
Pythonライブラリ(pickleファイル):joblib

1.概要
pythonモジュールをpickleファイル化するモジュールにjoblibがあります。用途として学習したAIモデルをどこでも使用することが可能になります。
pip install joblib2.サンプルAI学習モデルの作成
今回は|Iris⦅アヤメ⦆の判別モデルを作成してみます。
今回はPickleファイル作成が目的のため機械学習は最短コードで作成しました(交差検証やハイパラ調整も無し)。
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.svm import SVC
iris = datasets.load_iris() #Irisデータセット
datas, labels = iris.data, iris.target #データとラベルを取得
df_datas = pd.DataFrame(datas, columns=iris.feature_names) #データフレーム
svm = SVC() #svmモデル作成
svm.fit(datas, labels) #モデルの学習
accuracy = (svm.predict(datas) == labels).sum()/len(df_datas) #予測結果とラベルを比較
print('正解率:', accuracy) #正解率を表示[Out]
正解率: 0.97333333333333343.Pickleファイルの作成:joblib.dump()
作成モデルのPickle化はjoblib.dump(学習モデル, 'file.pkl')で作成可能です。
[In]
import joblib
joblib.dump(svm, 'svm_noteKIYO.pkl') #モデルを保存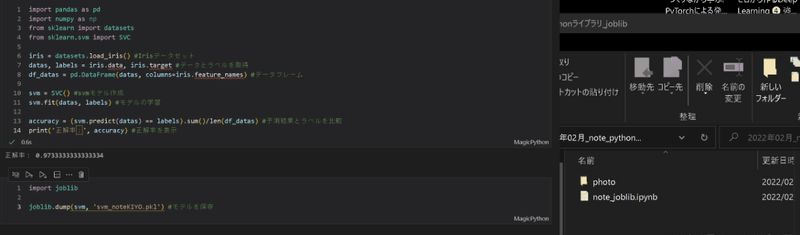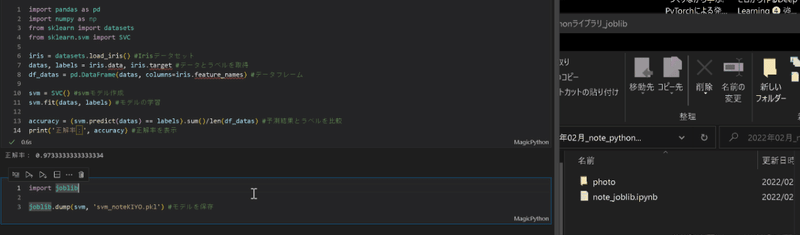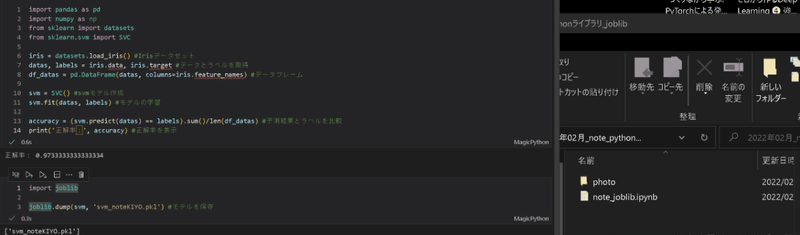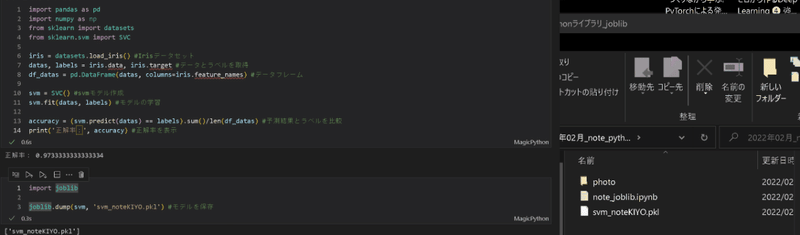
4.Pickleファイルの読み込み:joblib.load()
上記で作成したモデルを読み込むには model = joblib.load('picklefile.pkl')とすれば学習無しで作成したAIモデルと同じ結果が得られます。
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
import joblib
iris = datasets.load_iris() #Irisデータセット
datas, labels = iris.data, iris.target #データとラベルを取得
svm_load = joblib.load('svm_noteKIYO.pkl') #モデルを読み込み
t_predicted = svm_load.predict(datas) #モデルを使って予測
accuracy = (t_predicted == labels).sum()/len(datas) #予測結果とラベルを比較
print('正解率:', accuracy) #同じ正解率を確認
[Out]
正解率: 0.97333333333333345.AIモデル転用時の注意点
自分の備忘録も含めて注意点は下記の通りです。
【Pickleモデル使用時の注意点】
●AIモデルに入れるデータのデータ型、形状は学習時に合わせる必要がある。
●Pickle化するとすぐに中身を忘れるので何か工夫が必要。
6.参考:PandasでPickleファイル作成
PickleファイルはPandasでも作成できます。注意点としてPandasで作成したPickleファイルはjoblibでは使用できないため作成時のライブラリで読み込む必要があります(逆も同じ)。
6-1.ファイル作成:pd.to_pickle(model,path)
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.svm import SVC
iris = datasets.load_iris() #Irisデータセット
datas, labels = iris.data, iris.target #データとラベルを取得
df_datas = pd.DataFrame(datas, columns=iris.feature_names) #データフレーム
svm = SVC() #svmモデル作成
svm.fit(datas, labels) #モデルの学習
pd.to_pickle(svm, 'svm_note_pd.pkl') #pandasでpickle化
[Out]
svm_note_pd.pklが作成される。
6-2.ファイル読み込み:pd.read_pickle(path)
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
iris = datasets.load_iris() #Irisデータセット
datas, labels = iris.data, iris.target #データとラベルを取得
svm_load = pd.read_pickle('svm_note_pd.pkl') #モデルを読み込み
t_predicted = svm_load.predict(datas) #モデルを使って予測
accuracy = (t_predicted == labels).sum()/len(datas) #予測結果とラベルを比較
print('正解率:', accuracy) #同じ正解率を確認
[Out]
正解率: 0.97347.参考2:モデル保存の推奨方法
ライブラリによっては保存方法の推奨が異なるため保存時は公式ドキュメントをご確認ください。
参考としてXGBoostを事例を下記に示します。XGBoostではVersionの変更に合わせてPickleからJsonでのモデル保存を推奨しています。
(参考までに下記対応はxgboostのversionを1.4.0にダウングレード)
8.参考3:並列処理
2023年1月追記:JoblibはPickleファイルを作成するためのライブラリとしかイメージが無かったのですが、並列処理なども実装できるとのことです。取り急ぎ記事だけ追加しておきました。
あとがき
昔作成したモデルはなぜかPandasでPickleファイルを作成したんだけど何でだったか思い出せない・・・・・・
あとPickle形式ではなくHDF形式で保存できるh5pyというものがあるらしい。また時間のある時に勉強したい。
この記事が気に入ったらサポートをしてみませんか?