Yahoo画像検索からの自動取得(pythonのスクレイピング) 2018/6/22

Aidemyなどで機械学習やディープラーニングを勉強した後に実際に画像認識をしようとしている人が最初にぶち当たるカベは間違えなく画像収集ですよね。わかります。
画像収集の際によく使われるGoogle,Bing,Flickr,TwitterはAPIがあるおかげで簡単に実装できます。それに優秀な記事が多く存在してコピペで簡単に動かせます。(まじで優しい世の中で感謝しまくってます。)
しかし、YahooJapanの画像検索エンジンには質のいい画像が多く存在するのにAPIがなく記事も少なくてコピペで大量に画像を取得できるものが見つからなかった。
そんなわけでpythonのスクレイピングを使って、ほぼコピペすればYahoo画像検索から自動取得できるコードを書いてみました!!
----------------------------------------------------------------------------
※以下は自分用のメモとして書いているので言葉遣いが怪しいのはご愛嬌ということで、、、
そんなわけでまずは↓を参考にしながら頑張っていく
なんと!コピペで動いた!神! ただこのコードだと60枚の画像しか入手できないみたい、、、 というのも、このコードは画像検索したページのURLをもとに取得していくので検索した時に表示されている60枚しか取ってこれないというものだから。
そんなわけで試行錯誤して全件取得できるようにしたコードがこちら
# coding: utf-8
# testY2.py
import os
import sys
import traceback
from mimetypes import guess_extension
from time import time, sleep
from urllib.request import urlopen, Request
from urllib.parse import quote
from bs4 import BeautifulSoup
#任意のメールアドレス
#ツールを使ってダウンロードするときのマナーみたい
MY_EMAIL_ADDR = '××××××××××@△△△△△△'
class Fetcher:
def __init__(self, ua=''):
self.ua = ua
def fetch(self, url):
req = Request(url, headers={'User-Agent': self.ua})
try:
with urlopen(req, timeout=3) as p:
b_content = p.read()
mime = p.getheader('Content-Type')
except:
sys.stderr.write('Error in fetching {}\n'.format(url))
sys.stderr.write(traceback.format_exc())
return None, None
return b_content, mime
fetcher = Fetcher(MY_EMAIL_ADDR)
def fetch_and_save_img(num):
num_self = num
#dataというディレクトリが作られる
data_dir = 'data/'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
img_urls = img_url_list(num_self)[0]
num_self2 = img_url_list(num_self)[1]
s = num_self2 - 21
for i, img_url in enumerate(img_urls):
sleep(0.1)
img, mime = fetcher.fetch(img_url)
if not mime or not img:
continue
ext = guess_extension(mime.split(';')[0])
if ext in ('.jpe', '.jpeg'):
ext = '.jpg'
if not ext:
continue
result_file = os.path.join(data_dir, str(s) + ext)
with open(result_file, mode='wb') as f:
f.write(img)
s += 1
print('fetched', img_url)
if len(img_url) != 0:
fetch_and_save_img(num_self2)
def img_url_list(num):
"""
using yahoo (this script can't use at google)
"""
num_self = num
#このURL適宜変更
#具体的には簡易検索の2ページ目のURL
url = 'https://search.yahoo.co.jp/image/search?p=%E3%82%B7%E3%83%9E%E3%82%A8%E3%83%8A%E3%82%AC&oq=&ei=UTF-8&xargs=2&b={}&ktot=15'.format(num_self)
byte_content, _ = fetcher.fetch(url)
structured_page = BeautifulSoup(byte_content.decode('UTF-8'), 'html.parser')
img_link_elems = structured_page.find_all('a', attrs={'target': 'imagewin'})
img_urls = [e.get('href') for e in img_link_elems if e.get('href').startswith('http')]
img_urls = list(set(img_urls))
num_self += 20
return img_urls,num_self
if __name__ == '__main__':
# word = sys.argv[1]
# fetch_and_save_img(word)
num = 1
fetch_and_save_img(num)(本当だったら次へボタンもスクレイピングしてどんどん次のページに進む方がかっこいいのだけど今回はURLの規則性を利用してブンブンぶん回していくことにした)
ではでは使い方の説明
①YahooJapanの画像検索で検索したいワードを入力して検索
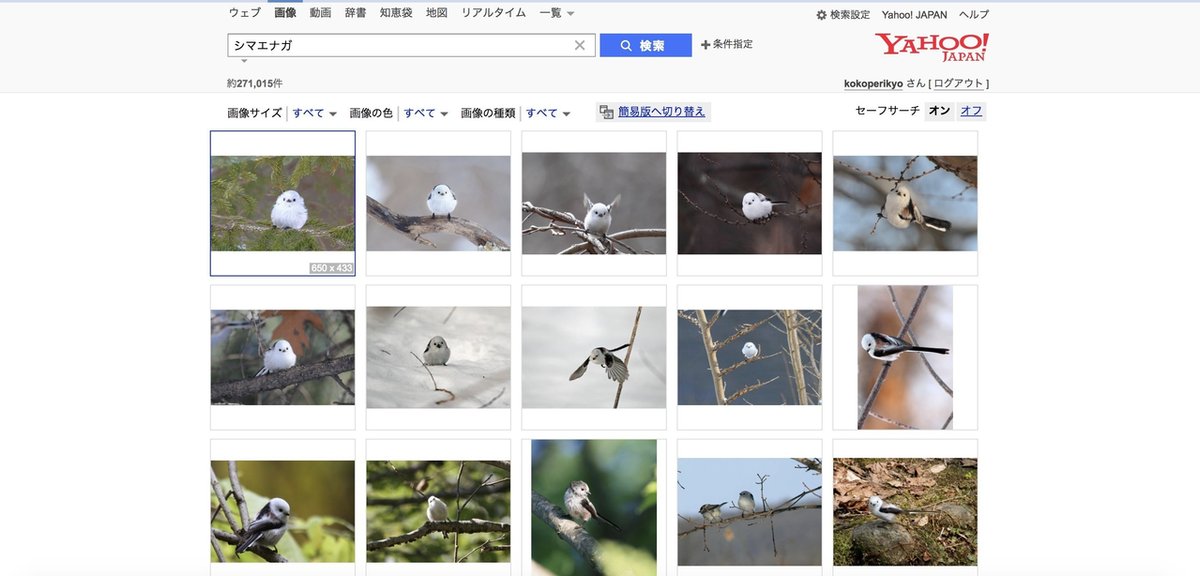
②「簡易版へ切り替え」をクリック

③画面の下の方にある「2」を押して次の画面へ

④2ページ目に移ったらURLをコピーする

⑤コピーしたURLの最後の方の'&ktot=15'の左にある'21'を'{}'に変える
https://search.yahoo.co.jp/image/search?p=%E3%82%B7%E3%83%9E%E3%82%A8%E3%83%8A%E3%82%AC&oq=&ei=UTF-8&b=21&ktot=15
↓
https://search.yahoo.co.jp/image/search?p=%E3%82%B7%E3%83%9E%E3%82%A8%E3%83%8A%E3%82%AC&oq=&ei=UTF-8&b={}&ktot=15
⑥変更したURLをコードのurl= の後に続く' 'のなかにコピペする これで実行するとdataというディレクトリが作られて画像が取得される
コードのまま実行するとシマエナガ の画像が取得できる!
最終的にターミナルで↓こんな表示が出たら全件取得できたことになる

無事に670件のシマエナガ画像が取得できた
やったね!
----------------------------------------------------------------------------
画像認識させてなんか面白いことやろうとしている人の役に立ったらすごく嬉しいです!
この記事が気に入ったらサポートをしてみませんか?