
製品検知AIの作成

変更履歴
2022/05/31 Miniconda3に対応。
序章

はじめに
本稿は物体検出のプログラムyolo v3を利用して、独自の画像を機械学習させ、製品検出AIを作成する手順です。今回はサンプルとしてB2Bの機械要素部品メーカーの2つの製品を検出対象にしています。
yolo はyou only look onceの略で、Joseph Redmon氏により作成されたPythonのプログラムコードのことを指します。プログラムコードは下記URLにおいて無償で公開されて全世界で利用されています。
https://pjreddie.com/darknet/yolo/
どのように利用しているかイメージを付けるために紹介動画をご覧ください。
筆者が本稿を企画した目的は、物体検知の応用範囲の拡大です。このAIは、一般的な対象、例えば犬や自動車、人間といった対象に限らず、専門的な対象、例えば病巣や破損個所、特殊機械、特定の個人といった対象にも広げられます。これらの対象は非常に広くて深いものです。しかしながら、専門領域の人達にとってAIの技術は身近ではありません。
一方で、本稿の手順を一通り実施することで、各人が独自の学習をさせて様々なものをAIで検知できるようになります。AI実装のハードルを下げ、専門領域の人達にとって身近なものにできます。そうすると、両者がマッチングし出すと思います。AIにより専門の経験や知識がアクセスしやすいものになれば、社会のボトルネックの解消に役立つ、と筆者は見込んでいます。
筆者は数年前からAIの記事や、有料を含めて教育コンテンツ等をたくさん見てきました。最初のころはどこも理論的な説明ばかりでしたが、近年では実装までしてくれるものが多くなりました。しかし、なかなかそれらが活きることはありませんでした。そういったコンテンツや知識が活きるには、身近な対象に気軽に実装できて、繰り返しAIに学習させられる、さらに仕事として重要であることで継続してブラッシュアップして行けることが必要であると考えるようになりました。言い換えるなら「実用的な適用範囲」が求められているのです。その意味で読者の皆さまも、学習対象をなるべく身近・気軽・繰り返し・重要・継続なものからピックアップしてみて下さい。
最後に、筆者はデータサイエンスの専門家でも、Pythonのコーダーでもありません。それぞれ詳しいことは専門のドキュメントを紹介しますので、そちらをご参照下さい。
逆に言えば、そういった門外漢でもAIを構築して手順化できた訳です。先陣を切った、参照先をご提供いただいた諸兄による好奇心と気前の良さに感謝しております。
進め方
本稿は目次の通りに章立てしています。一方で、必ずしも上から順に行えばゴールにたどり着くわけではありません。特に2回目の学習からは繰り返しプロセスに入るので、どこから始めたらいいか迷います。その手助けをするために2つの図を描きました。
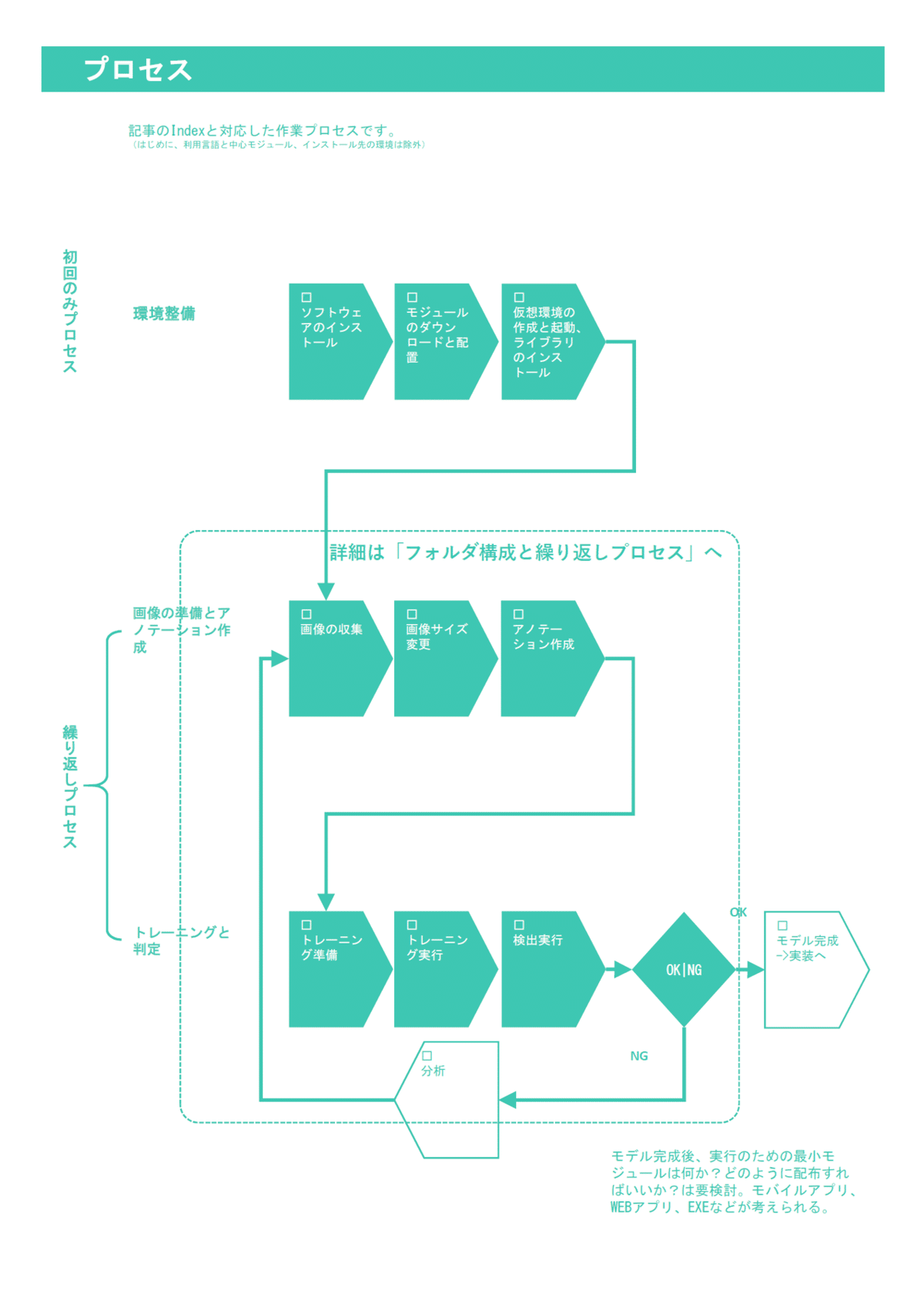
1)プロセス図
下図は各章のタイトルに応じたプロセス図です。ニューラルネットによるモデルは繰り返し何度も学習を行ってブラッシュアップするものです。しかしながら、この手順書だけでも情報量がかなり多いです。理論的な説明を一切していないにも関わらずです。一回の説明で完全に理解して手順を覚えるのは難しいでしょう。そこで、何度かトライする前提で初回のみの手順と、繰り返しの手順とを分けて表現しています。
図を見て下さい。三段組になっていて、最上段は初回1回のみのプロセスです。二段目、三段目と進み手順を完了させます。その後、2回目以降のトレーニングをするには、二段目の画像の収集から始めます。これで繰り返しのスタートポイントにいつでも立ち戻れると思います。これを活用して記憶の定着化を図ってみて下さい。
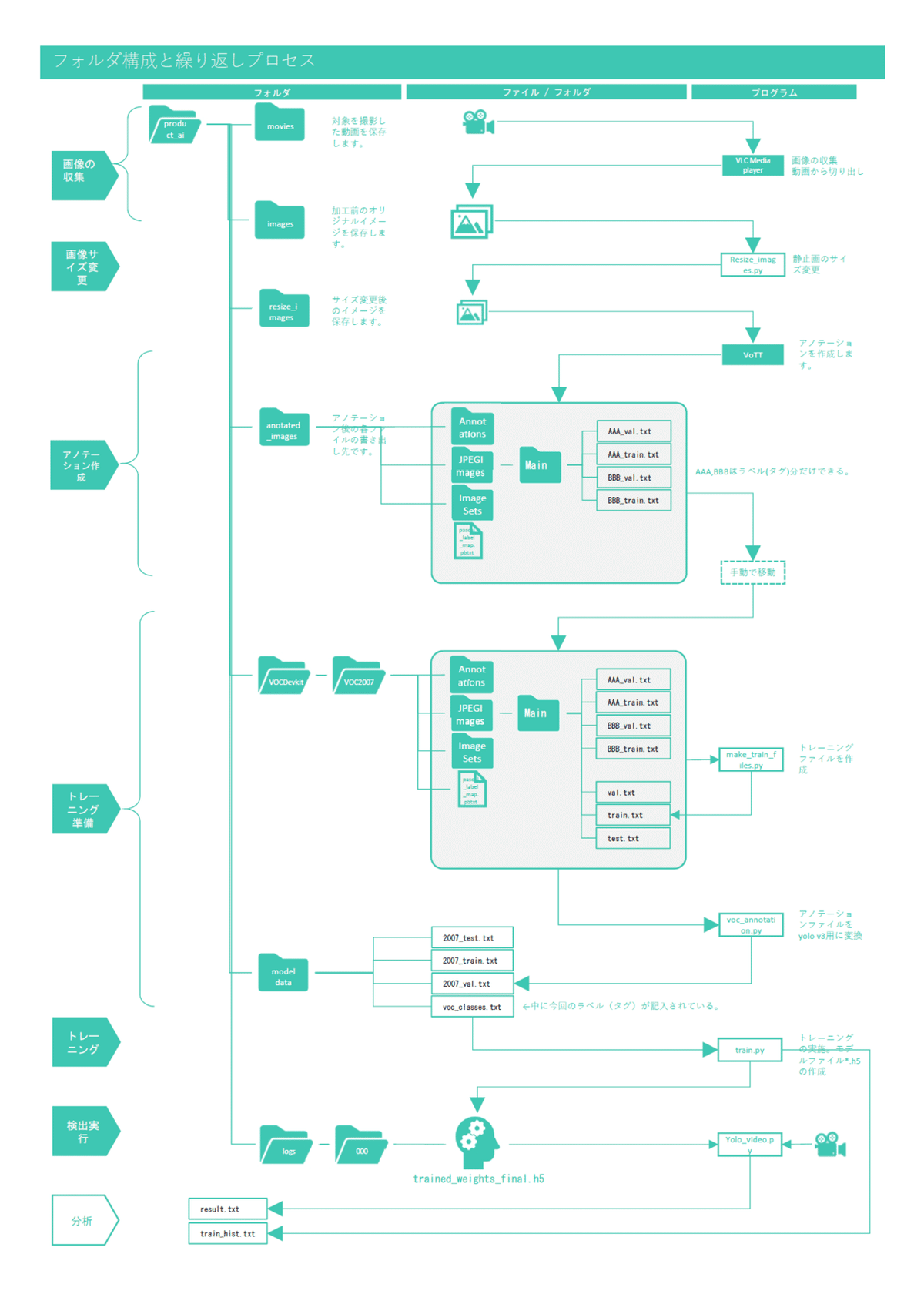
2)フォルダ構成と繰り返しプロセス
下図は「プロセス図」の第二段目、三段目の「繰り返しプロセス」の明細です。とくに処理フローとフォルダとの関係を中心に描きました。これをチェックシート代わりにして、いまどこにいるのか?どういった流れで何が出来ているか?確認しながら進めて下さい。これらの作業はproduct_aiフォルダの下で全て行うことが出来ます。
今回の内容はここまでですが、継続してトレーニングしていくために、また、サービスとして立ち上げるには次の実装が必要です。長い道のりに感じますが、ゴールがどこにあるか常に念頭に置いて、自分の立ち位置を見失わないように作業を進めてみて下さい。
・トレーニング履歴をデータとして書き出しする→済み
・検出結果のデータの書き出し→済み
・データを分析してトレーニングにフィードバック、精度を上げる。
・ユーザーインターフェース(UI)
第一章 環境整備

本章は初回一回のみ作業するプロセスです。再学習する際は次章から始めます。
第1節 利用言語と中心モジュールのバージョン、導入環境
プログラミング言語:Python 3.5.2
統合開発環境:Anaconda3
ニューラルネットのフレームワーク:tensorflow 1.6.0
ニューラルネットのラッパー:keras 2.1.5
物体検知プログラム:yolo v3 ※今回はkeras用のyolo v3であるkeras-yolo3を利用。
コンピュータ環境:
1) Windows
OS = Windows 10 Pro
CPU = Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz
Memory = (RAM) 8GB
2)Windows Server
Windows Server 2012 R
CPU = Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz
Memory = (RAM) 32GB
3)Macintosh
OS = macOS Big Sur 11.2.3
CPU = 1.1GHz デュアルコアIntel Core M
Memory = 8GB
第2節 ソフトウェアのインストール
(1)~(4)の4つのソフトウェアを導入します。PythonはAnaconda3に同梱されたものを利用します。それぞれインストールが終わったら、プログラム本体のショートカットを作成して、product_aiの直下に保存しておいて下さい。作業効率を上げることが出来ます。
□ Anaconda3 もしくはMiniconda3
□ VLC Media player,
□ Atom Editor,
□ VoTT
1)-(1)Anaconda3(Python統合開発環境)管理者権限必要
※企業ユースは有償になる可能性があります。その場合は1)-(1)Anaconda3はスキップして、下記1)-(2)Miniconda3の手順へ進んで下さい。
※過去にインストールしたことがある場合は、新旧バージョンが競合するためいったんアンインストールを推奨します。アンインストールだけでは削除しきれないモジュールもあります。次を参考にして手動で削除してください。
users\<user>\.conda 以下
users\<user>\AppData\Roaming\.anaconda 以下
① https://www.anaconda.com/ にアクセスし、WindowsのIndividual バージョンをダウンロードする。
②管理者権限でログインする。以下、ダウンロードした Anaconda3-2021.05-Windows-x86_64.exe を実行する。
③インストールオプションは次のように指定する。
Next --> I Agree --> All Users --> Destination Folder = C:\ProgramData\Anaconda3 --> Add Anaconda3 to my PATH environment variableにチェック --> Register Anaconda3 as the system Python 3.8 にチェック --> Install
④Anaconda3のインストール後、下位のPythonのバージョンを導入する。コマンドプロンプトを開き、conda install python=3.5 を実行する。完了したらプロンプトはExitで閉じる。
⑤管理者権限で行う作業は以上です。Anaconda3 は終了してログアウトして下さい。
⑥通常ユーザーでログインします。
1)-(2)Miniconda3 (Anaconda3が個人ユース以外は有償になったため、代替ツールとして準備したものです。Anaconda3ですでに作業した方はこの項目の作業は不要です。)
①管理者ユーザーでサインインし、Miniconda3-latest-Windows-x86_64.exe を実行。
②インストールオプションは以下に設定。
a.チェックInstall for: Just Me
b.Destination Folder
インストール先=C:\Users*****\miniconda3
*****の箇所に社員コード
c.チェック Add Miniconda3 to my PATH environment variable
d.チェック Register Miniconda3 as my default Python 3.9
③インストール完了後、スタートメニューに登録されているAnaconda prompt(miniconda)を起動。(もしコマンドプロンプトが無ければ補足の作業をして下さい。)SSL-VPNを切断して下記コマンドを実行。
conda install python=3.5
補足.Miniconda promptのショートカットの作成
a.Windowsの余白部分で右クリック→新規作成→ショートカット
b.項目の場所を選択して下さいの欄に下記入力。*****の箇所はユーザー名。
%windir%\system32\cmd.exe "/K" C:\Users*\miniconda3\Scripts\activate.bat C:\Users*\miniconda32)VLC media player 動画から静止画を切り出すソフトウェア ①https://www.videolan.org/vlc/ にアクセスする。 ②ダウンロードVLCの右の▼をクリックして該当環境のモジュールを選択するとダウンロードされる。Cドライブへのインストールに管理者権限が必要な場合はDドライブを指定する。 3)Atom Editor コード編集ソフトウェア ①https://atom.io/ にアクセスしてダウンロードする。 ②インストールを実行して起動する。 4)VoTT アノテーション作成のソフトウェア①https://github.com/Microsoft/VoTT/releases にアクセス ②最新バージョンの作業環境PCに適合するファイルをダウンロードして実行する。今回講師の環境では vott-2.2.0-win32.exe が対象でした。 ②インストール後に起動する。
続いてPythonのコード等のモジュールを揃えます。いったん図に戻り、全体プロセスのチェックをして下さい。
第3節 モジュールのダウンロードと配置
1)フォルダの作成
①Dドライブ直下にフォルダproduct_aiを作成して下さい。
Dドライブが無い場合はCドライブを、Machintoshの場合はユーザーのルートに近い位置を利用して下さい。本稿ではDドライブ直下にproduct_aiを作成した前提で進めます。
2)本体モジュールのダウンロード
①Githubのアカウントが無い人は新規作成。
②次のGithubリポジトリにアクセス。
https://github.com/nagnagg/product_ai
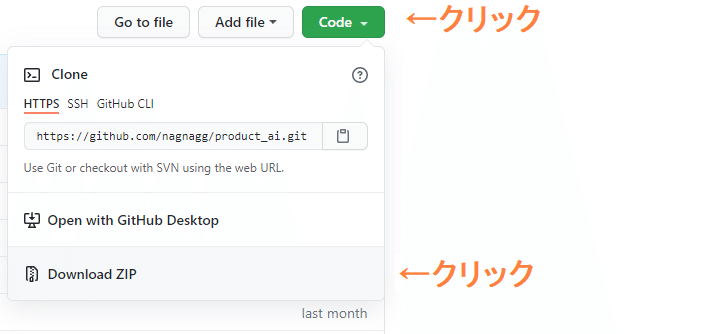
③ダウンロード
上記ページの右上のCodeをクリックしてDownload.ZIPを選択。
3)保存したZIPファイルを解凍して配置
①解凍するとproduct_ai.mainというフォルダが出来ます。README.mdが保存されているフォルダに移動して下さい。
②そこで全てを選択して切り取り、d:\product_ai\ に移動、ペーストして配置して下さい。
4)d:\product_ai内にフォルダ作成
次の4つのフォルダを作成して下さい。すでにある場合はこの手順はスキップして下さい。
movies
images
resized_images
annotated_images
次に仮想環境の作成と起動を行います。いったん図に戻り、全体プロセスのチェックをして下さい。
第4節 仮想環境の作成と起動、ライブラリのインストール
Anaconda3が導入されていることが前提です。
1)仮想環境の作成
①Windowsのスタートメニュー、Anaconda3のフォルダから、Anaconda Navigatorを起動する。
②Environmentsを開き、+マークをクリック→Nameをtf160、pythonを3.5としてCreateボタンを押す。
2)仮想環境の起動
①コマンドプロンプトを起動する。Macの場合はターミナルを起動。
②次のように入力して都度Enterキーを押します。Macの場合はcdの代わりにlsを使います。※ちなみに終了させるにはdeactivateを実行してexitでコマンドプロンプトを閉じます。
d:
cd product_ai
activate tf160

3)ライブラリのインストール
上図の状態から次のコマンドを実行。インターネットに接続されている必要があります。
pip install -r requirements.txt次に画像の収集を行います。いったん図に戻り、全体プロセスのチェックをして下さい。
第二章 画像の準備とアノテーションの作成

本章から繰り返しプロセスになります。再学習をする際はここから始めて下さい。
第5節-1 画像の収集 その1
動画から切り出し
学習のための画像を集めます。今回は動画から静止画を変換する手法にて行います。対象物の画像がネット上にほとんどないためです。
1)AIに学習させたい対象物を「動画」で撮影
お手持ちのカメラかスマートフォンのカメラ機能で撮影して下さい。対象物を中心にして球形を描き、ゆっくりと全体を撮影して下さい。おおよそ30秒間の撮影で、500枚強の画像になります。
2)動画をPCに取り込み
取り込み方法はそれぞれの撮影機に応じて対応して下さい。
3)VLC Media Playerをダウンロードしてインストール、実行。
管理者権限は不要です。最初の起動にプライバシーとネットワークポリシーを聞いてきます。気になるならチェックは外して大丈夫です。
4)動画を静止画に変換
下記①~⑱の手順です。今回はHSRの動画を例にします。こちらからダウンロードして下さい。
①フォルダ作成=d:\product_ai\images
②①のフォルダに動画を移動。
③VLC Media Playerを起動。
④メニューの「ツール」の「設定」をクリック
⑤「シンプルな設定」ダイアログが表示される
⑥左下の「設定の表示」の「すべて」をクリック。「詳細設定」ダイアログになる
⑦「ビデオ」内の「フィルター」を表示して「シーンフィルター」をクリック。右側が「シーンビデオフィルター」設定画面になる。
⑧「画像形式」を「jpg」にする(pngでもよい)
⑨「画像の幅」と「画像の高さ」はデフォルトのまま「-1」とする
➉「ファイル名のプレフィックス」を「hsr」と記入。この文字列が、生成される静止画のファイル名の冒頭につきます。そして連番が振られます。このあとのアノテーション作成で製品識別する単位になります。別の製品の動画を変換する場合は、この名称を実行前につど変更して下さい。
⑪「ディレクトリパスのプレフィックス」を先程作成した出力フォルダーのパスを記入。d:\product_ai\images
⑫「レコーディングレシオ」に分割間隔を記入。動画のフレームレートによるが、それが30の場合は30で1秒間隔。15で0.5秒間隔。1ですべてのフレーム。
⑬左側の「ビデオ」内の「フィルター」の文字をクリック。※右側が「フィルター」一覧表示になる
⑭「シーンビデオフィルター」をクリックしチェックボックスにチェックする。※下のテキスト領域内に「scene」と表示される
⑮右下の「保存」ボタンをクリック
⑯VLC media playerをいったん閉じる。設定が反映される。
⑰VLC media playerを開く。
⑱画像を一定間隔で取り出したい動画をVLCで再生する。
※画像切り出しが実行され、hsr***.jpgが、d:\product_ai\images 以下に保存される。
第5節-2 画像の収集 その2
インターネットから収集
学習のための画像をインターネット上から収集する手法です。今回は割愛します。既存の画像を使います。
次に画像ファイルのサイズ変更を行います。いったん図に戻り、全体プロセスのチェックをして下さい。
第6節 画像サイズ変更
1)フォルダimagesにオリジナルイメージを集める
2)フォルダresize_imagesを空にする。
アノテーションまで一通り作業をするとresize_imagesのフォルダにはサイズ変更済みの*.jpgファイルと、それに対応する*.json、フォルダ=〇〇-PascalVOC-export、〇〇.vott とが保存されます。
3)resize_images.pyの編集
①Atom editorでd:\product_ai\resize_images.pyを開く。
②オリジナルイメージの保存元を指定。次のようになっています。今回はそのまま変更しません。
images_dir = 'images/'
③変更後の画像サイズの指定です。次の箇所を128に変更。
image_size = 32032の倍数で指定します。サイズが大きく解像度が高ければ検出・判定が正確になりますが、学習に時間が掛かります。
④CTRL + S キーを押して resize_images.py を保存。
2)resize_images.pyの実行
①コマンドプロンプトを開き、d:\product_aiに移動する。
②次のコマンドを打ち込んでEnterキーを押して実行、tf160をアクティベーションする。
activate tf160③(tf160) product_ai>となるので次のコマンドを打ち込んでEnterキーを押して実行。
python resize_images.py※jpg以外のファイルが同じディレクトリにあるとエラーになる。
④d:\product_ai\resize_image\ に移動して、リサイズされた画像をチェック。
次にアノテーションを行います。いったん図に戻り、全体プロセスのチェックをして下さい。
第7節 アノテーションの作成
ここでは上記で作成してリサイズした複数の静止画とVoTTというソフトウェアを使い、アノテーション作成をします。アノテーション名は「thk_products」とします。今回はhsrとkrのタグ(ラベル)を付けます。
1)VoTTを起動します。インストール方法は別項を参照して下さい。
2)接続の設定を2つ作る
①1つ目。画面の左側の「プラグ」アイコンを選択し、[+]マークをクリック。
②表示名を入力。ここでは resize_image とする。
③プロバイダーの項目では、ローカルファイルシステムを選択
④フォルダを選択のボタンを押して、ここでは d:\product_ai\resize_image を選択。
⑤「接続を保存」ボタンをクリックする。
⑥2つ目。再度[+]マークをクリック。
⑦表示名を入力。ここでは anoteted_images とする。
⑧プロバイダーの項目では、ローカルファイルシステムを選択
⑨フォルダを選択のボタンを押す。 d:\product_ai\anotated_images を選択する。
⑩「接続を保存」ボタンをクリックする。
3)プロジェクトの作成
①ホームアイコンを押して「New Project」をクリック。
②表示名にTHK_Productsを入力
③ソース接続を resize_image に選択。
④ターゲット接続を anotated_images を選択して「プロジェクトを保存」する。
4)エクスポートの設定
①画面左側のエクスポートのボタンを押す。
②プロバイダーPascal VOCを選択
③アセットの状態を「タグ付きアセットのみ」にする。
④未割り当てをエクスポートのチェックを外す。
⑤保存する。
5)アクティブラーニング
※枠を自動検出する機能をセットする。
①アクティブラーニングボタンを押す。
②モデルプロバイダーに「事前トレーニング済みのCoco SSD」を選択する。
③予測タグ、自動検出のチェックを外して「プロジェクトを保存」する。自動検知してくれる機能なので、一度試してみて誤検知が無いようならチェックを付けても良いと思います。
6)タグ付け
①画面左側のタグエディターのボタンを押す。
②画像が出てきたら対象を枠で囲む
③右上のTAGSの⊕ボタンを押して対象のタグ名を付ける。→番号がふられる
④「↓」もしくは「S」で次の画像に移る。
⑤対象を枠で囲んだらキーボードの番号を押下すると同じタグ名を選べる。
⑥この繰り返しを行う。枠のコピー&ペーストも有効利用できる。
⑦フロッピーディスクマークをクリックして保存する。
7)エクスポート
①フロッピーディスクの右側の[↗]マークを押す。エクスポートされる。
②anotated_images の下にthk_products-PascalVOC-exportというフォルダが出来ていればOK
8)アノテーションを移動
①フォルダthk_products-PascalVOC-exportに入っている、
Annotations
JPEGImages
ImageSets
pascal_label_map.pbtxt
を、d:\product_ai\VOCDevkit\VOC2007 へコピーする。
いよいよ次にトレーニングを行います。いったん図に戻り、全体プロセスのチェックをして下さい。
第三章 トレーニングと判定

第8節 トレーニングの準備
1)トレーニングファイルの作成
①コマンドプロンプトでactivate tf160を実行して仮想環境を立ち上げる。既に立ち上がっている場合はそのセッションを利用してOK
①次のコマンドを実行。
python make_train_files.py※もしpansdasが無いというエラーが出たらpip install pandasを実行のこと。
※このスクリプトは書き出された学習用のアノテーションファイルをそれぞれ、train.txtとval.txtにまとめてval.txtの中身をシャッフルして、3割ほどtest.txtに移動させて保存しています。こちらの作者のオリジナルプログラムです。
②d:\product_ai\VOCDevkit\VOC2007\ImageSets\Main にラベルごとに下記ファイルが作成されたことを作成日時によって確認する。
~val.txt
~test.txt
2)yolo学習用にアノテーションを変換
①voc_annotation.pyを編集してラベルclassesを今回のタグに変更して保存する。今回の判定対象はhsrとkrなので下記のようになる。対象を増やした場合は都度追加する。
classes = ["hsr","kr"]
②tf160の仮想環境から次のコマンドを実行。
python voc_annotation.py
③d:\product_ai\model_data\の下に下記ファイルが作成される。
2007_trest.txt
2007_train.txt
2007_val.txt
④voc_classes.txtに今回のタグが書き込まれていることをチェックする。
hsr, kr
10)重みをダウンロード(初回のみ)
ブラウザで次のファイルを開くとダウンロードが開始される。完了したら、d:\product_ai\ に保存する。https://pjreddie.com/media/files/yolov3.weights
11)重みの変換(初回のみ)
tf160の仮想環境から次のコマンドを実行。数分掛かります。weightsの変換が必要なのはもとのYOLOのweightsがKeras用ではないからだと思います。未確認ですがこのページにある他のweightsを使えばベースとなるモデルを変えて移転学習ができると思います。 ※今回はYOLOv3-608を使用しています。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
12)h5ファイルの生成をチェック(初回のみ)
d:\product_ai\model_data\yolo_weights.h5 が出来たことをチェックして下さい。
第9節 トレーニングの実行
0)train.pyをトレーニング履歴の書き出しバージョンに差し替え
train_wh.py , write_hist.py をダウンロードして product_ai に保存して下さい。そして、product_ai の元々の train.py を train_org.py に名称変更したあとに、ダウンロードした train_wh.py を train.py に名称変更して下さい。
1)パラメータ調整
Atom Editorでtrain.pyを開きます。トレーニングの前に3つのパラメータを調整します。同じパラメータが複数ある場合は全て同じ数値に合わせて下さい。
input_shape = (128,128) # multiple of 32, hw
batch_size = 8
epochs=25
①input_shape :アノテーションした画像サイズに応じて変更して下さい。32の倍数で指定します。今回はresize_images.pyで指定した128にします。
②batch_size :32,16,8,4,2で指定して下さい。小さいほど処理は速く済みます。
③epochs:処理回数です。
変更したらCTRL + S で保存して下さい。
2)train.pyの実行
①tf160の仮想環境から次のコマンドを実行。
python train.py②次のような画面になってトレーニング処理が走ります。画像の数、解像度、PCのスペックによって数分~数日かかります。グラフィックボードを搭載したPCのGPUを使うことが出来ると数分~数十分のレベルになるそうです。終了するまで決してPCの電源を切らずに待っていて下さい。なお私の環境で今回のデータは30分程度の学習時間でした。もし、途中で明らかに処理が止まっているように見えたら、CTRL + C を押してジョブをキャンセルして下さい。再実行するとすんなり通る可能性があります。
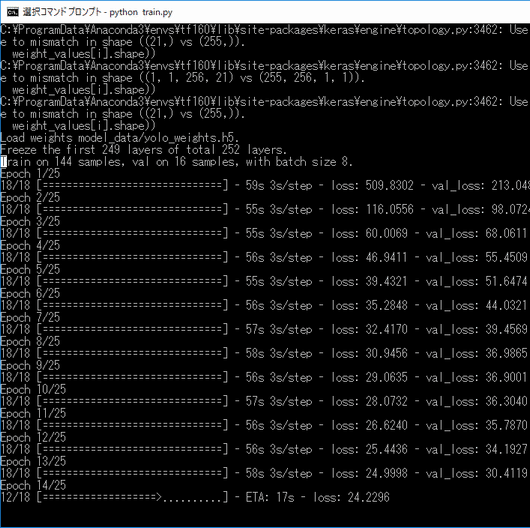
3)パラメータ履歴を取る
train.py で指定したパラメータがどうだったか、作成されたモデルでの検知の結果がどのようだったかをメモしておくことで適切なパラメータ・チューニングの手助けになります。手書きは億劫なので自動出力の仕組みを作りました。「結果の分析とフィードバック」をご参照下さい。
第10節 物体検出の実行
1)静止画を判定させたい場合
①tf160の仮想環境から次のコマンドを実行。
python yolo_video.py --image②input file nameと聞いてくるので、同じディレクトリにある判定対象のイメージファイル名を指定します。
③判定結果を枠を付けてイメージ表示してくれます。
2)動画を判定させたい場合
①こちらからサンプルをダウンロードして、d:\product_ai の直下に配置して下さい。
②次のコマンドを実行します。--input の後に動画ファイル名を指定します。※筆者の環境では、cv2のimportでエラーと出ました。仮想環境でpip install opencv-python を実行して解消しました。
python yolo_video.py --input 005.mp4 >> result.txt第11節 結果の分析
1)トレーニングの実行ログをCSVで書き出し
トレーニングの開始時刻、終了時刻やパラメータをメモする機能を作成しています。train_wh.py を使ってトレーニングを実行すると, write_hist.py が動いて, train_hist.csv が書き出される仕組みです。
2)検出結果の座標と確率を書き出し
判定の実行コマンドで末尾に >> result.txt と指定しています。これは実行ログをresult.txtファイルに追記するという指定です。分析に使うには加工が必要です。無いよりはマシといったところです。綺麗なデータの形で書き出すのはハードルが高そうですが、どなたかのトライをお願いしたいです。
3)分析サンプル・イメージ
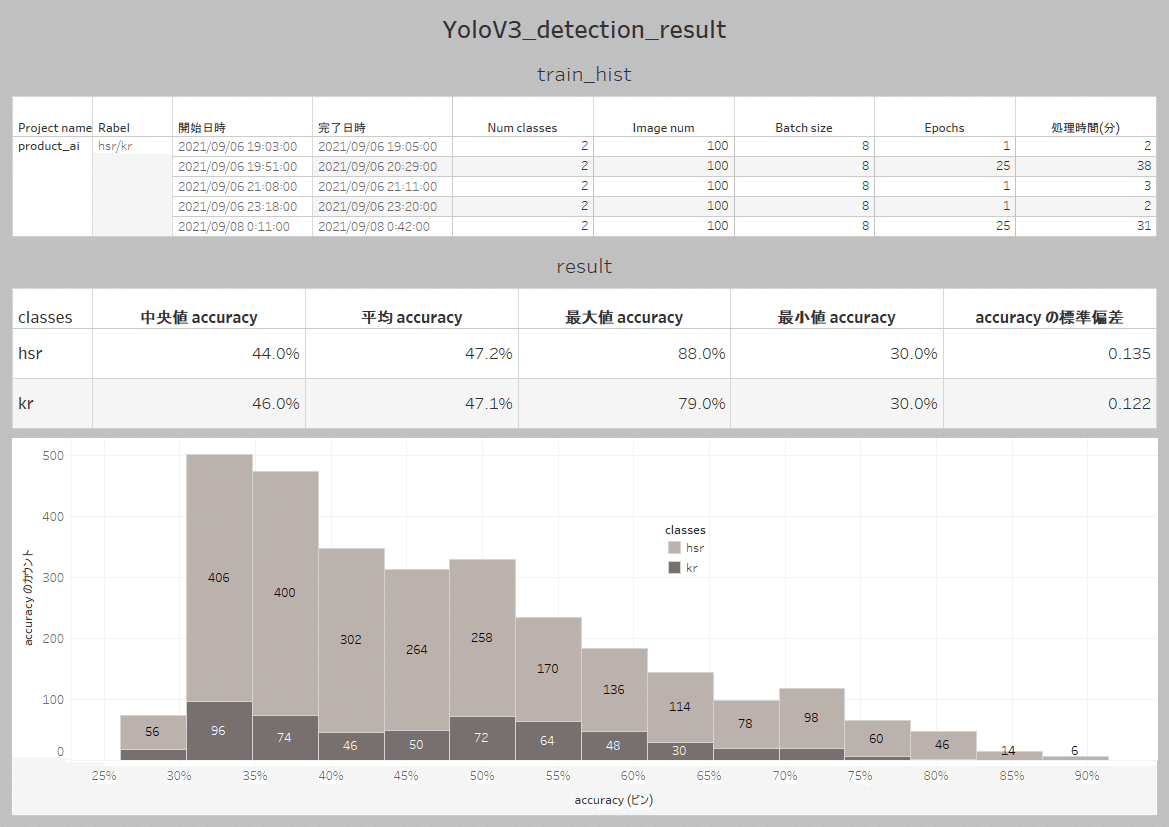
Tableauでダッシュボード化したサンプル画像を貼り付けます。ご参照下さい。ヒストグラムを見ながら、検出枠の出力条件などを変えて実用性を高めるチューニングが考えられます。理想的には、パラメータ設定等と結果の確率とがデータでつながり因果関係を自動的にチェックできる仕組みがあるとベストです。誰か機能追加をお願いします。
用語集

CNN
パーセプトロン
活性化関数
Batch Size
ニューラルネットワークの学習は、重みパラメータを、少しずつ増やしたり・減らしたりして最適な値に収束させるので、ある程度の回数を繰り返さないといけませんから、この学習データの件数分の学習を1回として、それを何回か繰り返すことになります。
学習(Training)データを1,500件ある場合を仮定すると、そのさいにニューラルネットワークの学習では、この1,500件を単純に順番に処理して1回の学習にするといった方法ではなく、もう少し少ない単位(例えば100件分とか)を1回の学習単位にします。仮にそれを100件とした場合、学習時には1,500件の中から100件のデータをランダムに選び出して学習をします。そしてそれが終わったら、またランダムに100件を選び出して、また学習する。そんな感じで繰り返していくのです。 このやり方のことを「ミニバッチ法」といいます。この「1回に処理する件数=ランダムに選び出す数」(上記例だと100件)を「Bach Size」(バッチサイズ)といいます。 ミニバッチ法では、こうして小さい塊で繰り返し学習処理を行い、テストデータ件数を全部カバーした段階(つまり、今回のケースなら1,500件)で、1単位の学習を終了したと考えます。
データ件数が1,500件で、「Bach Size(バッチサイズ)」が100なら、15回繰り返すと、1,500件のデータに相当する件数分処理したことになります。この1単位のことを「Epoch(エポック)」と呼びます。このサイクルを何単位まわしたかは「エポック数」といいます。参照先
Sigmoid function_
Softmax function
epochs
エポック数とは、「一つの訓練データを何回繰り返して学習させるか」の数のことです。参照先
参考文献
https://youtu.be/vRqSO6RsptU
https://pjreddie.com/darknet/yolo/
この記事が気に入ったらサポートをしてみませんか?