
GCP AutoML Visionで物体検出モデルを作ってみる

はじめに
この記事ではGoogleが提供しているクラウドサービスであるAutoML Visionを使用して画像認識モデルを作成してみる方法をご紹介します。
同じような手順であなた独自の画像認識モデルが作成できるようになるはずです。
今回は物体検出編です。
GCPのAutoML Visionは有料のサービスですが、2020年7月現在Googleは初めてGCPを利用する方に300ドルのクレジットを無料で提供しています。
AutoML Visionを数回利用するには十分なクレジットなので、これから初めてGCPを利用する方は実質無料でお試しすることが可能です。
詳しくは下記のリンクからご確認ください。
https://cloud.google.com/free
必要な知識
この記事は基本的には手順をなぞっていけば誰でも再現できる内容になっています。ただし、そこで行っている作業を理解するためには、機械学習の基本的な知識があることを前提としています。
1. GoogleアカウントとGCPの利用準備
何はともあれ、GCPを利用するためにGoogleアカウントが必要です。
今回新たに作成したい方、まだ持っていない方は下記のリンクからアカウントを作成することができます。
https://accounts.google.com/signup
次に下記のリンクにアクセスしてGCPの利用準備を行います。
https://console.cloud.google.com/
表示される確認事項に入力していき、利用登録を完了させると下図のようなGCPのWebコンソールの画面が表示されます。
2. AutoML Vision の利用準備
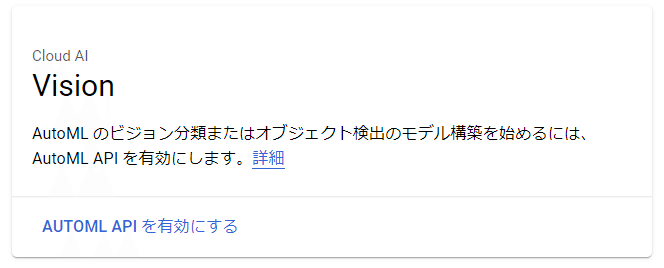
はじめてAutoML Visionを使用する場合は AutoML API の有効化が必要です。
左メニューか検索窓からAutoMLのサービスページにアクセスし、データセットという項目をクリックします。
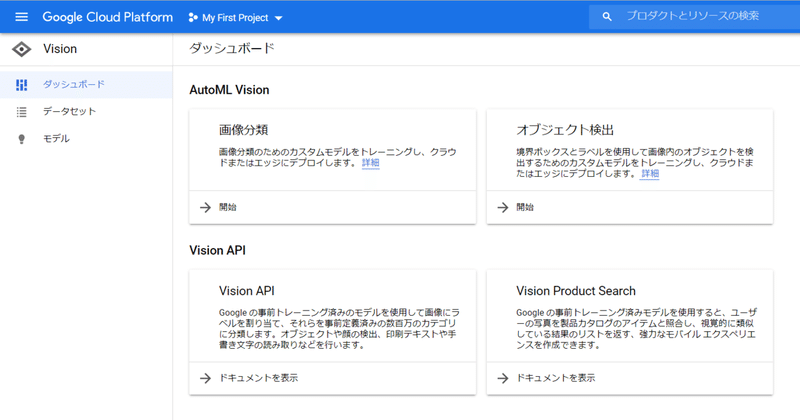
そうすると以下のようにAUTOML APIを有効化するというリンクが表示されます。リンクをクリックして有効化すると、AutoML Visionサービスを利用することができるようになります。
3. AutoML Visionで作成できるモデルの種類
画像認識モデルを学習させるために、これからデータセットというものを準備していきます。ここで言うデータセットとは、画像と『モデルに学習させたい内容』のセットのことですが、学習させたい内容は作りたいモデルの種類によって変わってきます。
例えば、画像から特定の物体が写っている場所を予測できるモデルを作りたい場合、画像と『物体が写っている場所の情報』を登録していき、それをデータセットにして学習させることで、物体が写っている場所を予測できるモデルが作成できます。
同じように、画像に写っている物体が何であるかを予測できるモデルを作りたい場合は、画像と『写っている物体の情報』を登録していき、それをデータセットにします。
上記の例のように、画像認識のなかでも画像のどこに物体が写っているかを予測するモデルを物体検出モデル、画像に写っている物体が何であるかを予測するモデルを物体認識モデルと言います。
2020年7月現在のAutoML Visionでは、これら2種類のモデルの作成に対応しています。
4. 物体検出モデルの学習用画像を用意する
まずは画像に写っている文房具の場所を予測する物体検出モデルを作成してみたいと思います。学習用に使用する画像の集め方はWebから拾ってきたり、機械学習用に公開されている画像を使用したり様々ですが、今回は自分で撮影して用意してみたいと思います。
学習用の画像を用意する際には、画像の撮り方・選び方に注意点があります。大前提として機械学習という技術は、学習したことしか予測できません。つまり、木の机の上に文房具を並べて撮影された画像で学習したモデルが、ガラスの机の上に文房具を並べて撮影された画像から、正しく文房具の位置を予測できるとは限らないということです。
これは、背景になるモノが何であるかだけでなく、文房具の位置や大きさ、向き、見えている面なども同様です。このため、モデルの予測能力に幅を持たせるためには、学習に使用する画像に用途に応じてある程度バリエーションが含まれている必要があります。
とはいえ、最初から全てのバリエーションを含むデータセットを作成することは難しいので、まずは用意できる範囲で学習させてみて、モデルが上手く予測できないパターンを後から追加するというアプローチがいいかなと思います。
また、AutoML Visionで物体検出モデルを学習させるためには、最低でも10枚の画像が必要です。ただし、10枚というのは非常に少ない枚数で、高精度のモデルを目指すのであれば1,000枚程度は必要です。
枚数の目安については、下記のGoogle公式ドキュメントをご参考ください。
https://cloud.google.com/vision/automl/docs/beginners-guide?hl=ja#include_enough_labeled_examples_in_each_category
今回は以下のような画像を28枚撮ってみました。
サンプルなので割と適当に撮影してしまっています。。

5. 物体検出モデルのデータセットを作成する
用意した画像をアップロードして、データセットを登録します。
画像をアップロードするために、GCPのCloud Storageというサービスでアップロード先を予め用意しておく必要があります。
GCPのWebコンソールでCloud Storageのサービス画面を開きます。
https://console.cloud.google.com/storage
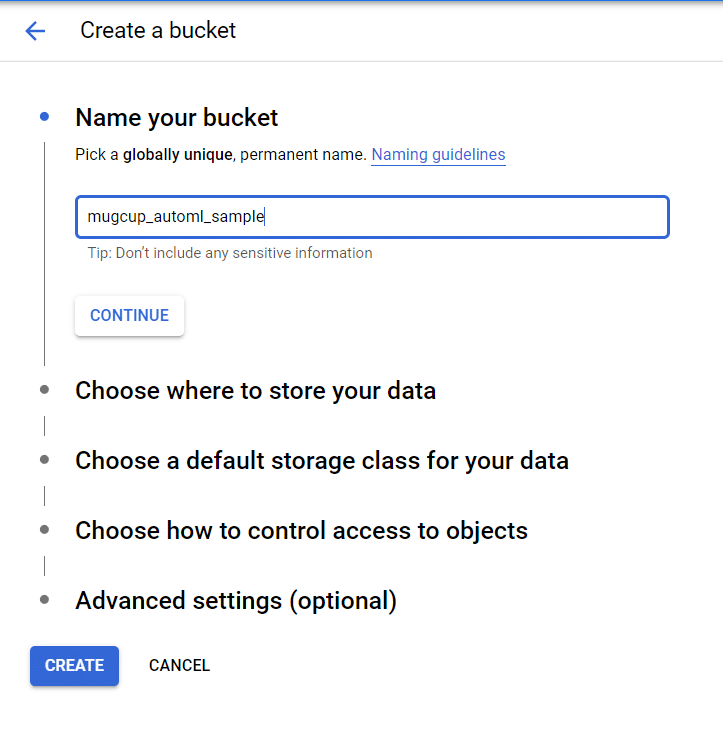
バケットを作成するというリンクをクリックし、下図のように適当なバケット名を入力して作成ボタンをクリックします。
そうすると、バケットが作成されるので、その中に入ってさらに検出モデル用の画像をアップロードするためのフォルダを下図のように作成しておきます。
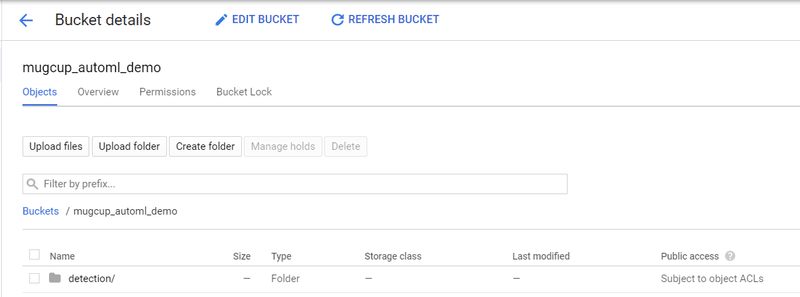
これでアップロードするための準備はできましたので、AutoML Visionのデータセット画面を開き、新しいデータセットをクリックして、画像をアップロードしていきます。
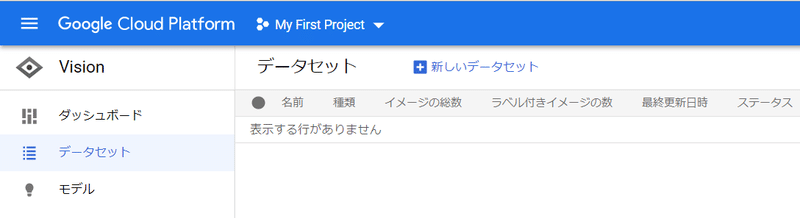
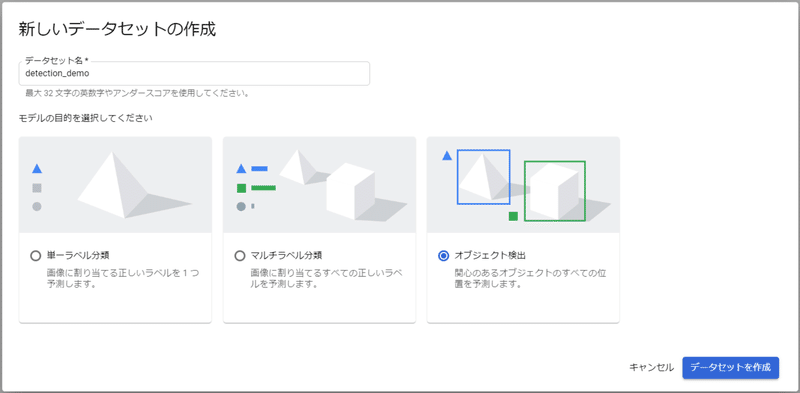
今回は物体検出モデルを作成するので、下図のようにオブジェクト検出を選択し、データセット名を入力して作成します。
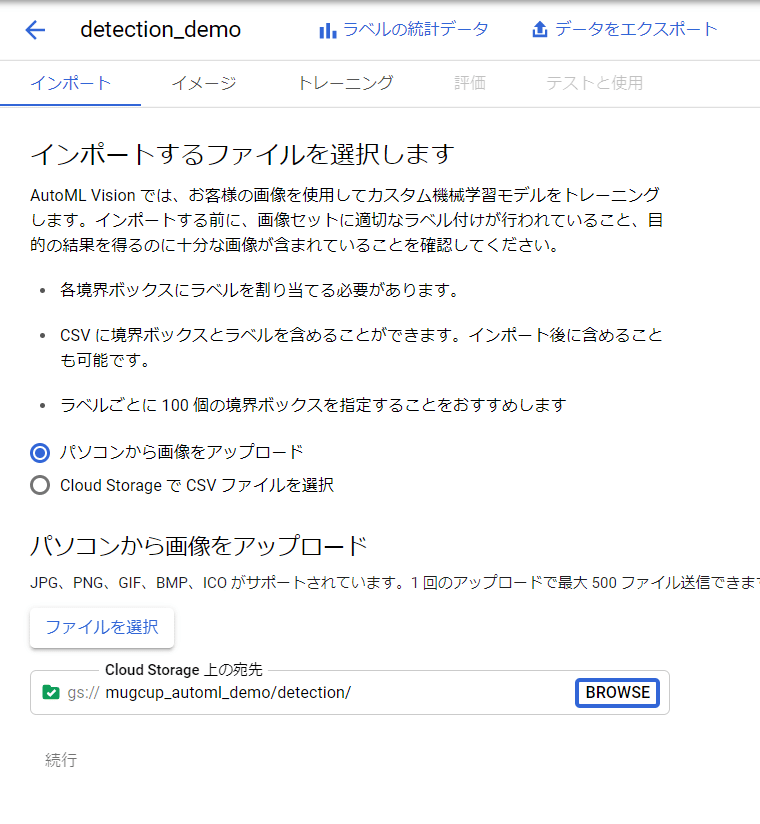
アップロードする画像をPCから選択し、アップロード先は先ほど作成したCloud Storageのフォルダを選択します。
実際に画像をアップロードして、AutoML Visionでインポートが完了すると下図のような画面が表示されます。
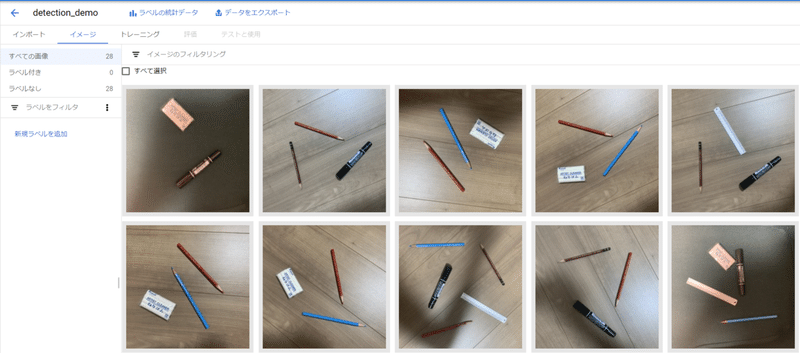
これで学習に使う画像の登録は完了しました。
次に学習させたい内容 =『文房具が写っている位置』を設定していきます。
この作業のことをラベリングやアノテーションと言ったりします。
AutoML VisionではWebコンソール上でラベリングを行うことができるようになっています。
まずは、画像に付与していくラベルそのものを作成します。
ここで言うラベルはモデルが検出する物体の名前のことで、今回は"stationery"としておきます。
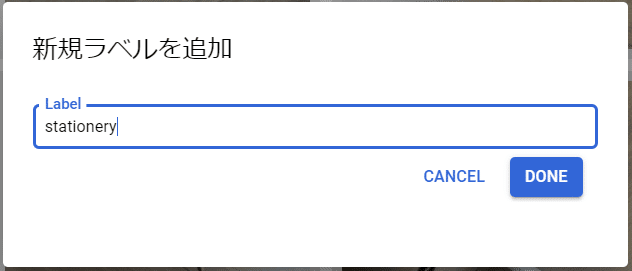
新規ラベルを追加をクリックし、下図のようにラベルを追加します。
※今回は簡単にするため一つのラベルしか登録していないですが、物体検出は通常マルチラベル分類を行うこともできるので、stationeryではなくeraserやpencilといった具体的な名前をラベルとして登録し、使用することができます。
そうするとラベルが追加されるので、実際にラベリングの作業を行っていきます。表示されている画像をクリックすると、ラベリングを行える画面が表示されます。そこで、下図のようにボックスを描画し、画像中に文房具が写っている場所を設定します。

設定できたら左下の保存ボタンをクリックし、その横に表示されている右矢印のアイコンをクリックして全ての画像にこの作業を行っていきます。
モデルを作成する作業において、学習用の画像を集める部分と、ラベリングの作業が最も大変で時間のかかる工程です。。
下図のようにボックスが重なってしまっても良いですが、ボックス内にぴったり物体が収まるように設定していきます。

ひたすら設定していきます。。
単純作業の連続なので、28枚ならまだ全然マシな方ですが1,000枚ともなるときついですよね。仕事では、大量のラベリング作業は人海戦術で行うこともあります。
大体10分くらいで28枚全ての画像にラベリングすることができました。

これで画像と学習させたい内容を設定したデータセットの作成が完了です。
6. 物体検出モデルを学習させる
それではいよいよ用意したデータセットを使用してモデルを学習させてみます。トレーニングというタブを開き、トレーニングを開始をクリックします。
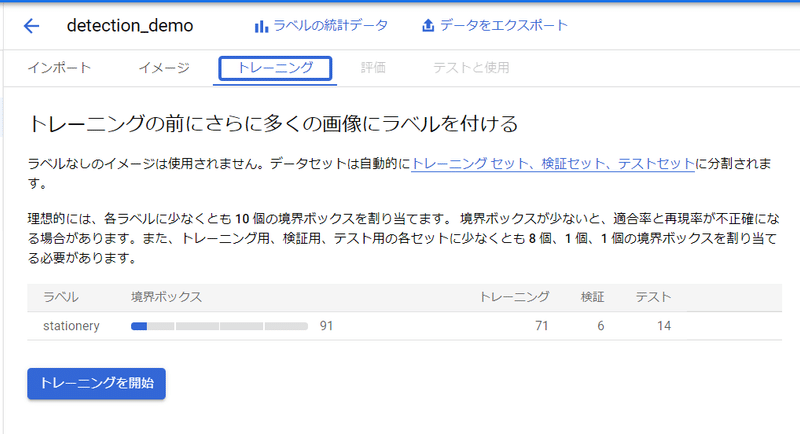
トレーニングの設定はそれぞれ下図のように設定しました。
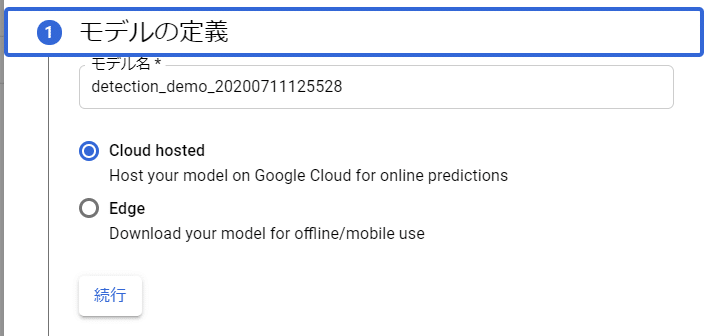
最初の設定ではモデルを使われ方を決めます。最終的に学習したモデルをクラウド上に配置してWebAPI経由で使用する場合はCloud hostedを選択し、モバイルアプリなどに組み込んで使用する場合はEdgeを選択します。
今回はCloud hostedを選択しました。
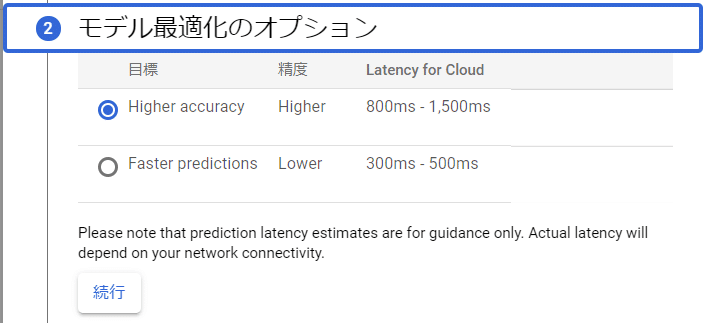
次に最適化オプションですが、予測精度をよくするかわり予測に必要な時間が長くなってしまう設定か、予測精度が落ちるかわりに予測に必要な時間が短縮される設定のどちらかを選択します。
今回は高精度設定を選択しました。
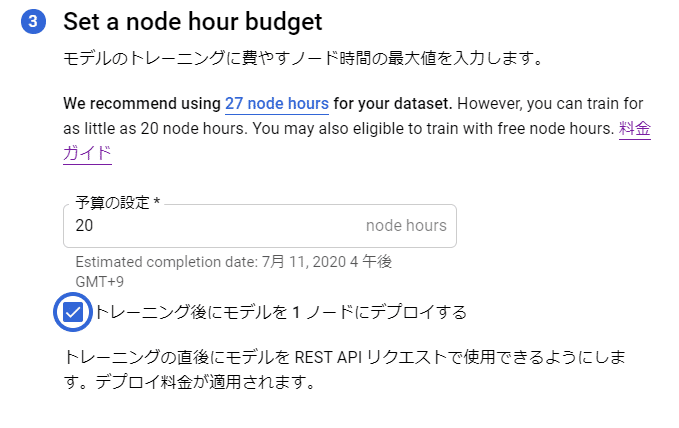
次に学習させる際の予算を設定します。"ノード時間"という特殊な単位ですが、ここの数値を増やせば増やすだけ時間をかけて学習してくれる代わりに費用が高くなります(現在は初回40ノード時間分は無料です)。
ただし、AutoML Visionがこれ以上学習させても精度が向上しないと判断した時点で学習は停止されますので、設定した予算が必ずしも全て使用されるという訳ではありません。
今回は最低値の20ノード時間を設定しました。
※初回利用でない方は料金が発生しますので、ご注意ください。
料金についての詳細は下記をご確認してください。
https://cloud.google.com/vision/automl/pricing?hl=ja&#object_detection
また、Cloud hostedのモデルを利用するためには、デプロイしておく必要があるため、学習後に自動的にデプロイされる設定を有効化しておきます。
モデルをデプロイすると費用が発生するため、使わなくなった後はデプロイを停止することを忘れないようにしてください(停止の方法は後述しています)。
※デプロイとは、学習済みモデルをサーバーにアップロードして、WebAPI経由でそのモデルに予測を行わせる環境を用意することです。
トレーニングが開始されると下図のように表示されます。
モデルの学習が完了すると下図のような表示になります。
おおよそ1時間弱トレーニングしていたような気がします。
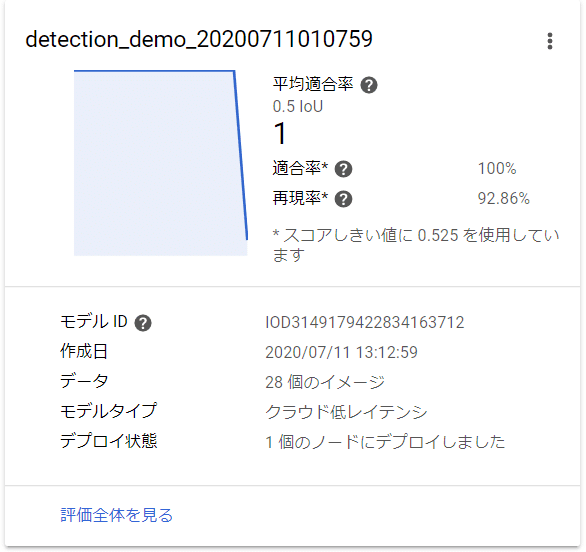
評価全体を見てみると、このモデルの精度やどの画像をどんなふうに予測したかを確認することができます。
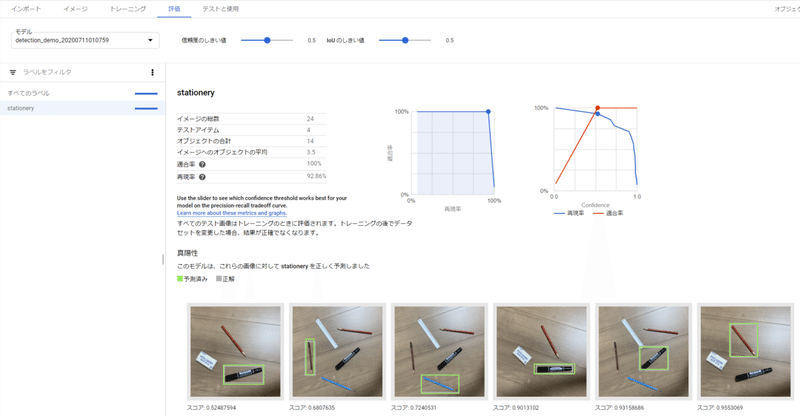
7. 学習させた物体検出モデルを使用してみる
それでは学習させたモデルを使用して、学習には使用していない画像を与えたときに正しく文房具の位置が検出されるか確認してみます。
テストと使用というタブから画像をアップロードして予測させてみることが可能です。
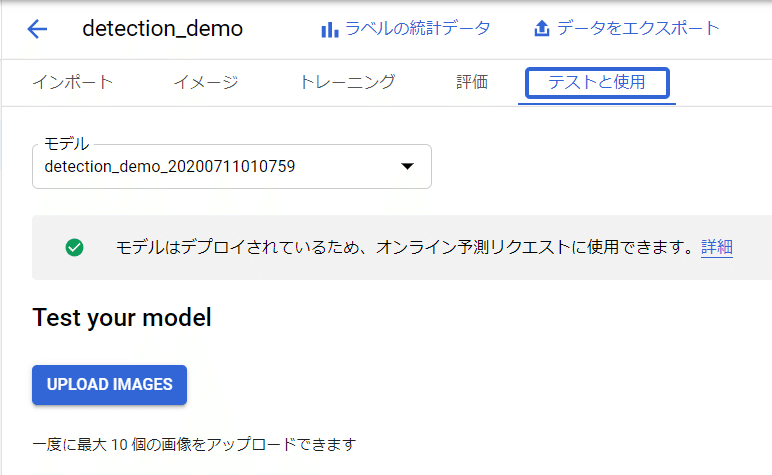
アップロードボタンをクリックして今回新たに用意した画像をアップロードしてみました。

このように上手く検出できていることがわかります。
今回はテストとして手動で画像をアップロードして物体の位置を検出させましたが、Pythonスクリプトや任意のアプリケーションからWebAPI経由で物体検出を実行することができます。
そうすることで物体検出を自動化して、画像中からモノが写っている部分だけをトリミングした画像を生成したり、動画に応用することで人が映っている部分を追跡したりすることができます。
機械学習のモデルの使い方は発想しだいですので、ぜひ自分の用途を探してみてください。
アプリケーションからAutoML Visionで作成したモデルを使用する方法は、また別の記事でご紹介したいと思います。
8. モデルのデプロイを停止する
モデルをデプロイしたままだと費用が継続的に発生してしまいますので、今回使用したモデルのデプロイを解除しておきます。
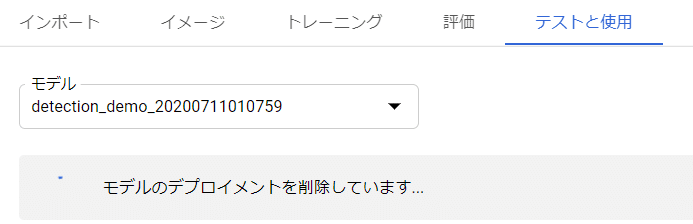
先ほどのテストと使用のページからデプロイメントを削除をクリックすることで解除することができます。

下図のように表示されれば、そのうち削除されています。
おわり
今回はGCPのAutoML Visionというサービスを利用して物体検出モデルを作成する方法を記事にしました。
また、別の記事で物体認識モデルを作成する方法やアプリケーションからAutoML Visionで作成したモデルを利用する方法をご紹介したいと思います。
この記事が気に入ったらサポートをしてみませんか?