isbn = ";".join(set(self.isbn.split(";")))
#データベースに挿入
cur.execute("INSERT INTO opac_large(ndlid, title, creator, publisher, date, isbn) VALUES (?, ?, ?, ?, ?, ?);",
(self.ndlid, self.title, self.creator, self.publisher, self.date, self.isbn))
self.ndlid = ""
self.title = ""
self.creator = ""
self.publisher = ""
self.date = ""
self.isbn = ""
# パーサーの初期化と設定
parser = xml.sax.make_parser()
handler = Handler()
parser.setContentHandler(handler)
# データベースへの接続
con = sqlite3.connect("/content/gdrive/MyDrive/cje1s2413892/opac_large.db")
cur = con.cursor()
# XML ファイルの解析
parser.parse("/content/gdrive/MyDrive/cje1s2413892/dcndl_large.xml")
# データベースへの変更をコミットして接続を閉じる
con.commit()
con.close()詳しい説明を知りたい方は見てほしい.
それ以外の人は基本飛ばしてもらって構わない.
インポート
import xml.sax
import xml.sax.handler
import sqlite3これらのインポート文は、XML解析のためのSAXパーサーとSQLiteデータベース操作のためのモジュールをインポートしている。
ContentHandler クラスの定義
class Handler(xml.sax.handler.ContentHandler):
NONE = 0
NDLID = 1
TITLE = 2
CREATOR = 3
PUBLISHER = 4
DATE = 5
ISBN = 6
def __init__(self):
self.stat = self.NONE
self.ndlid = ""
self.title = ""
self.creator = ""
self.publisher = ""
self.date = ""
self.isbn = ""Handler クラスは、XMLファイルの内容を処理するためのクラス。いくつかの状態定数(NONE, NDLID, TITLE, CREATOR, PUBLISHER, DATE, ISBN)を定義し、初期化メソッドで状態をNONEに設定し、各データフィールド(ndlid, title, creator, publisher, date, isbn)を空の文字列に初期化する。
startElement メソッド
def startElement(self, name, attrs):
if name == "identifier":
self.stat = self.NDLID
elif name == "dc:title":
self.stat = self.TITLE
elif name == "dc:creator":
self.stat = self.CREATOR
elif name == "dc:publisher":
self.stat = self.PUBLISHER
elif name == "dc:date":
self.stat = self.DATE
elif name == "dc:identifier":
self.stat = self.ISBNstartElement メソッドは、XMLの開始タグを処理するメソッドである。タグの名前に応じて、現在の状態(stat)を対応する定数に設定する。
characters メソッド
def characters(self, content):
if self.stat == self.NDLID:
self.ndlid = content
elif self.stat == self.TITLE:
self.title = content
elif self.stat == self.CREATOR:
self.creator = content
elif self.stat == self.PUBLISHER:
self.publisher = content
elif self.stat == self.DATE:
self.date = content
elif self.stat == self.ISBN:
self.isbn = contentcharacters メソッドは、XMLタグの間のテキスト内容を処理するメソッドである。現在の状態に応じて、対応するフィールドにテキスト内容を設定する。
endElement メソッド
def endElement(self, name):
self.stat = self.NONE
if name == "record":
#出版社、出版年月、ISBN番号の重複を取り除いて結合
self.publisher = ";".join(set(self.publisher.split(";")))
self.date = ";".join(set(self.date.split(";")))
self.isbn = ";".join(set(self.isbn.split(";")))
#データベースに挿入
cur.execute("INSERT INTO opac_large(ndlid, title, creator, publisher, date, isbn) VALUES (?, ?, ?, ?, ?, ?);",
(self.ndlid, self.title, self.creator, self.publisher, self.date, self.isbn))
self.ndlid = ""
self.title = ""
self.creator = ""
self.publisher = ""
self.date = ""
self.isbn = ""endElement メソッドは、XMLの終了タグを処理するメソッドである。record タグの終了時に、出版社、出版年月、ISBN番号の重複を取り除き、データベースに挿入する。データ挿入後、フィールドを空の文字列にリセットする。
パーサーの初期化と設定
parser = xml.sax.make_parser()
handler = Handler()
parser.setContentHandler(handler)これらの行は、SAXパーサーを作成し、Handler オブジェクトをコンテンツハンドラとして設定する。
データベースへの接続
# データベースへの接続
con = sqlite3.connect("/content/gdrive/MyDrive/cje1s2413892/opac_large.db")
cur = con.cursor()これらの行は、指定されたSQLiteデータベースファイルに接続し、カーソルオブジェクトを作成。
XMLファイルの解析
# XML ファイルの解析
parser.parse("/content/gdrive/MyDrive/cje1s2413892/dcndl_large.xml")この行は、指定されたXMLファイルを解析。
データベースへの変更をコミットして接続を閉じる
# データベースへの変更をコミットして接続を閉じる
con.commit()
con.close()これらの行は、データベースへの変更をコミットし、データベース接続を閉じる.
(3)Flaskを用いてfinal.ipynbを作成する
from flask import Flask, request, render_template, url_for, jsonify
import xml.etree.ElementTree as ET
import sqlite3
import math
import os
from IPython.display import display, HTML
from threading import Thread
os.chdir("/content/gdrive/MyDrive/cje1s2413892/")
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def search():
query = request.form.get('query') or request.args.get('query', '')
search_type = request.form.get('search_type') or request.args.get('search_type', 'any')
page = request.args.get('page', 1, type=int)
per_page = 20
if query:
conn = sqlite3.connect('opac_large.db')
c = conn.cursor()
try:
# 検索語を分割
keywords = query.split()
# 検索タイプに応じてSQLクエリを構築
if search_type == 'any':
sql = "SELECT * FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ? OR publisher LIKE ? OR date LIKE ? OR isbn LIKE ?)" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords for _ in range(5)]
elif search_type == 'title_or_creator':
sql = "SELECT * FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ?)" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords for _ in range(2)]
else:
sql = f"SELECT * FROM opac_large WHERE " + " AND ".join([f"{search_type} LIKE ?" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords]
# 総件数を取得
c.execute(f"SELECT COUNT(*) FROM ({sql})", params)
total_results = c.fetchone()[0]
# ページネーションに基づいて結果を取得
offset = (page - 1) * per_page
c.execute(sql + f" LIMIT {per_page} OFFSET {offset}", params)
results = c.fetchall()
# タイトルまたは著者・作者に指定のキーワードを含む件数を取得
keyword_sql = "SELECT COUNT(*) FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ?)" for _ in keywords])
keyword_params = ['%' + keyword + '%' for keyword in keywords for _ in range(2)]
c.execute(keyword_sql, keyword_params)
keyword_count = c.fetchone()[0]
# 全著者・作者数を取得
c.execute("SELECT COUNT(DISTINCT creator) FROM opac_large")
total_creators = c.fetchone()[0]
# 総ページ数を計算
total_pages = math.ceil(total_results / per_page)
return render_template('results.html',
results=results,
query=query,
search_type=search_type,
page=page,
total_pages=total_pages,
total_results=total_results,
keyword_count=keyword_count,
total_creators=total_creators,
max=max,
min=min)
finally:
conn.close()
return render_template('search.html')
@app.template_filter('min')
def min_filter(a, b):
return min(a, b)
@app.template_filter('max')
def max_filter(a, b):
return max(a, b)
@app.route('/detail/<ndlid>')
def detail(ndlid):
conn = sqlite3.connect('opac_large.db')
c = conn.cursor()
c.execute("SELECT * FROM opac_large WHERE ndlid = ?", (ndlid,))
book = c.fetchone()
conn.close()
if book:
return render_template('detail.html', book=book)
else:
return jsonify({'error': 'Book not found'}), 404
def run_flask(app):
app.run(host='127.0.0.1', port=5000, debug=False, use_reloader=False)
if __name__ == '__main__':
# Flask アプリケーションを別スレッドで実行
thread = Thread(target=run_flask, args=(app,))
thread.start()
# ngrok を使用して外部からアクセス可能なURLを取得
!pip install pyngrok
from pyngrok import ngrok
public_url = ngrok.connect(5000)
print(f"ngrok URL: {public_url}")
# ngrokのURLを表示
display(HTML(f'<a href="{public_url}" target="_blank">Open Flask App</a>'))詳しい説明を知りたい方は見てほしい.
それ以外の人は基本飛ばしてもらって構わない.
1. 必要なモジュールのインポート
from flask import Flask, request, render_template, url_for, jsonify
import xml.etree.ElementTree as ET
import sqlite3
import math
import os
from IPython.display import display, HTML
from threading import ThreadFlask, request, render_template, url_for, jsonify はFlaskフレームワークの機能で、Webアプリケーションのルーティングやテンプレートのレンダリング、JSONレスポンスの生成などに使用する。
ET はXML処理のためのモジュールである.(現在のコードでは使用されていない)
sqlite3 はSQLiteデータベースに接続するためのモジュールである。
math は数学的な操作(この場合は切り上げ)に使用されている。
os はオペレーティングシステムとのインターフェースを提供する。
IPython.displayの'display'と'HTML'はjupyter Notebookでの表示用
'Thread'は,Flaskアプリケーションを別スレッドで実行するために使用する.
2. 作業ディレクトリの設定
os.chdir("/content/gdrive/MyDrive/cje1s2413892/")os.chdir を使用して作業ディレクトリを指定。これは、データベースファイルなどがこのディレクトリに存在することを前提としている。
3. Flaskアプリケーションの初期化
app = Flask(__name__)
cje1gw.run_with(app)Flaskアプリケーションを初期化し、cje1gw.run_with(app) を呼び出して、外部モジュール cje1gw をアプリケーションと連携させる。
4. ルートの定義
メインの検索ルート
@app.route('/', methods=['GET', 'POST'])
def search():
query = request.form.get('query') or request.args.get('query', '')
search_type = request.form.get('search_type') or request.args.get('search_type', 'any')
page = request.args.get('page', 1, type=int)
per_page = 20
if query:
conn = sqlite3.connect('opac_large.db')
c = conn.cursor()
try:
# 検索語を分割
keywords = query.split()
# 検索タイプに応じてSQLクエリを構築
if search_type == 'any':
sql = "SELECT * FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ? OR publisher LIKE ? OR date LIKE ? OR isbn LIKE ?)" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords for _ in range(5)]
elif search_type == 'title_or_creator':
sql = "SELECT * FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ?)" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords for _ in range(2)]
else:
sql = f"SELECT * FROM opac_large WHERE " + " AND ".join([f"{search_type} LIKE ?" for _ in keywords])
params = ['%' + keyword + '%' for keyword in keywords]
# 総件数を取得
c.execute(f"SELECT COUNT(*) FROM ({sql})", params)
total_results = c.fetchone()[0]
# ページネーションに基づいて結果を取得
offset = (page - 1) * per_page
c.execute(sql + f" LIMIT {per_page} OFFSET {offset}", params)
results = c.fetchall()
# タイトルまたは著者・作者に指定のキーワードを含む件数を取得
keyword_sql = "SELECT COUNT(*) FROM opac_large WHERE " + " OR ".join(["(title LIKE ? OR creator LIKE ?)" for _ in keywords])
keyword_params = ['%' + keyword + '%' for keyword in keywords for _ in range(2)]
c.execute(keyword_sql, keyword_params)
keyword_count = c.fetchone()[0]
# 全著者・作者数を取得
c.execute("SELECT COUNT(DISTINCT creator) FROM opac_large")
total_creators = c.fetchone()[0]
# 総ページ数を計算
total_pages = math.ceil(total_results / per_page)
return render_template('results.html',
results=results,
query=query,
search_type=search_type,
page=page,
total_pages=total_pages,
total_results=total_results,
keyword_count=keyword_count,
total_creators=total_creators,
max=max,
min=min)
finally:
conn.close()
return render_template('search.html')GET と POST メソッドに対応するルート / を定義する。
ユーザーからの検索クエリや検索タイプ、ページ番号を取得する。
検索クエリがある場合、SQLiteデータベースに接続し、ユーザーの入力に基づいてSQLクエリを動的に構築する。
検索結果をページネーションし、テンプレート results.html に結果を渡してレンダリングする。
最小・最大値フィルター
@app.template_filter('min') def min_filter(a, b): return min(a, b) @app.template_filter('max') def max_filter(a, b): return max(a, b)テンプレート内で使用できるカスタムフィルター min と max を定義する。
詳細表示ルート
@app.route('/detail/<ndlid>')
def detail(ndlid):
conn = sqlite3.connect('opac_large.db')
c = conn.cursor()
c.execute("SELECK * FROM opac_large WHERE ndlid = ?", (ndlid,))
conn.close()
if book:
return render_template('detail.html', book=book)
else:
return jsonify({'error': 'Book not found'}), 404特定の ndlid に基づいて書籍の詳細情報を表示するルート /detail/<ndlid> を定義。
データベースから該当する書籍の情報を取得し、テンプレート detail.html に渡して表示。
Flaskアプリケーションの実行とngrokの設定
def run_flask(app):
app.run(host='127.0.0.1', port=5000, debug=False, use_reloader=False)
if __name__ == '__main__':
thread = Thread(target=run_flask, args=(app,))
thread.start()
!pip install pyngrok
from pyngrok import ngrok
public_url = ngrok.connect(5000)
print(f"ngrok URL: {public_url}")
display(HTML(f'<a href="{public_url}" target="_blank">Open Flask App</a>'))
'run_flask'関数を定義し,別スレッドでFlaskアプリケーションを実行
'pyngrok'をインストールし,ngrokを使用して外部からアクセス可能なURLを取得する.
ngrokのURLを表示し,リンクをクリックしてFlaskアプリケーションを開くことができる.
これにより,Flaskアプリケーションがローカルで実行され,ngrokを通じて外部からアクセス可能になる.
結果
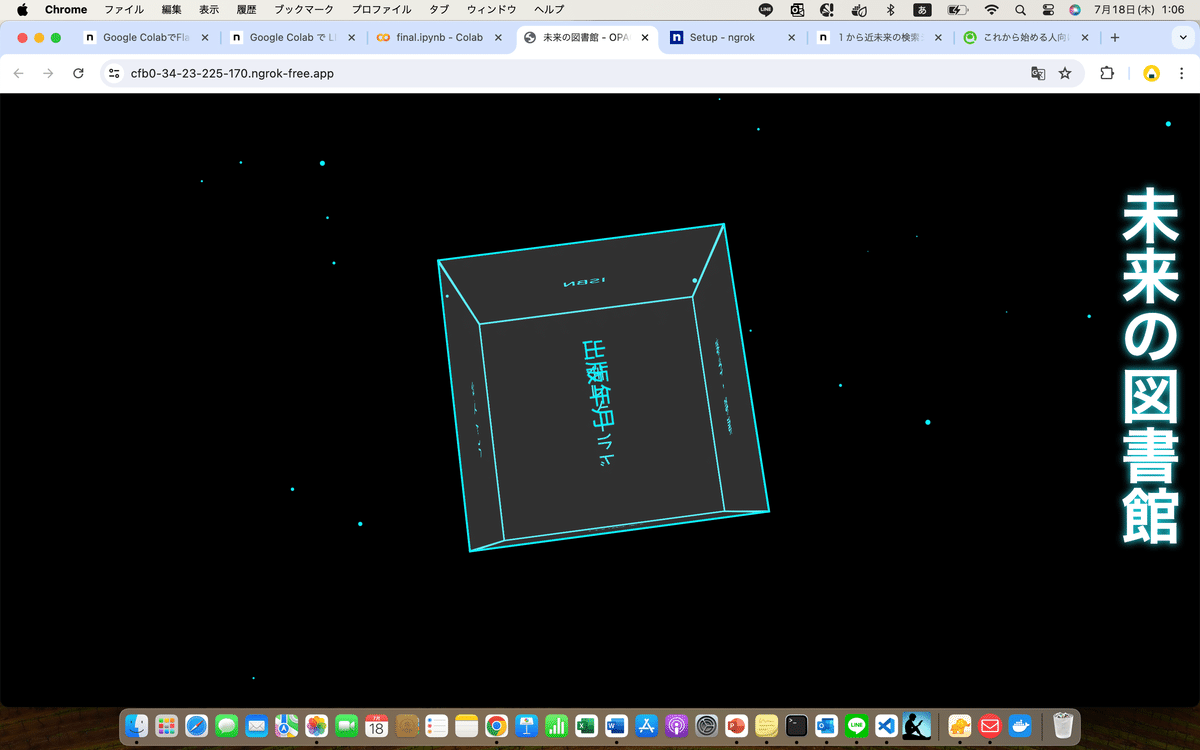
図5に https://95b7-34-23-225-170.ngrok-free.app (ngrokのURL),図6にngrok-Website,図7に未来の図書館(Web検索システム)を示す.
(3)Flaskを用いてfinal.ipynbを作成する
で作成したfinal.ipynbを実行すると,図5のようなURLが表示される.ここでは,Flaskアプリケーションをローカルで実行し,ngrokを使用して外部からアクセス可能にしたものである.
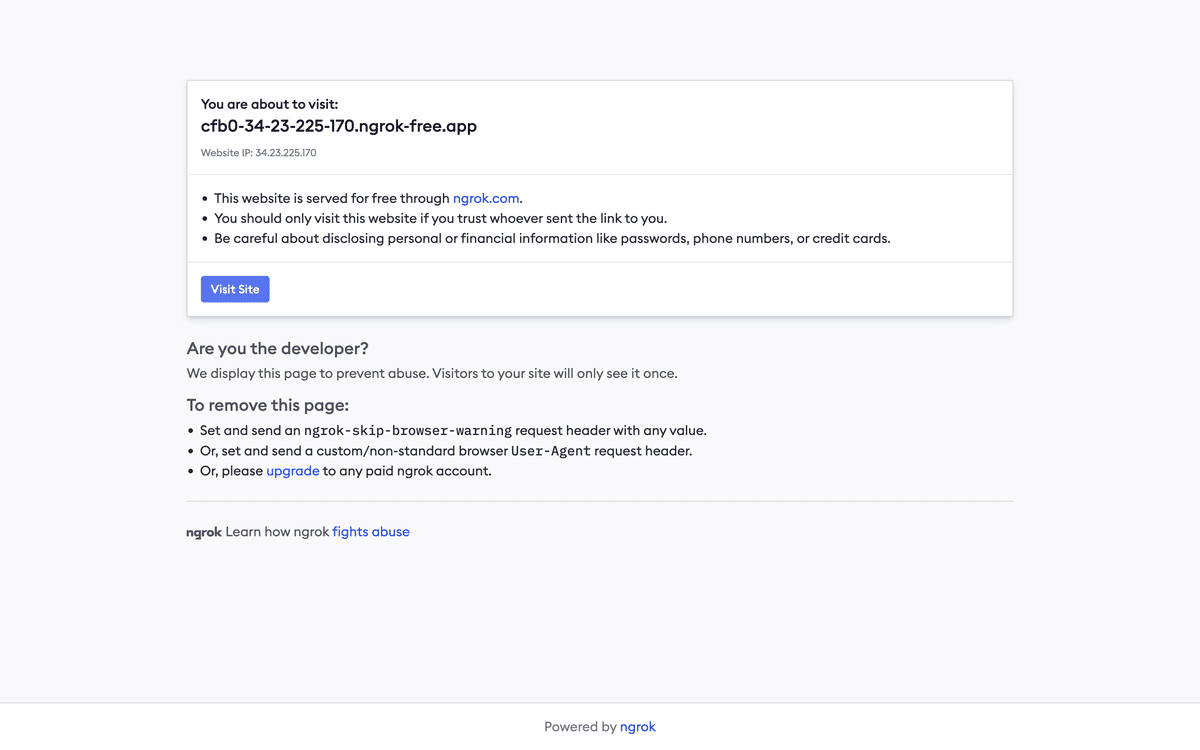
図5のURLをクリックすると,図6のような画面が表示される.
図6のような画面が表示されたら,青色のVisit Siteというボタンをクリックして外部から自分の作成したFlaskアプリケーション(未来の図書館)にアクセスが可能になる.
すると,図7のような画面が表示されてアクセス完了となり,以上でweb検索システムの構築が完成!
ここまでお疲れ様でした!!
最後に補足ですが,
google colabでもう一度コードを実行した際に以下のようなエラーがはかれることがある.
PyngrokNgrokHTTPError: ngrok client exception, API returned 502: {"error_code":103,"status_code":502,"msg":"failed to start tunnel","details":{"err":"failed to start tunnel: Your account may not run more than 3 tunnels over a single ngrok agent session.\nThe tunnels already running on this session are:\ntn_2jNXggzxkWYMnChL7yhY5UX2GPu, tn_2jNXx21OoJwUuXaIBL5WeetgwJ2, tn_2jNYITQkx3lFJMt45QcGxN9O0KU\n\r\n\r\nERR_NGROK_324\r\n"}}原因は,ngrokエージェントセッションで許可されているトンネル数を超えていることである.なので
対処法としては,既存のngrokトンネルを確認して停止する必要がある.
手順:
1.ngrokダッシュボード にアクセスし、ログインする.
2.現在実行中のトンネルを確認し、不要なトンネルを停止。
この手順を行うことにより,再度, 実行が可能になる
(3)Flaskを用いてfinal.ipynbを作成する
で紹介したコードが実行できる.
補足(自分メモ)
ngrok(エングロック)について
HTMLファイルの添付
以下のファイルは、未来の図書館の検索システム構築に必要なHTMLテンプレート(result.html, detail.html, search.html)です。これをcje1s2413892ファイル/templates内に3つのhtmlファイルを挿入することで簡単に実装が行えます!
Flaskに基づいており、/cje1s2413892/templatesフォルダに含めるだけで、簡単に検索システムを構築できます。これを使えば、迅速かつ効率的に図書館の蔵書を検索できるシステムを構築できるでしょう。
この検索システムは、直感的で使いやすく設計されており、利用者が求める情報をすばやく見つけることができます。
さらに、購入者様のご意見やフィードバックをもとに、今後のバージョンアップを予定しており、ますます使いやすく進化していく予定です。
有料コード
こちらでは, detail.html,result.html, search.htmlの完全コードを配布しています.このHTMLファイルを購入することでwebアプリケーションを迅速かつ確実に構築することが可能になります!!
購入された利益はすべて、
私のnote作成の向上のための投資に充てさせていただきます。
より多くの読者様に楽しんでいただけるよう、コンテンツの質を高め、興味深く充実した記事をお届けするための努力を続けます。
この機会にぜひお求めください。検索システムの構築にお役立ていただけるだけでなく、私のnoteの向上にもご協力いただけることに心から感謝いたします。
ここから先は
¥ 300
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?