
【2024年2月更新】 Filemakerで蔵書管理アプリを自作した(その3)

2024.2.28追記
国立国会図書館サーチの仕様変更に対応して、改修しました。
Filemakerで蔵書管理を自作した話、前回はバーコード読み取りからタイトルが自動で挿入されるところまで取り上げました。今回はその続き、必要な項目全てが自動入力されるようになるまでです。基本的に全文無料ですが、投げ銭してくださった方にはお礼として、有料部分で作成したデータをダウンロードできるようにいたします。
まずは項目を作ってしまう
やることはいろいろありますが、とにかく自分が入力するつもりで、レイアウトモードで完成形をイメージしながらフォーマットを作ってしまいます。

今回のゴールは、「バーコードリーダーを立ち上げて、読み込んだらこれらの項目が自動で入力される」です。
改めて返されるXMLを見てみましょう。作成したリクエストURLは以下の通りです。
https://ndlsearch.ndl.go.jp/api/sru?operation=searchRetrieve&recordSchema=dcndl&query=isbn=9784106100031&maximumRecords=1結果をブラウザで表示するとこんな感じになってます。

中程にある、書籍に関する記述はこうなっています。少し見やすくするために改行を入れています。
<dcterms:title>バカの壁</dcterms:title>
<dc:title>
<rdf:Description> <rdf:value>バカの壁</rdf:value>
<dcndl:transcription>バカ ノ カベ</dcndl:transcription>
</rdf:Description>
</dc:title>
<dcterms:creator>
<foaf:Agent> <foaf:name>養老, 孟司</foaf:name>
<dcndl:transcription>ヨウロウ, タケシ</dcndl:transcription>
</foaf:Agent>
</dcterms:creator>
<dc:creator>養老孟司著</dc:creator>
<dcterms:publisher>
<foaf:Agent> <foaf:name>新潮社</foaf:name> </foaf:Agent> </dcterms:publisher>
<dcndl:publicationPlace rdf:datatype="http://purl.org/dc/terms/ISO3166">ja</dcndl:publicationPlace>
<dcterms:date>2003.4</dcterms:date>
<dcterms:issued rdf:datatype="http://purl.org/dc/terms/W3CDTF">2003</dcterms:issued>
<dcterms:subject rdf:resource="http://id.ndl.go.jp/class/ndc9/304"/> <dc:subject rdf:datatype="http://ndl.go.jp/dcndl/terms/NDC8">304</dc:subject>
<dcterms:language rdf:datatype="http://purl.org/dc/terms/ISO639-2">ja</dcterms:language>
<dcterms:extent>18cm</dcterms:extent>
<dcndl:materialType rdf:resource="http://ndl.go.jp/ndltype/Book" rdfs:label="図書"/>
国会図書館の検索には、NDC(日本十進分類法)分類も格納されています。図書館の本についてる3桁ないし5桁の分類番号です。同じ本でも図書館によって違ったところに分類されることもあるようですが、これが付いていることで記録が溜まった時にその傾向あるいは偏愛とかが見えてくるのは面白いです。
「よみ」についても、データを格納しておくことで五十音順のソートはが確実なものになります。ふりがなフィールドで自動入力されるようにもしていますが、あくまで手入力が必要になった際の補助として使い、基本は信頼できるデータベースを利用することにします。
テキストフィールドを作り、「URLから挿入」スクリプトステップを使ってXMLを格納します。


ブラウザでは"<"、">"と記号表示されるが、テキストフィールドに流し込んだ場合は"<”、">"と表示され処理されます。

XMLの中から検索する範囲を指定する
並べた項目を入力するスクリプトを組みます。前回作った、タイトル入力のスクリプトステップをコピーし、全項目分繰り返すのが基本ですが、Middle関数で指定する先頭文字位置をタグの長さに合わせて調整すること、タグが追記されている属性もあるのでPosition関数で検索する文字列の作り方に工夫が必要です。
しかしここで問題があります。タイトルの読みと著者名の読みが同じ"dcndl:transcription"タグで記述されるようになりました。2024年1月の仕様変更で、上位に"dc"あるいは"dcterms"タグを置いてタイトルに関するセクション、著者に関するセクション、出版社名に関するセクションなどのように区別する構造に変更されたようです。各タグと構造に関しては国立国会図書館サーチのページに資料があります。
読み込んだXMLの記述の中から、Middle関数を使って抜き出す際に、検索の開始位置をPosition関数で指定します。ここで、Position関数を改めてみてみましょう。
Position
目的
テキスト内で検索テキストを検索し、指定された回数目の先頭文字位置を返します。
構文
Position ( テキスト ; 検索テキスト ; 先頭文字位置 ; 回数 )
引数
テキスト - 任意のテキスト式またはテキストフィールド
検索テキスト - 任意のテキスト式、または検索する文字の集合を表すテキストフィールド
先頭文字位置 - テキスト文字列の先頭から検索開始位置までの文字数を示す数値式または数値を含むフィールド
回数 - 検索するテキスト文字列の何回目の文字列を対象とするかを表す数値式または数値を含むフィールド。値が負の場合、検索開始位置から反対方向にスキャンが行われます。「0」は回数の値としては無効なため、実行結果はゼロが返されます。
戻り値のデータタイプ
数字
3つ目の引数「先頭文字位置」を、もう一度Position関数を用いて、タグの位置を指定してやります。著者名の読みを抜き出す場合を例とします。3つの関数が入れ子になっていますので、順を追って説明します。まずは検索の開始地点を示すPosition関数。著者に関する記述の中から検索することを指定します。
構文
Position ( テキスト ; 検索テキスト ; 先頭文字位置 ; 回数 )
引数は次のとおり
・テキスト=ほん::検索結果(XMLが格納されているフィールド名)
・検索テキスト="dcterms:creator"(著者に関する記述を宣言するタグ)
・先頭文字位置=1(テキストの最初から検索する)
・回数=1(最初に現れる)
関数の記述は次のようになります。
Position(ほん::検索結果 ; "dcterms:creator" ; 1 ; 1)
このPosition関数を、抜き出すテキストの位置を示すPosition関数の引数として使用します。
・テキスト=ほん::検索結果(XMLが格納されているフィールド名)
・検索テキスト="<dcndl:transcription>"(読みを記述するタグ)
・先頭文字位置=Position(ほん::検索結果 ; "dcterms:creator" ; 1 ; 1)
(前段で作った関数。著者名に関する記述の中から検索します)
・回数=1 (最初に現れる)
この2つを組み合わせると、検索したテキストの1文字目の位置を返す関数になります。実際に抜き出す文字列は、検索した"<dcndl:transcription>"の後に記述されていますので、その文字列の長さ分だけ足します。(ここでは23)。返すデータは数字になります。
Position(ほん::検索結果 ; "<dcndl:transcription>" ; Position(ほん::検索結果 ; "dcterms:creator" ; 1 ; 1) ; 1 )+27
抜き出すテキストの長さを求める
それでは、Middle関数を使ってテキストを抜き出していきます。
Middle
目的
テキストの先頭文字位置で指定された文字から、文字数で指定された文字数分のテキストを抽出します。
構文
Middle ( テキスト ; 先頭文字位置 ; 文字数 )
引数
テキスト - 任意のテキスト式またはテキストフィールド
先頭文字位置 - 任意の数値式、または数値を含むフィールド
文字数 - 任意の数値式、または数値を含むフィールド
引数のうち、実際に抜き出すテキストの文字数はタイトルによって異なるので、ここも計算式を作って入れてやらなければなりません。今回抜き出す著者名の読みがどのように記述されているか、再び見てみましょう。
<dcterms:creator>
<foaf:Agent> <foaf:name>養老, 孟司</foaf:name>
<dcndl:transcription>ヨウロウ, タケシ</dcndl:transcription>
htmlを触ったことのある方にはお馴染みですが、冒頭に"/”をつけたものが記述の終了を宣言するタグです。ですので、抜き出すテキストの文字数はそれぞれのタグの、冒頭からの位置の差分から計算することができます。ここでもPosition関数を使いますが、検索した文字列の先頭{"<"のある位置)を返すので、上の例の場合だと、単純な差分で返されるのは、"<dcndl:transcription>ヨウロウ, タケシ”の長さになります。なので差分からタグの長さ分だけ引く必要があります。
抜き出す文字数を求める計算式は次のようになります。
"determs:creator"セクション内にある</dcndl:transcription>の位置=
Position ( ほん::検索結果 ; "</dcndl:transcription>" ; Position ( ほん::検索結果 ; "<dcterms:creator>" ; 1 ; 1 ); 1 )
-"determs:creator"セクション内にある</dcndl:transcription>の位置=
Position ( ほん::検索結果 ; "<dcndl:transcription>" ; Position ( ほん::検索結果 ; "<dcterms:creator>" ; 1 ; 1 ) ; 1)
-"<dendl:transcription>"の文字数=
27
これで、必要な引数が揃いました。
*前段では"<”を含めずに検索しているので23ですが、終了タグの検索では">"が必ず入るので統一してタグ先頭の"<"を入れたために、27になっています。見た目はややこしくなりますが、入れ子になる関数内の全ての引数で同じ数値が使えます。
Middle関数で実際に抜き出してみる
以上の引数を、Middle関数に入れたものが、検索結果のXMLから著者名の読みを抜き出す関数になります。
Middle
構文
Middle ( テキスト ; 先頭文字位置 ; 文字数 )
引数
テキスト:
ほん::検索結果(XMLが格納されているテキストフィールドの名前)
先頭文字位置:
Position(ほん::検索結果 ; "<dcndl:transcription>
" ; Position(ほん::検索結果 ; "<dcterms:creator>" ; 1 ; 1) ; 1 )+27
文字数:
Position ( ほん::検索結果 ; "</dcndl:transcription>" ; Position ( ほん::検索結果 ; "<dcterms:creator>" ; 1 ; 1 ); 1 )
-Position ( ほん::検索結果 ; "<dcndl:transcription>" ; Position ( ほん::検索結果 ; "<dcterms:creator>" ; 1 ; 1 ) ; 1)
-27
これを、スクリプトステップの「計算結果を挿入」に組み込みます。
同じ要領で他の項目を抜き出す関数を作り、対応するフィールドに挿入するスクリプトステップを繋げます。著者名以降の各項目の関数を作る際に、タグの記述を見ながら検索範囲を指定していくことが肝です。

これで、ISBNで検索した結果を読み込み、そこから各項目を抜き出すスクリプトができました。実行してみると次のようになります。
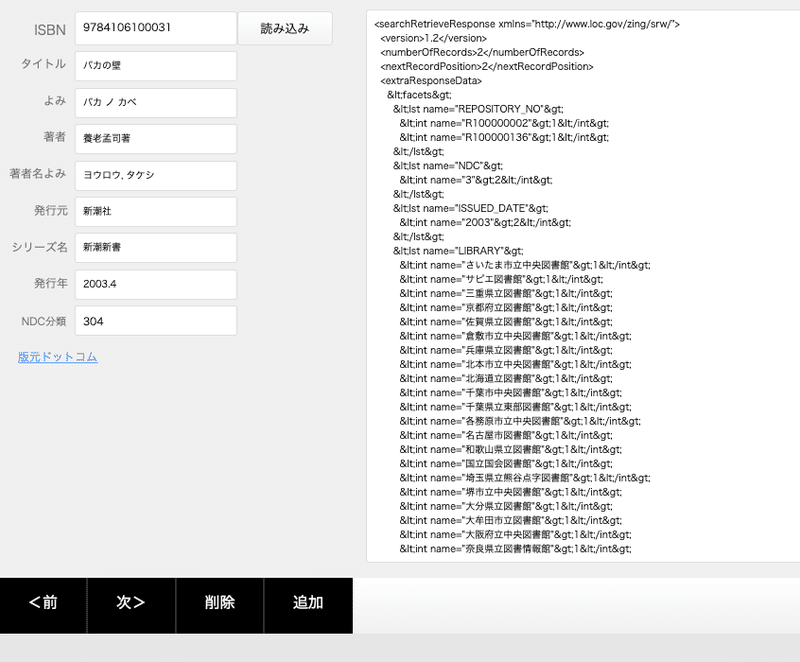
NDC分類だけは記述方法が異なっている
項目のうち、NDC分類はタグの中に記述されているようです。国会図書館サーチのサイトにある記述例を抜粋します。
NDC(10版)
<dcterms:subject rdf:resource="http://id.ndl.go.jp/class/ndc10/値"/>
NDC(9版)
<dcterms:subject rdf:resource="http://id.ndl.go.jp/class/ndc9/値"/>
NDC(8版)
<dc:subject rdf:datatype="http://ndl.go.jp/dcndl/terms/NDC8">NDC(8)の値</dc:subject>
NDC分類コードは定期的に更新されていて、最新は10版ですが少し古いものだと9版、古いものだと8版以前のものも珍しくはありません。先ほど引用した「バカの壁」は2003年の出版ですが、"NDC9"と"NDC8"で記述されています。
検索する文字列は”ndc"ですが、その後に続く文字列が”9”と”10”で長さが複数あ離、またNDC8以前では記述方法が異なるために先頭文字位置が揺れてしまうこと、書籍によって分類記号自体が3桁から7桁(ピリオド含む)まで幅があるのでそれらを吸収する必要があります。
Filter ( Middle ( ほん::検索結果 ; Position ( ほん::検索結果 ; "ndc" ; Position ( ほん::検索結果 ; "dcterms:subject" ; 1 ; 1 ) ; 1 ) + 5 ; 11 ) ; "1234567890.")
検索する文字列は"ndc"にし、"dcterms:subject"で宣言されている以降を検索範囲にする。
ndcのnから数えて5文字後ろから抽出する。NDC10であればnの5文字後ろは"/"、NCD9であればnの5文字後ろは抽出する文字列の1文字目、NDC8であればタグの閉じ括弧にあたる、”&"になる。
NDC8の場合、必要なコードの1文字目はNから数えて9文字目、抜き出す先頭文字(5文字目)から数えて4文字目にあり、NDC分類コードの最長が7桁(abc.def)なので、コードの記述がある可能性があるのは、Nから数えて5文字目から16文字目までの11文字なのでこの部分を抽出する。
Filter関数で数字とピリオドのみを取り出す。
例外がありそうですが、今のところこれで取得できています。
バーコード入力のスクリプトに連動させる
ここまで作ったスクリプトを、前に作ったバーコード入力のスクリプトに追加します。スクリプトステップをコピーして一つにしても動作しますが、ここでは入力するスクリプトは別にしておき、作動条件を設定します。

条件は以下の通りです。
ISBNが10桁以上入力されていれば無条件に検索
9桁以下の場合、iPhoneであればカメラを起動してバーコードを読み込んで入力
上2つに当てはまらない場合は何も起きない
これまで作ったレイアウト上のボタンにスクリプトの実行を割り当てます。検索結果のXMLを格納するフィールドを操作することはありませんが、レイアウト上に無いと動作しないので非表示部分に置いておきます。
iPhoneで表示させるとこんな感じです。
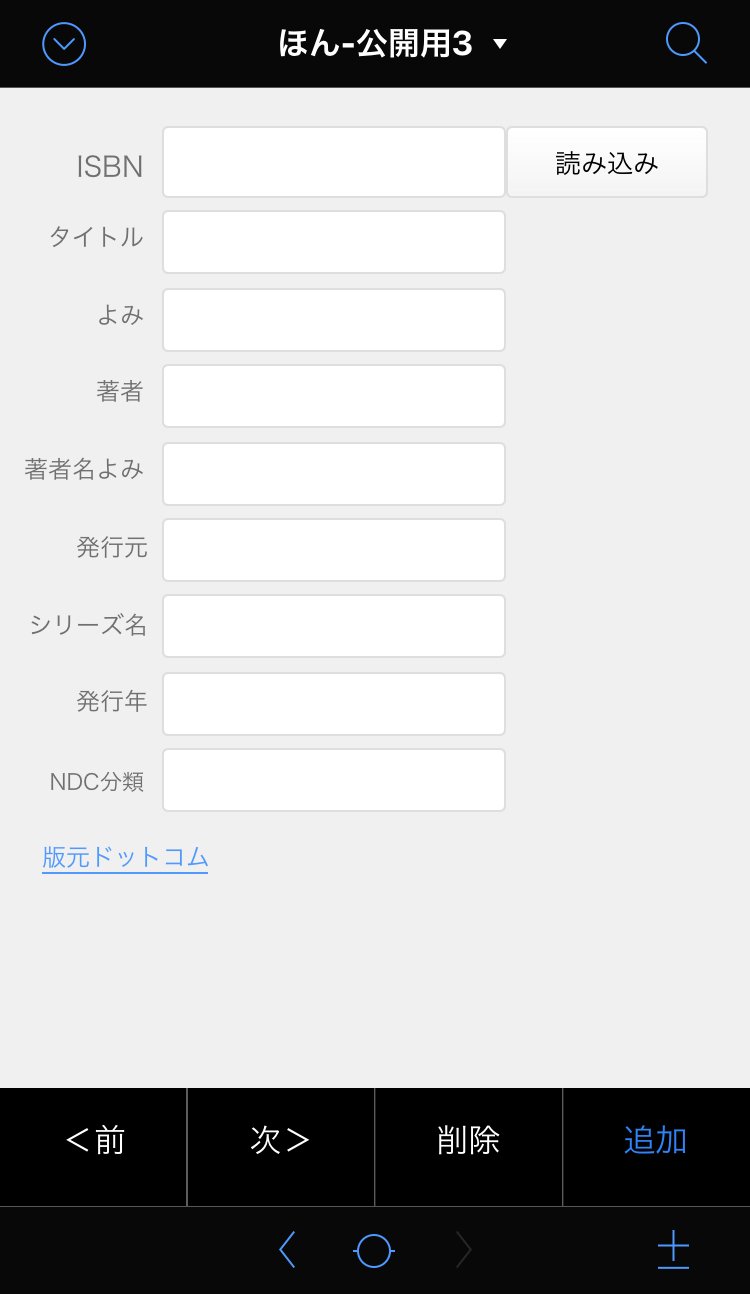
これで、ほとんどの入力作業を自動化できるようになりました。手元の本のバーコードをiPhoneで読み込むだけで、基本的なデータがどんどん蓄積されていきます。次回は書影を取り込む方法についてやろうと思います。
今回も、投げ銭のお礼として、ここまでのデータをダウンロードできるようにしておきますので、遊んでみてください。
各項目を抽出する関数

この記事が気に入ったらサポートをしてみませんか?