
#13高校情報科の授業で初めてPython(パイソン)というプログラミング言語に取り組む 第13回

2020年度、初めて授業でPython(パイソン)というプログラミング言語に挑戦している。
第13回はGoogleColaboratoryを使って、手書き数字の認識をさせる機械学習にチャレンジした。なかなか正解率は低く、うまくいかない理由を授業で考えてはみたが、実際のところがどうなのかは分からないまま終わってしまった。
これからPython(パイソン)を学ぶ方の参考になれば幸いです。
学習内容
機械学習でよく用いられるというscikit-learn(サイキットラーン)というライブラリに同梱されている手書き数字の光学認識データセットOptical Recognition of Handwritten Digits Data Setを利用した。
特徴は4つある。
1. 1797枚の画像
2. 0から9までの手書き数字で、1画像1数字
3. 1画像のサイズは8×8ピクセル(合計64ピクセル)
4. グレイスケールで、1ピクセルを0(薄い)から16(濃い)の範囲で表す
例えば、以下のような画像だ。


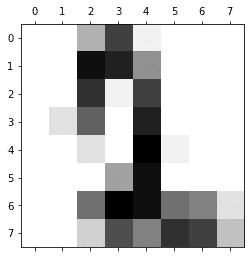
それぞれ、文字データとラベル(実際にどの数字を表すデータなのか)の一覧がセットになっている。ちなみに、上から3,0,2である。
1797枚の画像データとラベルを整形して、シャッフルし、学習用とテスト用に分割し、サポートベクターマシンアルゴリズムを使った学習モデルを構築し、その精度を確かめた。

テキストには2種類のサポートベクターマシンのアルゴリズムが紹介されていたが、いずれも98%くらいの正解率だった。
この後、サンプル画像の数字を判定してみた。

これを、サイキットラーンの画像と同じく8×8ピクセルに変換した。
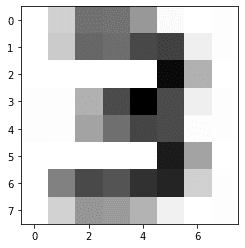
そして、学習済みモデルを使って認識させたのだが、なかなかうまくいかない。
10回実行してみて、「3」と正しく認識できたのは4回、「8」と間違えてしまったのが3回、「9」と間違えてしまったのが2回、「7」と間違えてしまったのが1回だった。
生徒たちも、うまく認識できなくて浮かない顔をしていた。
理由をいくつか考えてみたが、実際のところどうなのか検証できていない。(検証の仕方が分からない)
1. そもそもサイキットラーンの手書き数字の画像が8×8ピクセルで、解像度が不十分なのではないか
2. サイキットラーンの手書き数字の画像1798枚のうち、学習用のデータは75%の1348枚で、数が少ないのではないか。
3. サイキットラーンの手書き数字には独特の癖があって、認識率が落ちてしまうのではないか
生徒たちの様子
今回は打ち込むコードの分量が多かったので、コピー&ペーストOKとしたら、ちょっとつまらなそうだった。
実行してみても思うような結果が得られず、いくつか理由は考えてはみたものの検証することもできず、消化不良で終わってしまった。
人工知能に触れさせたい、ちょっとがんばれば自分たちでもできることを実感させたいと思っていたが、高校の授業で機械学習に取り組むのは難しかった。
テキスト
https://book.mynavi.jp/ec/products/detail/id=87236
マイナビ出版の『ゼロからやさしくはじめるPython入門 基本からスタートして、ゲームづくり、機械学習まで楽しく学ぼう!』に沿って学んでいる。
この記事が気に入ったらサポートをしてみませんか?