
Pythonライブラリ(可視化):WordCloud

1.概要
WordCloudはテキストの頻度から文字サイズを可視化してくれるライブラリです。特別業務に使えないと思いますが、テキスト内でよく出る文字を可視化できるのでプレイベートでは遊べます。
1ー1.サンプルテキスト作成
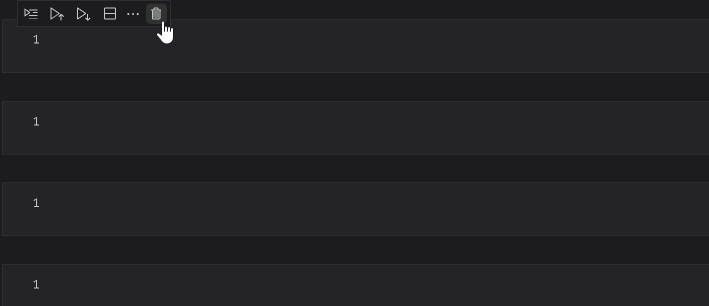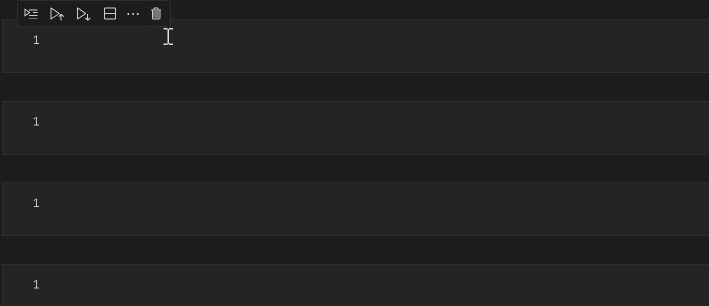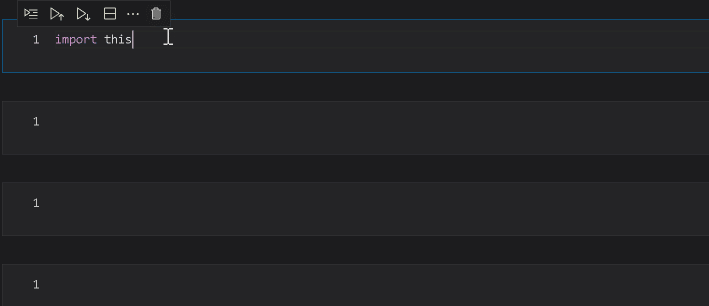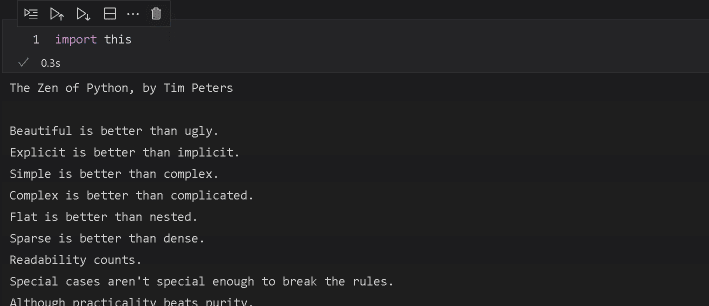
まずサンプルテキストして「The Zen of Python」を使用します。Jupyterなら「import this」と打ち込めば出力されるのでコピペして変数textとしました。
[In]※
text = """
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""参考までに各単語がどのくらいの頻度で出現しているかは下記の通りです。
[In]
import pandas as pd
text = text.replace('\n',' ') #改行をスペースに置換
words = text.split(' ') #スペースを区切り文字として分割
words = [word for word in words if len(word)>0] #不要な空文字を削除
# 単語と出現回数の辞書を作成
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
sorted_wordcount = sorted(word_count.items(), key=lambda x:x[1], reverse=True) #辞書を値でソート
pd.DataFrame(sorted_wordcount, columns=['word', 'count']).head(20) #20個の最も出現回数の高い単語を表示
2.シンプルな操作
2-1.シンプル表示: WordCloud().generate(text)
textの可視化には" WordCloud().generate(<text>)"を使用します。
[In]
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud().generate(text)
plt.figure(figsize=(12,12))
plt.imshow(wordcloud)
plt.axis('off') #軸の表示を消す
plt.show()
背景色やバランスを変更する時の引数は下記の通りです。
[In]
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(width=1200, height=720, background_color='white').generate(text)
plt.figure(figsize=(12,12))
plt.imshow(wordcloud)
plt.axis('off') #軸の表示を消す
plt.show()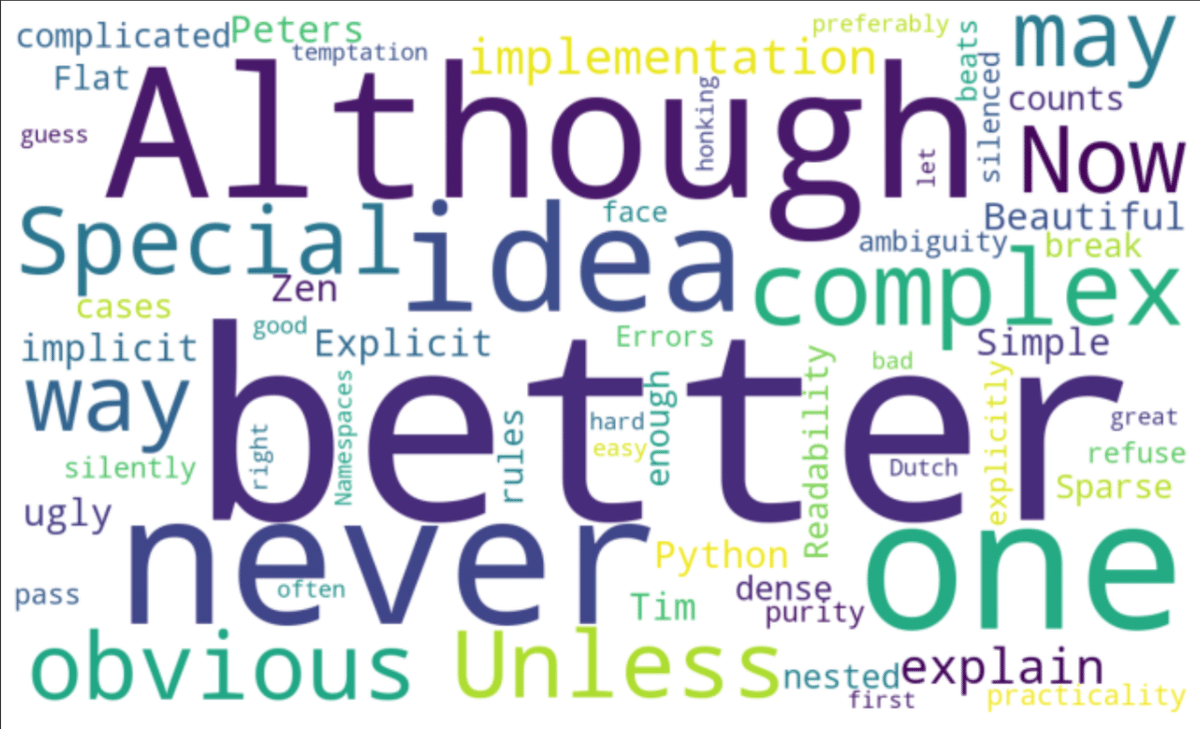
3.WordCloudの基本操作
上記ではシンプルな使用方法を説明したので本章は基本操作を紹介します。
3-1.WordCloud オブジェクトの初期化
WordCloudではオブジェクトを事前に作成して、そのオブジェクトに処理したいデータを渡して可視化します。引数の一部は下記の通りです。
width: 生成される画像の幅をピクセル単位で指定(default: 400)
height: 生成される画像の高さをピクセル単位で指定(default: 200)
background_color: 画像の背景色を指定します(default:'black')
max_words: 画像に表示する単語の最大数を指定します(default: 200)
stopwords: WordCloudに表示させない単語のリスト
font_path: 使用するフォントへのパスを指定。このパスはOTFまたはTTFフォントへのものである必要があります。
colormap:画像の色をMatplotlib colormapで指定
prefer_horizontal: 単語がフィットしない場合に単語を回転させてフィットさせるかどうかを制御。値が1未満の場合、アルゴリズムは単語がフィットしない場合に単語を回転させようと試みます。
mask: ワードクラウドの描画領域を制御するバイナリマスクを指定。指定するとwidthとheightは無視され、マスクの形が使用されます。
contour_width, contour_color: マスクが指定されcontour_widthが0より大きい場合マスクの輪郭を描画。contour_colorで輪郭の色を指定できます。
scale: 計算と描画の間のスケーリングを制御。大きなワードクラウド画像に対して、大きなキャンバスサイズを使用する代わりにscaleを使用すると計算が大幅に高速になりますが単語のフィットが粗くなる可能性があります。
min_font_size: 使用可能な最小のフォントサイズを指定
font_step: フォントのステップサイズを指定
max_font_size: 最大の単語に対する最大のフォントサイズを指定
mode: "RGBA"と設定しbackground_colorをNoneに設定すると背景が透明になる画像が生成
[IN]
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(width=800,
height=400,
max_words=100,
background_color='black')
print(wordcloud)
[OUT]
<wordcloud.wordcloud.WordCloud object at 0x000002938E40C190>3-1ー1.日本語表示:font_path
日本語をそのまま扱うと下記の通り豆腐が出ます。

日本語を扱う場合はWordCloudの引数にfont_path='フォントファイル'を選択します。今回は下記URLを参考にしてWIndowsに初期であるMeiryo.ttcファイルを使用しました。
[In]
text_JP = """
醜いより美しい方がいい。
Explicit is better than implicit.
Simple is better than complex.
Complex は complicated よりも良い。
Flat is better than nested.
Sparse is better than dense.
読みやすさは重要である。
特殊なケースは、ルールを破るほど特殊ではない。
実用性は純粋さに勝るが。
エラーは黙っていてはいけない。
明示的に黙らせない限り。
曖昧さに直面しても、推測の誘惑に負けてはいけません。
それを行うための明白な方法は1つ、できれば1つだけであるべきです。
その方法は、あなたがオランダ人でない限り、最初は明らかではないかもしれませんが。
今は絶対よりも良い。
ただし、「今」よりも「絶対」の方が良い場合もあります。
実装の説明が難しければ、それは悪いアイデアだ。
もし実装が説明しやすければ、それは良いアイデアかもしれません。
名前空間は非常に素晴らしいアイデアのひとつです。
"""
wordcloud_JP = WordCloud(width=1200, height=720, background_color='white', font_path='meiryo.ttc').generate(text_JP)
plt.figure(figsize=(12,12))
plt.imshow(wordcloud_JP)
plt.axis('off') #軸の表示を消す
plt.show()
font_pathの設定で日本語が表示されましたが上記の通り日本語は単語ごとにスペースで区切られていないためサイズ感が出ておりません。また助詞などの不要な品詞も含まれます。綺麗に表示するには形態素解析が必要です。
3-2.テキスト生成
作成したWordCloudオブジェクトから可視化のためのテキストを作成します。作成方法は文章と辞書の2種類があります。
(もう一つgenerate_from_text()がありますが違いが不明のため未記載)
3-2-1.文章から生成:generate()
文章から生成するには"Wordcloud.generate(<text>)"を使用します。出力は画像データのためMatplotlibのimshow()などで表示可能です。
注意点として英文のように半角で区切られている文章はよいですが、日本語のように半角区切りが無い場合は英語と同様の形で半角に区切った文章を用意する必要があります。
[IN]
text = 'I have a pen, I have an apple'
Wcloud_text = wordcloud.generate(text) #textから生成
print(Wcloud_text)
plt.imshow(Wcloud_text)
plt.axis('off') #軸の表示を消す
plt.show()
[OUT]
<wordcloud.wordcloud.WordCloud object at 0x0000029385B528B0>
3-2-2.辞書型から生成:generate_from_frequencies()
文章ではなく辞書型{<単語名>:<数量>}で渡す場合は"Wordcloud.generate_from_frequencies(dict)"を使用します。
[IN]
dict_text = {'cat':5, 'dog':3, 'otter':1}
Wcloud_dict = wordcloud.generate_from_frequencies(dict_text) #辞書から生成
print(Wcloud_dict)
plt.imshow(Wcloud_dict)
plt.axis('off') #軸の表示を消す
plt.show()
[OUT]
<wordcloud.wordcloud.WordCloud object at 0x0000029385B528B0>
3-3.画像の保存:wordcloud.to_file()
画像を出力するには"WordCloudオブジェクト.to_file(<保存path>)"で実行可能です。
[IN]
Wcloud_dict.to_file('sample.png')
[OUT]
画像ファイルが出力3-4.その他メソッド
上記で既にWordcloudオブジェクトの複数のメソッドを紹介しましたが、他にも使えそうなものを紹介します。
recolor([random_state, color_func, colormap]):色の変更
to_array():画像データのnumpy.array化
[IN]
dict_text = {'cat':5, 'dog':3, 'otter':1}
Wcloud_dict = wordcloud_recolor.generate_from_frequencies(dict_text) #辞書から生成
plt.imshow(Wcloud_dict.recolor(colormap='prism', random_state=123))
plt.axis('off') #軸の表示を消す
plt.show()
[OUT]
4.形態素解析(Janome)
形態素解析は文字列を解析して意味のある単語ごとに分割してくれます。今回形態素解析ライブラリとしてJanomeを使用しました。
[In]
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text_JP)
for token in tokens:
print(token.surface)
print(token.part_of_speech)[Out]
醜い
形容詞,自立,*,*
より
助詞,格助詞,一般,*
美しい
形容詞,自立,*,*
方
名詞,非自立,一般,*
が
助詞,格助詞,一般,*
いい
形容詞,自立,*,*
。
記号,句点,*,*
記号,空白,*,*
明示
名詞,サ変接続,*,*
的token.surfaceで分割した単語、token.part_of_speechで単語情報を取得できます。これを利用して指定の品詞のみ取得して表示させます。
[In]
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text_JP)
text_tokenized = ''
for token in tokens:
wordclass = token.part_of_speech.split(',')[0] #品詞を取得
if wordclass =='名詞' or wordclass =='動詞' or wordclass =='形容詞' or wordclass=='副詞':
text_tokenized += token.surface + ' '
text_tokenized [Out]
'醜い 美しい 方 いい 明示 的 暗黙 的 良い 単純 方 複雑 良い 複雑 複雑 良い フラット
ネスト 良い スパース デンス 良い 読み やす さ 重要 特殊 ケース ルール 破る 特殊 実用
性 純粋 さ 勝る エラー 黙っ い いけ 明示 的 黙ら せ 限り 曖昧 さ 直面 し 推測 誘惑 負け
いけ それ 行う ため 明白 方法 1 できれ 1 方法 あなた オランダ 人 限り 最初 明らか しれ
今 絶対 良い 今 絶対 方 良い 場合 あり 実装 説明 難しけれ それ 悪い アイデア もし 実装
説明 し やすけれ それ 良い アイデア しれ 名前 空間 非常 素晴らしい アイデア ひとつ ' これを可視化すると下記の通りです。

5.WordCloudで可視化してみた
5-1.Twitterのつぶやきを可視化
5ー1-1.ツイートの可視化(前処理前)
遊びでツイートを可視化してみました。下記記事「7.Keyword検索:api.search()」からキーワード「コロナ」で検索しました。
上記を応用してサクッと作成しました。
[In]
import matplotlib.pyplot as plt
import pandas as pd
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
filepath = "211117_twitter-api_コロナ.xlsx"
df = pd.read_excel(filepath)
df_tweets = df.loc[:, ['ツイート本文']]
text_tweet = ''
# ツイート本文を結合
for tweets in df_tweets['ツイート本文']:
text_tweet += tweets
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text_tweet)
text_tweet_tokenized = ''
for token in tokens:
wordclass = token.part_of_speech.split(',')[0] #品詞を取得
if wordclass =='名詞' or wordclass =='動詞' or wordclass =='形容詞' or wordclass=='副詞':
text_tweet_tokenized += token.surface + ' '
wordcloud = WordCloud(background_color="white", width=800, height=600, font_path='meiryo.ttc').generate(text_tweet)
plt.figure(figsize=(10,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
結果として余計な文字が多いことがわかります。これはURLが形態素解析され意味不明の文字が発生しているためです。
5ー1-2.ツイートの可視化(前処理込み)
余計そうな単語を事前にテキストから抜いて再表示して色もちょっと変えてみましたcolormapは下記参照しました。
[In]
import matplotlib.pyplot as plt
import pandas as pd
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
filepath = "211117_twitter-api_コロナ.xlsx"
df = pd.read_excel(filepath)
df_tweets = df.loc[:, ['ツイート本文']]
text_tweet = ''
# ツイート本文を結合
for tweets in df_tweets['ツイート本文']:
text_tweet += tweets
import re
removewords = ['\n', 'https://', '\u3000', 't.co', 'co'] #除外する単語
for removeword in removewords:
text_tweet = re.sub(removeword, '', text_tweet)
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text_tweet)
text_tweet_tokenized = ''
for token in tokens:
wordclass = token.part_of_speech.split(',')[0] #品詞を取得
if wordclass =='名詞' or wordclass =='動詞' or wordclass =='形容詞' or wordclass=='副詞':
text_tweet_tokenized += token.surface + ' '
wordcloud = WordCloud(width=800, height=600, font_path='meiryo.ttc', colormap='prism').generate(text_tweet)
plt.figure(figsize=(12,12))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
「コロナ」検索でワクチンとかよりも怪しい広告や出会い系っぽいのが見えますね。
5-2.内閣総理大臣所信表明演説のワード分析
第二百十回国会における岸田内閣総理大臣所信表明演説を取得します。
5-2-1.スクレイピングでテキストデータ取得
下記手順でテキストデータを取得しました。
Beautiful Soup×RequestsでホームページのHTMLデータ取得
"soup.prettify()"でHTML構造を確認・理解して必要な要素を取得
不要な情報を削除(いらない文字とカッコ付き文字を削除
取得した要素のテキストデータを文字列として結合
[IN]
import gensim
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import requests
from bs4 import BeautifulSoup
url = 'https://www.kantei.go.jp/jp/101_kishida/statement/2022/1003shoshinhyomei.html' #第二百十回国会における岸田内閣総理大臣所信表明演説
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
# print(soup.prettify()) #HTMLを整形して表示
elem_block = soup.select_one('.block-center') #class名がblock-centerの要素を取得※1つ
elem_ptags = elem_block.select('p') #pタグを取得 ※複数
words_remove = ['動画が再生できない方はこちら(政府インターネットTV)',
'動画ファイルはこちら']
text = ''
for idx, elem_ptag in enumerate(elem_ptags):
#不要な文字列を削除※空白文字はsplit()で除外
if elem_ptag.text.strip() in words_remove:
continue
#()内の文字列を削除
if elem_ptag.text.startswith('('):
continue
text += elem_ptag.text
print(text[:100]) #先頭100文字を表示
[OUT]
第二百十回国会の開会に臨み、日本を守り、未来を切り拓(ひら)く覚悟を新たにしています。
足下の物価高への対応に全力をもって当たり、日本経済を必ず再生させます。多層的な外交の展開と防衛力の抜本的5-2ー2.可視化:形態素解析(前処理)なし
取得したテキストデータを可視化しました。
[IN]
def ShowWordCloud(text, width, height):
img = WordCloud(width=width, height=height, font_path='meiryo.ttc', colormap='prism').generate(text)
plt.figure(figsize=(12,12))
plt.imshow(img)
plt.axis("off")
plt.show()
ShowWordCloud(text, width=800, height=600)
[OUT]
5-2ー3.可視化:形態素解析(前処理)あり
Janomeで欲しい品詞(名詞・動詞・形容詞・副詞)だけ抽出します。また今回1文字の単語も出てきたためそちらは除外するようにしました。
注意点として「WordCloudに渡すテキストは品詞間に半角スペースを追加」します。
今回は2パターンのコードを作成しましたが出力結果は同じです。
[IN ※パターン1]
from janome.tokenizer import Tokenizer
import re
def parse_text(text):
t = Tokenizer()
tokens = t.tokenize(text) #形態素解析 text_tweet_tokenized = ''
for token in tokens:
wordclass = token.part_of_speech.split(',')[0] #品詞を取得
if wordclass =='名詞' or wordclass =='動詞' or wordclass =='形容詞' or wordclass=='副詞':
if len(token.surface) > 1: #1文字の単語は除外
text_tweet_tokenized += token.surface + ' '
return text_tweet_tokenized
text_prec = parse_text(text)
print(type(text_prec), len(text_prec), text_prec[:50])
ShowWordCloud(text_prec , width=800, height=600)
[OUT]
<class 'str'> 6689 国会 開会 臨み 日本 守り 未来 切り 覚悟 新た 足下 物価高 対応 全力 もっ 当たり 日本 [IN ※パターン2]
def parse_text2(text):
t = Tokenizer()
tokens = t.tokenize(text) #形態素解析
output = [token.surface for token in tokens if token.part_of_speech.split(',')[0] in ['名詞', '動詞', '形容詞', '副詞']]
output = [word for word in output if len(word) > 1] #1文字の単語は除外
return " ".join(output) #単語間を半角スペースで連結
ShowWordCloud(parse_text2(text) , width=800, height=600)
参考資料
あとがき
業務には1mmも活用できていないけどおじさんのメールの特徴なんかを抽出すると面白いかもね。
それにしてもgifの調子が悪い気がする・・・・
この記事が気に入ったらサポートをしてみませんか?