
【実習編】非専門家のためのQGIS ~山の分布図を描こう~

I. はじめに
国土地理院は、日本の代表的な山「1003山」の情報をウェブサイトで公開しています。この情報には座標値も掲載されているので、これを使って山の位置を地図上に描くことができそうです。
今回は、日本の山の分布図を作成してみましょう。
II. データの準備
1. 表データのコピー
下記のリンクより、国土地理院のウェブサイト「日本の主な山岳一覧」にアクセスします。ここに掲載されている表のデータをコピーし、Excelに貼り付けましょう。このとき、表の形式を保ったまま貼り付けるとセルが結合され後の処理が大変なので、「形式を選択して貼り付け」→「テキスト」と操作し、テキストとして貼り付けします(※1)。
※1 一旦メモ帳に貼り付け、それを再度コピーしてExcelに貼り付けてもテキストとして貼り付けることができます。
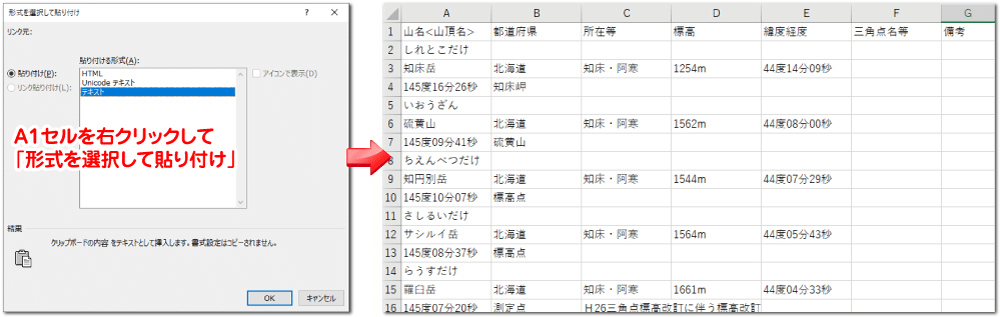
--- --- --- --- --- --- --- ---
2. 貼り付けた情報の成形
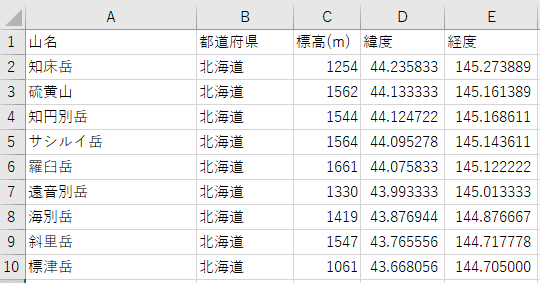
テキストとして貼り付けたことで、ウェブサイトでは1つの山につき1行にまとまっていた情報が、Excelでは3行に分割されました。1行目はルビなので不要ですが、2行目と3行目には座標値が書かれており、これは残しておきたい情報です。また、これらは1行にまとめたいところです。

3行に分かれてしまった情報を、1つの山につき1行にまとめる作業を行います。まず、新しくA列を追加します。
次に、知床岳に関する3行について、追加したA列に上から順に1、2、3の番号を振ります。この3つのみ、手入力で番号を付与します。
続いて、オートフィル機能を用いてA列の最後まで番号を自動入力します。手入力した番号に続いて4、5、6、・・・と連番で数字が入力されます。
A列の最後尾のところで、セル右下に表示されたオートフィルオプションをクリックします。オプションのウィンドウが展開されるので、ラジオボタンを「連続データ」から「セルのコピー」に変更します。すると、連番で入力されていた数値が1、2、3を繰り返すパターンに変更されます。これで、「1」の行にはルビ、「2」「3」の行には座標情報(を含む山情報)という形になりました。

[Ctrl]+[Shift]+[L]でフィルタ機能を追加し、A列のフィルタから「2」だけ表示させます。表示された情報をコピーし別のシートに貼り付けましょう。
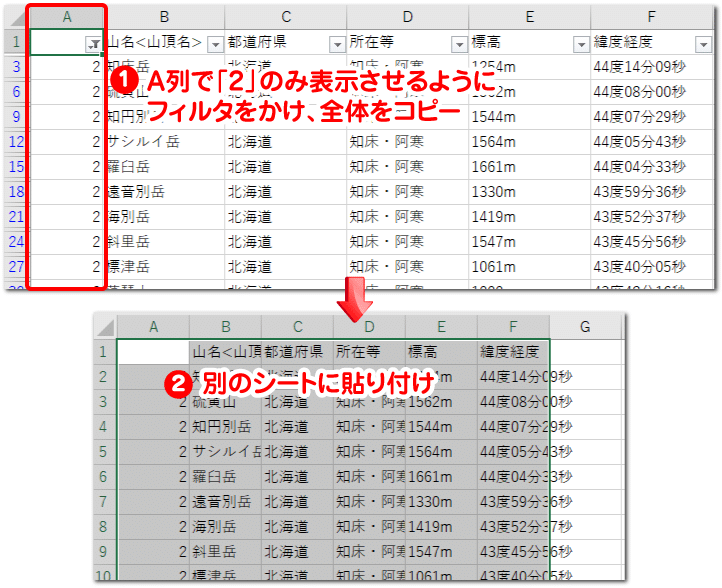
続いて、A列のフィルタから「3」のみ表示させて表示された情報をコピーし、先ほど「2」の情報を貼り付けたシートで、表の右側に続けて貼り付けます。これで、ウェブサイトからコピーした際に分かれてしまった情報を1行に戻すことができました。

ところで、代表的な1003山ということなので、行数はヘッダーを含めて1004行になるはずですが、Excelを見ると1060行もありますね。改めてリストを確認してみると、「丹沢山」と「丹沢山<蛭ヶ岳>」のように同じ山系から重複してリストに加えられているものがあるようです。本来なら、このような重複を整理したいところですが、重複かどうかを判断する根拠が無いのでこのまま次の工程に進みます(※2)。
※2 単純に重複を削除すると996個になり、今度は1003を下回ってしまいます。どのようなルールで重複を処理すれば1003山になるのか、分かりません・・・。
次に、座標値の前処理を行います。国土地理院の公開情報では座標値は度分秒(60進法)で記述されています。しかし、GISでは一般に10進法による座標値表記を用います。QGISも座標値を10進法で扱うため、60進法から10進法に変換が必要になります(※3)。
※3 実は、QGISでは60進法のままでも読み込むことができます。ただし、一般にGISの世界では、60進法から10進法への変換はユーザ側で対応することが求められます。そこで、ここではQGISの機能には頼らず、10進法に変換してからQGISに読み込むことにします。60進法のまま読み込む方法はこの記事の末尾に補足として記載しました。
ここまでをコマンドで処理するするならこんな感じでしょうか。書き捨ての作業なので、スクリプトを書くというよりは、1ライナーでゴリゴリ処理した方が良いと思います。
$ cat mountain.txt | awk 'NR % 3 == 0' > column2.txt
$ cat mountain.txt | awk 'NR >= 2' | awk 'NR % 3 == 0' > column3.txt
$ cat column2.txt | tr -d '\r' | paste - column3.txt > re_mountain.txt
# awk input.csv > out.csvとしてもよいのですが、入力ファイルと出力ファイルの指定が並ぶと見難いので、読み込みをcatで担って、それをパイプで繋げています。
# 「awk 'NR % 3 == 0'」で行数を3で割ったときに余りが0になる行を、すなわち3行おきにデータを抽出しています。
# 「awk 'NR >= 2'」で2行目以降の行を、すなわち先頭行を削除しています。これにより行数が1つ繰り上がるので、次のawkコマンドで3行おきにデータを抽出したとき、1つ目のコマンドで抽出した行の1つ下の行を対象にデータを抽出しています。
# pasteコマンドで2つのファイルを列方向に結合します。ただし、改行コードがCRLFだとうまく結合できないので、先に「tr -d '\r'」で改行コードをLFに変更しています。pasteコマンドを使うとき、パイプで渡したファイルは「-」に入ります。
--- --- --- --- --- --- --- ---
3. 座標値を数値として扱うための準備
60進数座標を10進数座標に変換したいのですが、Excelで座標値の入ったセルを見ると「44度14分09秒」のような文字列として入力されており、このままでは計算できません。なので、度分秒の値をそれぞれ別のセルに分割し、数値として入力し直します。分割方法は何通りか考えられそうです。
1. LEFT関数やMID関数、VALUE関数を用いて必要な数値を抜き出す
2. 「度」や「分」を区切り文字としてセル分割する
3. 座標値列をメモ帳などにコピーして「度」や「分」をタブやカンマに置換し、それらを再びExcelに貼り付ける
1.の方法について見てみましょう。
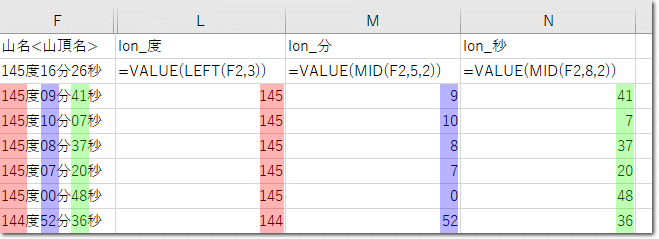
まず、緯度の列について、「度」の値を抽出します。今回は、全て左から2文字までの文字列が「度」の値であることから、「=VALUE(LEFT(E2,2))」という式で抽出できます。LEFT関数は、値が入っているセルを対象とし、左から指定した数までの文字列を抽出する関数です。また、LEFT関数は文字列型で値を返すため、VALUE関数を使って数値型に変換しています。
次に、「分」は左から4文字目を起点として2文字分取り出せばよさそうです。これを関数で指定すると「=VALUE(MID(E2,4,2))」となります。MID関数は、MID(対象セル, 開始位置, 抽出文字数)という引数を取ります。同様にして、「秒」も「=VALUE(MID(E2,7,2))」とすれば抽出できます。
それぞれの数式を、オートフィル機能を用いてコピーし、全ての行の緯度の値を抽出しましょう。

経度についても、同じ方法で度、分、秒の値を抽出しましょう。ただし、経度は「度」が3桁であることに注意しましょう。度は「=VALUE(LEFT(F2,3))」、分は「=VALUE(MID(F2,5,2))」、秒は「=VALUE(MID(F2,8,2))」のように修正し、全ての行に対してコピーします。
--- --- --- --- --- --- --- ---
4. 60進数座標を10進数座標に変換
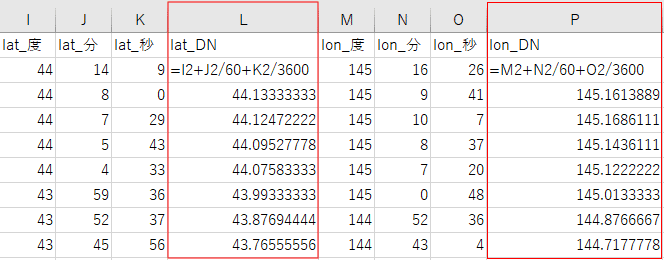
度、分、秒の数値をそれぞれセルに分けて数値として保存できたので、60進数から10進数へ変換する数式を作ります。変換式は、「度」と「分を60で割った値」と「秒を3600で割った値」を足し合わせた式になります。つまり、「=I2+J2/60+K2/3600」になります。緯度も経度も参照セルだけ変更すれば同じ数式で10進数の座標値に変換できます。
--- --- --- --- --- --- --- ---
5. QGIS用データとして整形
QGISのテーブルデータの形式に合わせるために、不要なフィールドを削除したり、フィールド名(ヘッダー名)を変更したりしましょう。最低限、10進数の緯度と経度さえあればOKです。緯度・経度は、「コピー」→「値で貼り付け」して数式から数値にしておきます。
標高について、元データはでは各セルに「1254m」のように単位の「m」が標高値と共に入力されているため、文字列として認識されています。標高値は数値とする方が扱いやすいので、「m」を置換で取り払っておきます。
座標値について、一般に小数第6位まであれば、十分な精度があると言われています。座標値のセルを選択し、「セルの書式設定」で「小数点以下の桁数」を「6」に指定しておくと、後にCSVで保存した時に小数点以下6桁までの値になります。
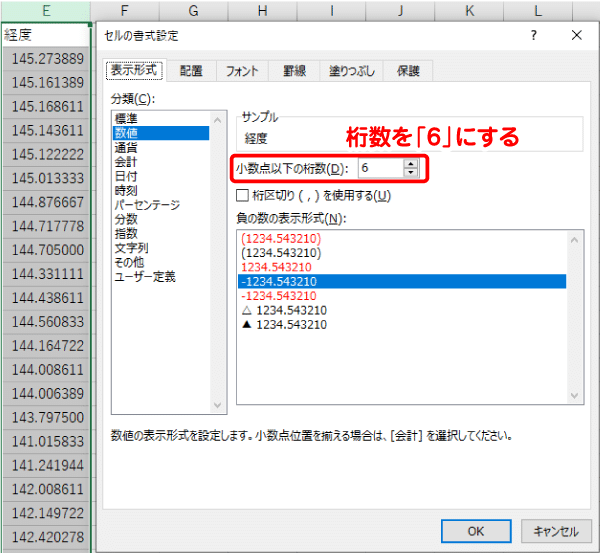
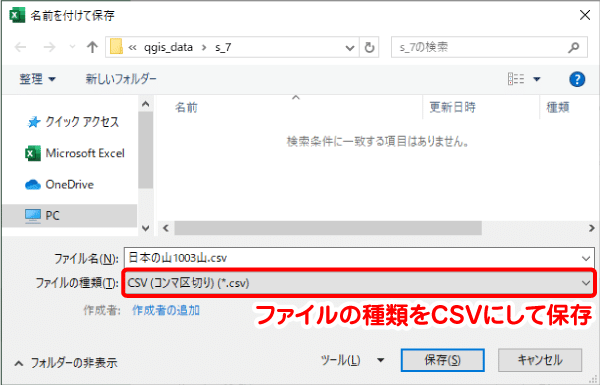
テーブルの整形が出来たら、CSVファイルとして保存します(※4)。Excel2016以降では、文字コードをUTF-8として保存することもできます。Shift-JIS、UTF-8のどちらで保存しても構いません。
※4 テーブルとしてQGISに読み込ませるだけであれば、Excelのファイル形式(.xlsx)も対応していますが、座標値を指定して読み込む場合はCSVの形式から行います。
--- --- --- --- --- --- --- ---
6. この座標値の座標系は?
長かったExcelでの前処理がようやく終わりました。これでようやく作業をQGISに移すことができますが、その前に1つ確認しておかなければならないことがあります。それは、整備した「座標値の座標系は何?」ということです。
準拠している座標系や測地系が異なると、同じ場所を示す緯度・経度の値でも座標値は異なります。QGISで正しい場所にプロットするためには、座標値をそれが準拠する測地系・座標系を正しく指定して読み込まなければなりません。
データ出所である国土地理院のウェブサイトを確認すると、山岳一覧ページの1階層上のページに次のような文章が記載されています。

国土地理院ウェブサイトより(https://www.gsi.go.jp/kihonjohochousa/kihonjohochousa41139.html)
図の赤で示した箇所より、測地系は「世界測地系」に基づくものだと予想できます。一方、座標系のことは何も書かれていないので分かりません。
とはいえ、度分秒という単位から、地理座標系であることは分かります。あとはWGS84なのかJGD2000なのか、JGD2011なのか・・・ですが、これは判断がつきません。そもそも、全ての座標値が1つの座標系で統一されているかも非常に怪しいです(※5)。
幸い、WGS84、JGD2000、JGD2011の3つの座標系において、それぞれのズレは数cm~数m程度なので、描く地図の縮尺にも依りますが、どの座標系を用いてもズレが気にならない程度には、概ね正しい地図を描くことは可能です。
※5 「最初はJGD2000で整備したけど、後で修正したものについてはJGD2011を使ったよ。その結果、JGD2000とJGD2011が混在しちゃったよ」ということが良くある・・・。
III. 日本の山の分布マップを作成
1. CSVファイルの読み込み
ここからQGISを使った作業になります。まず、QGISを立ち上げ、都道府県界データを読み込ませておきましょう。
次に、CSVを読み込みます。「メニューバー」の「レイヤ」→「レイヤの追加」→「CSVテキストレイヤの追加」からデータソースマネージャを開きます。そして、下図のように設定します。
「ジオメトリ定義」で、座標値の読み込み設定を行います。Xフィールドに経度、Yフィールドに緯度の値が入った列を指定します。ジオメトリのCRSでは座標値が準拠する座標系を指定します。上で確認したように、今回はJGD2011を設定していします。
座標系一覧からEPSGのコート番号「6668」や座標系名称「JGD2011」などのキーワードで検索し、指定しましょう。設定が完了したら、[追加]ボタンをクリックします。

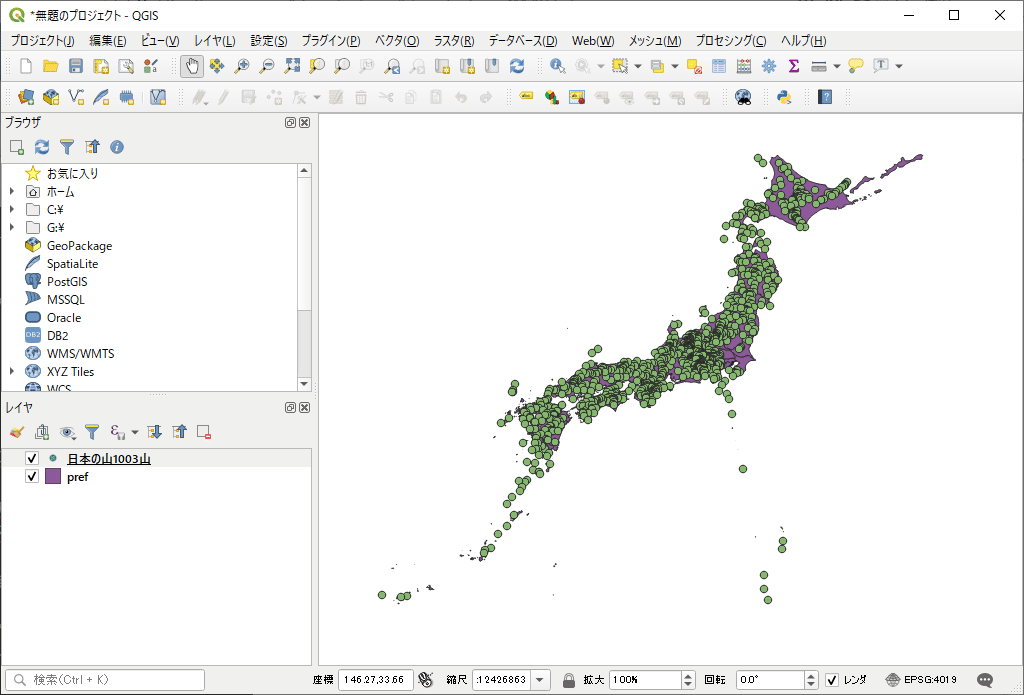
QGISに山のポイントが描画されました。追加されたレイヤを右クリックして「エクスポート」→「地物」と選択すると、シェープファイルなどのGISデータとして保存できます。
--- --- --- --- --- --- --- ---
2. 山の分布マップを作成
1000以上の山を表示させた日本全図は、ごちゃごちゃしすぎて分かりにくいですね。そこで、今回は関東地方に描画対象を絞ることにします。関東地方を拡大して表示してみましょう。
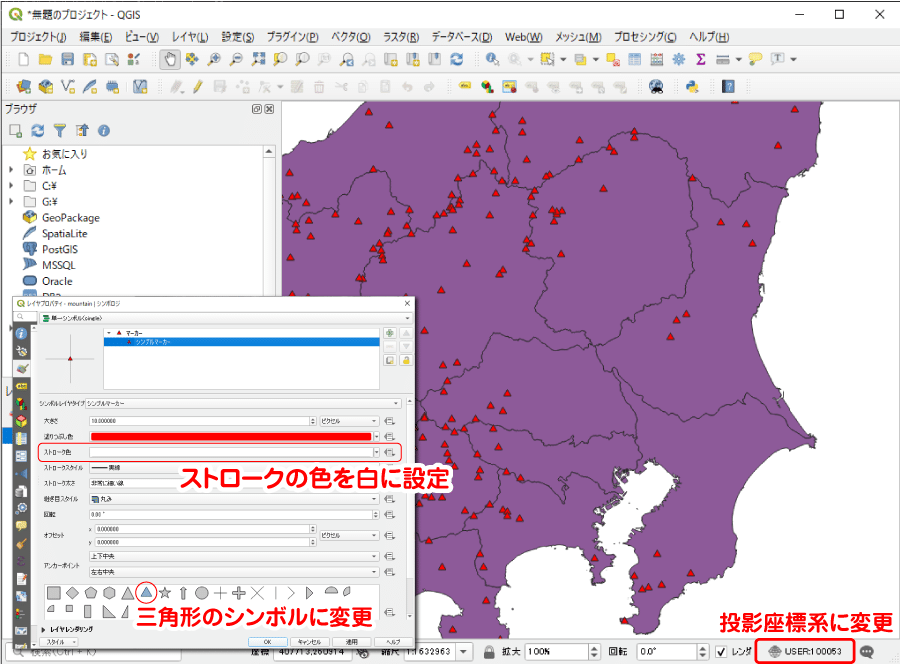
下の図は、座標系を投影座標系(ランベルト正角円錐図法)に変更し、関東地方を拡大したものです(※6)。またシンボルを三角形に変更し、山っぽくしてみました。
※6 ランベルト正角円錐図法は「【実習編】非専門家のためのQGIS ~白地図を描こう_都道府県界~」で日本を中心に描かれるように独自に定義した座標系です。既存の投影座標系で済ませたい場合は、JGD2011/UTM Zone 54N(EPSG:6691)が利用できます。UTM54系は関東から北海道にかけて描くことができる投影座標系です。
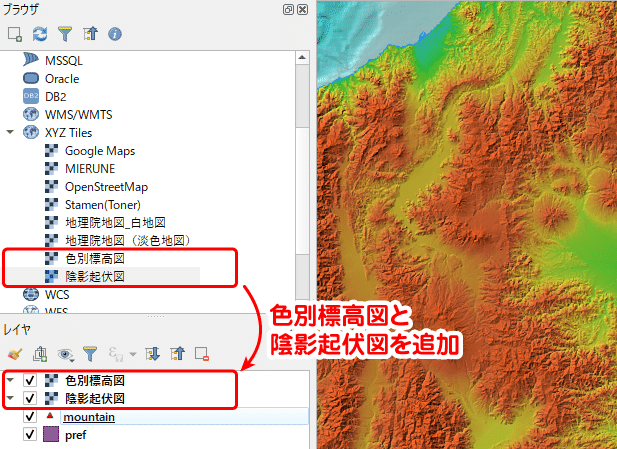
もう少しデザインを凝ってみましょう。まず、「XYZ Tiles」から国土地理院の色別標高図、陰影起伏図を追加します。XYZ Tilesの追加方法は「【実習編】非専門家のためのQGIS ~QGISのインストール~」で紹介しています。
レイヤ設定を変更しましょう。色別標高図について、「プロパティ」→「シンボロジ」を開き、彩度を「-100」にします。彩度を下げることでカラーの標高画像をグレースケールに変更しています。
陰影起伏図は、混合モードをオーバーレイにします。
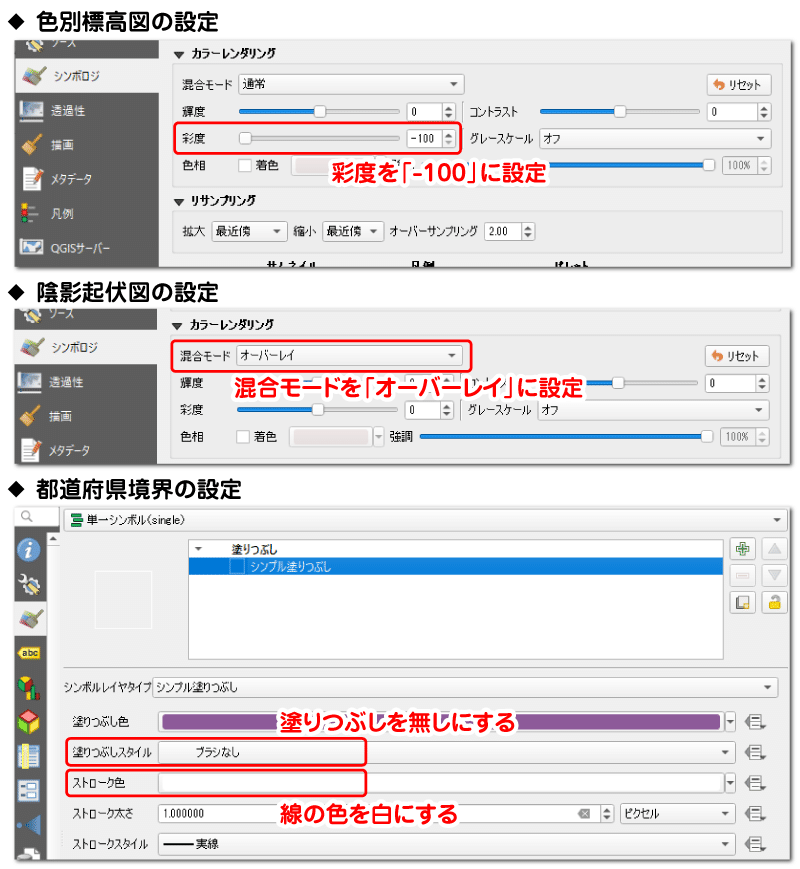
最後に、レイヤの並びを変更します。上から順に「山のポイントデータ」、「都道府県境界」、「陰影起伏図」、「色別標高図」の順にします。
陰影起伏図と色別標高図を重ね合わせることで、地形の凸凹をくっきりと描くことができます。

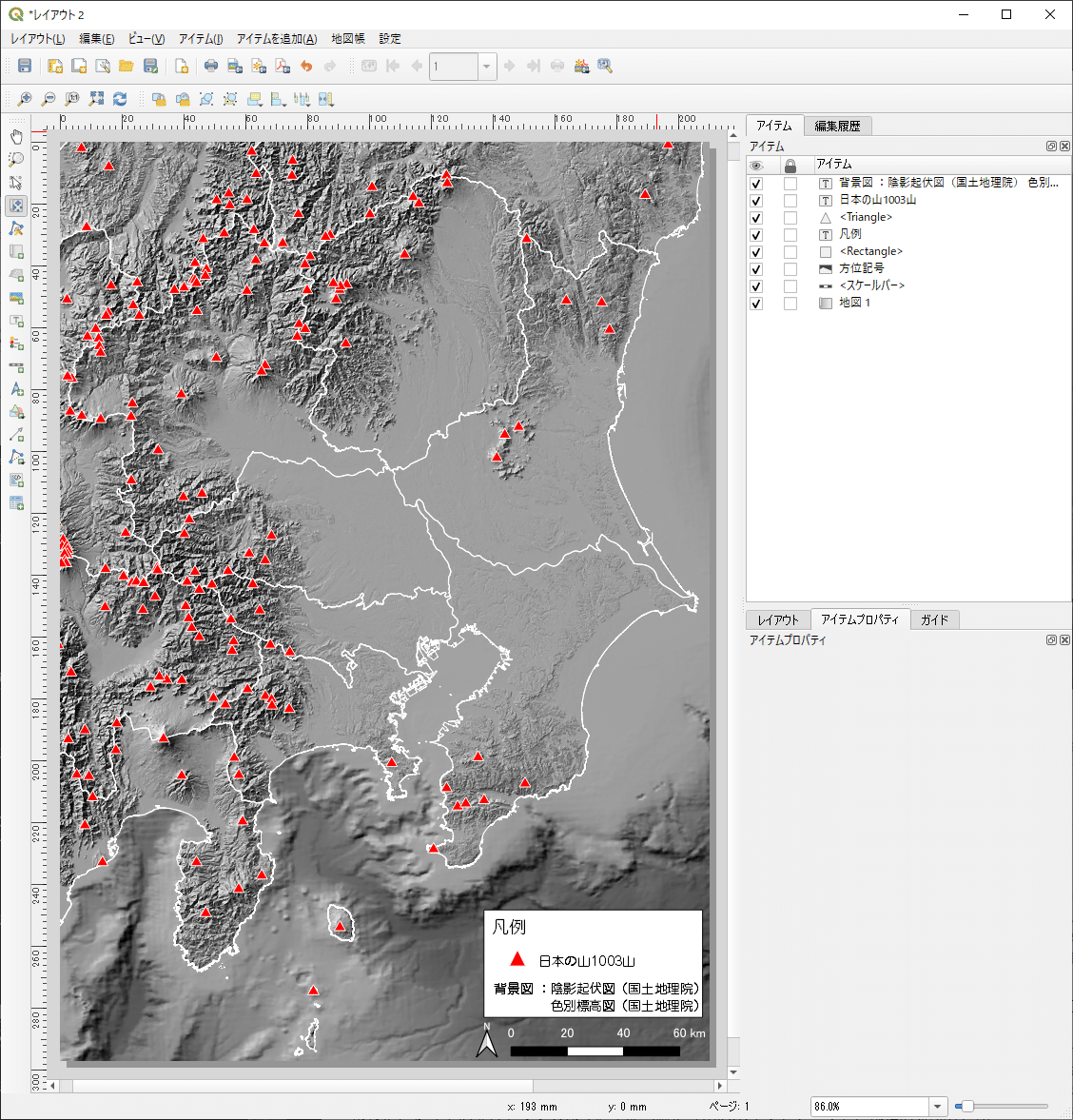
出力用にレイアウトを設定してみました。QGIS上で見る地図と、出力ファイルで見る地図では、線の太さやシンボルサイズなどのバランスが若干異なるので、トライ&エラーで修正していきます。
今回の凡例は、QGISの凡例機能ではなく、図形とラベルを使って作成しています。こちらの方が自由にレイアウトができるので、凡例機能より便利ですね。まぁ、このような作り方をするなら、Illustrator上で作業する方が、断然楽ですが・・・。
IV. おわりに
今回は、国土地理院に掲載されている日本の山の座標値情報を用いて山の分布図を描いてみました。1003山を全て描くとごちゃごちゃしていたので、関東地方を拡大して地図を作成しました。
このほか、テーブルデータの都道府県や標高のデータを活用して、「長野県の山だけ表示する」とか「1500m以上の山だけ表示する」のようにフィルタリングして分布図を描くこともできます。また、「日本の百名山」などの外部情報をCSVに付け加えて、その分布図を描くこともできます。
インターネット上を探してみると、モニタリング測定データや施設の立地情報など、座標値を持ったデータベースがたくさん見つかります。座標値をQGISに取り込む方法を習得できれば、様々な分布図が描けるようになります。
補足:60進数座標を読み込む
一般的にGISでは、座標値は10進数で扱うことが暗黙のルールとなっています。不幸にも60進数で示された座標値を掴まされてしまった場合には、自分で10進数に変換しなければ利用できません。
しかし、QGISは親切設計なので、60進数の値のままでも座標値を取り込むことができます。その方法は下図のように、CSVを読み込むときに「度分秒を使う」にチェックを入れて[追加]ボタンをクリックします。
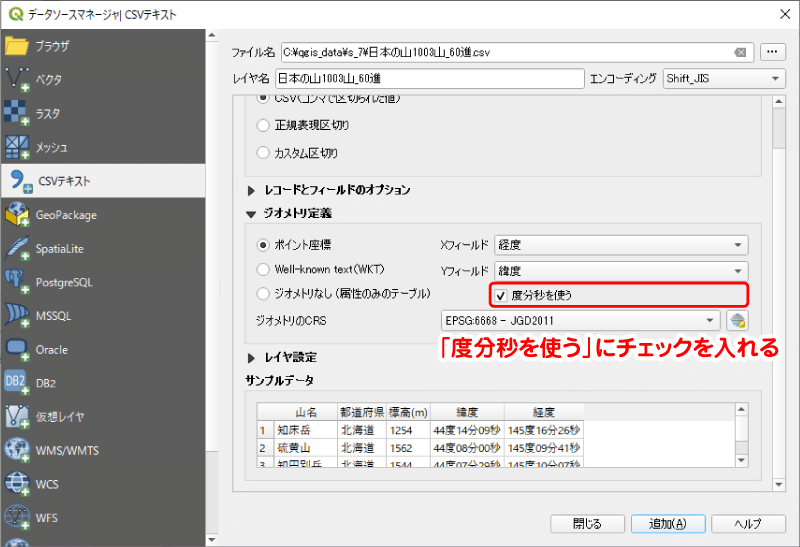
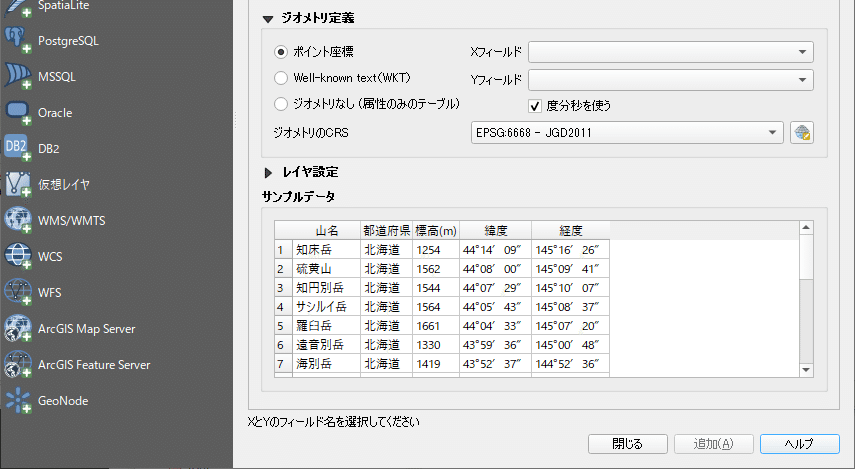
下図のように、元の座標値が記号「°、'、"」で入力されている場合でも、QGISが自動で判別して座標値を読み込んでくれます。
記事の内容でもそれ以外でも、地理やGISに関して疑問な点があれば、可能な限りお答えしたいと思います。