
ggml-c4ai-command-r-plus-104b-iq2_xxs.gguf をMac 64GBで動かしてみる

下記の記事を見てトライしてみました。
Llama.cppのmakeからということで、githubからダウンロードしてmakeしました。
git clone https://github.com/ggerganov/llama.cppdirectoryを移動
cd llama.cppここでmake
makeいろいろファイルが作られますが、mainというのが実行ファイルとなります。
現在のdirectoryにある mainというファイルの引数を以下で確認。
./main --help下記のように山ほど引数がありました…
usage: ./main [options]
options:
-h, --help show this help message and exit
--version show version and build info
-i, --interactive run in interactive mode
--interactive-first run in interactive mode and wait for input right away
-ins, --instruct run in instruction mode (use with Alpaca models)
-cml, --chatml run in chatml mode (use with ChatML-compatible models)
--multiline-input allows you to write or paste multiple lines without ending each in '\'
-r PROMPT, --reverse-prompt PROMPT
halt generation at PROMPT, return control in interactive mode
(can be specified more than once for multiple prompts).
--color colorise output to distinguish prompt and user input from generations
-s SEED, --seed SEED RNG seed (default: -1, use random seed for < 0)
-t N, --threads N number of threads to use during generation (default: 12)
-tb N, --threads-batch N
number of threads to use during batch and prompt processing (default: same as --threads)
-td N, --threads-draft N number of threads to use during generation (default: same as --threads)
-tbd N, --threads-batch-draft N
number of threads to use during batch and prompt processing (default: same as --threads-draft)
-p PROMPT, --prompt PROMPT
prompt to start generation with (default: empty)
-e, --escape process prompt escapes sequences (\n, \r, \t, \', \", \\)
--prompt-cache FNAME file to cache prompt state for faster startup (default: none)
--prompt-cache-all if specified, saves user input and generations to cache as well.
not supported with --interactive or other interactive options
--prompt-cache-ro if specified, uses the prompt cache but does not update it.
--random-prompt start with a randomized prompt.
--in-prefix-bos prefix BOS to user inputs, preceding the `--in-prefix` string
--in-prefix STRING string to prefix user inputs with (default: empty)
--in-suffix STRING string to suffix after user inputs with (default: empty)
-f FNAME, --file FNAME
prompt file to start generation.
-bf FNAME, --binary-file FNAME
binary file containing multiple choice tasks.
-n N, --n-predict N number of tokens to predict (default: -1, -1 = infinity, -2 = until context filled)
-c N, --ctx-size N size of the prompt context (default: 512, 0 = loaded from model)
-b N, --batch-size N logical maximum batch size (default: 2048)
-ub N, --ubatch-size N
physical maximum batch size (default: 512)
--samplers samplers that will be used for generation in the order, separated by ';'
(default: top_k;tfs_z;typical_p;top_p;min_p;temperature)
--sampling-seq simplified sequence for samplers that will be used (default: kfypmt)
--top-k N top-k sampling (default: 40, 0 = disabled)
--top-p N top-p sampling (default: 0.9, 1.0 = disabled)
--min-p N min-p sampling (default: 0.1, 0.0 = disabled)
--tfs N tail free sampling, parameter z (default: 1.0, 1.0 = disabled)
--typical N locally typical sampling, parameter p (default: 1.0, 1.0 = disabled)
--repeat-last-n N last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size)
--repeat-penalty N penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled)
--presence-penalty N repeat alpha presence penalty (default: 0.0, 0.0 = disabled)
--frequency-penalty N repeat alpha frequency penalty (default: 0.0, 0.0 = disabled)
--dynatemp-range N dynamic temperature range (default: 0.0, 0.0 = disabled)
--dynatemp-exp N dynamic temperature exponent (default: 1.0)
--mirostat N use Mirostat sampling.
Top K, Nucleus, Tail Free and Locally Typical samplers are ignored if used.
(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)
--mirostat-lr N Mirostat learning rate, parameter eta (default: 0.1)
--mirostat-ent N Mirostat target entropy, parameter tau (default: 5.0)
-l TOKEN_ID(+/-)BIAS, --logit-bias TOKEN_ID(+/-)BIAS
modifies the likelihood of token appearing in the completion,
i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',
or `--logit-bias 15043-1` to decrease likelihood of token ' Hello'
--grammar GRAMMAR BNF-like grammar to constrain generations (see samples in grammars/ dir)
--grammar-file FNAME file to read grammar from
--cfg-negative-prompt PROMPT
negative prompt to use for guidance. (default: empty)
--cfg-negative-prompt-file FNAME
negative prompt file to use for guidance. (default: empty)
--cfg-scale N strength of guidance (default: 1.000000, 1.0 = disable)
--rope-scaling {none,linear,yarn}
RoPE frequency scaling method, defaults to linear unless specified by the model
--rope-scale N RoPE context scaling factor, expands context by a factor of N
--rope-freq-base N RoPE base frequency, used by NTK-aware scaling (default: loaded from model)
--rope-freq-scale N RoPE frequency scaling factor, expands context by a factor of 1/N
--yarn-orig-ctx N YaRN: original context size of model (default: 0 = model training context size)
--yarn-ext-factor N YaRN: extrapolation mix factor (default: 1.0, 0.0 = full interpolation)
--yarn-attn-factor N YaRN: scale sqrt(t) or attention magnitude (default: 1.0)
--yarn-beta-slow N YaRN: high correction dim or alpha (default: 1.0)
--yarn-beta-fast N YaRN: low correction dim or beta (default: 32.0)
--pooling {none,mean,cls}
pooling type for embeddings, use model default if unspecified
-dt N, --defrag-thold N
KV cache defragmentation threshold (default: -1.0, < 0 - disabled)
--ignore-eos ignore end of stream token and continue generating (implies --logit-bias 2-inf)
--penalize-nl penalize newline tokens
--temp N temperature (default: 0.8)
--all-logits return logits for all tokens in the batch (default: disabled)
--hellaswag compute HellaSwag score over random tasks from datafile supplied with -f
--hellaswag-tasks N number of tasks to use when computing the HellaSwag score (default: 400)
--winogrande compute Winogrande score over random tasks from datafile supplied with -f
--winogrande-tasks N number of tasks to use when computing the Winogrande score (default: 0)
--multiple-choice compute multiple choice score over random tasks from datafile supplied with -f
--multiple-choice-tasks N number of tasks to use when computing the multiple choice score (default: 0)
--kl-divergence computes KL-divergence to logits provided via --kl-divergence-base
--keep N number of tokens to keep from the initial prompt (default: 0, -1 = all)
--draft N number of tokens to draft for speculative decoding (default: 5)
--chunks N max number of chunks to process (default: -1, -1 = all)
-np N, --parallel N number of parallel sequences to decode (default: 1)
-ns N, --sequences N number of sequences to decode (default: 1)
-ps N, --p-split N speculative decoding split probability (default: 0.1)
-cb, --cont-batching enable continuous batching (a.k.a dynamic batching) (default: disabled)
--mmproj MMPROJ_FILE path to a multimodal projector file for LLaVA. see examples/llava/README.md
--image IMAGE_FILE path to an image file. use with multimodal models
--mlock force system to keep model in RAM rather than swapping or compressing
--no-mmap do not memory-map model (slower load but may reduce pageouts if not using mlock)
--numa TYPE attempt optimizations that help on some NUMA systems
- distribute: spread execution evenly over all nodes
- isolate: only spawn threads on CPUs on the node that execution started on
- numactl: use the CPU map provided by numactl
if run without this previously, it is recommended to drop the system page cache before using this
see https://github.com/ggerganov/llama.cpp/issues/1437
-ngl N, --n-gpu-layers N
number of layers to store in VRAM
-ngld N, --n-gpu-layers-draft N
number of layers to store in VRAM for the draft model
-sm SPLIT_MODE, --split-mode SPLIT_MODE
how to split the model across multiple GPUs, one of:
- none: use one GPU only
- layer (default): split layers and KV across GPUs
- row: split rows across GPUs
-ts SPLIT, --tensor-split SPLIT
fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1
-mg i, --main-gpu i the GPU to use for the model (with split-mode = none),
or for intermediate results and KV (with split-mode = row) (default: 0)
--verbose-prompt print a verbose prompt before generation (default: false)
--no-display-prompt don't print prompt at generation (default: false)
-gan N, --grp-attn-n N
group-attention factor (default: 1)
-gaw N, --grp-attn-w N
group-attention width (default: 512.0)
-dkvc, --dump-kv-cache
verbose print of the KV cache
-nkvo, --no-kv-offload
disable KV offload
-ctk TYPE, --cache-type-k TYPE
KV cache data type for K (default: f16)
-ctv TYPE, --cache-type-v TYPE
KV cache data type for V (default: f16)
--simple-io use basic IO for better compatibility in subprocesses and limited consoles
--lora FNAME apply LoRA adapter (implies --no-mmap)
--lora-scaled FNAME S apply LoRA adapter with user defined scaling S (implies --no-mmap)
--lora-base FNAME optional model to use as a base for the layers modified by the LoRA adapter
--control-vector FNAME
add a control vector
--control-vector-scaled FNAME S
add a control vector with user defined scaling S
--control-vector-layer-range START END
layer range to apply the control vector(s) to, start and end inclusive
-m FNAME, --model FNAME
model path (default: models/7B/ggml-model-f16.gguf)
-md FNAME, --model-draft FNAME
draft model for speculative decoding (default: unused)
-mu MODEL_URL, --model-url MODEL_URL
model download url (default: unused)
-hfr REPO, --hf-repo REPO
Hugging Face model repository (default: unused)
-hff FILE, --hf-file FILE
Hugging Face model file (default: unused)
-ld LOGDIR, --logdir LOGDIR
path under which to save YAML logs (no logging if unset)
-lcs FNAME, --lookup-cache-static FNAME
path to static lookup cache to use for lookup decoding (not updated by generation)
-lcd FNAME, --lookup-cache-dynamic FNAME
path to dynamic lookup cache to use for lookup decoding (updated by generation)
--override-kv KEY=TYPE:VALUE
advanced option to override model metadata by key. may be specified multiple times.
types: int, float, bool. example: --override-kv tokenizer.ggml.add_bos_token=bool:false
-ptc N, --print-token-count N
print token count every N tokens (default: -1)
log options:
--log-test Run simple logging test
--log-disable Disable trace logs
--log-enable Enable trace logs
--log-file Specify a log filename (without extension)
--log-new Create a separate new log file on start. Each log file will have unique name: "<name>.<ID>.log"
--log-append Don't truncate the old log file.
とりあえず、-p でプロンプトを指定、フォーマットはnpakaさんの記事に従ってます。-m で自分のモデルのパスを指定、--tempもnpakaさんのをまねました。モデルは、text-generation-webuiを用いてダウンロードしたので、その場所を指定してます。text-generation-webuiは試した時点では、まだ⌘R-Plusに未対応です。ということで、Llama.cppをmakeする必要があったという話ですね。
さて今回自分がおこなったモデルのダウンロード先はこちら、importance matrix (imatrix) quantsと新しい量子化の方法をされているもので行いました。
肝心の実行コードと出力です。
./main -p "<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What's the meanig life? respond in Japanese.メタファーを使って説明して<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>" --color -m /Volumes/JetDrive/ai/projects/text-generation-webui/models/ggml-c4ai-command-r-plus-104b-iq2_xxs.gguf --temp 0.3
<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What's the meanig life? respond in Japanese.メタファーを使って説明して<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>人生の意味とは、自分自身の人生を形作る物語を理解しようとする試みに他なりません。人生とは、川を下る旅のようなものです。時には激流に身を任せ、時には岸辺に立ち、自分の進路をじっくりと検討します。人生の目的は、この旅の終着点を見つけることではなく、旅そのものを味わい、その美しさや苦難を理解することです。
人生はまた、自分自身を理解しようとする旅でもあります。自分自身を理解することは、複雑なパズルを解くようなものです。ピースを一つずつ組み合わせていき、自分というパズルの全体像を明らかにしていきます。自分自身を理解するために、時には自分自身と向き合い、時には自分から逃げることもあります。
人生とは、山登りに似ています。頂上を目指して一歩一歩登っていきます。しかし、頂上に達したとしても、そこがゴールとは限りません。人生とは、絶え間なく続く挑戦であり、頂上を目指す過程こそが重要なのです。
人生はまた、海原を航海する船のようでもあります。自分の人生という船を操舵し、嵐を乗り越え、穏やかな海原を航行します。時には新しい港に立ち寄って、そこでしか味わえない経験をします。しかし、人生の真の宝物は、港ではなく、航海そのものにあるのです。
人生は、夜空に輝く星にも例えられます。私たちは、自分の人生という星を輝かせ、他の人の星とぶつかることなく、暗い夜空を照らすのです。私たち一人ひとりが、人生という銀河の中で独自の軌道を描きます。 [end of text]
llama_print_timings: load time = 1420.85 ms
llama_print_timings: sample time = 29.59 ms / 368 runs ( 0.08 ms per token, 12438.32 tokens per second)
llama_print_timings: prompt eval time = 749.83 ms / 22 tokens ( 34.08 ms per token, 29.34 tokens per second)
llama_print_timings: eval time = 59446.94 ms / 367 runs ( 161.98 ms per token, 6.17 tokens per second)
llama_print_timings: total time = 60457.00 ms / 389 tokens
ggml_metal_free: deallocating
Log end
そこそこ待ってられるスピードで生成ができました。ただしモデルのロードにはかなり時間がかかってます。(SDカードにモデルが収まってるので)
Ollamaに⌘R-Plusのモデルがすでにアップロードされていますが、Ollama本体がまだ対応していないので、対応待ちです。
あと、もうちょっと頑張って、64GBメモリーで、47GサイズのQ3_K_M が動くか試してみたいと思っていますが、どうでしょう。
ダウンロード先に掲載されていた、それぞれのモデルの大きさと性能の表が以下です。
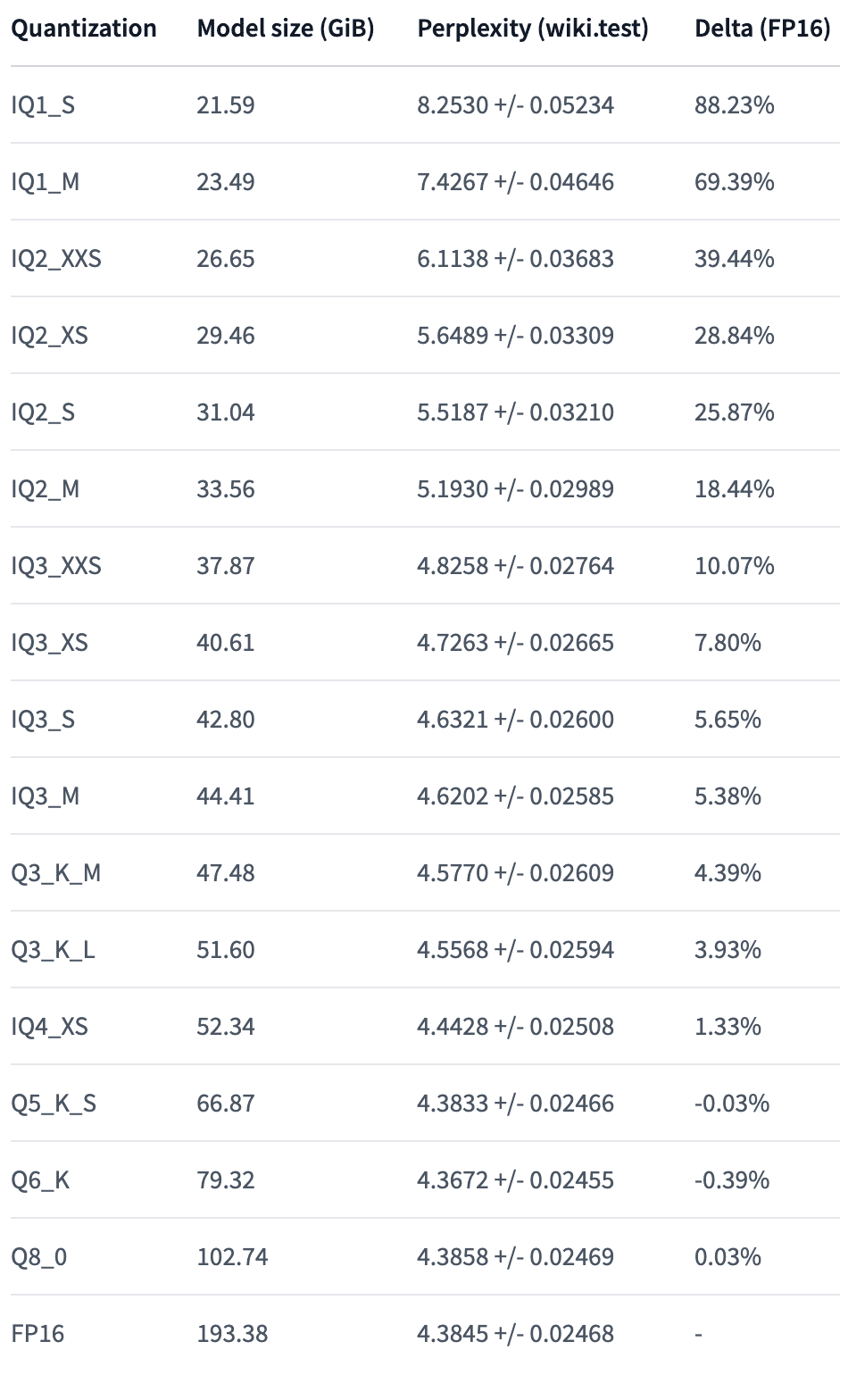
すごいすごいと思っていたら、Mixtral-8x22というモデルが急に出てきたのでまたビックリしてます。64GBメモリではこちらは無理でしょうかね。これからMacを買うことを考えてる人はがんばって、この2倍の128GBを買ってください😢
#AI #AIとやってみた #やってみた #ローカルLLM #Huggingface #MacbookPro #Command -R-Plus
この記事を最後までご覧いただき、ありがとうございます!もしも私の活動を応援していただけるなら、大変嬉しく思います。