
深層学習(ディープラーニング):順伝搬

概要
一般的なディープラーニング(全結合)の理解を深めるための内容です。本記事では線形代数などの説明は省いて、プロセスだけに焦点を当てました。
深層学習(ディープラーニング)とは?
ディープラーニングは一言でいえば「複雑な合成関数※」です。合成関数のため数値を入れたら別の数値を返してくれるため、精度の高い数値変換器のようなものです。
(※パラメータ数は多いですが全結合の構成は非常にシンプルです。)
ディープラーニングのすごいところは予想したい現象(モデル)の特徴量を人間ではなく機械が(ほぼ)自動でしてくれるところです。この特徴のおかげで専門家でなくてもモデルが自動で特徴をとらえて最適な回答を出力してくれます。
関数・合成関数
関数とは入力した数値を処理して、処理後の数値を出力するものです。例としてf(x)=2x+1という関数に、入力x=1を入れると出力y=3を返します。

合成関数とは関数を組み合わせた(連結させた)ものであり、入力値を連続で指定した関数で処理させるようにした関数です。
例として、関数f1(x), f2(x)と合成関数g(x)はそれぞれ下記の通りとします。
f1(x) = 2x + 1
f2(x) = x^2
g(x) = f2(f1(x)) = f2(2x+1) = (2x + 1)^2
入力x=1を合成関数に入力すると、f1(x), f2(x)を経由して出力9となります。

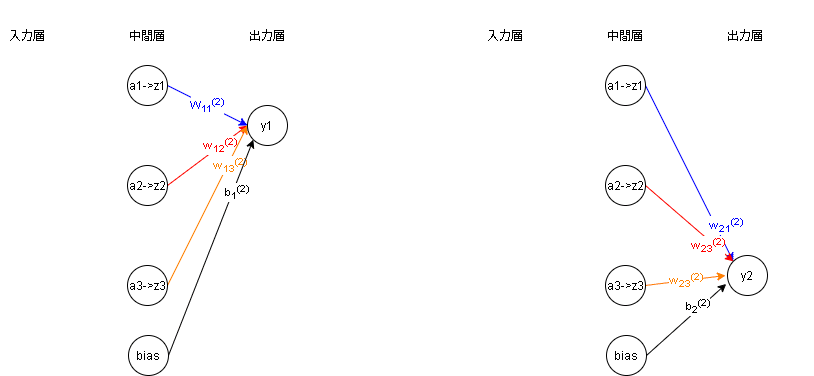
よく見るディープラーニング(全結合)図の理解
よく見る全結合の図は下記のとおりです。
※線の色は各ノードからの違いを出すだけであり各層での連動はないです。
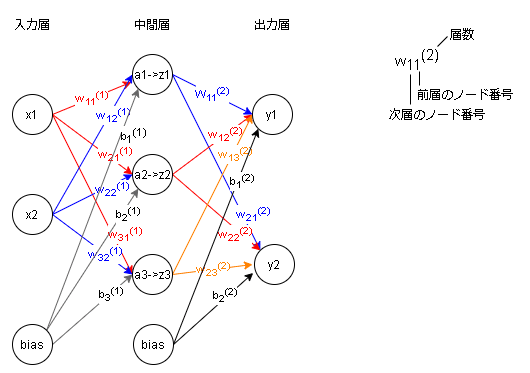
全結合の図の入力層-中間層を分解すると下図のとおりです。
各フローの計算式は下記のとおりです。(※h(x)は活性化関数を表します。)
a₁ = w₁₁¹x₁+w₁₂¹x₂+b₁¹
z₁ = h(a₁)
a₂ = w₂₁¹x₁+w₂₂¹x₂+b₂¹
z₂ = h(a₂)
a₃ = w₃₁¹x₁+w₃₂¹x₂+b₃¹
z₃ = h(a₃)
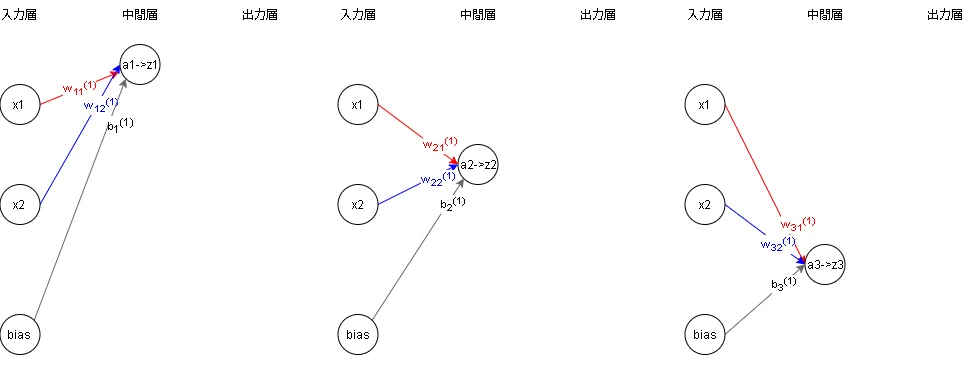
全結合の図の入力層-中間層を分解すると下図のとおりです。
各フローの計算式は下記のとおりです。
y₁ = w₁₁²z₁+w₁₂²z₂+w₁₃²z₃+b₁²
y₂ = w₂₁²z₁+w₂₂²z₂+w₂₃²z₃+b₂²
フローを見てわかる通り、重みwの掛け算、バイアスbの足し算、活性化関数h(x)を通す処理を連続でしている(掛け算、足し算、活性化関数の合成関数)だけあり、非常にシンプルであることがわかります。
※逆伝搬を学ぶ上で重要な考え方です。
活性化関数(Activation Function)
活性化関数の歴史の説明は長くなるので省いて、活性化関数の効果だけ説明ます。
活性化関数とは入力値を期待される特徴をもった出力値に変換してくれる関数です。例として活性化関数で有名なシグモイド関数(1/(1+exp(-x)))は入力値を入れると0から1の間の出力を出してくれます。
活性化関数の最大の特徴は非線形変換をしてくれることでモデルの表現力が上がります(線状だけでなく曲線や階段状の線も書ける)。
->(言い換え:)活性化関数がないと各層で重みwをかけてバイアスbを足す処理を繰り返すだけであるため、非線形処理をしないと層を深くしても動きのある線はかけない。
a₁ = w₁₁¹x₁+w₁₂¹x₂+b₁¹
a₂ = w₂₁¹x₁+w₂₂¹x₂+b₂¹
a₃ = w₃₁¹x₁+w₃₂¹x₂+b₃¹
y₁= w₁₁²a₁+w₁₂²a₂+w₁₃²a₃+b₁² =w₁₁²(w₁₁¹x₁+w₁₂¹x₂+b₁¹)+w₁₂²(w₂₁¹x₁+w₂₂¹x₂+b₂¹)+w₁₃²(w₃₁¹x₁+w₃₂¹x₂+b₃¹)+b₁²
= c₁x₁+c₂x₂+(w₁₁²b₁¹+w₁₂²b₂¹+w₁₃²+b₃¹)+b₁²
(c₁=w₁₁²w₁₁¹+w₁₂²w₂₁¹+w₁₃²w₃₁¹、c₂=w₁₁²w₁₂¹+w₁₂²w₂₂¹+w₁₃²w₃₂¹)※重みwは定数項のため、線形だとひとまとめにできる=層を深くしても一つの重みを最適化しているのと同等の処理しかできない。
あとがき
とりあえず逆伝搬を書きたいために順伝搬はさわりの部分だけ書いてみましたが、必要な部分は適宜追記かな・・・・・・
この記事が気に入ったらサポートをしてみませんか?