
GASでスクレイピングできないページをPythonでスクレイピングした【不動産競売物件情報サイト】

何日か前にGASで不動産競売物件情報サイトから情報を取り出せないかと聞かれたのですがサイトの仕組みの関係でGASではできないので無理ですねーっと返事をしました。後になってGASじゃなくてPythonならできるかも?と、思ってやってみたらPythonで出来たので紹介します。
動作しているところ
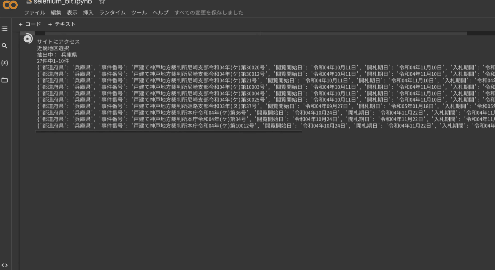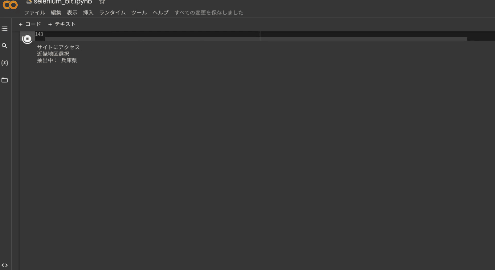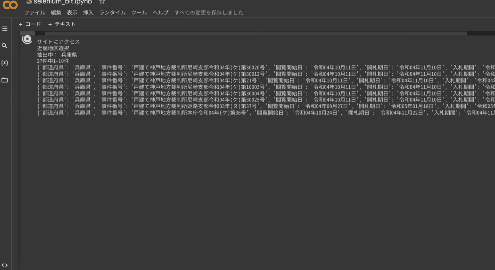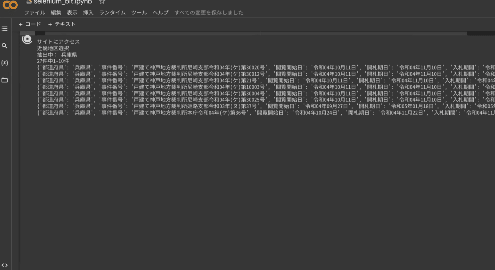

GOOGLE COLABORATORYリンク
下が実際に動作するリンク。グーグルのアカウントがあれば開けます
このプログラムでは近畿地方の競売情報を取得しています。
プログラムリスト
#Chromiumとseleniumをインストール
print("前処理を開始")
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip3 install selenium
!pip3 install beautifulsoup4
#ライブラリをインポート
import os
from google.colab import files
import csv
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from bs4 import BeautifulSoup
import time
#---------------------------------------------------------------------------------------
# 処理開始
#---------------------------------------------------------------------------------------
# ブラウザをheadlessモード実行
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
driver.implicitly_wait(30)
#都道府県のボタンリスト
areaxpathlist={
'兵庫県':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[1]',
'京都府':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[2]',
'奈良県':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[3]',
'大阪府':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[4]',
'滋賀県':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[5]',
'和歌山県':'/html/body/form/main/div/div[3]/div/div/div/div/div/div/div[2]/div/map[6]/area[6]',
}
def getData(area):
datatable=[]
#検索ボタン
driver.find_element(By.XPATH,'//*[@id="bit__clickablemaplink_contents"]/div[2]/div[2]/div[2]/button[2]').click()
time.sleep(5)
if driver.find_elements(By.CLASS_NAME,'bit__text_red mb-0 text-left'):
tmp = driver.find_element(By.CLASS_NAME,'bit__text_red mb-0 text-left')
if '該当データがありません' in tmp:
return []
soup = BeautifulSoup(driver.page_source.encode('utf-8'), "html.parser")
num = soup.find_all('span', class_='bit__numberOfResult_totalNumber')[0].getText()
num=int(num)
pageMAX = num//10
if num%10>0:
pageMAX+=1
for i in range(1,pageMAX+1):
soup = BeautifulSoup(driver.page_source.encode('utf-8'), "html.parser")
results = soup.find_all("div", class_="bit__searchResult bit__currentSearchCondition_regionBox mb-2")
print(soup.find('p', class_='bit__text_normal mb-0').getText().replace('\n','').replace('\u3000','').replace('\t',''))
for item in results:
base_data = {}
base_data["都道府県"]=area
base_data["事件番号"]=item.find('div', class_='d-flex flex-column flex-sm-row px-0').getText().replace('\n','').replace('\u3000','').replace('\t','')
tmp = item.find_all('div', class_='bit__multiHeadTable_td col-12 col-sm-3')
if len(tmp)>=2:
base_data["閲覧開始日"]=tmp[0].getText()
base_data["開札期日"]=tmp[1].getText()
elif len(tmp)==1:
base_data["閲覧開始日"]=tmp[0].getText()
base_data["開札期日"]=""
tmp = item.find_all('div', class_='bit__multiHeadTable_td col-12 col-sm-5')
if len(tmp)>=2:
base_data["入札期間"]=tmp[0].getText()
base_data["特別売却期間"]=tmp[1].getText()
elif len(tmp)==1:
base_data["特別売却期間"]=tmp[0].getText()
base_data["売却基準評価額"]=item.find('div', class_='col-12 col-sm-6 d-flex justify-content-between align-items-center pr-sm-2 pl-0 mb-2 mb-sm-0 mt-2 mt-sm-0').getText().replace('\n','').replace('-円','').replace('売却基準価額','').replace('売却基準価額','')
base_data["買受申出保証金"]=item.find('p', class_='font-weight-bold mb-0').getText().replace('\n','').replace('-円','')
base_data["住所"]=item.find('p', class_='text-wrap mb-2 mr-3').getText()
if item.find_all('div', class_='col-12 pl-0 bit__text_small'):
base_data["住所2"]=item.find('div', class_='col-12 pl-0 bit__text_small').getText().replace('\n','').replace('\u3000','')
else:
base_data["住所2"]=""
datatable.append(base_data)
print(base_data)
#次ページへのボタンを押す
jsstr = "getData("+str(i+1)+");"
driver.execute_script(jsstr)
time.sleep(3)
#戻る
for i in range(pageMAX+1):
driver.back()
time.sleep(3)
return datatable
# サイトにアクセス
print("サイトにアクセス ")
driver.get("https://www.bit.courts.go.jp/app/top/pt001/h01")
time.sleep(10)
#画面の最大化
w = driver.execute_script("return document.body.scrollWidth;")
h = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(w,h)
#近畿選択
print("近畿地区選択")
driver.find_element(By.XPATH,'/html/body/main/div[1]/div/div/div/div/div[2]/div/map/area[6]').click()
time.sleep(3)
#page-item
all_data = []
for area in areaxpathlist.keys():
#都道府県ボタンをおす
path=areaxpathlist[area]
driver.find_element(By.XPATH,path).click()
time.sleep(3)
#地域の全選択ボタンをすべて押す
for i in driver.find_elements(By.XPATH,"//button[text()='全選択']"):
i.click()
time.sleep(1)
#データ取得
print("抽出中:",area)
tmp=getData(area)
all_data+=tmp
# 出力
with open('bit_utf8.csv', 'w') as f:
writer = csv.DictWriter(f, all_data[0].keys())
writer.writeheader()
for i in all_data:
writer.writerow(i)
files.download('bit_utf8.csv')
with open('bit_shiftjis.csv', 'w', encoding='cp932') as f:
writer = csv.DictWriter(f, all_data[0].keys())
writer.writeheader()
for i in all_data:
writer.writerow(i)
files.download('bit_shiftjis.csv')このプログラムはGoogleColaboratory用。他の環境では前処理のところを削除すると動くと思います。
プログラムは他の解説サイトにあるサンプルとほぼ同じ。ちょっと違うのはサイトを開いた後、画面サイズをページサイズに合わせて最大化しているところ。この最大化によってボタン操作ができるようになりました。
苦労したところ
検索結果ページの「次ページ」への進み方が分からずに苦労しました。「次ページ」ボタンを押す操作が上手くいきません。.click()はダメ、画面をズラして.click()もダメ、onclickで指定しているjavascriptを実行してもダメ、XPATHで指定してもダメ、CSSで指定してもダメ。一度は諦めたのですがボタンを直前のスクリーンショット撮ってみようとウインドウサイズをページに合わせる下のコードを挿入したら
w = driver.execute_script("return document.body.scrollWidth;")
h = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(w,h)
急に「次ページ」ボタンが押せるようになり問題が解決しました。つまり、
『ウインドウ中にボタンが表示されていないと押せない』
これに全然気が付きませんでした。Udemyの有料講座でスクレイピングの解説を見ていたのですがこのことに触れられていなかった(しばくぞキカガク)こともあり、気づくのに時間がかかりました。ボタンだけでなく文字入力なんかもウインドウ中に表示されてないと上手く動かないようで、ウインドウサイズをページに合わせるのは常識みたいです。
苦労もあったけど今回のことでWEB操作が身についたので自動売買システムなんかも作れそう。時間があれば株の自動売買もやってみたい。
自動化
GASだと「毎週水,木曜日の12時」というような定期実行が簡単にできるんですがPythonだと難しい。サーバを借りるか、24時間電源入れたままのパソコンを用意しないといけない。PythonにもGASみたいなサービスがあればいいんですが
#自動化 #Python #不動産競売 #スクレイピング #GAS
この記事が気に入ったらサポートをしてみませんか?