
医療統計で必要なtable1、集計からofficeに貼り付けるまでをgtsummaryパッケージで一気に行う

*更新日:2020/09/28
*記事を大幅に追加
*最終更新日:2020/09/30
*gtsummaryのバージョンが上がったことでインストールのコードを一部修正
医療統計に限らず、データを分析する時に集計表を出す場面は多くあります。
特に医療統計では表1(table1)として図表の最初に提示することが多いです。

ポスター発表だとPower Pointでしょうか。
論文であればWordを使うかもしれません。

このtable1を作る時は基本次のような作業が必要になります。
Excelで集計
コピー
WordやPower Pointに張り付け、もしくは手打ち
体裁を整える
これが意外とめんどくさい作業なのですがRを使えば一度に行えます。
Excelでデータを集める
Rで集計→体裁を整える→Word, Power Point, 図として出力する
今回はgtsummaryパッケージを紹介します!
そしてこの記事を書いている最中にgtsumarryパッケージの作者であるDaniel Sjobergさん(@statistishdan)より直接アドバイスを頂きました。この場を借りてお礼申し上げます。
I would love to hear your thoughts on areas where gtsummary can be improved! 🕺Message me on Twitter, or connect on GitHub 🤩
— Daniel Sjoberg (@statistishdan) September 12, 2020
改善点やリクエストがあれば連絡が欲しいとのことでした。自分もいくつかリクエストさせていただきましたが、疑問点や改善点あればご指摘いただければ連絡してみるのはいかがでしょうか。
1.データの準備
今回はこちらのデータを使います。まとめてコピペして実行してください。
今回は治療(0:対照群、1:治療群)として分けていきます。
set.seed(1)
年齢 <- floor(rnorm(100,60,10))
性別 <- sample(c("男性","女性"),100,replace = TRUE)
体重 <- floor(rnorm(100,60,7))
MMT <- as.numeric(sample(c(1:5), 100, prob = c(0.1,0.1,0.2,0.3,0.3), replace = TRUE))
術側 <- sample(c("右","左"),100,replace = TRUE)
治療 <- sample(c(0,1),100,replace = TRUE)
data <- data.frame(年齢,性別,体重,MMT,術側,治療)
head(data)2.パッケージの読み込み
一言でいうとパッケージとはRの機能を拡張してくれる機能の事です。
今回は5つのライブラリを使います
packman(パッケージのインストール・呼び出しに使う)
gtsummary(table1や結果の表をいい感じにまとめてくれる)
tidyverse(データの集計などに使用。今回はサブ的に使う)
gt(gtsummaryのデータをもっと細かく修正することができる。gtsummaryだけで完結するので必要ないが、表のタイトルやサブタイトルを付け加えたかったら必要)
flextable(できた表をWordやPower Point形式に貼り付ける際、gtsummaryよりも細かいく修正することができる。gtsummaryだけで完結するので必要ないが、表のタイトルやサブタイトルを付け加えたかったら必要)
#上記パッケージがインストールされていなければネットに繋いで以下を実行
#インストール済みならネットにつながっていなくてもOK
#packmanパッケージが入っていない方はインストールする
if (!require("pacman")) install.packages("pacman")
#残りのパッケージを読み込む
pacman::p_load(
gtsummary,
gt,
flextable,
tidyverse
)3.表を作る前に確認しておくこと
table1はそもそも各群のベースラインを比較します。
そのためには各変数(評価)がどんなデータか理解している必要があります。
数値かカテゴリーか?
集計を行うにはその変数が数値なのか?カテゴリー変数なのか?の理解が必要です。
数値:年齢・体重
カテゴリー:性別、MMT、術側
MMTは「1が7人、2が5人・・・」と集計を行いたいとすると、値は数値ですがカテゴリー変数として集計を行う必要があります。
数値の場合は正規分布なのか?そうでないのか?
同じ数値でも正規分布かそうでないのか?を決めておくことが必要です。
正規分布であれば平均±標準偏差ですが、正規分布でない場合は中央値(四分位範囲 or 最大値〜最小値)で表現したりします。
4.基本的な使い方
今から実際にgtsummaryを使っていきます。
まずは作ってみる
集計表を作るのはtbl_summary()関数を使います。
dataのデータをtbl_summary関数に入れ込みます。
これを表現するとdata %>% tbl_summary()と表記します。
%>%はパイプ演算子といい、最近Rでデータを扱う時の主流となっています。
%>%はtidyverseパッケージを読み込むことで使えます。最新バージョンではtidyverseパッケージを読み込まなくても |> も同じ役割をしますがここでは%>%を使って説明します。
data %>%
tbl_summary()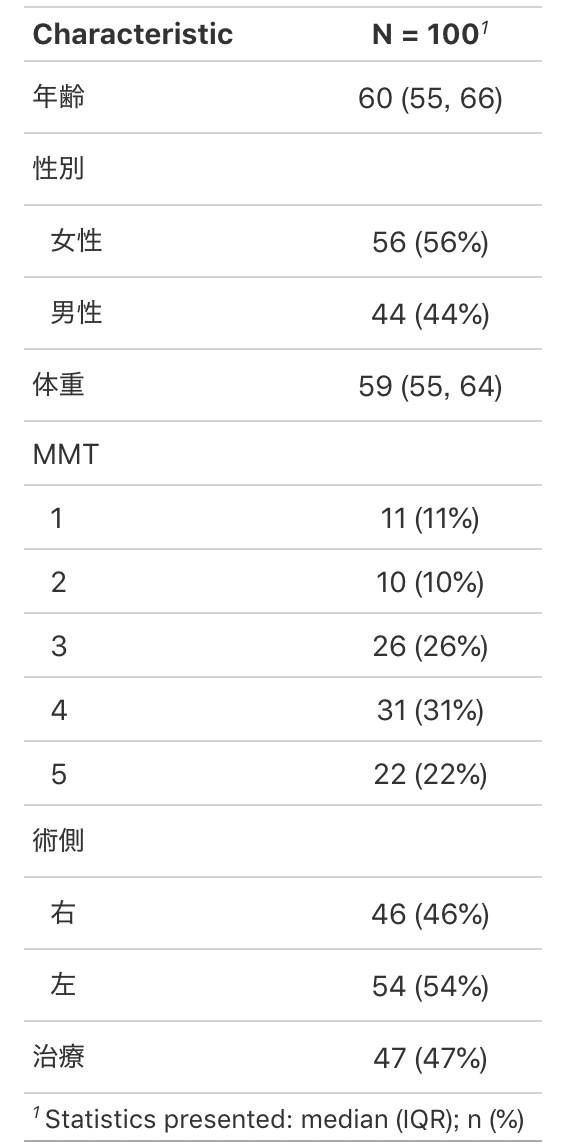
とりあえず集計表ができました!ただ群別に表示がされていないので群を分けます。tbl_summary(by = 群分けする列名)のようにby=○○を付け加えるだけです。
data %>%
tbl_summary(by = 治療)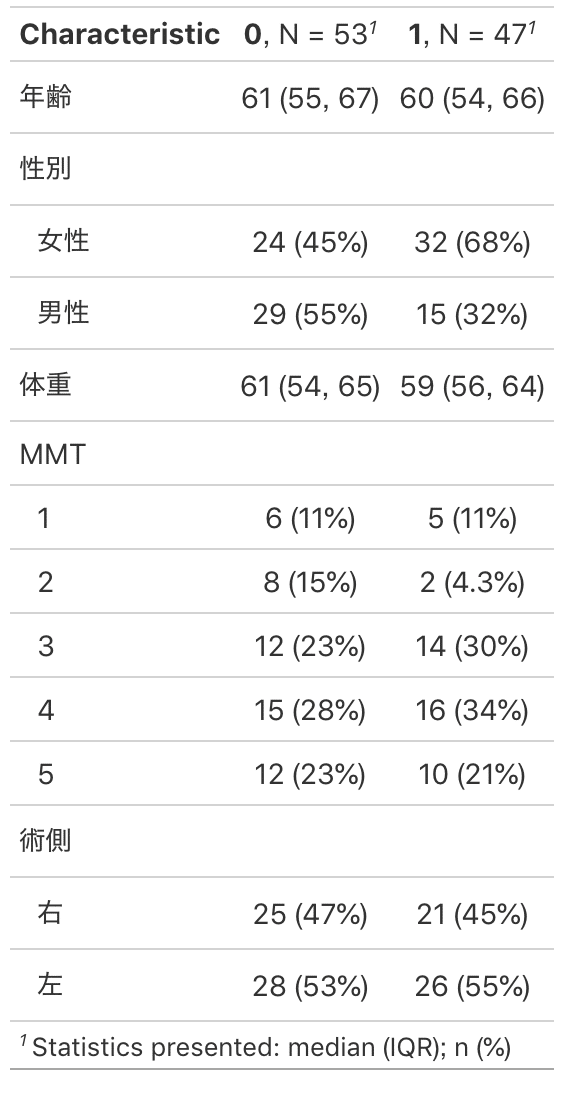
5.テーマを決める
gtsummaryはいくつかのテーマ(設定)があります。
表の細かい修正の前にテーマについて紹介します。
ジャーナルに合わせたテーマに変える(JAMA / LANCET)
日本語にする
デフォルトの中央値(四分位範囲)を平均(標準偏差)に変える
列幅を狭める
元の設定に戻す
ジャーナルに合わせたテーマに変える(JAMA / LANCET)
table1といっても投稿するジャーナルで投稿規定が違います。
gtsummaryでは現在JAMAとLANCETのに合わせたテーマがあります。
#JAMAの投稿規定に合わせる
theme_gtsummary_journal(journal = c("jama"), set_theme = TRUE)
#LANCETの投稿規定に合わせる
theme_gtsummary_journal(journal = c("lancet"), set_theme = TRUE)
#元の設定に戻す
reset_gtsummary_theme()日本語にする
英語→日本語にする機能もあります。
#日本語にする
theme_gtsummary_language("ja")
#元の設定に戻す
reset_gtsummary_theme()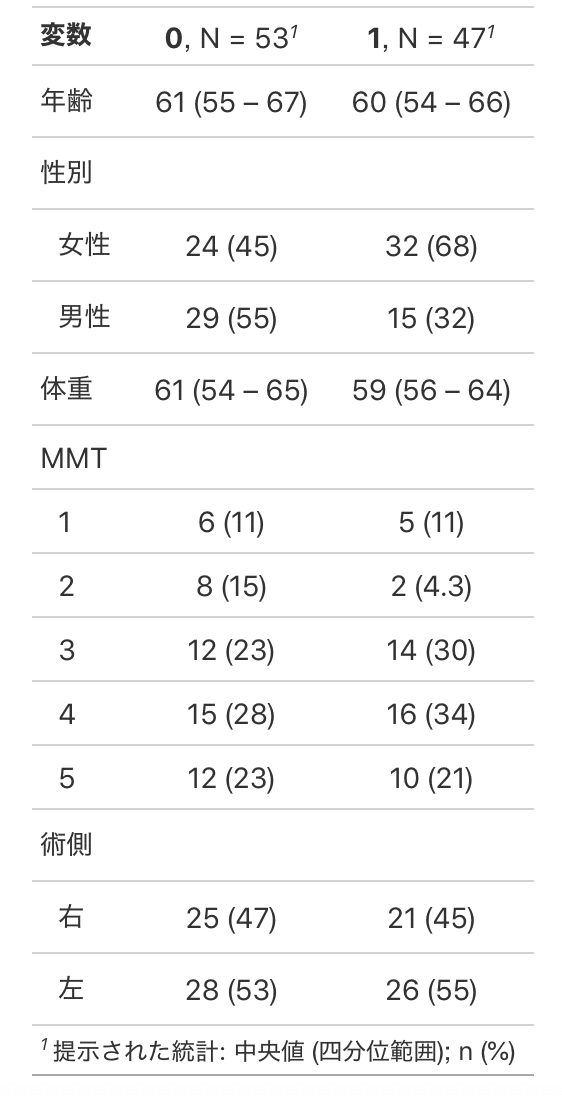
デフォルトの集計・検定を中央値(四分位範囲)を平均(標準偏差)に変える
gtsummaryではデフォルトの集計・検定方法がノンパラメトリックとなっています(中央値・四分位範囲・Wilcoxonの順位和検定など)。
医療統計では平均(標準偏差)で表現することが多いです。個別に設定する方法は後ほど説明しますが、デフォルトでパラメトリックにする設定があります(平均・標準偏差・t検定など)。
#平均と標準偏差にする
theme_gtsummary_mean_sd()
#元の設定に戻す(中央値・IQRとwilcoxonの順位和検定)
reset_gtsummary_theme()幅を狭くする
できた表はゆとりがありますがコンパクトにまとめることもできます。
theme_gtsummary_compact()を実行するだけです。
#幅をコンパクトにまとめる
theme_gtsummary_compact()
#もとの設定に戻す
reset_gtsummary_theme()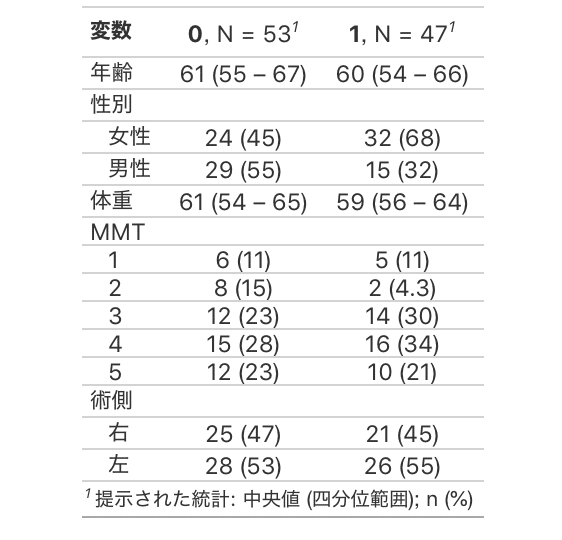
設定を戻す
今まで説明したtheme_gtsummary_〇〇関数ですが、全てrecet_gtsummary_theme()を使えばデフォルトの設定に戻ります。
reset_gtsummary_theme()6.p値の列を作る
次にp値の列を作ります。
作り方は%>%を使い、先程のコードにadd_p()を加えるだけです。
data %>%
tbl_summary(by = 治療) %>%
add_p()
注釈までつけてくれました。
年齢と性別にはWilcoxonの順位和検定(マン・ホットニーのU検定)、
性別と術側にはカイ二乗検定、
MMTにFisherの正確確率検定が使われています。
「Wilcoxonの順位和検定じゃなくてt検定にして欲しい」に関しては先程説明したデフォルトの集計・検定を中央値(四分位範囲)を平均(標準偏差)に変えるをご参照ください。中には平均±標準偏差にしたり、これは平均だけどこっちは中央値など細かい調整をしたい場合もあるかもしれません。細かい設定は下にある14.集計方法を変更するをご参照ください。
7.N数を加える
人数を加える場合はadd_n()を加えます。
data %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_n() 
8.全体の集計の列を作る
もし全体の集計列を加えたければadd_overall()を加えます。
今回はadd_n()を外してadd_overall()を加えていますが、もちろんどちらも加えることも可能です。
data %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall()
9.変数名を太字にする
このままでもいいですが、変数名を太字にしてわかりやすくします。
bold_labels()を使います。
data %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels()10.出力する
まだまだ調整は必要ですが、とりあえずここで出力してみます。

出力には出力のファイル形式(docやpdf,図など)にあわせてgtsummary内の型を変える必要があります。
出力の形式はgt,kable,flextableなどがあります。
デフォルトはgtとなっています。
gtとはRだけでいい感じの表を作るためのgtパッケージの形式です。
今まで見てきた表です。確かにとても綺麗です。
綺麗です。 https://t.co/iO4k6Dm3wy
— 米元佑太 (@yutayonemoto) September 11, 2020
HTMLの場合
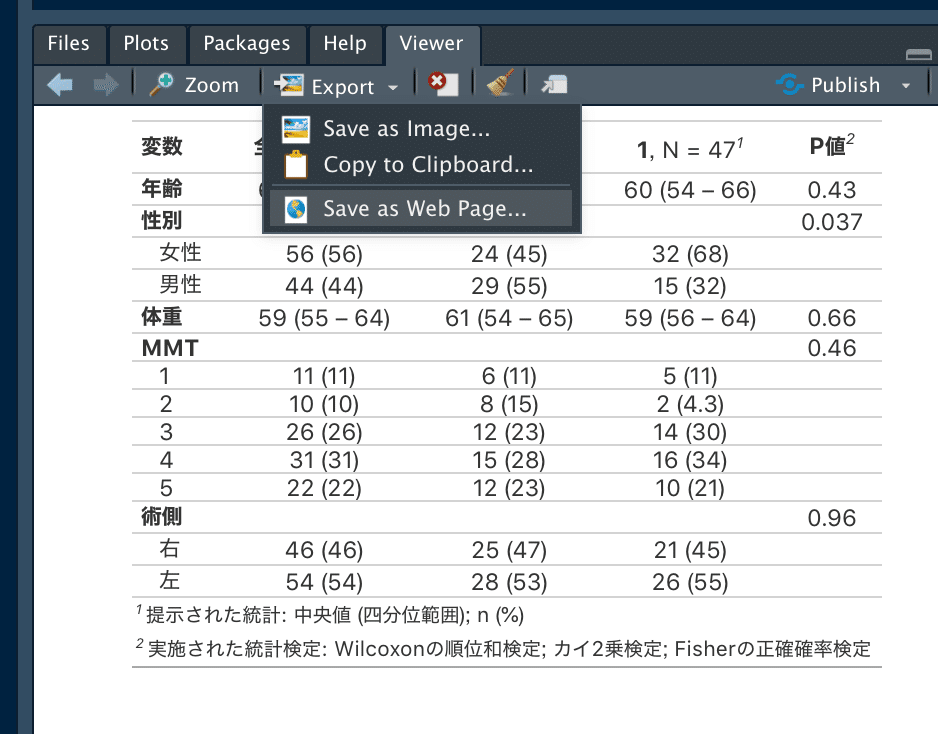
HTML形式の場合はこのまま出力できます。
右下のViwerからSave as Web Pageを選択します。
Save as ImageやCopy to Clipboardは日本語が入るとうまく機能しません。
画像として残したいならパソコンでスクリーンショットを撮ったほうが早いです。
Office(Word, Power Point)の場合
Officeの場合はflextable形式に変換します。
先程のコードにas_flex_table()を加えます。
そしてtable1(他の名前でもいい)という変数を付けます。
今までずっとtheme_gtsummary_compact()を設定していたので小さなサイズの表になっています。
今回は一度リセットし再度日本語にした状態で行ってみます。
reset_gtsummary_theme()
theme_gtsummary_language("ja")
table1 <-
data %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels() %>%
as_flex_table()
table1
次にこれをWordやPower Pointに変換しますが1行のコードでできてしまいます。
手っ取り早く変換するにはprint(今作った変数名, preview="○○")を使います。
preview="○○"はpreview="docx"かpreview="pptx"の2択です。
#Wordで開く場合
print(table1, preview = "docx")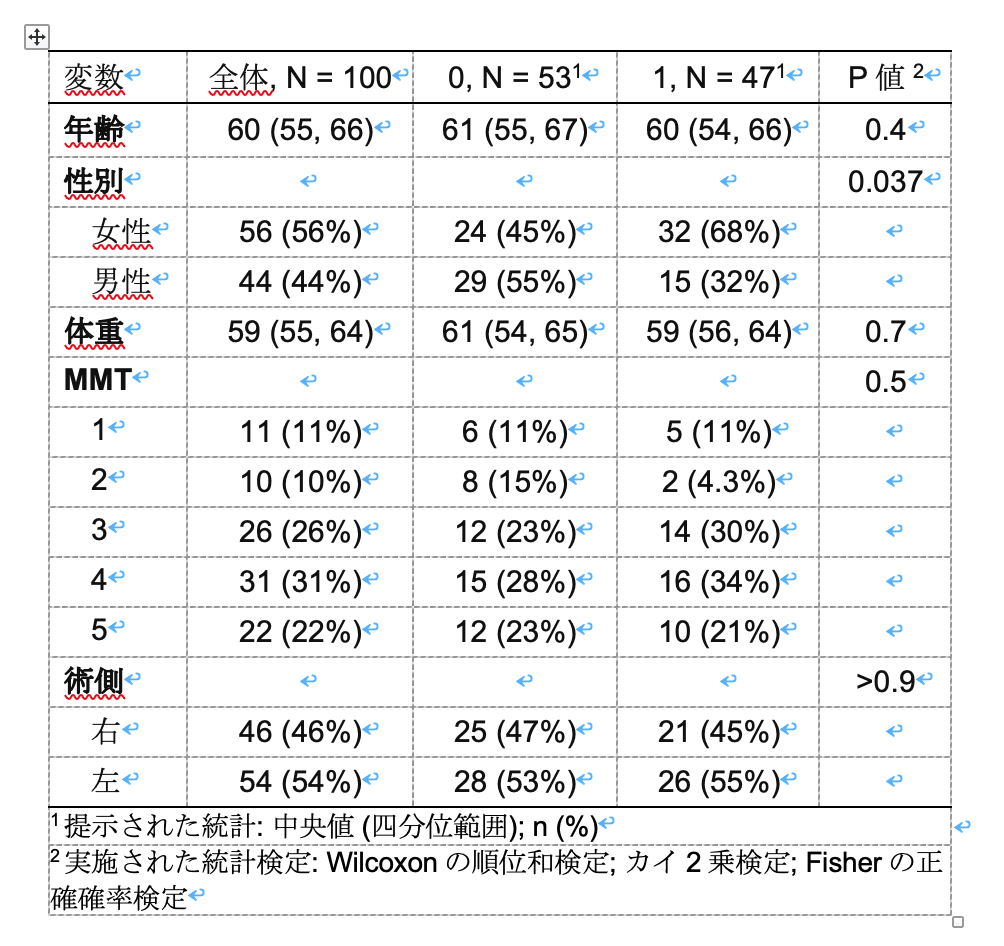
#Power Pointで開く場合
print(table1, preview = "pptx")
どうでしょうか!!!この後の文字サイズや修正もWordやPower Pointで直接できてしまいます!これだけでもかなり時短になるかと思います。
ただ集計方法を平均(標準偏差)やt検定を使うためにはもう少しコードを変える必要があります。
11.様々な箇所を修正する
ここからは応用編になりますが、gtsummaryは色々な箇所を変更することができます。
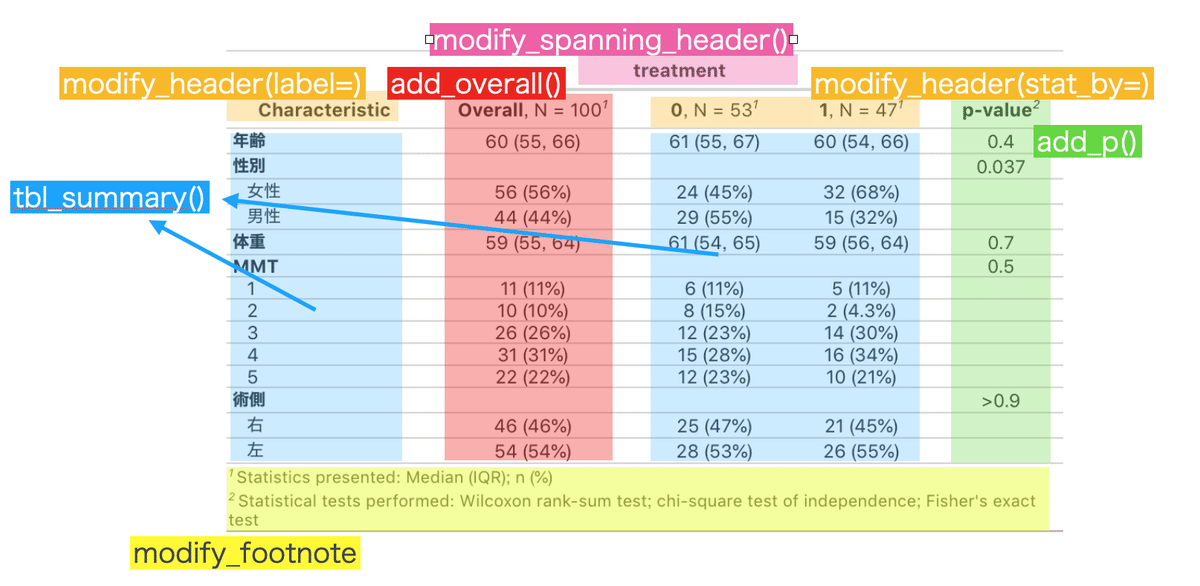
変数の順番を変えたい、いらない変数を減らしたい:
gtsummaryの前に修正しておく列内の文字の修正(0→対照群):gtsummaryの前に修正しておく
集計の方法や表示を修正したい:tbl_summary()
検定の方法を変えたい:add_p()
左上のCharacteristicを変えたい:modify_header(label=)
ヘッダーを編集したい:modify_header(stat_by=)
overallの列を編集したい:add_overall()
ヘッダーの上にもう一つ追加したい:modify_spanning_eader()|
Nの列を編集したい:add_n()
脚注を編集したい:modify_footnote()
タイトル、サブタイトルを加えたい:
gtsummaryで直接できない。(gtパッケージやflextableパッケージで編集する)
12.変数を並べ替えたい
変数はdataの変数の並んでいる順になっています。そのため並べ替えるにはgtsummaryを使う前にdataの並び順を変える必要があります。
dataを並べ替えるにはtidyverseパッケージのselect関数を使います。
data %>% select関数で並べ替える %>% tbl_summary() %>% ・・・とtbl_summary()の前に入れます。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels()
13.列内の文字の修正(0→対照群など)
今は治療が0,1となっています。
修正するにはgtsummaryの前にdataのデータ自体を修正します。
列を修正するにはmutate関数を使います。先ほどと同じでtbl_sumamry()の前に入れます。mutate()の中はfactor関数を使います。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels()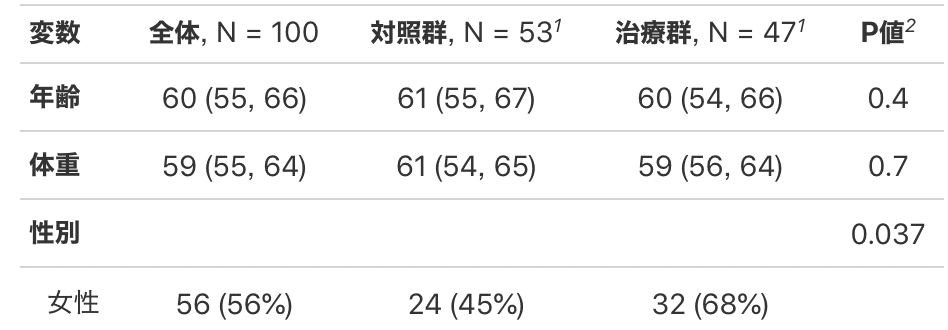
14.集計を変更する(tbl_summaryのいろいろな設定)
集計方法を指定するのはtbl_summary()です。
公式ドキュメントはこちら
Yep, the list looks great! In this case, you wouldn't need the `c()` portion, e.g.
— Daniel Sjoberg (@statistishdan) September 11, 2020
tbl_summary(by = A,
statistic = list("年齢" ~ "{mean}({sd})",
"体重" ~ "{median}[{p25},{p75}]"))
add_p(list("年齢" ~ "t.test",
"体重" ~ "wilcox.test"))https://t.co/Uf7XVnwpzg pic.twitter.com/2OjcgKZWE2
既にby=は説明していますが、ここではtype(変数のタイプ)、label(一番左の変数名)、statistics(集計方法)、digits(小数点第何位まで示すか)を紹介します。
どれも○○ =変えたい変数名を選択 ~ 何に変えるかといった表記方法になります。
14−1.集計のタイプを指定する(type=)
今回のデータでいうと、MMTはカテゴリーとして表にする予定で特に修正は必要ありませんでした。もしMMTがカテゴリーでなく数値として認識されるとこうなります。
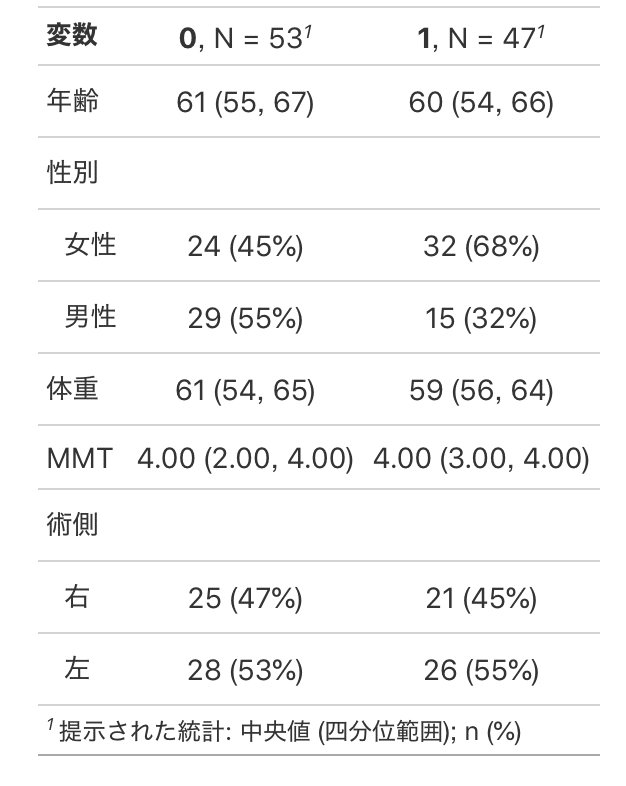
これは列ごとに集計のタイプが決まっているからです。
タイプというのは以下のの3種類です。
"continuous(数値)"
"categorical(カテゴリー)"
"dichotomous(2択)"
gtsummaryでは自動的にタイプを決めてくれるのですが、もし変更したい場合場合はtbl_summary()内でtype = 変えたい変数名 ~ "○○"を加えます。
○○は先程の3択です。
例えばMMTをカテゴリー変数として扱いたければ以下のようになります。
data %>%
tbl_summary(by = 治療,
type = MMT ~ "categorical")14−2.一番左の変数名を変更する(label=)
左の列は変数名が載っていますが、単位など付け加えたい場合もあります。
変数名を直接編集したい場合はtbl_summary()のlabel=""で編集します。
もし変えたい変数が2つ以上の場合はlist()を使う必要があります。
下の2つのコードはlabel=しか変わっていないので見比べてください。上のツイートも参考になります。
#変えたい列が1つだけのとき
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療,
label = 年齢 ~ "年齢(歳)") %>%
add_p() %>%
add_overall() %>%
bold_labels()
#変えたい列が2つ以上の時はlist()の()内に入れる
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療,
label = list(年齢 ~ "年齢(歳)",
体重 ~ "体重(kg)")) %>%
add_p() %>%
add_overall() %>%
bold_labels()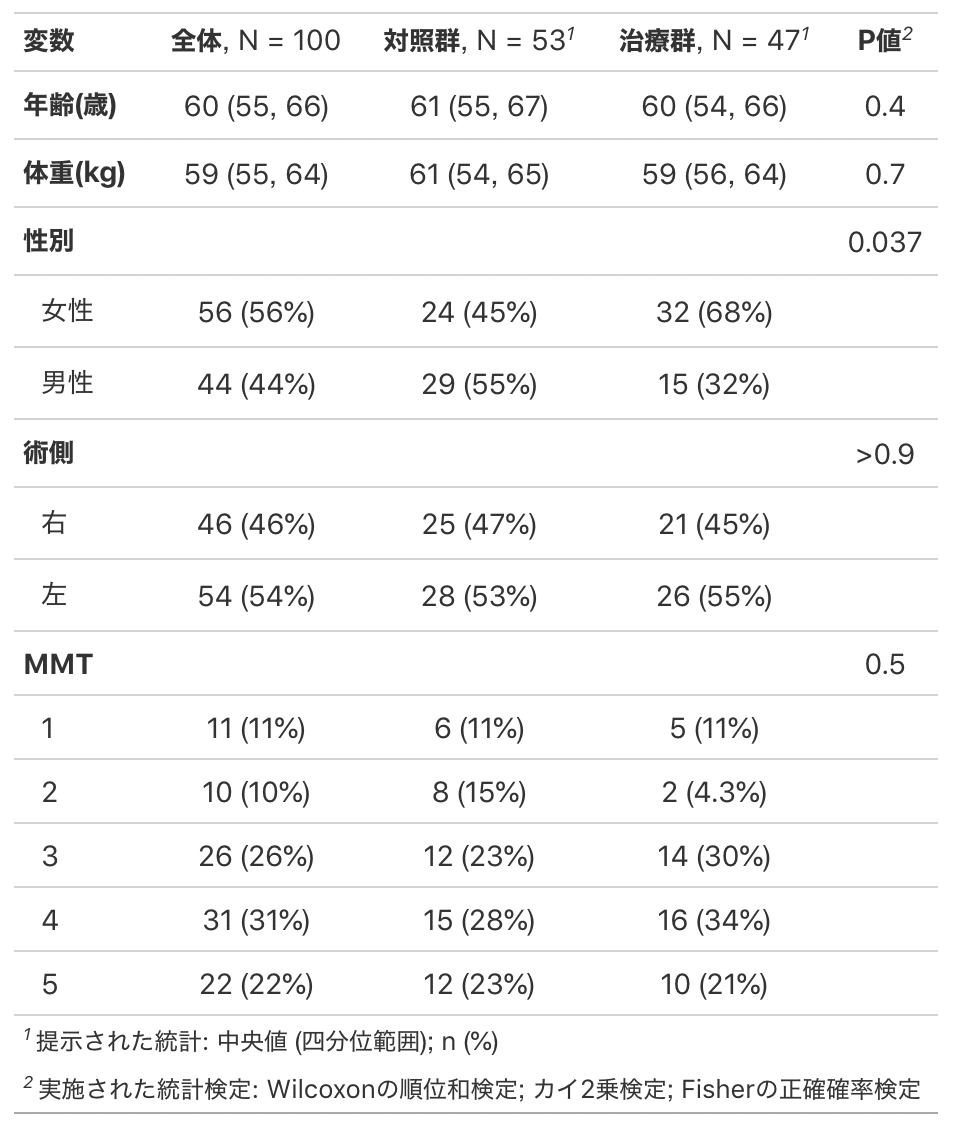
14−3.集計方法を変える(statistic=)
集計方法のデフォルトが中央値(四分位範囲)となっています。
最新バージョン(バージョン1.3.4.9008以降)ではtheme_gtsummary_mean_sd()関数を使えば平均(標準偏差)になりますが、平均±標準偏差や平均と中央値を同時使いしたい場合はtbl_summary()内でstatistic=○○を指定します。
tbl_summary(statistic = 変えたい変数名 ~ "集計方法")という書き方をします。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = c(年齢, 体重) ~ "{mean}({sd})") %>%
add_p() %>%
add_overall() %>%
bold_labels()
今回はc(年齢, 体重)と列名を指定しました。
もし全ての数値の列を選びたい時はall_continuous()を使うこともできます。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = all_continuous() ~ "{mean}({sd})") %>%
add_p() %>%
add_overall() %>%
bold_labels()もし年齢だけ指定すると、年齢は平均(標準偏差)、体重はデフォルトの中央値(四分位範囲)となります。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = 年齢 ~ "{mean}({sd})") %>%
add_p() %>%
add_overall() %>%
bold_labels()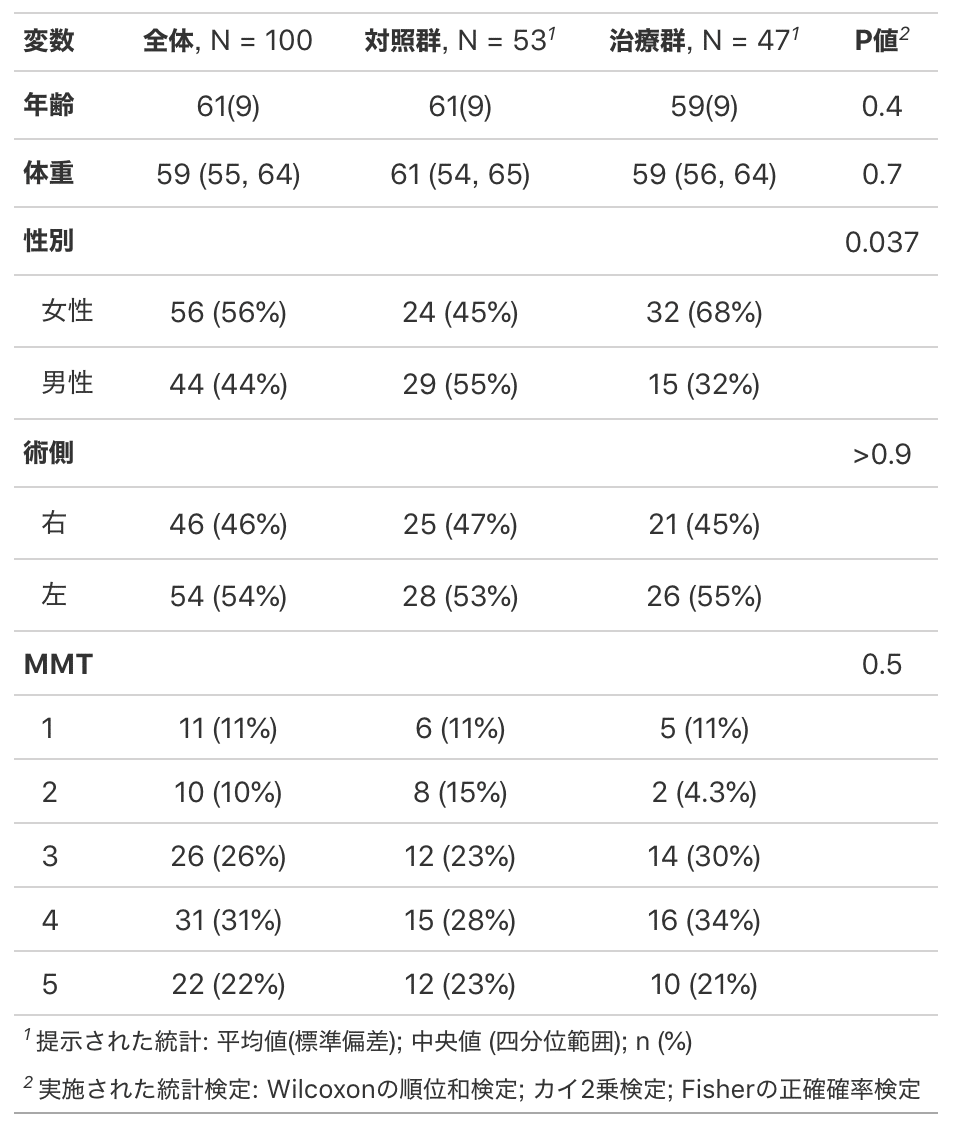
もし中央値[四分位範囲]など2箇所変更するならlabel=の時と同様にlist()を使います。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = list(年齢 ~ "{mean}({sd})",
体重 ~ "{median}[{p25},{p75}]")) %>%
add_p() %>%
add_overall() %>%
bold_labels()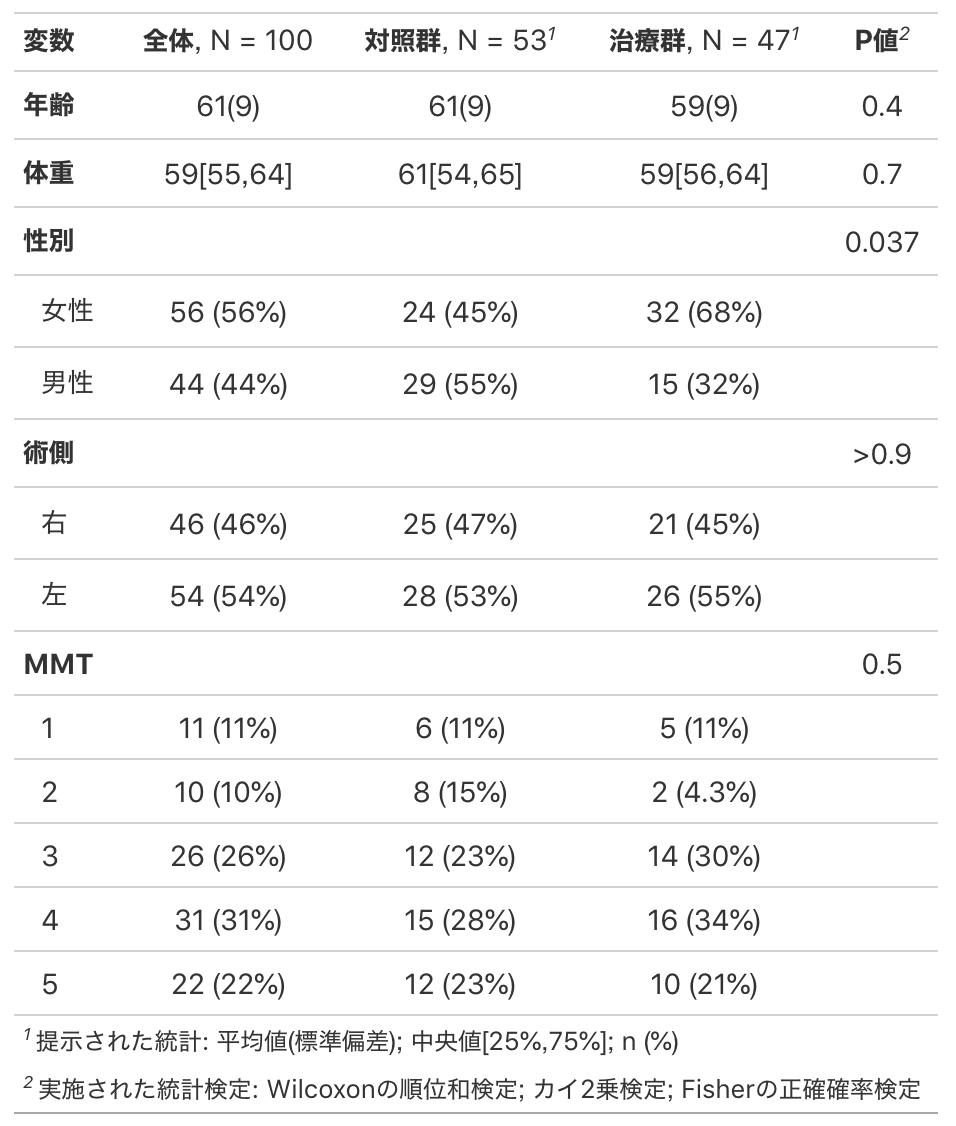
ここで右側の説明を行います。
{集計方法}とすることで集計ができます。{}に入っていない箇所はその文字がそのまま使われます(ここでは( )や[]やカンマなど黒文字の箇所。%や人など文字を入れることも可能)。

他にも集計方法はあります。
{n}:集計した人数
{p}:集計した人数の%
{N}:母数
{p○○}:○○%時の値(0から100の数値を指定。"{p10},{p90}"など)
{var}:分散
集計方法を変えると自動的に脚注が変わるのもありがたいところです。
もし平均±標準偏差にしたい場合はどうしたらいいでしょうか?
"{mean}±{sd}"とすればOKです。±の間にスペースを入れることだって可能です。
14−4.小数点をあわせる(digits=)
デフォルトでは整数になっていますが、小数点第何位まで指定することができます。人数は整数(0)がいいですし、小数点第何位で指定したい場合もあります。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = list(年齢 ~ "{mean}({sd})",
体重 ~ "{median}[{p25},{p75}]"),
digits = list(c(年齢,体重) ~ c(1,2),
c(性別,術側,MMT) ~ c(0,1))) %>%
add_p() %>%
add_overall() %>%
bold_labels()
digits = list(c(年齢,体重) ~ c(1,2),
c(性別,術側,MMT) ~ c(0,1)))
~の左側は今までと同様に列の選択を行っています。
今回~の右側は2つ数値を指定しています。
これは{平均}({標準偏差})という2つの数値を使っているからです。
年齢と体重の1つめの1は平均の小数点は第1位、2つめの2は小数点第2位という意味になります。
ここで体重の75%を確認してみてください。小数点第1位になっています。これは体重は{中央値}、{25%}、{75%}の3つの数値を指定する必要があるのに3つ目を指定していないためです。
そのため正しくは以下になります。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = list(年齢 ~ "{mean}({sd})",
体重 ~ "{median}[{p25},{p75}]"),
digits = list(年齢 ~ c(1,2),
体重 ~ c(1,2,2),
c(性別,術側,MMT) ~ c(0,1))) %>%
add_p() %>%
add_overall() %>%
bold_labels()15.add_p()のいろいろな設定
14ではtbl_summary()のいろいろな設定について説明しましたが、今度はadd_p()の設定について説明します。
15−1.検定方法を変える
統計を見るとデフォルトはWilcoxonの順位和検定(マン・ホットニーのU検定)やクラスカル・ウォリス検定といったノンパラメトリック検定となっています。これをt検定や分散分析で行うには修正が必要です。手っ取り早いのは最新バージョンで使えるtheme_gtsummary_mean_sd()です。(上にある5−3をご参照ください)これを使えば集計も検定も自動的にパラメトリックに変わります。
theme_gtsummary_mean_sd()もし個別に修正するにはadd_p(列名 ~ "検定方法")で指定します。2つ以上あればlist()を使います。このあたりの記載は14集計を変更するで説明していますのでさかのぼって確認してみてください。
"t.test" for a t-test,(t検定)
"aov" for a one-way ANOVA test,(1元配置分散分析)
"wilcox.test" for a Wilcoxon rank-sum test,(マン・ホットニーのU検定)
"kruskal.test" for a Kruskal-Wallis rank-sum test,(クラスカル・ウォリス検定)
"chisq.test" for a chi-squared test of independence,(χ二乗検定)
"chisq.test.no.correct" for a chi-squared test of independence without continuity correction,
"fisher.test" for a Fisher's exact test,(フィッシャーの正確確率検定)
"lme4" for a random intercept logistic regression model to account for clustered data, lme4::glmer(by ~ variable + (1 | group), family = binomial). The by argument must be binary for this option.(階層モデルのロジスティック回帰?)
Tests default to "kruskal.test" for continuous variables, "chisq.test" for categorical variables with all expected cell counts >=5, and "fisher.test" for categorical variables with any expected cell count <5. A custom test function can be added for all or some variables. See below for an example.
例えば全ての数値データをWilcoxonの順位和検定でなくt検定にするには add_p(all_continuous() ~ "t.test")となります。
またt検定とWilcoxonの順位和検定を同時使いしたければlistを使って以下のようになります。
data %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
tbl_summary(by = 治療,
statistic = list(年齢 ~ "{mean}({sd})",
体重 ~ "{median}[{p25},{p75}]"),
digits = list(年齢 ~ c(1,2),
体重 ~ c(1,2,2),
c(性別,術側,MMT) ~ c(0,1))) %>%
add_p(list(年齢 ~ "t.test",
体重 ~ "wilcox.test")) %>%
add_overall() %>%
bold_labels()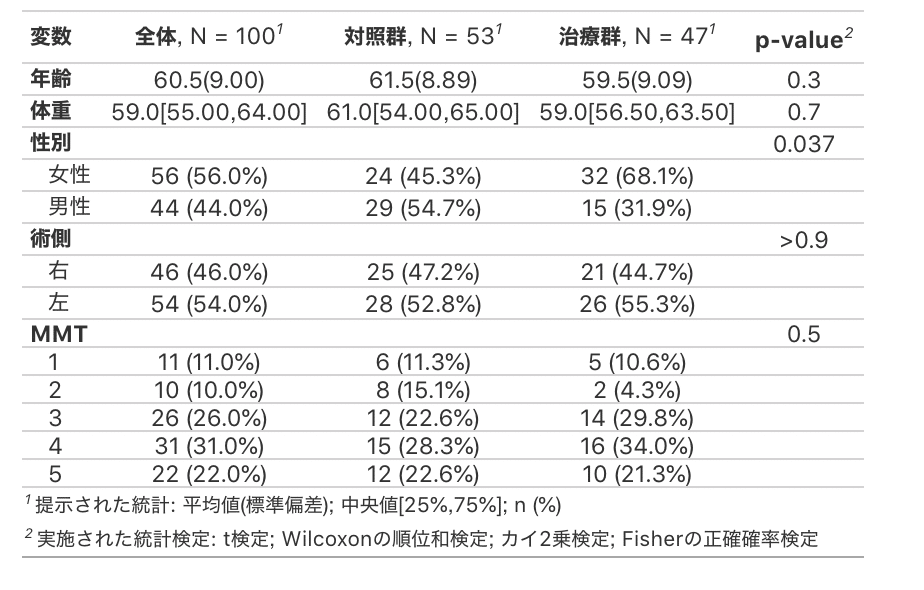
16.左上の変数(Characteristic)を修正したい

左上の「変数(Characteristic)」と書かれている所を編集するにはmodify_header(label="○○")を追加します。
data %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
modify_header(label = "○○") %>%
bold_labels()
17.ヘッダーを編集したい

上の表では対照群, N = 53となっています。
オレンジの箇所をヘッダーといい、変えたり改行するにはmodify_header(stat_by=)で編集します。
<br>は改行記号で、{style_percent(p)}は人数を%で表記することができます。

このような修正も可能です。

一つ前の左上の「変数(Characteristic)」を変えるのもmodify_header(label=)でした。同じ関数なので両方とも修正したい場合はまとめることができます。
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
modify_header(label = "○○",
stat_by = "**{level}**<br>N = {n}") %>%
bold_labels()
よくみると全体(Overall)は改行されていません。これはOverallを修正するのはadd_overall()内になるからです。
18.全体(Overall)の列を修正したい

全体(Overall)に関してはadd_overall()で修正を行います。
先程modify_header()でヘッダーを2段にしました。
ここではOverallのヘッダーも2段にします。
Overallのヘッダーはadd_overall(col_label = "")を使います。

data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall(col_label = "**全体**<br>N = {N}") %>%
modify_header(label = "○○",
stat_by = "**{level}**<br>N = {n}") %>%
bold_labels()
19.ヘッダーの上に列を追加したい

ピンクの箇所になりますが、ヘッダーの上に「治療」などもう一列つけることもできます。modify_spanning_header(starts_with("stat_") ~ "**○○**") とします。starts_with("stat_")は集計をしている列という意味になります。
**で挟まれたところは太字になります。
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall(col_label = "**全体**<br>N = {N}") %>%
modify_header(label = "○○",
stat_by = "**{level}**<br>N = {n}") %>%
bold_labels() %>%
modify_spanning_header(starts_with("stat_") ~ "**ここに文字を入れてください**") 
20.脚注を編集したい
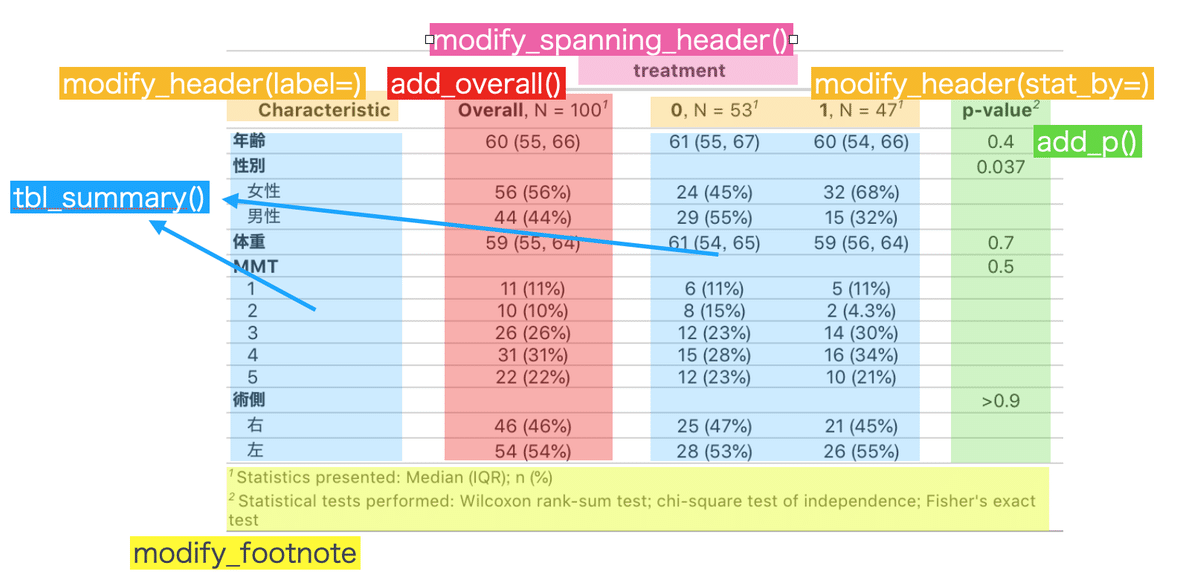
脚注(黄色)の箇所はmodify_footnote()で編集します。
脚注自体をなくす
modify_footnote(update = everything() ~ NA)を追加。集計方法(1となっている列)を編集
modify_footnote(update = starts_with("stat_") ~ "○○")を追加。検定(2となっている列)を編集
modify_footnote(update = starts_with("p") ~ "○○")を追加。
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
modify_footnote(update = starts_with("stat_") ~ "11111") %>%
modify_footnote(update = starts_with("p") ~ "22222") %>%
bold_labels()
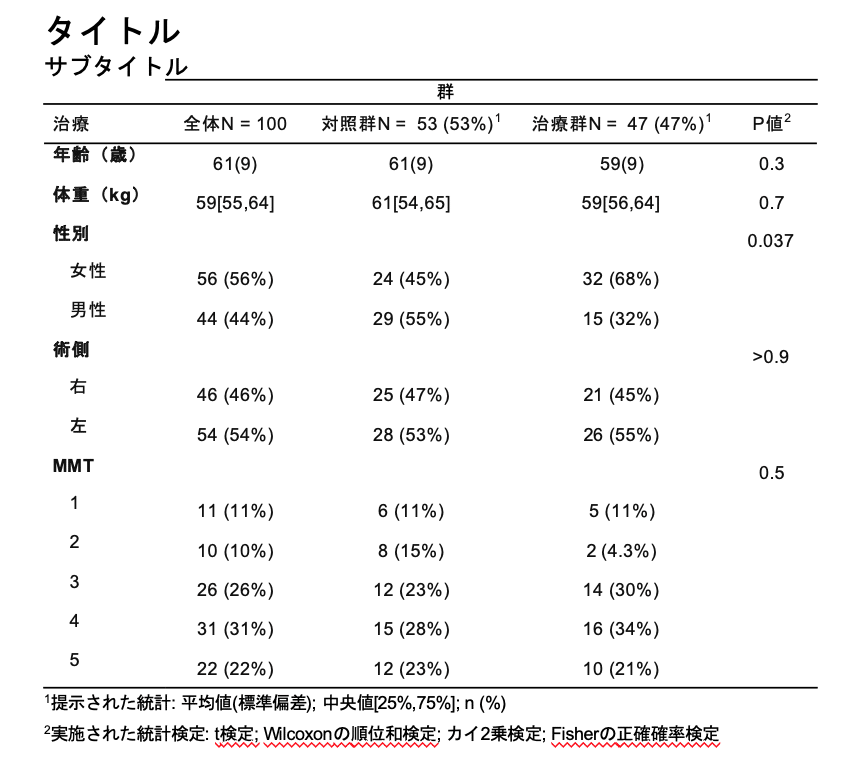
21.タイトル・サブタイトルを加える
表のタイトル・サブタイトルは実はgtsummaryで作成できません。
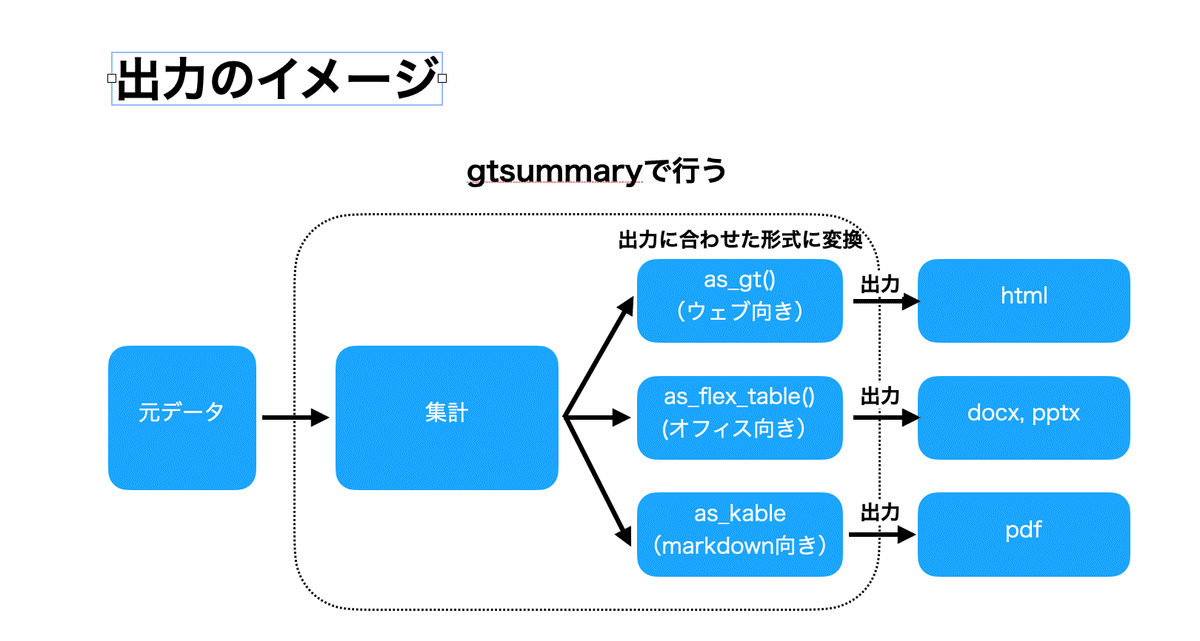
もう一度出力のイメージを確認します。
今までは全て「集計」と書かれたところで作業していました。
ただタイトル・サブタイトルはas_○○と出力に合わせた形式に変換してから作成します。
21−1.HTML形式でタイトル・サブタイトルを加える
HTML形式ははas_tg()形式で行います。最初にgtパッケージを読み込んでいない場合は2.パッケージの読み込みに戻ってください。
もともとgtsummaryのデフォルトはas_gt()となっているので修正はいりませんがわかりやすく加えています。gtパッケージのtab_header()を使います。
table1 <-
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels() %>%
as_gt()
table1 <-
table1 %>%
tab_header(title = "タイトル",
subtitle = "サブタイトル")
table1
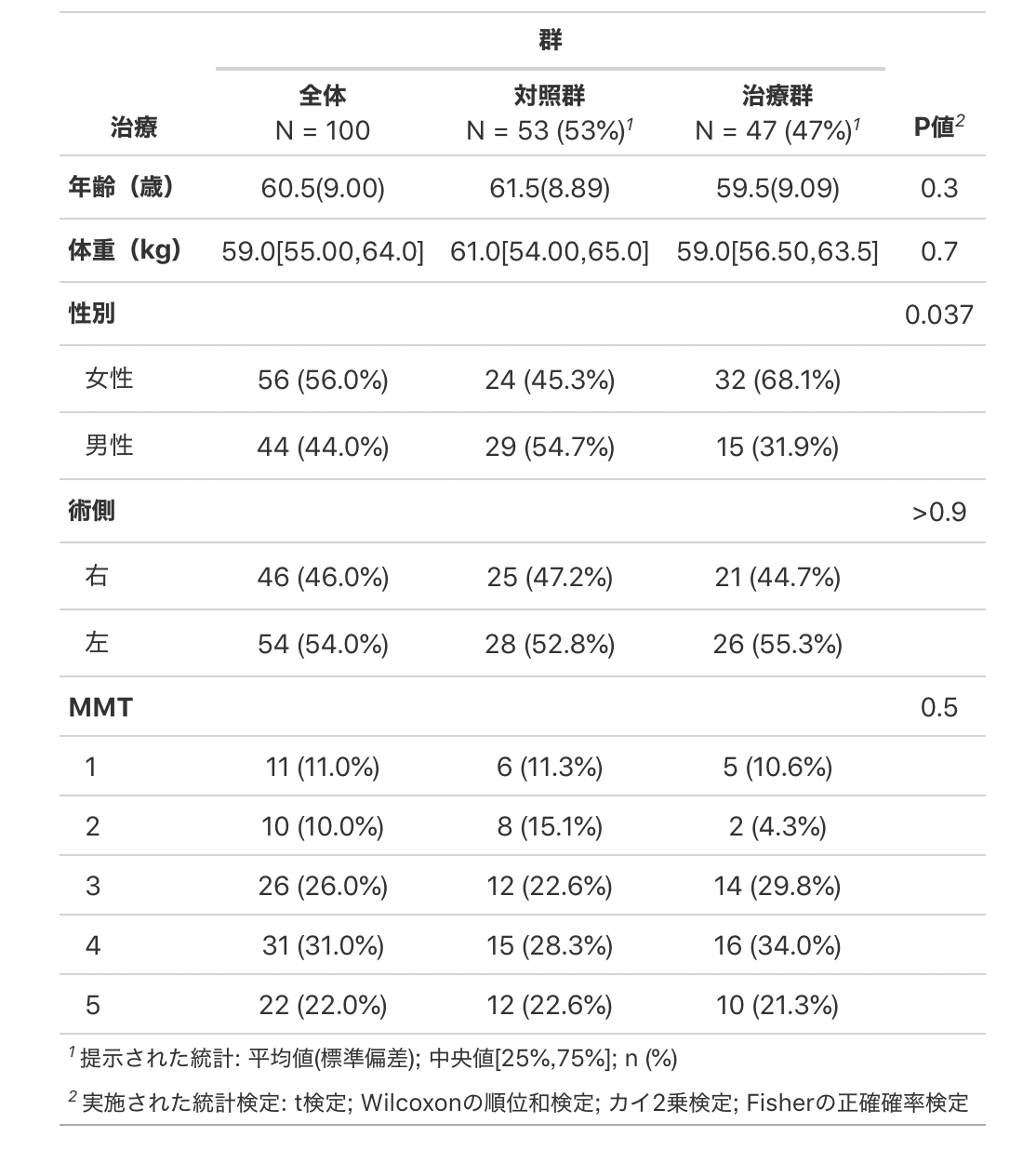
21−2.office形式でタイトル・サブタイトルを加える
office形式はflextable形式で行います。
flextable形式にするにはas_flex_table()を使います。
table1 <-
data %>%
mutate(治療 = factor(治療, labels = c("対照群", "治療群"))) %>%
select(治療,年齢,体重,性別,術側,MMT) %>%
tbl_summary(by = 治療) %>%
add_p() %>%
add_overall() %>%
bold_labels() %>%
as_flex_table()
table1次にflextableパッケージを使って編集します。最初にflextableパッケージを読み込んでいない場合は2.パッケージの読み込みに戻ってください。
まずはflextableパッケージを呼び出すのですが、このパッケージにはタイトル・サブタイトルを指定する関数がありません。代わりにadd_header_lines()を使って1番上に1行増やします。
ポイントはサブタイトル→タイトルの順に作ることです。
フォントサイズを変更することもできます。
table1 <-
table1 %>%
add_header_lines("サブタイトル") %>%
add_header_lines("タイトル") %>%
fontsize(i = c(1,2), size = c(20,14), part = "header")
table1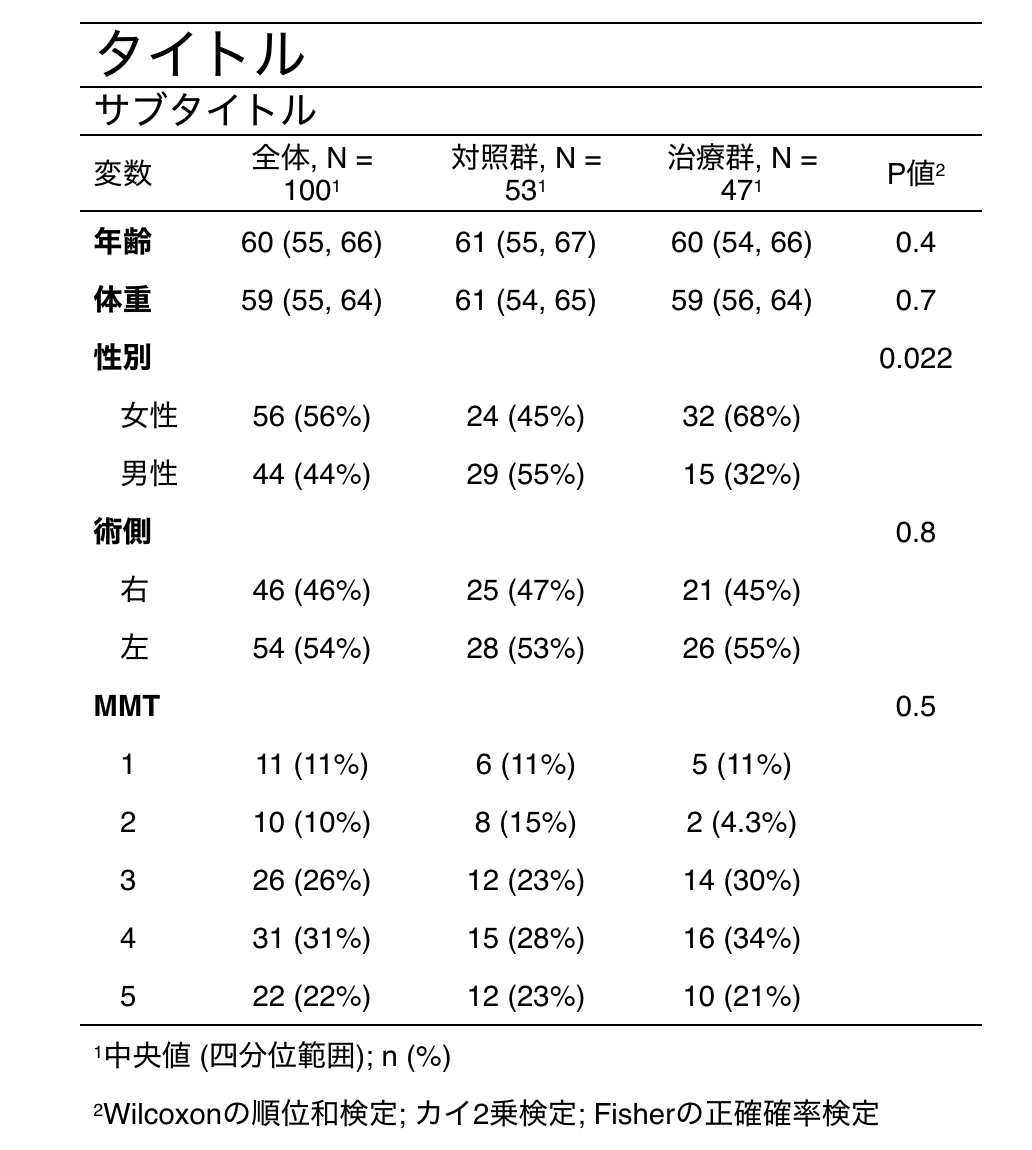
この後はprint関数でWordやPower Pointに変換します。
#Wordの場合
print(table1, preview = "docx")
#Power Pointの場合
print(table1, preview = "pptx")22.まとめ
かなり長くなりましたが、gtsummaryでtable1を作成する方法を紹介しました。
ただ慣れないうちは全てgtsummaryで作成しなくても、ある程度作成したら残りはdocxやpptxに変換して修正できることもできます。
まずは触ってみながらどこまでをRでするか、どこからをOfficeでするかなど自分なりの方法を探してみるのもいかがでしょうか?そしてgtsummaryは回帰分析の結果など、table1以外の表にも対応しています。そこに関しては今後の記事で紹介します。
この記事が気に入ったらサポートをしてみませんか?