
統計的因果推論と因果探索について
こんにちは。エムスリーデータ分析グループの中島です。
本記事ではマーケティングやデータサイエンスの文脈で重要度が高まっている統計的因果推論への足掛かりをデータ分析グループの業務と結び付けながらご紹介したいと思います。
1. はじめに
「A→Bの因果関係がある」とは、Aへ介入する(Aを変化させる)ことよって、要因Bを変化させることができることを意味します。
具体例で考えると、投薬(A)の有無によって病気の治癒率(B)が変化する場合、投薬→治癒率の因果関係があるといえるわけです。
このような因果関係をデータを活用して解き明かそうとするのが統計的因果推論の目的ですが、大別するとさらに次の2つに分類されます。
(1) 因果の方向を既知のものとして因果の大きさを評価(因果推論)
(2) 因果の方向の決定・探索(因果探索)
これらの基本的な考え方と手法について紹介をしたいと思いますが、その前に重要な概念である「交絡」について簡単に説明させていただきます。
交絡と疑似相関
相関関係があっても因果関係はないことがあり、疑似相関と呼ばれます。
具体例を挙げると、「小学生の握力が計算テストの点数と正の相関がある」という関係が挙げられます。では握力と計算力の間に因果関係があるのでしょうか。定性的に考えると、そのような結論にはならないでしょう。
例えば、学年という変数を追加で考えることでこの問題がクリアになります。
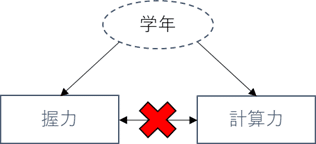
・学年が上がるほど計算力が向上し、テストの点数が高くなる
・学年が上がるほど身体が成長し、握力が強くなる
→結果的にテストの点数と握力が正の相関を示すが、両者に因果関係はない
このような状況を交絡があるといい、上記の例でいう「学年」は交絡因子と呼ばれます。
因果関係を適切に把握するためには、交絡の影響を取り除くことがポイントとなります。
2. 因果推論
因果の方向を既知のものとして、因果の大きさを評価する方法について、少し掘り下げたいと思います。
A/Bテスト(ランダム化比較試験)
ランダム化比較試験とは、介入を実施するか否かを無作為に対象に割りつけることで、介入の有無を介入以外のすべての因子と独立とし、交絡をなくす方法です。これは、介入以外の因子を2群間で同質(同分布)にすることを意味します。
介入以外の因子を同質にしたうえで2群間の平均をすることで、平均的な介入効果を測定できるようになるわけです。これは、介入以外の因子を2群間で同質にすることを意味し、交絡の影響を取り除いた状態で平均的な介入効果を測定できるようになります。
エムスリーでは、m3.comのサービスをより多く利用していただくためのプラットフォーム改善施策を日々検討し、A/Bテストによる効果検証を実施しています。
データ分析グループでは、A/Bテストを支援するようなツールの開発等を行っており、その事例の1つに「ユーザを介入以外の因子の同質な2群に分離するためのツール」の開発があります。
実務の中では、交絡の影響を受けない無作為な割りつけを行うことは思いのほか難しく、何の考慮もなくテストを実施すると、介入群と非介入群の同質性を確保できないことがあります。このような事態を避けるためには、テスト開始前に無作為割りつけができているかの事前確認を行うことが望ましいです。
そこで、同質性のチェックを簡単に行えるようなツールを開発することにより、データ分析に詳しくないプロダクトマネージャーでもA/Bテストを設計できる環境を整備し、高速なPDCAサイクルを回すことに寄与しています。
また、汎用的なツールでは対応しきれないような複雑なテストや、データ分析グループスタッフが自身で企画する施策のテストについては、テスト設計から効果測定を行います。
A/Bテストが実施できない場合
実際には、A/Bテストを実施できない状況下での因果効果を測定したい場合があります。このような場合には、交絡の影響を事前に取り除くことはできないため、検証の方法を工夫することにより、事後的に交絡を取り除くことになります。代表的な方法として次のようなものが挙げられます。
・層別解析
・傾向スコアマッチング
・差の差法
・回帰分断デザイン
データ分析グループの業務の例としては、「MR君」という製薬会社から医師に向けて薬剤の情報提供を行うサービスの効果検証等でこのような状況に行き当たります。
実務の中では上記の方法などに加え、交絡因子が同質な対象同士のマッチング比較等の方法も用いて効果測定を行っています。
3. 因果探索
因果探索は因果推論とは異なり、どのような因果関係があるのかを事前知識からは特定できないような場合に、データから因果の方向を特定しようという問題です。
相関のある2変数A、Bについて考えた場合、
①A→Bの因果がある
②B→Aの因果
③ AとBに因果関係はない(疑似相関)
のいずれに該当するかを判断することに相当します。

この問題を解くための1つの方法として、LiNGAMモデルという方法が提案されています。
LiNGAMは構造方程式モデルと呼ばれるデータの生成過程を記述するモデルを用いて、上記の問題にアプローチする方法です。
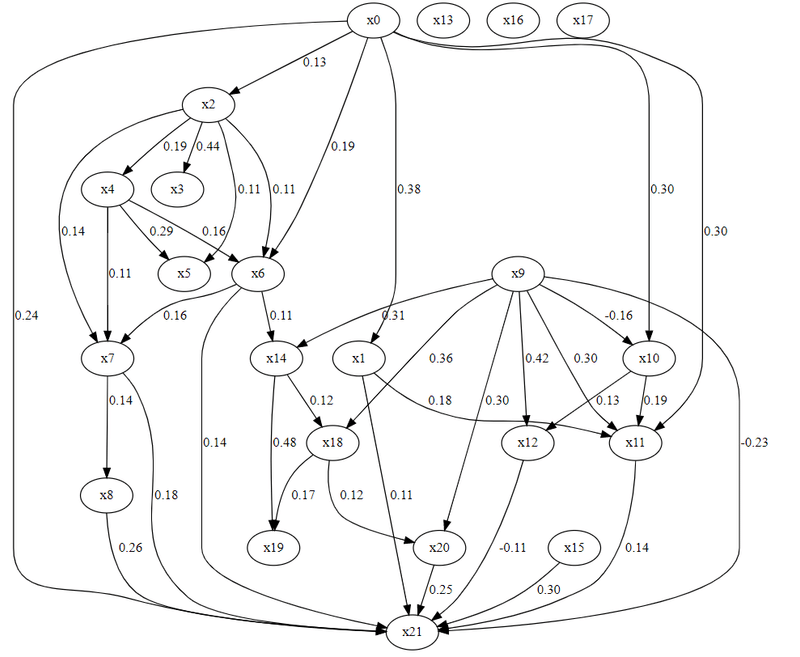
この方法では、一定の仮定を置いてくことで、変数間の因果の有無と因果の方向性を一意的に推定することができ、それを因果グラフによって可視化することが可能です。
下図は私が普段の実務で利用しているデータで推定したLiNGAMモデルの因果グラフです。(変数名はマスキングさせていただきましたが、各変数はm3.com上のサービス毎のユーザアクティビティ等を意味します。)
この分析によって、m3.com全体でのアクティビティを向上させるためにはどのサービスが重要になのかを確認でき、さらにはm3.com全体でのアクティビティへの各サービスの貢献度を評価することもできます。
サービス横断でのm3.comの全体最適化を進めるためには、サービスごとの貢献度を比較しなければならない場面が多数存在しますので、それを定量的に評価できる因果探索モデルは強力な武器になると考えています。
4. さいごに
統計的因果推論についての導入を中心に、一部データ分析グループでの取組みを含めて紹介させていただきました。
実務で因果推論(効果検証)を行う際には、本当に交絡をすべて考慮できているのかを含め、正しく効果測定できているか突き詰めて考えることになります。難しさを感じつつも、責任感・やりがいを実感できる仕事だと思います。
また、本記事では紹介できませんでしたが、データ分析グループでは、課題の発見・モデルの構築・効果検証などデータサイエンスの一連の業務を経験することができます。具体的な事例等については、採用HPや別のnote記事で紹介していますので、少しでも興味を持っていただけましたら是非ご覧になってください!