
天気予報を例に機械学習の特徴を理解する

AI、ビッグデータ、機械学習。最近これらのワードを目にする機会が本当に多くなりました。普段の仕事でデータ活用に関わる業務をされていなくても、社内でデータ活用の話を聞いたことがあるという方も多いのではないでしょうか。近い将来には人間の仕事を奪うとまで言われているAIですが、実際に今の自分の業務をAIがどのようにこなすのか、そもそも置き換えることは可能なのかをイメージすることは簡単ではありません。
この記事ではAIのトピックで必ずと言っていいほど目にする「機械学習」について「天気予報」を例に挙げながら、機械学習にできること、できないこと、得意なこと、苦手なことを(できる限り)わかりやすく説明していきます。今回、機械学習の事例になぜ天気予報を選んだかというと、天気予報は我々の生活でもっとも身近な機械学習だと私は考えているからです。私たちが毎日チェックしている天気予報にも実は機械学習が使われているのです。私は気象予報士でもなければ天気予報に関わる仕事をしているわけではないのですが、この記事を通して機械学習というものを感覚的に理解して、機械学習の使われ方の具体的なイメージをもっていただければ幸いです。
機械学習とは
機械学習について説明する前に用語の整理をします。AI(人工知能)と機械学習という言葉は区別されずに使われることも多いですが、AIとは機械学習を含んだ包括的な表現であり言葉の抽象度が高いため、以下ではAIという言葉は使用せず、「機械学習」と表現します。(詳しくはこちら)
機械学習の特徴を理解することがこの記事の目的なので、機械学習それ自体の解説は簡単に済ませます。機械学習とは与えられたデータから特徴的な規則性やパターンを学習するアルゴリズムの総称です。大雑把に言うと、データを与えれば何か有益な情報を答えてくれるものです。そして機械学習の応用事例として多いのが、データを使って機械学習に予測させるという使い方です。これは機械学習の中でも教師あり学習と呼ばれています。
そして、「天気予報」も立派な機械学習の応用例のひとつです。正確には気象予報士の判断や数値シミュレーションが入りますが、データを使って未来の気象現象を予測するという点はまさに機械学習そのものです。(機械学習が天気予報にどのように使われているかの詳細はこちら)
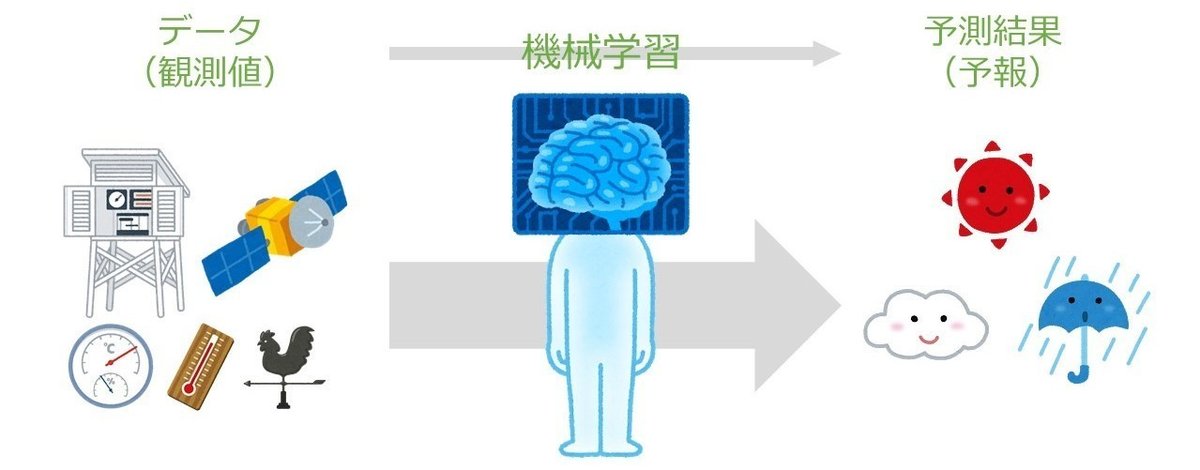
それではここからは、我々の生活に身近な天気予報を例に機械学習の特徴をみていきましょう。
データが必要
これは機械学習にとって当たり前なことですが、もっとも大切なことです。天気予報でも全国各地に観測点を設け、衛星を飛ばし、少なくない費用をかけてデータを収集しています。データを使わない予報は占いと同じです。裏を返せば、データを使うからこそ客観的な証拠に基づき未来を予測できるといえます。よってそれぞれの現場に機械学習が導入可能か考える場合、まず業務に関わるデータが入手可能かどうかを検討することから始めるとよいでしょう。
データ量が必要
ビッグデータと言われるほどなので、機械学習にはそれなりのデータ量が必要です。また、むやみにデータが多いだけでも不十分で、予測したい状況に近いデータが十分に必要です。これが不十分な場合、予測精度は下がってしまいます。
天気予報では晴れ、雨、曇りのような予報はおおよそ当たりますが、大雨や大雪などの予報は外れることも多いです。「大雨の予報だったけど、たいしたことなかったな」ということはよくありますよね。これは普通の雨や曇りという現象が頻繁に観測されるのに対して、大雨や大雪はそもそもの発生回数が少ないことが原因と考えられます。大雨の予報をするためには過去の大雨のデータを参考にするのですが、その大雨という状況に近いデータが少ないために予報の精度が下がってしまうと考えられます。
実際には行われませんが、「夏の気象データだけで冬の予報」をすることや、「北海道のデータで沖縄の予報」をすることも上記にあてはまります。一見このような問題点には簡単に気づきそうですが、実際に機械学習の活用を考える時にはうっかり見落としがちな観点なので注意しておく必要があります。
データの精度が必要
予測の精度を高めるためには、正確なデータが必要です。観測された気温や降水量が本来の数値と異なっていれば、そのデータをもとにした天気の予測結果はより悪化することはイメージしやすいと思います。観測データの品質を保つためには、観測所の条件を細かく定めたり、センサー機器を統一したりすることで、データ取得環境を統一する必要があります。
また、本来は1時間に1回のペースで観測すべきデータが1日に1回しか取得できていないだとか、観測のタイミングがまばらであるような場合も、機械学習の実用化の難易度を高めてしまう要因になります。
取得されるデータの精度が悪い場合、たとえ優秀な技術者や最新の機械学習(モデル)を使ったとしても予測の精度は低くなってしまいます。現場で発生するデータの精度低下の原因で多いのは、観測者のさじ加減やクセの違いでデータ入力にぶれがある場合や、データに空白(欠損値)が多い場合です。
遠い将来の予測は難しい
もし1ヶ月後の天気まできっちり的中させてくれる天気予報があるのなら、私たちは毎日のように天気予報をチェックする必要はないのですが、残念ながら現実はそうではありません。明日、明後日の天気は信用できますが、1ヶ月後の予報は気に留めておく程度でしょう。
一般的な機械学習もこれと同じです。何かを予測する場合、予測時点と予測したい時点が離れているほど予測精度は低下してしまいます。具体的な例を出すと、スーパーの商品の売れ行きを1週間先まで機械学習で予測したいが、予測精度の面からどうしても3日先までしか予測できないというようなケースがありえます。この場合は無理して1週間先まで予測するよりも、3日先の予測だけでも業務が成り立つように仕入れのプロセスを変更するなどして機械学習以外の所で問題に対応することもひとつの考えです。
100%ではないが、ないよりはマシ
「機械学習ってミスをすることもあるんだよね?」
これは機械学習の導入についてよく耳にする批判ですね。これは間違いではありません。しかしこの批判に対して私は「予測は100%ではないが、ないよりはマシ」と応えたいのです。
私たちは経験から、天気予報が100%的中することはないことを知っています。しかし、だからといって雨の予報の日に傘を持って出かけない人はいないはずです。もし予報がはずれて文句を言ったとしても、それで二度と天気予報を見ないという人はいません。
「天気予報は正確ではない」という事実を理解しながら私たちはそれをうまく生活に利用しています。天気予報があるおかげで大雨に備えることもできるし、晴れ予報の日には傘を家に置いて出かけることができます。
機械学習を実用化する上でも同様です。機械学習の精度を高めることだけに注目するのではなく、精度が100%ではないことを前提とした上で、機械学習の予測が外れた場合にどのような対処をとるかを考えておくことも必要です。
おわりに
いかがだったでしょうか。機械学習の背景には数学的な技術や複雑なアルゴリズムが含まれているので、AIや機械学習について正確に解説しようとすると、どうしても複雑な説明になってしまいます。天気予報はもっとも身近な機械学習の事例だと気づいたことをきっかけに、数式を使わずに機械学習の特徴について感覚的に伝えることを意識してこの記事を書いてみました。この記事を通して機械学習をもっと身近に感じてもらえたら嬉しいです。
天気予報って生活の中で最も身近な予測モデルだと思っている
— くりやま/データ分析 (@kuriyama_data) January 13, 2020
だから人に機械学習モデルを説明するときは天気予報に例えてあげると案外すんなり受け入れてもらえるのではないだろうか
この記事が気に入ったらサポートをしてみませんか?