
後編:私の好きなジブリ絵は顔が中心なのか。python初心者(Ep19)

こんにちわ。色々とありまして、本日に投稿です。笑。すみません。
前回では、抽出したファイルを元に、それぞれの顔認証を行い、どれくらい検出できているのか。をピックアップすることができましたね。
本日は、ピックアップした検索結果をデータセットに加えることを行いたいと思います。
準備:元のデータセットの準備
結構前の記事になってしまいますが、データセットを下記の状態まで準備できている状態にしていましたので、こちらのデータセットが揃っている状態を準備したいと思います。
(1)ファイル名(ジブリサイトの抽出名)
(2)ファイルの拡張子
(3)自分の好み判定フラグ
(4)映画のタイトル
(5)動員数(万人)
(6)興行収入(億円)
下記のエピソードまでで、構築できた状態でしたね。
しかし、久々すぎて何が何やらでしたので、下記の様にまとめました。
STEP1:個人判断項目の追加+CSV掃き出し
ファイルを読み込み、個人の判断項目を追加したデータを構成
#requests ライブラリの使用宣言
import requests
import time
#ライブラリのインポート
import pandas as pd
import numpy as np
# osモジュールをインポート
import os
# original_photoのフォルダからリストを抽出
path = "./original_photo"
files = os.listdir(path)
#拡張子まとめとファイル名まとめのデータフレームを作成
extention_matome = pd.Series(files)
extention_filename = pd.Series(files)
#ファイル個数分だけ繰り返し処理を行う
for i in range(len(s)):
#抽出したいファイル名の場所を指定
file_names = "original_photo/{}".format(s[i])
root_ext_name= os.path.splitext(os.path.basename(file_names))[0]
root_ext_pair= os.path.splitext(file_names)[1][1:]
#拡張子の情報をデータフレームに格納
extention_matome[i] = root_ext_pair
#ファイル名の情報をデータフレームに格納
extention_filename[i] = root_ext_name
#データフレームの結合及びカラム名の指定
df = pd.DataFrame({'filename':extention_filename,'extention':extention_matome})
#my_judgeの追加
df=df.assign(my_judge=0)
#dfのデータをoutput_pd.csv として、出力(日本語が含まれる場合はshift_jis)する
df.to_csv("output_pd.csv",encoding ="shift_jis")STEP2:my_judgeのCSVファイルを編集
自分でCSVファイルを開き、自分の好みに1を付けましょう。
ファイル名:output_pd_mod.csv
STEP3:編集したCSVファイルを読み込む+映画名+上映時の人気度合い追加
CSVファイルを読み込み、ファイルから映画名の抽出、そして興行収入の追加を行います。
import re
#output_pd_mod.csv は、私の感じた事フラグを入れている状態
df_mod = pd.read_csv('output_pd_mod.csv',usecols=['filename','extention','my_judge'])
#映画名のデータフレームの作成
movies_name = pd.Series(files)
#fileサイズに合わせて繰り返し
for i in range(len(pd.Series(files))):
name = re.sub(r'[0-9]',"",df_mod.filename[i])
movies_name[i]=name
#映画名の追加
df_mod['movie_name']=movies_name
#辞書型で保存
mobilization_list = {"mononoke":1420,"howl":1500,"kazetachinu":969}
performance_income_list ={"mononoke":202,"howl":196,"kazetachinu":120}
#映画名のデータフレームの作成
mobi_list = pd.Series(files)
per_incom_list= pd.Series(files)
#fileサイズに合わせて繰り返し
for i in range(len(pd.Series(files))):
if df_mod.movie_name[i] == "mononoke":
mobi_list[i]=mobilization_list["mononoke"]
per_incom_list[i]=performance_income_list["mononoke"]
elif df_mod.movie_name[i] =="howl":
mobi_list[i]=mobilization_list["howl"]
per_incom_list[i]=performance_income_list["howl"]
elif df_mod.movie_name[i] =="kazetachinu":
mobi_list[i]=mobilization_list["kazetachinu"]
per_incom_list[i]=performance_income_list["kazetachinu"]
else:
mobi_list[i]=None
per_incom_list=None
df_mod['mobilization']=mobi_list
df_mod['performance_income']=per_incom_list
df_mod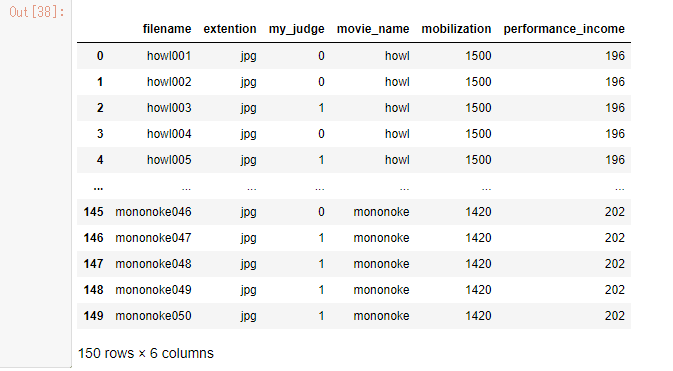
これで、今までのデータ状態が準備できましたね。今回の反省を生かして、一度このデータをCSVファイルに書込みを行う状態にしておきたいと思います。
STEP4:CSVファイルの書込み
df_mod.to_csv("output_pd_modi_1.csv",encoding ="shift_jis")これでここまでの前情報を df_mod のデータセットとして記録できましたね。それでは、やっと、顔情報の抽出した情報を追加したいと思います。
ファイル名:output_pd_modi_1.csv
実行:画像から顔抽出した情報をデータセットに追加
上記の準備で、保存したcsvファイルを読み込み、画像処理を実施したいと思います。画像処理の内容としてはEP18で述べましたが、今一度下記にコードを記載致します。というのも、少し微調整も入ったことにより、コード数が増えています。
#csvファイルの読み込み
df1= pd.read_csv('output_pd_modi_1.csv',index_col=0)
#画像のIMPORT処理
import cv2 as cv
import matplotlib.pyplot as plt
#映画名のリスト
mo_names=["howl","kazetachinu","mononoke"]
# カスケード型識別器の読み込み
cascade = cv.CascadeClassifier("./lbpcascade_animeface-master/lbpcascade_animeface.xml")
#顔の抽出した個数は何個か
pick_num =[]
pick_num_all =[]
#検出したすべてのリスト
pick_name_all =[]
#映画名毎に実施
for name in mo_names:
for num in range(1,51):
#活用するリンク先の確保
pick_file = "original_photo/{}{}.jpg".format(name,str(num).zfill(3))
print (pick_file)
#活用する画像の読み込み
pick_img = cv.imread('./{}'.format(pick_file))
#画像をグレーに変換
#読み込んだときの画像をグレーに変換
gray_t = cv.cvtColor(pick_img, cv.COLOR_BGR2GRAY)
# 顔領域の探索
face = cascade.detectMultiScale(gray_t, scaleFactor=1.1, minNeighbors=3, minSize=(30, 30))
# 顔領域を赤色の矩形で囲む
for (x, y, w, h) in face:
cv.rectangle(pick_img, (x, y), (x + w, y+h), (0, 0, 200), 3)
#何のファイルにどの数だけの検出ができているのか
pick_num = "{}{}_pick{}".format(name,num,len(face))
#ピックアップした顔の数をリスト化
pick_num_all.append(len(face))
#検出した名前をリスト化
pick_name_all.append(pick_num)
#データセットに追加処理
df1['pick_name']=pick_name_all
df1['pick_face_num']=pick_num_all進めていくと、顔検出の有無の部分の情報も欲しくなり、下記のコードを追加します。
#顔検出の有無リストを追加
pick_face_judge=[]
pick_face_judge_hold=[]
for num in range(0,150):
if df1.pick_face_num[num]==0:
pick_face_judge=0
else:
pick_face_judge=1
pick_face_judge_hold.append(pick_face_judge)
pick_face_judge_hold
df1['pick_face_judge']=pick_face_judge_hold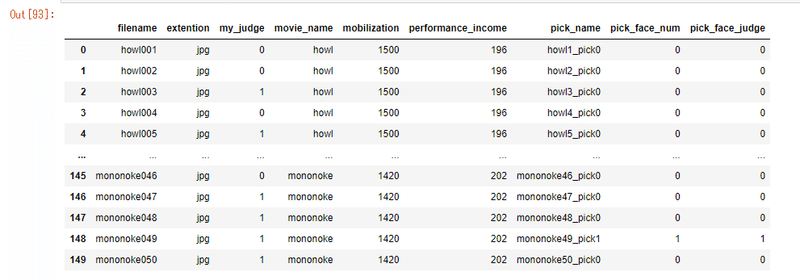
これで一通りのデータセットが準備できました。
数字でみても良く分からない為、次に図で状態を確認しましょう。
結果発表:私の好きなジブリ絵は顔が中心なのか
それでは、今回の結果を図で表現しましょう。
sns.swarmplot("my_judge","pick_face_num",data =df1)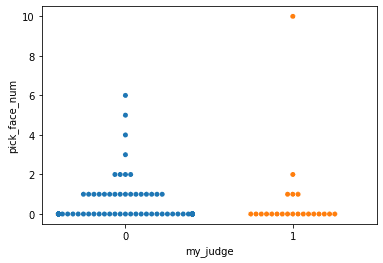
ふむふむ
私がいいな!っと思ったものは、顔があまり検出されていない
sns.catplot(x="pick_face_judge", y="pick_face_num", hue="movie_name", col="my_judge", data=df1)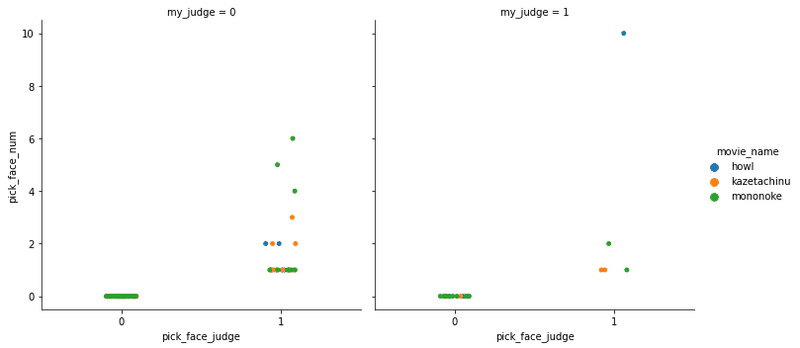
うーん。
いいな!と思ったもので顔検出ができた作品は、
もののけ姫 :2枚
風立ちぬ :2枚
ハウルの動く城:1枚
ということが分かり、
#私が気にいっている画像で顔が検出された枚数
my_select_true = (df1.my_judge&df1.pick_face_judge).sum()
#私が気にいっている画像で顔が検出されていない枚数
my_select_false = df1.my_judge.sum() - my_select_true
#私が気にいっている画像の検出確率
my_score = my_select_true/(my_select_false + my_select_true)
print("気に入った画像で顔が検出された枚数:{}".format(my_select_true))
print("気に入った画像で顔が検出されなかった枚数:{}".format(my_select_false))
print("気に入ったいる画像の検出確率:{}".format(my_score))
以上より、、
私の好きなジブリ絵は顔が中心ではない!!
事が分かりました。お疲れさまでした。。。
次は、
次はデータを深く観察すること
を行い、確からしさを確認しようと思います。
season2もあと少しで終わります。頑張っていきましょう!!
よろしければサポート頂けると幸いです!子供へのパパ時間提供の御礼(お菓子)に活用させて頂きます☆