
PythonスクリプトからGCP AutoML Visionで作成したモデルを利用する

はじめに
この記事ではGoogleが提供しているクラウドサービスであるAutoML Visionを使用して作成した画像認識モデルをPythonスクリプトから使用する方法をご紹介します。
今回は物体検出モデルを使用して、いくつかの物体が映っている画像から自動的にモノが映っている範囲でトリミングした画像を生成してみます。
この記事で使用している物体検出モデルの作り方は以下の記事をご確認ください。
https://note.com/mug_cup/n/ncf12655972b8
必要な知識と環境
この記事ではPython 3系を使用しています。
そのため、この記事の方法をお試ししたい方は予めPython 3系を実行できる環境が必要になります。また、Pythonそのものの文法の説明などはしていないため、Pythonに関する基本的な知識を必要とします。
1. GCPサービスアカウントと認証情報の準備
GCPのサービスを任意のアプリケーションから利用するためにサービスアカウントとその認証情報を予め作成しておきます。
GCPのWebコンソールからIAMと管理のページを開きます。
https://console.cloud.google.com/iam-admin/serviceaccounts

サービスアカウントを作成をクリックし、下図の通りアカウントの設定をしていきます。アカウントの詳細では適当なアカウント名を入力し、作成をクリックします。

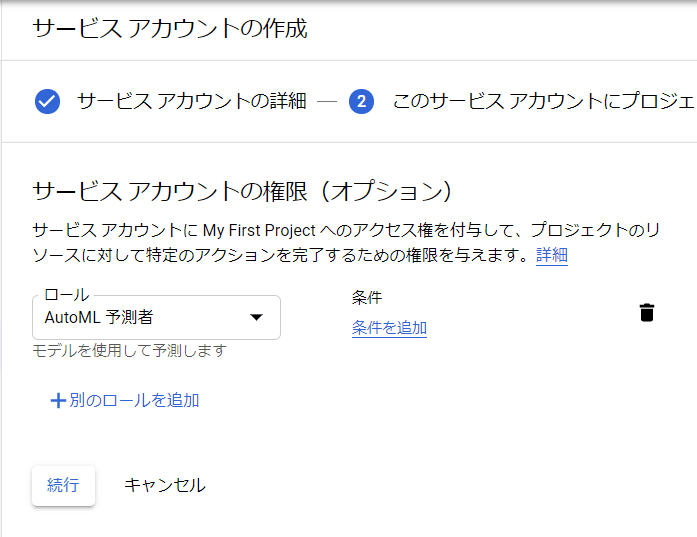
権限の設定でこのサービスアカウントが行うことができる操作を設定できます。今回はAutoMLで作成したモデルから予測を取得できれば十分であるため、AutoML 予測者というロールを選択し、続行をクリックします。
最後の設定は特に何も入力せず、サービスアカウントの作成を完了します。

そうすると、下図のようにサービスアカウントが作成されるため、このサービスアカウントをアプリケーションから利用するために、認証情報を作成してダウンロードしておきます。

サービスアカウントの詳細画面を開くと下図のような鍵を作成するための画面が表示されますので、鍵を追加をクリックして新しい鍵を作成します。

鍵のタイプにはJSONを選択し作成をクリックすると、作成された鍵ファイルが自動的にダウンロードされます。

ダウンロードされた鍵ファイルは後ほどPythonスクリプトで利用するので、無くなさないようにしてください。
2. Pythonスクリプトの依存モジュールをインストールする
今回ご紹介するPythonスクリプトは以下のモジュールに依存しているため、pip installコマンドなどで予めインストールしておいてください。
1. google-cloud-automl
2. Pillow
3. Pythonスクリプトを実装するディレクトリを作成する
スクリプトの実装の前に以下のようなディレクトリ構成でファルダを作成しておきます。また、作成したフォルダのルート階層(automl_detection_demo)に先ほどダウンロードしておいた鍵ファイルを格納しておきます。
※下記の鍵ファイルは名前を変更しています。
└── automl_detection_demo
├── input/
├── output/
└── credentials.json4. Pythonスクリプトを実装する
それではdetector.pyという名前でPythonのスクリプトファイルを作成し、AutoML Visionで作成した物体検出モデルを利用してみます。
detector.pyは作成したフォルダのルート階層(automl_detection_demo)に格納します。
└── automl_detection_demo
├── input/
├── output/
├── credentials.json
└── detector.pydetector.pyの実装内容は下記の通りです。
最低限の実装しかしておりませんので、必要に応じてパラメータの外部定義化、入力画像に対する前処理は実装してください。
import io
from glob import glob
from PIL import Image
from google.cloud import automl_v1beta1
# GCP
GCP_PROJECT_ID = 'ご自身のプロジェクトIDを設定してください'
AUTOML_MODEL_ID = 'ご自身のモデルIDを設定してください'
SERVICE_ACCOUNT_CREDENTIALS = 'credentials.json'
# Environments
INPUT_DIR = './input'
OUTPUT_DIR = './output'
def predict(client, image_bytes, project_id, model_id):
model = f'projects/{project_id}/locations/us-central1/models/{model_id}'
payload = {'image': {'image_bytes': image_bytes}}
params = {}
result = client.predict(model, payload, params)
return result.payload
def image_to_byte_array(image):
bytea = io.BytesIO()
image.save(bytea, format=image.format)
return bytea.getvalue()
def detect(client, image):
image_bytes = image_to_byte_array(image)
predictions = predict(client, image_bytes, GCP_PROJECT_ID, AUTOML_MODEL_ID)
results = []
for pred in predictions:
detected_box = pred.image_object_detection.bounding_box
detected_points = (
detected_box.normalized_vertices[0].x,
detected_box.normalized_vertices[0].y,
detected_box.normalized_vertices[1].x,
detected_box.normalized_vertices[1].y
)
results.append(detected_points)
return results
def crop_image(image, box):
w, h = image.size
return image.crop((box[0]*w, box[1]*h, box[2]*w, box[3]*h))
def main():
automl_client = automl_v1beta1.PredictionServiceClient.from_service_account_file(SERVICE_ACCOUNT_CREDENTIALS)
input_files = glob(f'{INPUT_DIR}/*')
for filepath in input_files:
filename = filepath.split('/')[-1].split('.')[0]
# detect inputs
image = Image.open(filepath)
results = detect(automl_client, image)
# output results
for index, result in enumerate(results):
cropped_image = crop_image(image, result)
output_path = f'{OUTPUT_DIR}/{filename}-{index}.jpg'
cropped_image.save(output_path)
if __name__ == '__main__':
main()5. Pythonスクリプトを実行してみる
用意しておいたinputフォルダに入力用の画像を格納しておきます。
今回は下記のような画像を格納しておきました。

detector.pyを実行してoutputフォルダを確認してみると、正常にモデルから取得した検出結果を使用してトリミングされた画像が出力されています。

おわり
今回はPythonスクリプトからAutoML Visionで作成した物体検出モデルを使用し、物体が写っている範囲でトリミングした画像を自動生成する処理を実装してみました。
最後に、デプロイしたAutoML Visionのモデルが必要でなくなったら、デプロイを解除しておいて費用が発生しないようにしておきましょう。
この記事が気に入ったらサポートをしてみませんか?