
ChatGPTに、表データが記載された紙を読み込み、表を再現する機能をつくってもらった!その2 (pytesseract, python)

以前の続きで、ChatGPTに、表データが記載された紙を読み込み、表を再現する機能作成の続きをしていきます!
今回もChatGPTを使っていき、画像から文字を抽出する際のアドバイスをもらったり、表データを作る箇所のコーディングをサポートしてもらう想定で進めてまいります!
前回の記事
pythonで画像から文字を抽出するコード(ChatGPT)
以前、作成した画像から文字を抽出するコードは、pytesseract.image_to_stringを使用していますが、今回も同様のものを使用していきます。
(ChatGPTから教えてもらったコードは以下ですが、適宜カスタマイズしています。)
import pytesseract
from PIL import Image
# 画像の読み込み
image = Image.open('your_image.png')
# PSMとOEMを設定してテキストを抽出
custom_config = r'--oem 3 --psm 6'
text = pytesseract.image_to_string(image, config=custom_config)
print(text)事前の前提整理
表を作る上で、事前に前提を整理していきます。
読み取り対象ファイル
フリーの請求書フォーマットがありましたので、こちらを使用させて頂き、今回はこちらを読み込みながら検証していきたいと思います。
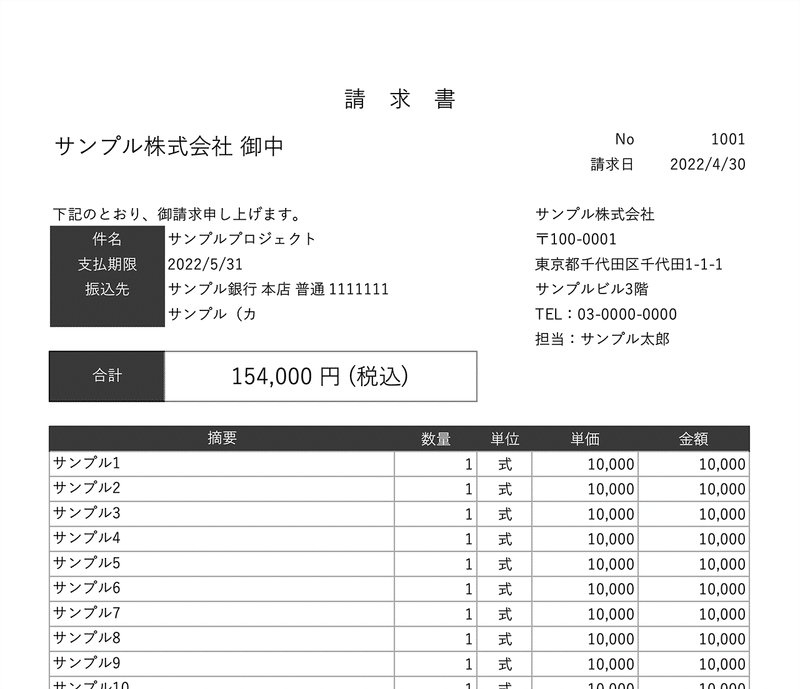
請求書の読み込み結果
請 求 書
サンプル株式会社 御中 No 1001
請求日 2022/4/30
下記のとおり、御請求申し上げます。 サンプル株式会社
件名 サンプルプロジェクト 〒100-000
支払期限 02747人| 東京都千代田区千代田1-1-1
あん サンプル銀行 本店 普通 1111111 サンプルビル3階
サンプル (カ TEL : 03-0000-0000
担当: サンプル太郎
154,000 円 (税込)
摘要 EE 単位 単価 金額
サンプル1 1| 式 10,000 10,000
サンプル2 1| 式 10,000 10,000
サンプル3 1| 式 10,000 10,000
サンプル4 1| 式 10,000 10,000
サンプル5 1| 式 10,000 10,000
サンプル6 1| 式 10,000 10,000
サンプル7 1| 式 10,000 10,000
サンプル8 1| 式 10,000 10,000
サンプル9 1| 式 10,000 10,000
ユエキュレーア1 ィ ード ィ4n nn 4ィ4n nnn設計メモを作る
それでは表を組み立てるための、設計メモをまとめていきます。
カラム数が5つであり、複数行続く場合は、表とみなし、その箇所を抽出しテーブルタグに表示するようなロジックとします。
(「カラム数が5つ」は可変とする。)

表の箇所以外に、カラム数が5つで複数行続く場合もあるので、もう一手間ロジックを加える必要がありそうですが、今回は簡易版で作っていこうと思います、、
カラム数が5つであり、複数行続く場合のロジックを作る
プロンプト
ines = text.split('\n')
table_data = [line.split(' ') for line in lines]
' table_data 'をチェックし、
カラムが5つ以上ある場合、multi_col_flgをonにする。multi_col_flgは各行に保持するものとする
multi_col_flgが複数行続く場合、table_flgをonにする。table_flgは各行に保持するものとする
ChatGPTの回答
def check_table_data(text):
lines = text.split('\n')
table_data = [line.split(' ') for line in lines]
result = []
multi_col_flag = False
consecutive_multi_col_count = 0
for row in table_data:
if len(row) >= 5:
multi_col_flag = True
consecutive_multi_col_count += 1
else:
multi_col_flag = False
consecutive_multi_col_count = 0
# table_flg is true if multi_col_flag is true for at least 2 consecutive rows
table_flg = consecutive_multi_col_count > 1
result.append((row, multi_col_flag, table_flg))
return result
# 使用例
text = """col1 col2 col3 col4 col5
col1 col2 col3 col4 col5
col1 col2 col3 col4
col1 col2 col3 col4 col5
col1 col2 col3 col4 col5
col1 col2
col1 col2 col3 col4 col5
"""
result = check_table_data(text)
for row, multi_col_flag, table_flg in result:
print("Row:", row, "multi_col_flag:", multi_col_flag, "table_flg:", table_flg)
このコードだと、5カラムある一番上の行が表示されないので、ここは手で修正
自分の指示に不足があったのですが、上記のコードだと、5カラムある一番上の行が表示されないロジックでしたので、再度ChatGPTにコードの修正依頼をしましたが、なかなか上手く伝わらなかったため、ここは手直ししました。
摘要 EE 単位 単価 金額 // この行が抽出対象とならない
サンプル1 1| 式 10,000 10,000
サンプル2 1| 式 10,000 10,000
サンプル3 1| 式 10,000 10,000
サンプル4 1| 式 10,000 10,000テーブルタグのHTMLは以前ChatGPTに作ってもらったものを流用
最後に、上記で抽出した表データを画面に表示していきますが、HTMLは以前ChatGPTに作ってもらったものを流用して作っていこうと思います!
動作確認
最後に動作確認をしていきます!
表の箇所のみを抽出し、テーブルタグに表示することができました!
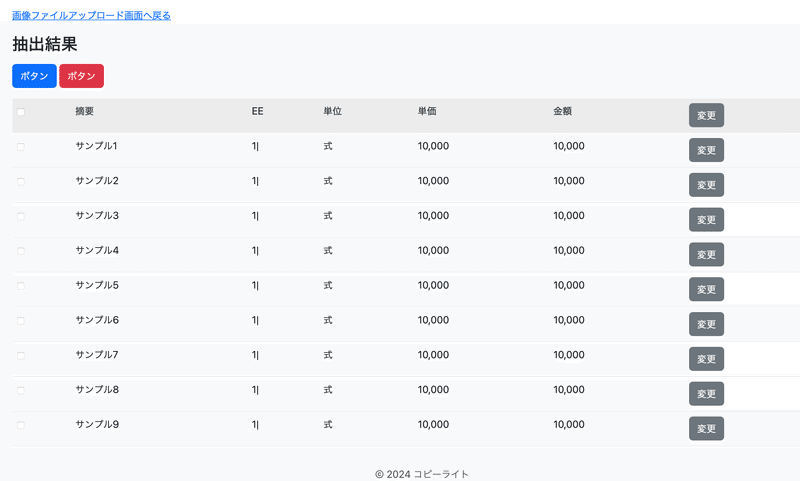
おわりに
最後まで読んでいただきありがとうございます!
多少、想定通りに文字が抽出できない箇所がありましたが、そのあたりの微調整は今後精査していこうかと思います。
最近、ChatGPTでコード作成をしてもらってますが、細かい仕様が多くなると、まるっとコード作成をしてもらうのも難しく、部分的にロジックの書き方を教えてもらい、それを自分でプログラムに取り入れていくやり方が多くなっている気がします。
おまけ
最近、ChatGPTを使用し、色々なことを模索しています。
もしよければ、以下の記事も見て頂けると嬉しいです!
この記事が気に入ったらサポートをしてみませんか?