
Rを使って白地図に地理データをプロットする

はじめに
こんなときありませんか?
日本の白地図を出力したい
河川や湖の地理データを白地図にプロットしたい
調査対象としている河川やポイントのみをプロットしたい
ArcGISやQGISを使って上記の地図データを出力することもできますが、
何度も手作業で操作するとなると、なかなかしんどいですよね・・・(しかもお金がかかったりする)。
そこで、Rの出番です。
今回はシェープファイルをRで操作しながら、白地図に地理データを出力する方法を紹介します。
準備する
次のようなシナリオを考えます。
①京都府の主要3河川で生物採集調査をおこなった。調査河川のみが描画された地図を作る。
②ある1河川では、複数の地点で生物を採集した。地図に、対象の河川と調査地点をプロットした地図を作る。
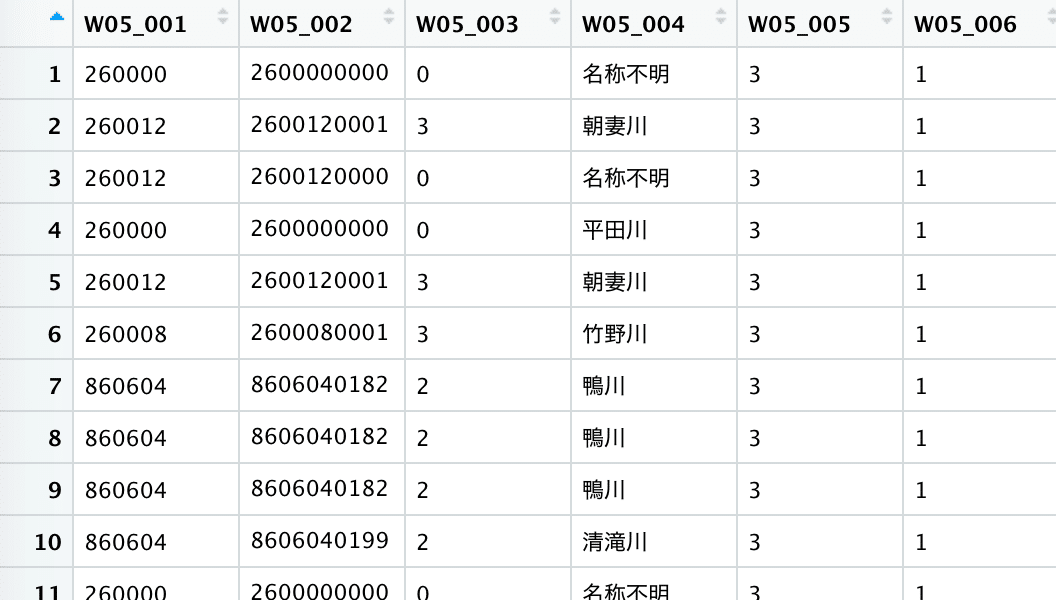
データファイル
3種類のデータファイルを用意します。
まず、国土交通省 国土数値情報ダウンロードサイトから、行政区域データと河川データをダウンロードします。
この記事では、京都府のデータを使って説明します。
1, 行政区域データ
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N03-v3_0.html#prefecture26
2, 河川データ
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-W05.html#prefecture26
※行政区域データと河川データのファイルの構成は後ほど説明します。
3, 調査地点の情報が入力されたcsvファイルを用意します。
最低限、緯度 (lat)と経度 (lng) のデータが入っていればOKです。
今回は、「地点名 (Site)、緯度 (lat)、経度 (lng) 、環境情報 (Salinity)」が入ったデータを使って説明していきます。
"Map_03.csv" と名前をつけて保存します。

環境構築(Rパッケージ)
今回紹介する方法では、以下のRパッケージを活用します。
library(dplyr)
library(ggplot2)
library(sf)
library(kokudosuuchi)
library(rmapshaper)library(dplyr) データ操作のために必要
library(ggplot2) 描画のために必要
↑この2つは、地図の描画やシェープファイルの操作に限らず、よく使われるパッケージです。
library(sf) 空間情報データを扱うために必要
library(kokudosuuchi) 国土地理院のデータを扱うために必要
library(rmapshaper) シェープファイルの加工・操作のために必要
インストールが済んでいない場合は、install.packages("ライブラリー名")でダウンロードしましょう。
準備はここまで。
やってみよう
白地図を作る (都道府県ごと)
まずは、1, 行政区域データを使って、京都府の白地図を作ります。
kyoto <- readKSJData("N03-20210101_26_GML.zip") %>%
translateKSJData()
kyoto <- kyoto[[1]]
kyoto <- kyoto %>%
ms_dissolve(field = "都道府県名", copy_fields = c("都道府県名", "市区町村名", "行政区域コード")) %>%
ms_simplify(keep = 0.01, keep_shapes = TRUE)
ggplot() +
geom_sf(data = kyoto) +
theme_void() 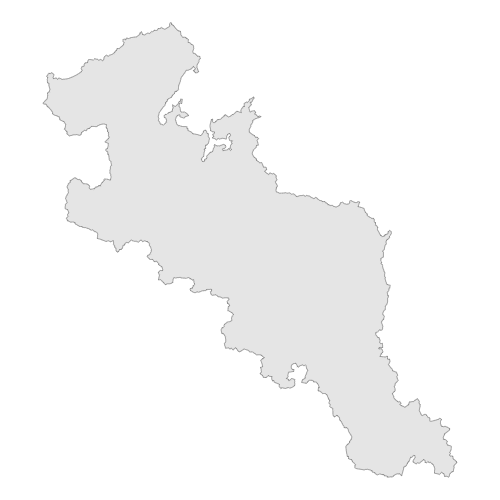
解説
#1-2 readKSJData() でシェープファイル(*1)を読み込みます。
kokudosuuchi パッケージの関数です。国土地理院発行のデータファイルを読み込むのに便利です。
translateKSJData() も忘れずに実行してください。
"readKSJData(データ名) %>% translateKSJData()" として、まとめてコードを実行することが大事です。
京都府の行政区域データを読み込み、 "kyoto" という箱に格納しておきます。
*******************************************************************************
*1について (読み飛ばしてもOKです)超簡単に解説します。
シェープファイルは、都道府県の"エリア"や河川の"流域"を描画する際に使われるデータです。
実際には、点 (座標系など)、線(河川の範囲など)、ポリゴン(都道府県のエリアなど)の情報が含まれます。
そして、1つのシェープファイルは、少なくとも次の3つのファイルから構成されます [".shp", ".shx", ".dbf"]
今回、国土交通省 国土数値情報ダウンロードサイトから取得したデータファイルは.zip形式になっていましたが、これを展開すると [".shp", ".shx", ".dbf"] を含む、いくつかのファイルが出現します。
シェープファイルを構成するファイルたちは、同じディレクトリに収まっている状態が望ましいです。フォルダから移動させずにそっとしておきましょう。
なお、特定のアプリケーションを使わないと、これらのファイルの中身を確認できません。
参考: シェープファイルについてはこちらのサイトでわかりやすく解説されています。
※Note 1
国土地理院が発行しているシェープファイルは、列名や、河川名などのラベルが、人間には理解しづらい「コード」で与えられています。
readKSJData() を実行すればシェープファイルを読み込むことができますが、列名が何を表しているかわからないです。
translateKSJData() を実行することで、「コード」を人間が理解できるラベルに変換してくれます。
※Note 2
.zip を展開してから、Rに".shp"ファイルを読み込むことも可能なはずですが、私のPC環境(Mac)では上手くいきませんでした。
ということで、.zipファイルを展開せずそのままの状態で、中のファイルにアクセスしました。
*******************************************************************************
解説つづき
#3 kyoto[[1]] で"kyoto"から必要な要素を抽出します。
"kyoto" はlist 形式のデータなので、[[]] をしないと、この先のコードがうまく動作しないです。
#4-6 ms_dissolve() でシェープファイルを操作します。今回は、"京都府"ラベルに基づいてデータを融合します。(*2)
rmapshaper パッケージの関数です。
#7-9 ggplotを用いてシェープファイルを描画します。
geom_sf(data = ) で、シェープファイルが格納されたデータセットを指定してください。
*******************************************************************************
*2 の解説(読み飛ばしてもOKです)
今回使っている「1, 行政区域データ」には、名前の通り、"各市町村+政令指定都市の区"の境界線を引くためのデータが格納されています。
よって、コード#4-6 の作業をせずに"シェープファイル"をプロットすると、以下の地図が得られます。
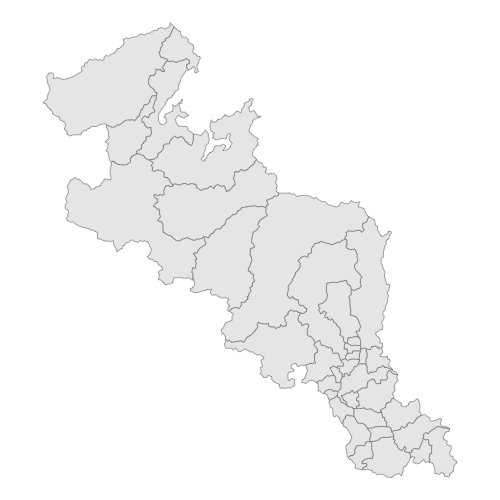
しかし今回の作図では、市町村の境界を消しておきたいです。なぜなら、河川をプロットしたときに見づらくなるから・・・
そこで、境界線を消すために「属性を融合させる」作業をおこないました。
属性融合の概念は、こちらのサイトでわかりやすく説明されています。(遊戯王みたいだな)
参考: IV. 同じ属性のフィーチャを融合(ディゾルブ)
Rでは、rmapshaper パッケージの ms_dissolve() 関数が有用です。
地図の解像度を行政区域レベルではなく「都道府県レベル」で考えたいため、field= で"都道府県名"を指定します。
copy_fields = では、抽出したい列名を指定できます。
ms_simplify() では、簡単に言うと解像度を調整します。
実は生データだと、とても解像度が高い(線や点データが多い)、つまりデータ容量が大きいです。
このため、最終的に容量の大きい図ができたり、操作に時間がかかったりすることがあり、色々と面倒なので解像度を落とすと便利です。
落としすぎるとカクカクした地図が出来上がります。
こうして整えたシェープファイルのデータを "kyoto" に格納しておき、後の描画で使用しました。
地図の解像度はやはり行政区域レベルで考えたい!という場合は、field= で"行政区域コード"を指定すればOKです。
kyoto <- readKSJData("N03-20210101_26_GML.zip") %>%
translateKSJData()
kyoto <- kyoto[[1]]
kyoto1 <- kyoto %>%
ms_dissolve(field = "行政区域コード", copy_fields = c("都道府県名", "市区町村名", "行政区域コード")) %>%
ms_simplify(keep = 0.01, keep_shapes = TRUE)
ggplot() +
geom_sf(data = kyoto1) +
theme_void()*******************************************************************************
白地図に河川データを描画する
それでは、先ほど作成した京都府の白地図に、京都府の河川を描画してみましょう。
rivers <- readKSJData("W05-09_26_GML.zip") %>%
translateKSJData()
rivers2 <- rivers[[2]]
st_crs(rivers2) = "+proj=longlat +datum=WGS84"
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = rivers2) +
theme_void() 
解説
#10-11 readKSJData() でシェープファイルを読み込みます。(#1-2と同じ)
京都府の河川データを読み込み、 "rivers" という箱に格納しておきます。
#12 rivers[[2]] で、 "rivers"のうちStreamファイルのみを抽出します。
"rivers" (もとは"W05-09_26_GML.zip") には、River_Node と Stream に関連するファイルが含まれます。
河川の描画には Stream データがあればOKです。

#13 st_crs() でCRSを指定します。
CRS とは、座標参照システム (Coordinate Reference System) のことです。
河川データのみを描画する際には指定なしでも構いませんが、他のデータセットとあわせてプロットする際には必須です。
参考: 座標参照系(CRS)とは?
https://www.aeroasahi.co.jp/fun/column/19/
#14-17 ggplotを用いてシェープファイルを描画します。…#1-9までのコードに +geom_sf(data = rivers) を追記しただけです。
ちなみに、河川のみを描画することも可能です。
ggplot() +
geom_sf(data = rivers2) +
theme_void() 
任意の河川のみを描画する
ここで、冒頭のシナリオを考えてみます。
①京都府の主要3河川で生物採集調査をおこなった。調査河川のみが描画された地図を作る。
それでは、"桂川"、"鴨川"、"由良川"で調査をおこなったとし、これら3河川のみを白地図に描画してみましょう。
main_rivers <- rivers2[rivers2$河川名 == "桂川" |
rivers2$河川名 == "鴨川" |
rivers2$河川名 == "由良川" ,]
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = main_rivers) +
theme_void() 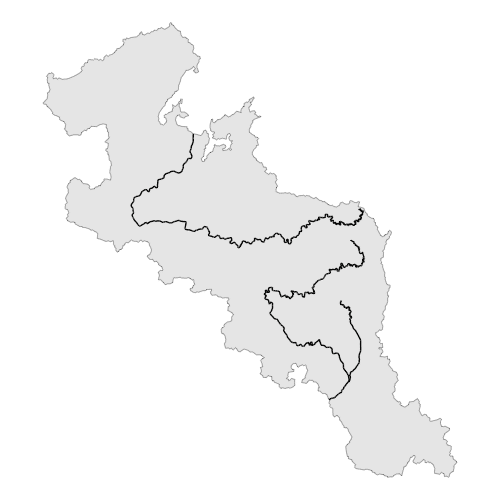
解説
#16-18 京都府の全河川のデータが格納された "rivers2" データセット から、"桂川"、"鴨川"、"由良川"のみを抽出します。
rivers2 の 河川名列から、条件「"桂川"、"鴨川"、"由良川"」と一致する行を抽出し、"main_rivers" にデータセットを保管しておきます。

#19-22 ggplotを用いて、シェープファイルを描画します。
…#1-10までのコードに geom_sf(data = main_rivers) を追記しただけです。
シェープファイルの操作は以上です。
まとめ
・シェープファイルをRに読み込む;国土地理院データの場合はコードを翻訳する
・シェープファイルを描画に適した解像度に整える
・複数のシェープファイルを重ね書きする場合は、CRSを指定する
応用編
調査地点をプロットする
ここで再び、冒頭のシナリオを考えてみます。
②ある1河川では、複数の地点で生物を採集した。地図に、対象の河川と調査地点をプロットした地図を作る。
それでは、由良川の9地点で調査をおこなったとし、白地図に由良川と調査ポイントを描画してみましょう。
9地点の情報は、"Map_03.csv" から取得します。
dt <- read.csv("Map_03.csv")
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = main_rivers) +
theme_void() +
geom_point(data = dt, aes(x = lng, y = lat), size = 3) 
解説
基本的には、これまでに紹介したコードと同じです。
ggplot2で地図を描画しているため、geom_point() などプロット描画のための関数を組み合わせることも可能です。
dt <- read.csv("Map_03.csv")で位置情報が格納されたデータファイルを読み込み、
geom_point(data = dt, aes(x = lng, y = lat), size = 3) で座標データを取得します。
白地図や河川の色を変える
ここからは、図の色や体裁をカスタマイズするためのコードを紹介します。
まず、地図や河川はデフォルトでグレーと黒になっていますが、好みの配色に変えることができます。
ggplot() +
geom_sf(data = kyoto, fill = "white") +
geom_sf(data = main_rivers, colour = "blue") +
theme_void() +
geom_point(data = dt, aes(x = lng, y = lat), size = 3) 
「ポリゴンデータ」である京都府のエリアは fill = "色"で、「線データ」である河川は colour = "色" で、好きな色に変更できます。
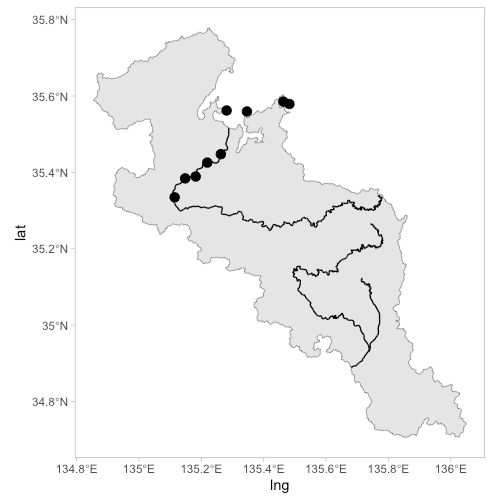
緯度・経度ラベルの表示と範囲を指定する
ggplot2の"theme"を変更すれば、地図に緯度・経度ラベルを表示できます。
個人的には、theme_light() + theme(panel.grid=element_blank()) の組み合わせが好みです。
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = main_rivers) +
theme_light() +
theme(panel.grid=element_blank()) +
geom_point(data = dt, aes(x = lng, y = lat), size = 3) 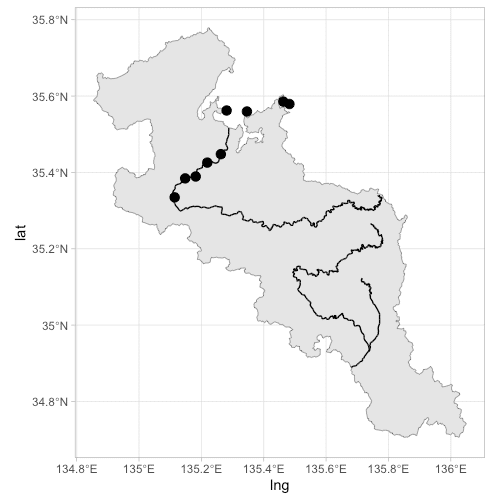
なお、ggplot2 の theme についてはこちらのサイトで詳しく説明されてます。
また、xlim() や ylim() を指定することで、任意の緯度・経度のみを描画することができます。
ためしに由良川だけ描画してみましょう。
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = main_rivers) +
theme_light() +
theme(panel.grid=element_blank()) +
geom_point(data = dt, aes(x = lng, y = lat), size = 3) +
xlim(c(135.05, 135.60)) + ylim(c(35.25,35.75))
ポイントの色を変える
調査をおこなった9点を、塩分濃度に応じて次の3タイプに分類します:海水・汽水・淡水
ここでは、塩分濃度ラベルごとにプロットの色を変えてみます。
"Map_03.csv"の Salinity 列に格納されている各地点の塩分濃度情報を使います。
col01 <- c("#350c0c","#a22526","#fa6c6d")
ggplot() +
geom_sf(data = kyoto) +
geom_sf(data = main_rivers) +
theme_light() +
theme(panel.grid=element_blank()) +
geom_point(data = dt, aes(x = lng, y = lat, colour = Salinity), size = 3) +
scale_color_manual(values = col01) +
xlim(c(135.05, 135.60)) + ylim(c(35.25,35.75))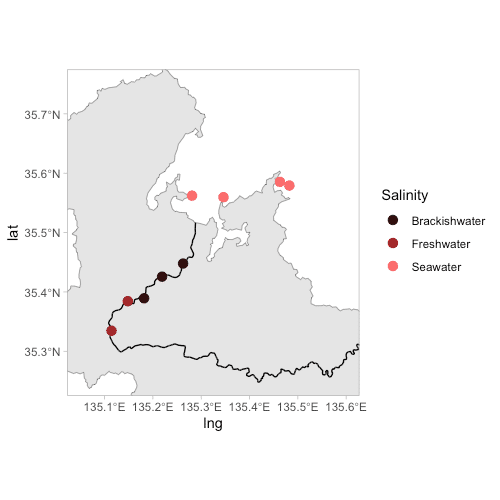
まずはカラーパレットを作ります。col1 <- c() で、好きな色を3つ指定しました。
これまでのコードに2点、変更を加えました。
geom_point(data = dt, aes(x = lng, y = lat, colour = Salinity), size = 3) + scale_color_manual(values = col01) +
※ggplot2で散布図を描くときのカスタマイズ方法と同じです。
今回はここまでです。
ポリゴンデータ (湖、都道府県、市町村など) を扱うコードについても、そのうち紹介するかもです。
おまけ (シェープファイルの読み込み方法)
今回は、kokudosuuchi パッケージ の readKSJData() でシェープファイルを読み込みましたが、
sf パッケージの read_sf() 関数を使ってもOKです。
たとえば、#10-11のコードを以下のように書き換えることが可能です。
rivers <- read_sf("W05-09_26-g_Stream.shp",
crs = "+proj=longlat +datum=WGS84") read_sf() 関数を使う利点は、シェープファイルを読み込むときにCRSを指定できることです。
一方、操作プロセスが少し増えます。
①"W05-09_26_GML.zip" を展開し、②ワーキングディレクトリを"W05-09_26_GML"に移動してから、③read_sf() を実行する
ということです。
ここで、"W05-09_26-g_Stream.shp" を現在のワーキングディレクトリに移動させるというアイデアが出るかもしれませんが、
前半で説明したように、シェープファイルを構成するファイルたちは同じフォルダに収まっている状態が好ましいので、できれば".shp"ファイルだけを動かすのは避けたいです。
Rの setwd() 関数で簡単にワーキングディレクトリを移動できるので、こちらの方法をおすすめします。
また、国土地理院データをread_sf() 関数で読み込むと、コードの翻訳が行われません。
#16-18 の列名指定の際に少し苦労する可能性があります。
国土地理院データ以外のシェープファイルを扱うときは、read_sf() 関数が適していると思います。
(おわり)
この記事が気に入ったらサポートをしてみませんか?