
明日の平均気温予測 【知識0でもやってみたい機械学習】

前回の「ワインの品質判定 【知識0でもやってみたい機械学習】」が好評だったため、勉強するテーマを変えて今回も機械学習をやっていきます。でも機械学習って数学の知識とか難しいプログラミングとかしないといけないんでしょ?
必要な知識、技能
タイトル通り知識は必要ありません。この記事に辿り着けているだけで十分な知識がありますが、前回の続きなのでまだお読みになっていない方は先に前回の記事を下記のリンクから読むとより楽しめます。
機械学習をするにあたってアルゴリズムの話が出てきます。アルゴリズムを説明する際に数学の知識が絡んでくるのですが、噛み砕いて説明するのでどうか構えずに読んでください笑
必要な機材、ソフト
本来は機械学習用の環境構築をするのですが、皆さんが持っている環境 ( pc ) が同じでは無いので Google 先生の力を借ります。
前回に引き続き、今回も colab こと Google Colaboratory を使っていきます。
colab の使い方は「colab の使い方(操作手順)」という記事で説明してあるので、使い方がわからない方は下記のリンクから使い方をマスターしてみてください。
機械学習をしてみよう
本題に入りますが、今回のテーマは気象予測です。
機械学習にはデータが必要ですが、気象庁がデータを公開してくれているので今回はそれを使うことにします。県や地域を指定できたり、どの期間のデータをダウンロードするのかを決めることができます。なのでデータは皆さんが住んでいる地域を選択すると面白いと思います。
まずは気象庁のサイトから学習に使うデータを取得します。下記のリンクから気象庁のサイトに飛んでください。
サイトを開いたら、「地点を選ぶ」からお好きな都道府県を選んでクリックしてください。(私は愛知を選びました)
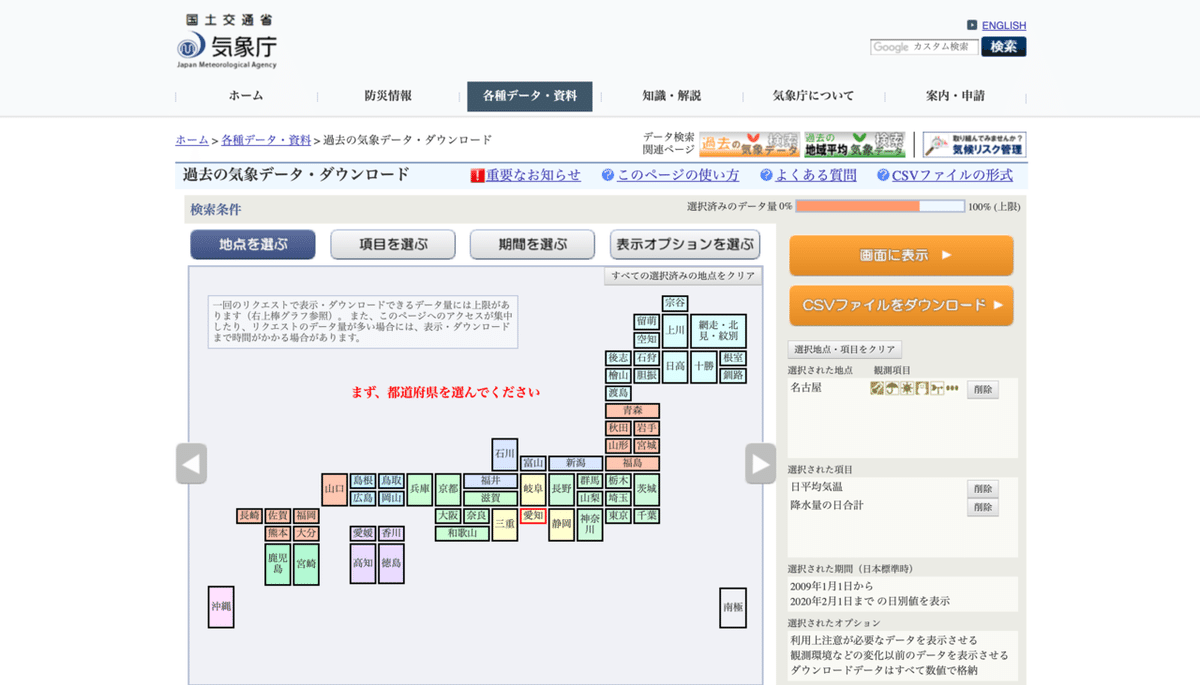
次に選択した都道府県からお好きな地域を選んでクリックしてください。(私は名古屋を選びました)
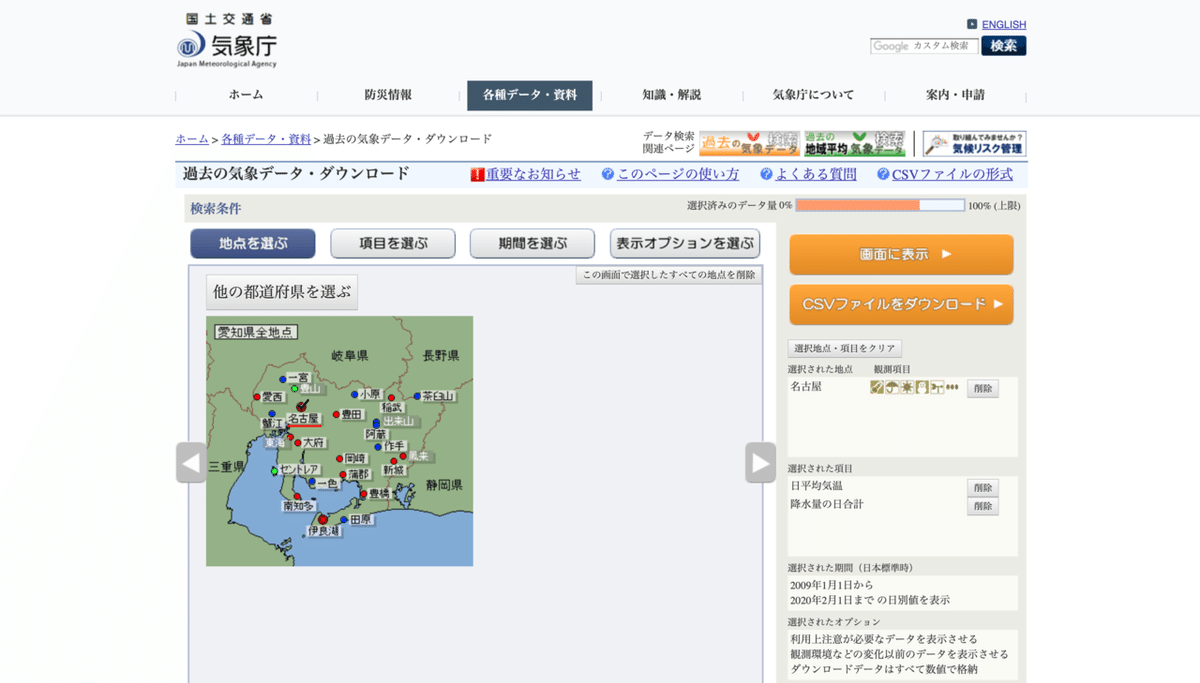
地域を選択したら、画面右側中央に「選択された地点」が表示されているので、間違いがないか確認してください。
確認ができたら「項目を選ぶ」タブから「データの種類」を日別値、「気温」から日平均気温を選択してください。

全て選択できたら、画面右側中央に「選択された項目」が表示されているので、間違いがないか確認してください。
確認ができたら「期間を選ぶ」タブから連続した期間で表示するを選択してください。詳細な日付ですが 10 年分の学習データが欲しいので、2009 年 1 月 1 日から昨日の日付 ( 2020 年 2 月 3 日に選択する場合は、2020 年 2 月 2 日 ) を選択してください。
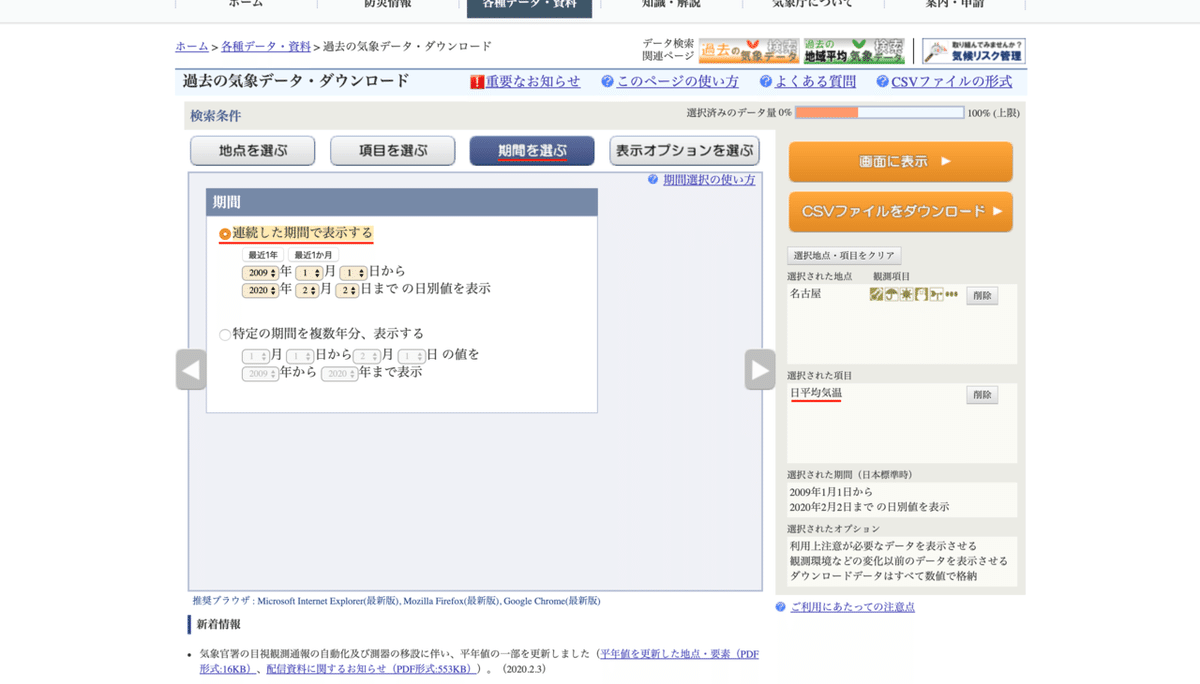
日付が選択できたら、画面右下に「選択された期間」が表示されているので、間違いがないか確認してください。
確認できたら画面右上にある「 CSV ファイルをダウンロード」を押して CSV ファイルをダウンロードしてください。

「 data.csv 」というファイルがダウンロードされていれば成功です。
ここからは colab を使って Python のコードを書いていきます。
まず、下記のリンクから colab を開いてください。
開いたら画面左上の「ファイル」から「Python 3 の新しいノートブック」を押します。
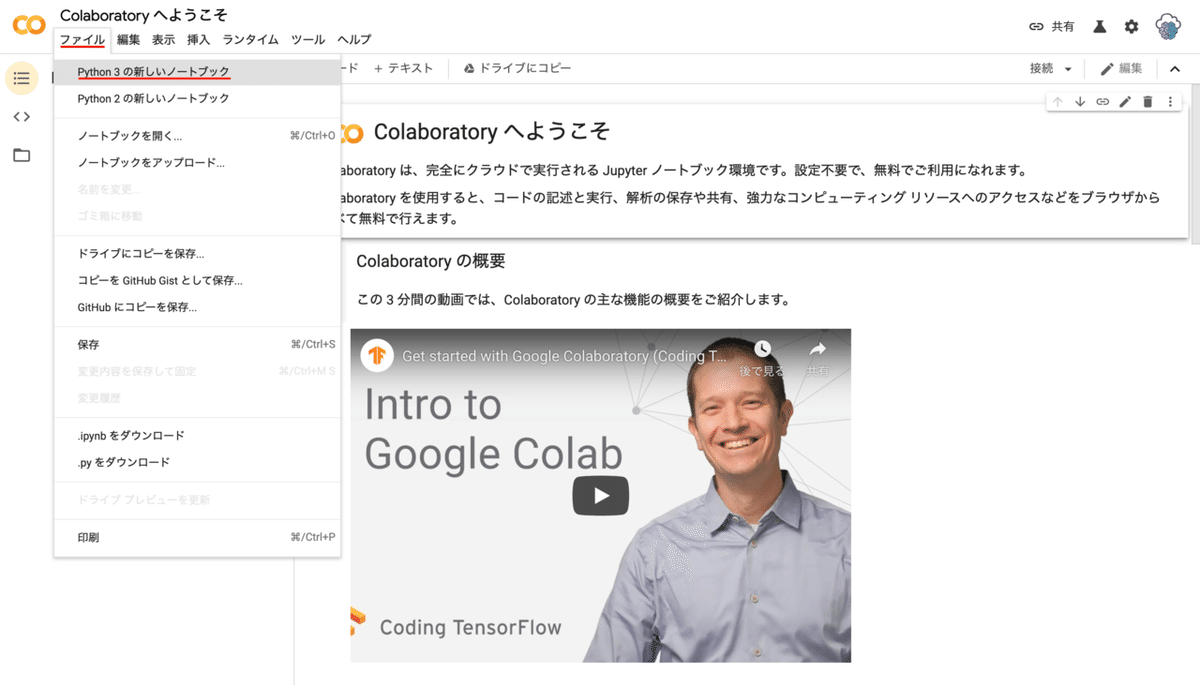
新しいタブで Python 3 の実行環境が出来上がるので、画面左上の「ノートブック名」を tomorrow-weather に変更しておきましょう。

変更できたら画面左にあるファイルアイコンから「ファイル」を開いて「アップロード」を押します。(ファイルのブラウジングを有効にするには、ランタイムに接続してください。という表示がある場合は、初回接続をしている状態なので少し待ってください)

アップロードを押した後は、先ほどダウンロードした「 data.csv 」を選択してください。アップロードが終わると「注: アップロードしたファイルはランタイムのリサイクル時に削除されます。」という警告が表示されるので「 OK 」を押してください。これは colab の仕様で、90 分以上操作しないもしくはノートブックを作成してから 12 時間経過するとファイルが初期化されますよ。という警告です。(書いたコードは初期化されません)
「ファイル」にアップロードした「 data.csv 」があれば成功です。
ファイルのアップロードを確認したら「コード」セルに下記のコードを書いて実行します。
# データの整形
in_file = "data.csv"
out_file = "temp10y.csv"
# CSVファイルを読み込む
with open(in_file, "r", encoding="Shift_JIS") as fr:
lines = fr.readlines()
# ヘッダーを付け替える
lines = ["年,月,日,気温,品質,均質\n"] + lines[5:]
lines = map(lambda v: v.replace('/', ','), lines)
result = "".join(lines).strip()
print(result)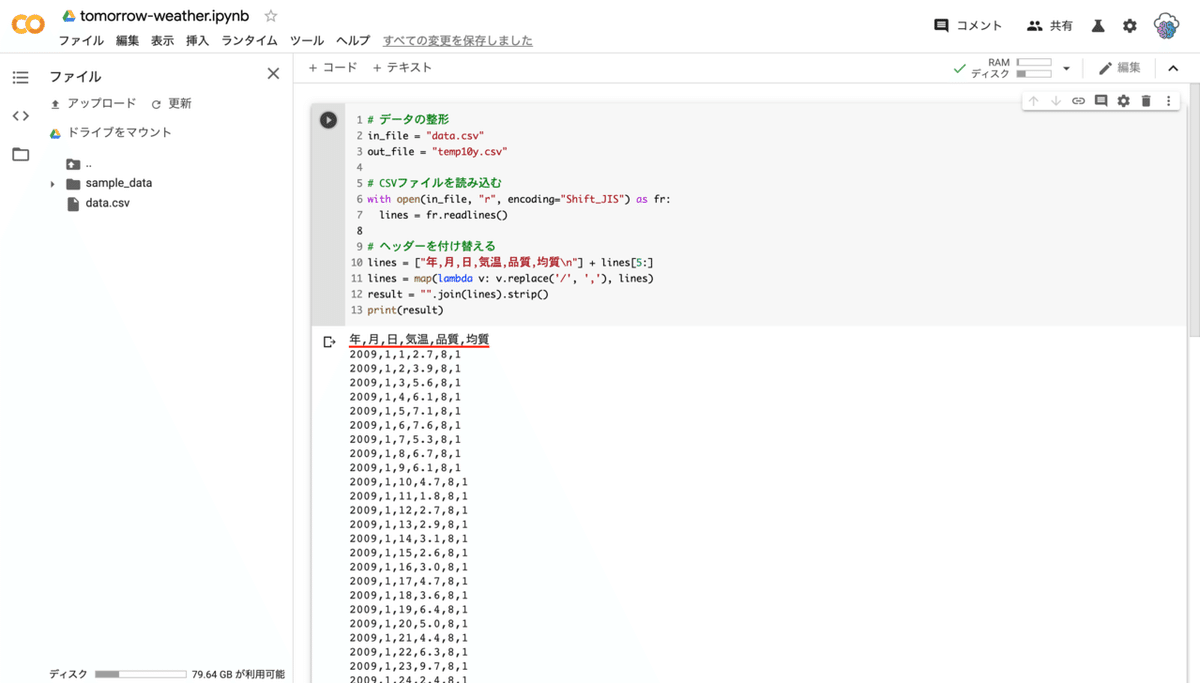
--- コード解説 ---
2, 3 行目では data.csv を読み込むファイルとして、temp10y.csv を新しく作るファイルとして指定しています。
6, 7 行目では data.csv を "r"(読み込み専用)で、文字コードが「 Shift-JIS 」の指定をして開いています。Shift-JIS という文字コードは日本語の文字コードで、日本のサイトでは見かけることがあります。 後述しますが、現在では文字化けを回避するために utf-8 という文字コードを指定することが望ましいです。
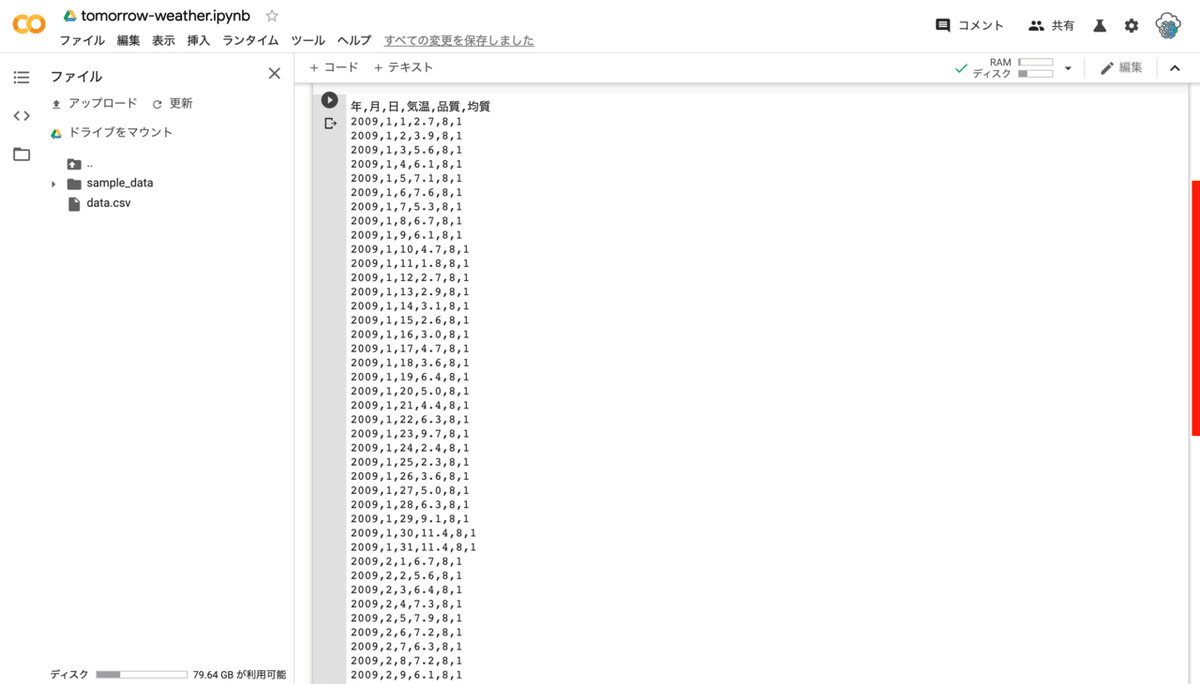
10 行目以降ではデータを扱いやすい形式にするためにヘッダー(データの名前)を付け替えています。実行結果をスクロールして一番上を確認するとヘッダーが「年,月,日,気温,品質,均質」となっているのが確認できます。また、元のデータでは日付が 2009/1/1 のように /(スラッシュ)で区切られています。/ の状態では扱いづらいので、,(コンマ)で区切るように変えています。
--- コード解説終わり ---
実行結果から 2009 年 1 月 1 日から昨日の日付までのデータが , で区切られた形式になっていることがわかります。
実行結果がとても長いので、画面をスクロールする際は画面右側のスクロールバーからスクロールすると良いです。
実行結果を確認したら「コード」セルを追加し、下記のコードを書いて実行します。
# 結果をファイルへ出力
with open(out_file, "w", encoding="utf-8") as fw:
fw.write(result)
print("saved.")
--- コード解説 ---
先ほどの実行結果を temp10y.csv という名前で保存しています。その際に文字コードを utf-8 にしているので、文字化けのリスクを減らすことができます。
--- コード解説終わり ---
実行が終わったら、実行結果に「 saved. 」と表示され画面左の「ファイル」に temp10y.csv というファイルができている事を確認してください。
ファイルを確認したら「コード」セルを追加し、下記のコードを書いて実行します。
# 気温データの読み込み
import pandas as pd
df = pd.read_csv("temp10y.csv", encoding="utf-8")

--- コード解説 ---
扱いやすい形式に整形したデータ temp10y.csv を読み込んでいます。このコードは「ワインの品質判定 【知識0でもやってみたい機械学習】」で一度登場しているので、少し詳しい内容を話します。pd.read_csv() という括弧付きのまとまりを「関数」と呼びます。関数は料理に例えると包丁やまな板、フライパンなどの調理器具です。関数の括弧の中は料理に例えると具材や調理方法です。今回の場合は pd.read_csv() というまな板(関数)に括弧で temp10y.csv という具材(データ)を utf-8 という調理方法(文字コード)で調理(読み込む)してね。という指定をしています。(なんとなく雰囲気が伝われば嬉しいです笑)
--- コード解説終わり ---
今回はデータを読み込んだだけなので、実行しても何も出力されません。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。
# データを学習用と予測用に分離する
train_data = (df["年"] <= 2019)
pre_data = (df["年"] >= 2020)
interval = 6

--- コード解説 ---
今回は 2009 年から 2019 年までの 10 年間を学習用のデータとします。2020 年のデータは明日の平均気温を予測する際に使うので、学習用データとは分けておきます。interval = 6 という数値は平均気温を求めたい日の直前 6 日のデータから予測するという指定です。interval = 7 にすれば直前 1 週間の平均気温から予測します。
--- コード解説終わり ---
今回もデータを分離しただけなので、実行しても何も出力されません。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。( 3 行目以降の行頭にインデント(半角スペース)がありますが、Python と言う言語の使用上、詰めてしまうとコードが動かなくなるので注意してください。)
# 直前6日分を学習するためのデータ整理
def make_data(data):
x = []
y = []
temps = list(data["気温"])
for i in range(len(temps)):
if i < interval: continue
y.append(temps[i])
xa = []
for j in range(interval):
d = i + j - interval
xa.append(temps[d])
x.append(xa)
return(x, y)
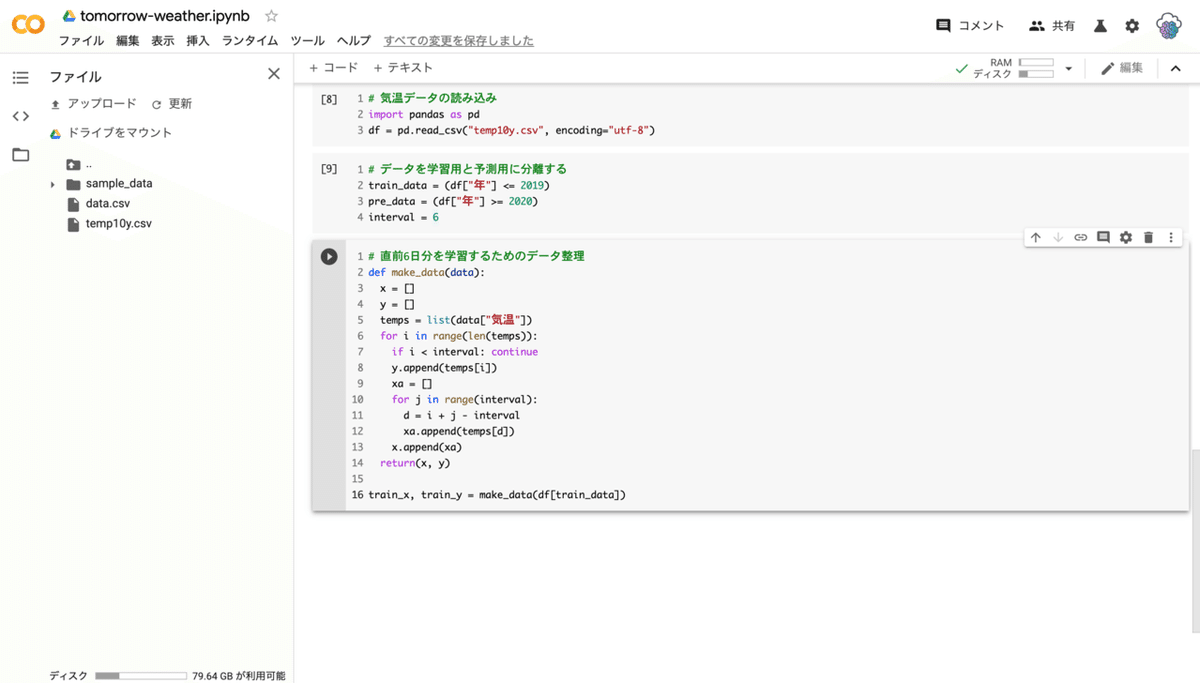
train_x, train_y = make_data(df[train_data])
--- コード解説 ---
今回は直前 6 日間データから当日の気温を予測します。そこで直前 6 日間のデータと当日のデータに分ける事で学習しやすいデータを作っています。コード自体は長いのですが、6 つ毎に区切っては代入を繰り返しているだけなので、難しい処理をしているわけではありません。
--- コード解説終わり ---
言葉で説明してもイメージしづらいので、実際にデータを出力してどのような形式になっているのか確認します。「コード」セルを追加し、下記のコードを書いて実行します。
print(train_x)
print(train_y)

--- コード解説 ---
先ほど二つに分けたデータを表示しています。上が学習で使う直前 6 日の平均気温で、下が当日の平均気温です。
--- コード解説終わり ---
上の画像でそれぞれ同じ色のデータがペアとなります。
実際のデータが確認できたら「コード」セルを追加し、下記のコードを書いて実行します。
# 直線回帰分析を行う
from sklearn.linear_model import LinearRegression
lr = LinearRegression(normalize=True)
lr.fit(train_x, train_y)
coef = list(lr.coef_)
intercept = lr.intercept_
print(coef)
print(intercept)
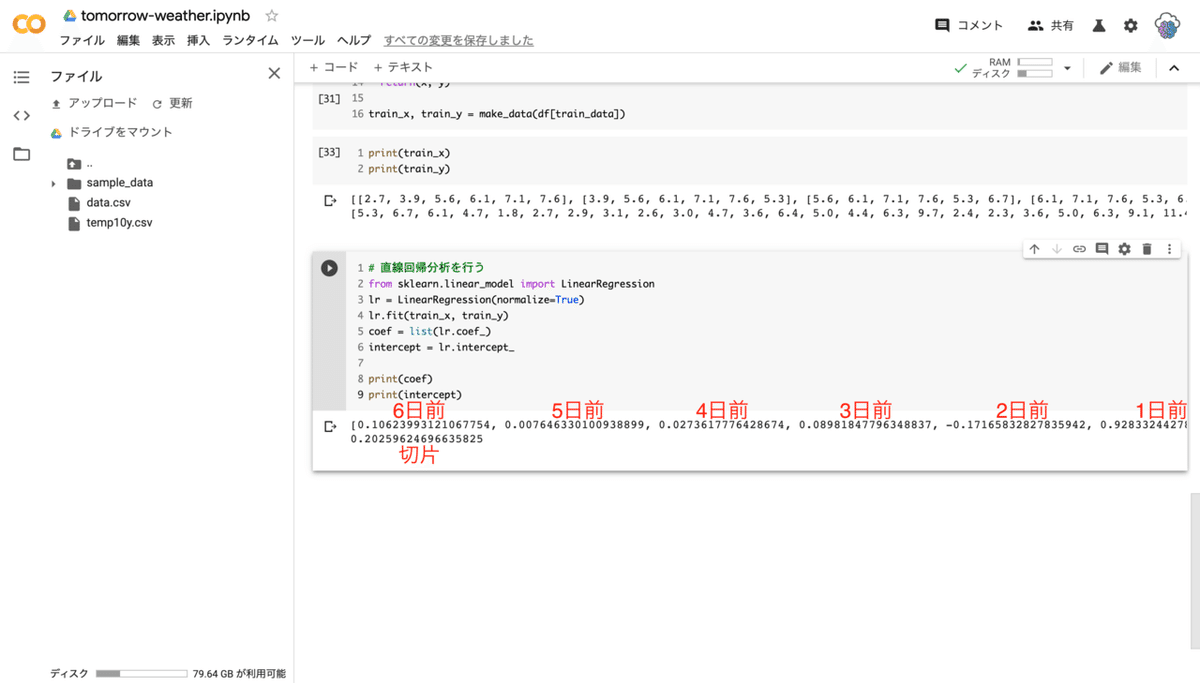
--- コード解説 ---
いよいよ学習ですが、今回は直線回帰分析を使います。直線回帰分析とは重回帰分析の最も単純な形で... と言われても余計に混乱するだけなので、噛み砕いて説明します。今回の学習データは過去 6 日間の平均気温と当日の平均気温です。私たちがやりたい事は、過去 6 日間のデータをどう変形させれば当日のデータに近い数値を得られるか?というところです。ここで回帰分析を使うことで、過去 6 日間のそれぞれのデータをどれだけ強く反映(データの重みとも言います)させれば良いかということが計算できるのです。この説明でもあまり理解できない場合は実際のデータで説明をするので次に進んでください。
--- コード解説終わり ---
出力結果で二種類の数値が出力されています。上の数値は偏回帰係数と言って(理解する上で名前は重要ではありません)、6 日間のデータをどれだけ強く反映させれば良いかという数値です。6 つ並んでいますが、左から 6 日前、5 日前、4 日前... というように並んでいます。下の数値は切片と言って、この数値を足し合わせると良い感じになるという微調整をしている数値です。
ここまでで数学の話は終わりです。正直一回で理解する必要はないです。こんな数学の話で機械学習を嫌いになってしまっては困るので、雰囲気を掴んでいただけたら嬉しいです。(最悪忘れてしまっても大丈夫です笑)
実行ができたら「コード」セルを追加し、下記のコードを書いて実行します。
# 回帰分析の結果から明日の平均気温を予測する
last6d = (df[pre_data].iloc[-6:])
last6d_temps = list(last6d["気温"])
pre_temp = sum([x * y for (x, y) in zip(coef, last6d_temps)]) + intercept
print("明日の平均気温は " + str(pre_temp) + " 度です。")

--- コード解説 ---
先ほど求めた偏回帰係数に直前 6 日間のデータを掛け合わせ、切片を足した値が明日の平均気温になります。式はどうなっているかと言うと、(0.10623993121067754 × 6 日前の平均気温) + (0.007646330100938899 × 5 日前の平均気温) + (0.0273617776428674 × 4 日前の平均気温) + ( 0.08981847796348837 × 3 日前の平均気温) + (-0.17165832827835942 × 2 日前の平均気温) + (0.9283324427887097 × 1 日前の平均気温) + 0.20259624696635825 (切片) = 7.206020935923868 (当日の平均気温) という計算式になっています。(選んでいる地域や日付によって数値は異なります)
--- コード解説終わり ---
ここまで実行できれば機械学習で明日の平均気温を求めることができたと言えます。前回よりも難しい内容だったかもしれませんが、楽しめたでしょうか?
今回は明日の平均気温を予測すると言う内容なので、この記事を読んでいる今日の日付は人によって違います。なので皆さんは日付を置き換えて読んでください。
初めに日付を整理しておくと私の場合、今日は 2020/02/03 で気象庁から 2020/02/02 までの最新のデータをダウンロードしました。そして予測した明日の平均気温の日付は 2020/02/03 です。今日の日付と予測した明日の平均気温の日付が同じなのでややこしいのですが、2020/02/04 になると 2020/02/03 まで(前日まで)の平均気温が気象庁から公開される事を考えるとわかりやすいかもしれません。
先ほど予測した明日の平均気温の値(私の場合は 7.206020935923868 度)は比較の際に使うのでメモしておいてください。
それでは実際のデータを気象庁からダウンロードして... と言いたいところなのですが、実際のデータを扱っている都合上日付が変わらないとデータをダウンロードすることができません。これ以降は日付が変わってから続きを行ってください。
日付が変わったら、下記のリンクから気象庁のサイトへ飛んでください。
サイトを開いたら、「地点を選ぶ」「項目を選ぶ」は予測に使ったデータと同じにしておき、「期間を選ぶ」タブから予測した日の日付(私の場合は 2020 年 2 月 3 日)が選択できるようになっているので選択し、画面右上の「 CSV ファイルをダウンロード」からファイルをダウンロードします。

予測の際にダウンロードした data.csv を消していなければ data (1).csv と言うような名前でダウンロードされていると思います。(環境によって変わってくるので適宜読み替えてください)
ダウンロードできたら、data (1).csv をダブルクリックして開きます。windows の場合は Excel 、mac の場合は Numbers でファイルが開くと思います。

ここに書いてある平均気温が実際の数値になります。
私の場合は予測が 7.206020935923868 度、実際が 6.9 度だったのでぼちぼちと言ったところでしょうか。
皆さんの結果がどうなったのかコメントで教えてください!
下記のリンクから私の Twitter に飛ぶことができます。DM を一般公開しておくので質問等ご気軽にしてください。(純粋な感想もとても嬉しいです)
質問をする際は、質問を投げるだけではなく、何がしたいのか?どこまで試したのか?等を説明していただけると答えやすいです。
それでは最後まで読んでいただきありがとうございました。
サポートは書籍購入や記事を書く際の素材費として使わさせていただきます!