
自治体税務データを用いた経済格差研究のフロンティア:行政データと実証経済学⑤

経済セミナー編集部noteでは、『経済セミナー』2022年6・7月号から23年10・11月号まで8回にわたって連載した「行政データと実証経済学:東京大学CREPE自治体税務データ活用プロジェクトの実践」を、第1回から改めて掲載していきます。
第1回から第8回までの各回は、以下の noteマガジン に順次公開していきますので、ぜひご覧ください。
このnoteでは、2023年6・7月号に掲載された連載第 5 回をお送りします。
著者紹介
北尾早霧
東京大学大学院経済学研究科教授
プロフィール
ニューヨーク大学経済学博士。南カリフォルニア大学マーシャル経営大学院助教授、ニューヨーク連邦準備銀行調査部シニア・エコノミスト等を経て、2018年より現職。
論文:“Fiscal Cost of Demographic Transition in Japan,” Journal of Economic Dynamics and Control, 54: 37-58, 2015 など。
鈴木通雄
東北大学大学院経済学研究科准教授
プロフィール
ウェスタン・オンタリオ大学経済学博士。一橋大学経済研究所附属経済社会リスク研究機構特任准教授、内閣府経済社会総合研究所主任研究官等を経て、2022年より現職。内閣府経済社会総合研究所客員研究員も兼任。
論文:“Consumption, Income, and Wealth Inequality in Canada,”(共著)Review of Economic Dynamics, 13(1): 52-75, 2010など。
山田知明
明治大学商学部教授
プロフィール
一橋大学経済学博士。立正大学経済学部専任講師、明治大学商学部准教授等を経て、2014年より現職。
論 文:“Population Aging, Health Care and Fiscal Policy Reform: The Challenges for Japan,”(共著)Scandinavian Journal of Economics, 121(2): 547-577, 2019など。
1. 格差の分析はなぜ難しいのか?
1.1 経済格差への関心の高まり
バブル崩壊以降、日本において経済格差への関心が高まってきた。一億総中流といわれた時代が終わり、1980年代頃まで2%前後と、欧米と比較したら信じられないほど低水準であった失業率も上昇する中、格差への関心が高まるのは自然であった。しかし、アメリカを中心として世界的にはいわゆる偉大な安定期(the Great Moderation)の真っ只中であったこともあり、経済格差に関する関心は決して高いものではなかった。ところが、日本同様にアメリカでも2007年頃に住宅バブルが崩壊して以降、2011年に発生した「ウォール街を占拠せよ(Occupy Wall Street)」のデモ活動が注目されるなど、格差への関心が高まっていくことになる。
マクロ経済学の教科書の著者としても有名なマンキュー教授や『21世紀の資本』の著者であるピケティ教授が指摘するように、経済格差の研究というのは決して経済学の中ではメインストリームといえるものではなかった。
とはいえ、経済格差研究の歴史は決して短くない。古くはマルサスやリカード、マルクスの時代から一定の関心を持たれていた。さらには、クズネッツ曲線で有名なクズネッツや、いずれノーベル経済学賞をとると期待されながら2017年に亡くなったイギリス人経済学者アトキンソン教授の一連の研究もある。
1.2 もっとデータを!
なぜ経済格差は経済学のメインストリームになれなかったのだろうか。もちろん、多くの人が関心を持つトピックは時代によって変わってくる。今話題の「持続的な開発と環境」はその典型例であろう。一方、経済格差に関しては異なる事情がある。格差研究を行うためにはデータが欠かせない。それもGDPのような集計されたマクロデータではなく、個人や家計を対象としたミクロ的なデータ(個票データ)が必要である [1]。
[1] ピケティはアトキンソン(2015)の序文で、マルサスやリカード、マルクスらは格差問題に関心を持ちながら、「限られたデータしか使えず、しばしば純粋理論的な考察にとどまるしかなかった」と指摘している。
現在、経済格差を把握するうえで主流になっているのが、いわゆるサーベイデータを用いるアプローチである。日本で家計サイドから所得や消費、資産格差を把握したい場合には、総務省統計局が集めている「家計調査」や「全国消費実態調査」(2019年より「全国家計構造調査」に名称変更)などが用いられる。また、賃金や労働時間、時間の使い方といった情報に関しては、厚生労働省が実施する「賃金構造基本統計調査」や、総務省統計局が集める「就業構造基本調査」「社会生活基本調査」なども用いられている。
これらのデータに共通するのが、国や大学といった調査機関がデータ収集のために世帯や個人、企業単位で対象を抽出したうえで調査への協力を求めている点である。多くのデータセットは地域や年齢といったさまざまな属性が偏らないように工夫されて、調査がデザインされている。
サーベイデータはすでに長期間にわたって収集されており、たとえば「家計調査」は消費者物価指数の計測にも使用されるなど、さまざまな方面で利活用されてきた実績がある。もちろん、経済格差の研究においても重要な役割を果たしている。
1.3 サーベイデータの限界
そんなサーベイデータであるが、サンプル調査であるがゆえの短所もある。格差研究では”極端”な世帯、すなわち、超富裕層と貧困層(いわゆる分布の両裾)の動向が知りたい場合が多いが、その把握が難しいのである。近年、アメリカでは富がごく一部のトップ層に集中していることが指摘されている。このような傾向を把握することは、公平性だけでなく徴税などの観点からも重要であるが、その正確な実態把握は容易ではない。もちろん、サーベイは税務調査とは別ものであるが、「痛くもない腹をさぐられたくない」と警戒して、調査に非協力的な人たちがいても不思議ではない。
一方、貧困層の実態把握もまた、税制や生活保護を中心とした各種再分配政策のために大切である。しかし、こういった貧困層がどのような生活をしていて、どういった理由で困窮しているのかを把握するのもまた難しい。たとえば、シングルマザーであれば調査員が自宅に出向いて調査しようにも、日中は留守にしていて調査できないかもしれない。あるいは、どんなに困っていても、その困窮した生活状況を詳らかに調査員に伝えることを嫌がる人もいるだろう。
こういった理由から、サーベイデータはたとえば分布の右側であれば意図的に富裕層を多めに抽出するといった工夫をしない限り、分布の両裾が相対的に多く抜け落ちて、中流階級が多めになる可能性がある [2]。集計量、たとえば平均所得や平均支出を把握したいということであれば、超富裕層と貧困層の脱落はそれほど問題ではないかもしれない。しかし、そもそもの目的が所得や資産分布の把握である格差研究や、小さな確率が引き起こす大きな変化にも注目する所得リスクの分析の場合、この点は大きな問題になる。
[2] 実際、アメリカの「Survey of Consumer Finance」は意図的に富裕層を多めにサンプリングしている。
1.4 サーベイデータを補う行政データ
上記のようなサーベイデータの短所を補完するために、本連載でこれまで説明してきた自治体税務データのような行政データに注目が集まっている [3]。
[3] 諸外国の場合、税務データは自治体ではなく国単位で管理しているケースが多いため、日本以外のデータについては自治体税務データとは呼ばず、行政データと呼称しておく。
なぜ行政データに注目が集まったのだろうか?行政データの強みはその圧倒的なサンプルサイズとカバレッジである。なにしろ、すべての個人は必ず何らかの形で記録が残る。収入が低くて課税対象でなかったとしても、「課税対象にならない程度の収入であった」ことが記録されている。たとえばアメリカの場合、原則としてすべての労働者が確定申告を行っている [4]。そのため、サーベイに協力してもらえないといった悩みはない。また、各個人のIDである社会保障番号をもとに同一個人を追跡可能なため、後ほど説明するように時間を通じた所得の変化を利用した所得リスクの推定にも用いることができる [5]。
[4] 所得が基礎控除額を下回る場合など、一定の例外はある。
[5] 税務データから経済格差を把握するという試み自体は決して新しいものではない。有名なクズネッツ曲線はアメリカの連邦所得税を用いているほか、ピケティも2000 年代前半にはフランスの税務データを用いた格差研究を行っている(ピケティ 2016)。
2. 行政データの可能性
2.1 行政データを用いた格差研究
行政データを用いて経済格差と所得リスクの推定を行って一躍脚光を浴びたのが、ミネソタ大学のグヴェネン教授らによる一連の研究である(Guvenen et al. 2021)。彼らはアメリカの社会保障局が記録している給与データを利用して、アメリカにおける労働者の給与所得の特徴をさまざまな側面から分析した。前述の通り、従来はこのような分析にはサーベイデータが用いられていた。サーベイデータの場合、サンプルサイズは各年について数千から多くて数万程度である。もちろんこれだけの数を集めるのも一苦労ではある。しかし、行政データのサンプルサイズははるかに大きい。グヴェネン教授らは社会保障局の給与データから10%に当たる労働者の給与所得にアクセスすることが許可された。アメリカで働く労働者の 10%なので、彼らが実際に分析対象とした25歳から60歳までの男性労働者だけでも数百万人分のデータとなる。
サンプルサイズが大きいおかげで、これまで分析されてきた平均や分散に加えて、歪度や尖度といった高次のモーメント情報もより安定的に扱えるようになった。加えて、年齢階層ごとに所得パーセンタイルに分けて、それぞれで所得成長率がどのように異なっているかも分析している。サーベイデータなどにおける従来のサンプルサイズでは、ここまで細かく分類をしてしまうと、各分類のサンプルサイズは数十程度、年齢階層によっては1桁になってしまい、とてもではないが格差分析はできなかった。
2.2 GRIDプロジェクト
グヴェネン教授はプロジェクトをさらに拡大し、スタンフォード大学のピスタフェッリ教授、プリンストン大学のヴィオランテ教授とGlobal Repository of Income Dynamics(GRID)プロジェクトを立ち上げた。GRIDプロジェクトは、行政データを用いて、国ごとの経済格差に関するデータベースを作成しようという一大プロジェクトである。
現時点でアメリカのほかにイギリスやフランス、ドイツ、カナダ、デンマーク、ノルウェー、スウェーデンなど、13カ国が参加している。プロジェクトのホームページにアクセスをすれば、GDP データを取得するような感覚で各国のさまざまな角度からの経済格差データを比較できる [6]。
[6] 詳しくは、GRIDのホームページを参照。
3. 所得のダイナミクスと格差に迫る
3.1 所得プロセスを推定する
所得は人によってバラツキがあるうえ、毎年変動している。それらの動きは所得格差やリスクといった形でわれわれの生活に影響を与える。ミクロデータを用いて、こうした個人が直面する所得変動のリスクの性質(長期にわたる所得の低下や短期的な所得変動など)を把握しようという試みが、所得プロセスの推定である。
同一個人を追跡できる大規模な行政データの強みにより、個人レベルの所得変動の分析がさらに進んでいる。グヴェネン教授らは、アメリカの行政データを用いて、所得変化率の分布が負の歪度と高い尖度を持ち、正規分布から大きく乖離していることを示した(Guvenen et al. 2021)。さらに、彼らは、その尤度や尖度が年齢や所得水準によって大きく変わることや、高所得者にとっては所得の増加は一時的であることが多いのに対し、所得の減少の影響は長期間にわたること、低所得者ではそのパターンが逆になることを示した。このように、行政データによる精度の高い所得情報で明らかにされた所得変動のパターンは、従来の実証分析で使われてきた線形の所得動学モデルでは説明できないことが多く、モデルの拡張が行われてきた。
所得リスクの把握がなぜ大事なのかを理解するために所得動学モデルを少し丁寧に説明しよう。実証分析でよく使われているのは下記のモデルである。
$$
\begin{aligned}
& \widetilde{y_{i a t}}=x_{i a t}^{\prime} \gamma+\delta_t+y_{i a t} &&(1) \\
& y_{i a t}=z_{i a t}+\epsilon_{i a t} &&(2) \\
& z_{i a t}=\rho z_{i, a-1, t-1}+\eta_{i a t} &&(3)
\end{aligned}
$$
こ こ で、$${\widetilde{y_{i a t}}}$$は、個人$${i}$$の年齢$${a}$$歳、時点$${t}$$年での所得の対数値、$${x_{i a t}}$$は年齢などの観測可能で外生的な個人属性変数のベクトル、$${\delta_t}$$は年固定効果、$${y_{i a t}}$$は残差項である。 $${y_{i a t}}$$は2つの項$${z_{i a t}、\epsilon_{i a t}}$$からなる。$${z_{i a t}}$$は1次の自己回帰AR (1) 過程に従う。$${\eta_{i a t}}$$と$${\epsilon_{i a t}}$$は独立で同一(i.i.d.)な正規分布$${N\left(0, \sigma_\eta^2\right) 、 N\left(0, \sigma_\epsilon^2\right)}$$にそれぞれ従う外生的な所得ショックである。$${z_{i a t}}$$のイノベーションである$${\eta_{i a t}}$$は持続的な(persistent)所得ショック、$${\epsilon_{i a t}}$$は一時的な(transitory)所得ショックと呼ばれる。
持続性が異なるこれら2種類の所得ショックを考慮することは、所得データの分散・共分散構造を説明するためであるとともに、基本的な消費理論である恒常所得仮説・ライフサイクルモデルで、所得ショックの持続性に応じて消費の反応度合いが異なることが示唆されるため、重要である。実証分析では$${z_{i a t}}$$の自己相関係数$${\rho}$$は1に近い値で推定されることが多い。そこで実際の研究では、$${\rho = 1}$$を仮定して、所得リスクのパラメータ$${\sigma_{\eta}}$$、$${\sigma_{\epsilon}}$$の推定に集中することも多い。このモデルで、$${\rho = 1}$$を仮定すると、1期間の所得変化率は、$${\Delta y_{i a t} = y_{i a t} - y_{i, a - 1,t - 1} = \eta_{i a t} + \Delta \epsilon_{i a t}}$$となる。この式からも、所得変化率の分布の情報は所得ショックの分布の推定に重要な役割を果たすことがわかる。
この基本モデルは研究の目的やデータの特性に応じてさまざまに拡張されてきたが、ここでは非正規性、非線形性、パラメータの異質性を考慮するためにGuvenen et al.(2021)が提案したモデルを紹介しよう[7]。Guvenen et al. (2021) は、まず所得のレベルを変化させる雇用ショック$${\nu_{i a t}}$$を導入する。具体的には、所得のレベルを$${\widetilde{Y_{i a t}}}$$とし、指数をとった (1) 式と雇用ショック$${\nu_{i a t}}$$を用いて、以下のように表す。
$$
\widetilde{Y_{i a t}} = \left( 1 - \nu_{i a t} \right)e^{x_{i a t}^{\prime}\gamma + \delta_{t} + y_{\text{iat}}}
$$
[7] 所得動学モデルの近年の研究動向については、たとえば、Altonji et al.(2022)によくまとめられている。
雇用ショック$${\nu_{i a t}}$$により、所得が一定割合減少する確率は、年齢$${a}$$と$${z_{i a t}}$$に依存すると仮定する。次に、(2) 式に個人固定効果項$${\alpha_{i}}$$、年齢による成長率の個人間異質性$${\beta_{i} \times a}$$を加えて
$$
y_{i a t} = \alpha_{i} + \beta_{i} \times a + \eta_{i a t} + \epsilon_{i a t}
$$
とした。ここで、$${\alpha_{i}}$$と$${\beta_{i}}$$は所得のレベルと成長率における異質性を説明するものであり、2変量正規分布に従うと仮定する [8]。さらに、所得変化率の非正規性を説明するため、所得ショック$${\eta_{iat}}$$と$${\epsilon_{iat}}$$ がそれぞれ異なる混合正規分布に従うと仮定した。Guvenen et al.(2021)は、この拡張したモデルを、所得変化率の分布やインパルス応答関数のモーメントなどを用いたシミュレーション積率法(method of simulated moments)で推定し、上記の拡張の中でも、特に雇用ショック$${\nu_{i a t}}$$の導入がデータを説明するために重要であることを示した。
[8] 所得成長率のバラツキを表す$${\beta_{i}}$$を考慮するモデルは、Heterogeneous Income Profiles (HIP) モデルと呼ばれ、たとえば、$${\sigma_{\eta}}$$、$${\sigma_{\epsilon}}$$が年齢とともに変化する場合、その識別には長期間の所得の自己共分散の情報が必要であることが指摘されている。通常のサーベイデータでは、各参加者の調査期間が短いことが多く、また調査期間中での参加者の脱落が起こりうるため、HIPモデルの推定には懸念があった。したがって、長期間のパネル構造を持ち、サンプルの内生的な脱落が起こらない行政データは、HIPモデルの識別と推定においても非常に重要である。HIPモデルの詳細については、Guvenen (2009) やHoffmann (2019) を参照。
行政データの活用により、正規分布の制約を置かずにさまざまな非線形性とパラメータの異質性を考慮した所得動学モデルの分析が進んでいる。 Guvenen et al. (2021) が雇用ショックの重要性を示したことにも関連するが、所得変動のパターンの理解をさらに進めるため、雇用と賃金の変化がどのようにその後の所得に影響を与えるのかについても、分析が蓄積されてきている。さらに、複雑な所得ショックが個人や家計の行動や厚生にどのような影響を与えるのかも重要な研究課題である。次項で紹介するDe Nardi et al.(2020)のように、拡張した所得プロセスをマクロ経済モデルに導入する試みも進んでいる。
3.2 行政データを活用した政策研究
行政データは個人や企業の経済活動に関するミクロの情報であるが、ミクロデータは近年のマクロ経済研究や政策効果の分析にも不可欠な要素となっており、自治体税務データの潜在的な有用性は計り知れない。1990年代には家計や企業の動学的最適化問題に(前掲のモデルよりはるかにシンプルであるが)所得リスクを組み込んだモデルが開発され、その後、所得や資産格差の説明を試みる数多くの研究が蓄積され、税や社会保障など再分配に関わる政策効果への理解が進んだ。
現在では、Imrohoroğlu (1989) やAiyagari (1994) などといった初期の研究で使われた、AR(1) 過程などのシンプルではあるが強い仮定に基づいて推定された所得プロセスだけでは、比較的大きな分散や高い慣性を仮定しても、実際のデータでみられるような富の集中や格差の動向を捉えきれないことが知られている。
豊かな行政データを使うことで、個人の所得プロセスは非常に複雑であり、シンプルなモデルでは説明しがたいことが明らかとなってきた。われわれが消費や貯蓄を決める際には、所得がこれからどう変化していくかは重要な情報であるし、リスクをどうモデル化するかによって、再分配に関わる政策効果の検証や反実仮想実験の分析結果も大きく変化する。そこで、ここでは先に挙げた GRIDプロジェクトの中から所得格差や政策分析に 関 わ る 分 析 の 例 と し て、Hoffmann et al. (2022) およびHalvorsen et al. (2022) によるイタリアとノルウェーの行政データを使った研究を紹介しよう。
Hoffmann et al. (2022) は、1985年から2016年までのイタリア国立社会保障研究所の行政データを使って格差動向を分析している。社会保険関連費用の計算を目的として雇用主である企業からの提供が義務付けられた所得データで、自営業者や公共部門の所得データは欠如しているが、職種や産業、雇用契約期間や離職理由、また社会保険費用の計算に必要となる労働時間(パートタイム、フルタイム)、勤務週数などの情報が利用可能で、年収や総所得データのみが入手可能なことが多い他国の行政データに比べた強みがある。
過去30年あまりの間に所得格差・リスクともに大きく上昇した一方で、所得階層の移動(mobility)には目立った変化はない。データをさらに精査すると、格差の拡大は低所得層の所得低下によって、また所得リスクの増大は2000年以降に働き始めた人々の雇用と所得動向によって説明されることが明らかとなった。
さらにHoffmann et al. (2022) は、こうしたトレンドの背景には、1990年代に施行された一連の労働市場改革があると指摘する。若者や女性を中心とした慢性的な高失業率に対処するために、パートタイムや有期契約の労働者の雇用が容易となる改革が行われ、欧州でも際立って硬直的であった労働市場は、少なくとも新規の雇用者に関しては最もフレキシブルな労働市場へと変化した。その結果、新規採用に占める有期雇用者の割合が急増し、失職率も大幅に上昇した。よりフレキシブルな市場で職を得やすくすることで、キャリア形成を促すことが期待された改革ではあったが、コホートごとの所得推移を検証した結果、10年近く経過した後も安定した仕事への移行や人的資本形成の増進は見られず、一時的な仕事が ”Stepping stone” として機能していないことを示している。
Halvorsen et al. (2022) は、ノルウェーの全国民をカバーする1967年から2017年の人口統計を用いて所得リスクを推定している。このデータには、年金計算のベースとなる賃金・自営業所得のほか、失業保険、病気・育児休業に関わる給付などの所得移転のデータも含まれている。1993年以降、この統計には家計の資産データも加わり、これらすべてが研究に活用されている。さらに、各個人に付与されているIDに基づいて親子関係の識別も可能となっており、世代間の所得のつながりを詳細に分析することができる。
世代間の所得には統計的に有意な相関が確認され、父親の生涯所得が10%上がると、息子(娘)の生涯所得は2.4%(2.3%)高くなる。さらに、父親と子供の所得の変化率にも強い相関がみられ、父親の所得成長率が5%上昇すると、息子(娘)の所得成長率は1%(0.8%)高くなる。これらの事実は、世代を超えた格差の連鎖を理解するには、親子の所得水準だけではなく、生涯を通じた変化を捉えるのが重要であることを示している。
さらにHalvorsen et al. (2022) は、子供の直面する所得リスクが親の生涯所得とどう関係するかについても分析しており、たとえば、トップ1%の所得を持つ父親の子供の所得リスク(所得成長率の90・10パーセンタイル比で計測)は、所得中位層の父親の子供に比べて15%程度高い。つまり、高所得の家庭で育つ子供は、所得の水準や成長率が高いだけでなく、リスクの高い仕事に就いているということである。加えて、父親と子供の所得リスクは強く相関している。
このように、豊富なデータを分析に活用できることで、所得格差の背景の解像度が格段に増す。格差を是正したければ、どのような政策が望ましいのか、また政策によってどのような効果が期待できるのか、データを精査しないことにはまったく誤った方向に突き進んでしまいかねない。
GRIDプロジェクトのように行政データに限定した研究以外にも、サーベイデータと行政データとを組み合わせることで、個人のみならず世帯単位での所得リスクを分析したり、所得税以外の政策効果を検証したりする研究もある。De Nardi et al. (2020) は、イギリスの行政データである「New Earnings Survey Panel Dataset」の個人所得データと、世帯調査である「British Household Panel Survey」を使って所得リスクを推定し、公的な所得支援や就労支援給付の効果を分析している。そして、より精緻な所得リスクの推定結果に基づいて、所得移転制度の効果を分析すると、最適な移転の水準や、所得に応じた逓減率といった数値も変化することを示している。
行政データは課税単位となる個人の所得を精緻に追跡することはできても、サーベイデータに通常含まれている婚姻関係や家族構成などの世帯の状況、学歴、雇用形態といった、実証分析や構造モデルの構築において伴となる変数が欠落している場合が多い。所得税や年金の算出には個人の所得情報で十分であっても、世帯の状況に依存する政策の効果を分析したり、個人や世帯の貯蓄や労働供給といった行動を説明したりするには、サーベイデータの情報が欠かせない。巨大な行政データが入手できるようになれば今まで活用してきたサーベイデータが不要になる、というわけではなく、双方の優れた点を補完的に組み合わせて研究を発展させていくことが期待される。
4. 自治体税務データに見る所得格差とリスク
4.1 自治体税務データを使ってみる
それでは、日本の自治体税務データを使って、日本の所得格差と所得リスクの性質について見ていこう。筆者らは現在、約20市区町村のデータ分析を行っているが、紙幅の都合からすべての自治体の結果を見せるのは難しいため、ここでは東京都から1つ(人口約40万人)、地方からサンプル期間が長い市区町村1つ(人口約1.4万人)の自治体を選んで紹介しよう。
さまざまな所得控除に関する情報なども含まれているデータであるが、今回は”給与収入一般” のみに絞った分析を紹介する。自治体税務データでは、サンプル期間は自治体によって異なっている。これは、過去5年間の所得データについては保管が義務付けられているものの、それを超える期間への対応は自治体によって異なるためである。
そのため、自治体によって最短で2016〜2021年の 6年間、最長で2011〜2021年の11年間とバラツキがある。また、自治体によっては50%のランダム・サンプリングを行っているため、それぞれの市区町村における総人口全体、あるいは約50%をカバーするというデータセットになっている [9]。ただし、この中には扶養されている子供や引退している高齢者も含まれるため、大量の所得ゼロの者が存在している。先行研究に従って、ここでは給与所得にフォーカスするため、25〜59歳の男性サンプルに絞った(退職金の可能性を考慮して60 歳はデータから除いた)。
[9] 同じくプライバシー保護の観点から、自治体によっては所得トップ層に対してトップコーディングを施している自治体もある。詳細は 本プロジェクトの自治体向けホームページ を参照してほしい。
4.2 時系列方向からの分析:暫定結果
結果の紹介に入る前に、ここでの結果はまだ暫定的なものである点を強調しておきたい。図1は 2つの自治体の平均給与を並べたものである。横軸は実際に給与を得た年であり、住民税を支払った年ではない点に注意してほしい。平均給与は、おおむね右肩上がりで増えている。コロナ前の 2019年までは持続的な景気回復が続いていたことを考えれば、この点は驚きではない。

しかし、コロナショックの影響は自治体によって異なることがわかる。東京都の自治体の男性平均給与が2020年のコロナショック後に12万円程度低下しているのに対して、もう1つの地方の自治体ではそのような低下は見られない。
図2は同じ2つの自治体における給与のバラツキを測ったものである。格差の指標としてジニ係数を用いた。まず顕著な傾向として、どちらも期間を通じておおむね右下がりである。すなわち給与格差は緩やかな縮小傾向にある。もちろんデータ期間が短いことから、この傾向がたまたまこの約10年間の傾向なのか、それともより長期間のトレンドなのかについてはさらなる分析が必要である。ただし、東京都の自治体ではコロナショック後に平均給与が下がり、格差が少し上昇している点は見逃してはいけない。

日本ではどんどん経済格差が拡大しているという印象を抱いている人もいるかもしれない。しかし、アメリカと異なり、先行研究によると日本では足元の20年で格差が急激に拡大したという証拠は今のところはみつかっていない[10]。自治体税務データでも、期間は短いもののそうした先行研究と同様の結果が得られた[11]。従来のサーベイデータでは市区町村単位で格差のトレンドの違いを把握することは、サンプルサイズの問題から非常に困難であった。地方自治体によるきめ細かい政策決定に役立てるためにも、こういったデータはより幅広く活用されるべきであろう。
[10] Lise et al. (2014) やKitao and Yamada (2019) を参照してほしい。もちろんジニ係数で測った経済格差は格差の一側面を表しているに過ぎないので、この指標が上昇していないから何も問題がないというわけではない。
[11] この結果は、注 [9] で述べた通り、トップコーディングされた25~59歳男性に限定したものであり、それ以外の格差の側面に関しては、これからさらに分析を進める必要がある。
4.3 日本の所得格差と所得リスク:暫定結果
次に、所得格差とリスクの分析例を紹介しよう。以下では先ほどの東京都の自治体のみに注目し、 2015〜2021年の給与収入(以下「所得」)データを利用する。
図3は5歳年齢階級別の就業率(年間所得18万円以上の人の割合)を示している。プロファイルはきれいな山型で、50代後半以降に労働市場からの退出が増える。就業率は高齢層を中心に上昇傾向にあり、2015年から2021年にかけて、男性60代の平均就業率は65.5%から72.1%に上昇している。

図4は2021年の所得について、年齢階級内におけるパーセンタイルごとの所得の値を示している。年齢が上がるにつれてグラフの間隔が広がり、所得格差は拡大していることがわかる。
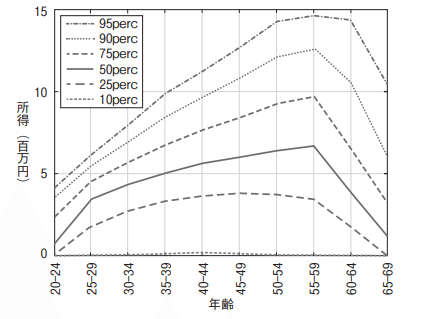
図5は年齢階級別のジニ係数を示しており、 2015年以降年齢ごとのパターンは同じような形状をしているが、格差の水準にはやや変化があり、多くの年齢において低下傾向にある。

こうしたクロスセクションでみた所得格差は、個人が直面する「リスク」について多くを語るものではない。各年齢で見られる所得の違いは、固定的なものかもしれないし、あるいは毎年個人の所得が大きく変動しているせいかもしれない。
本自治体税務データはパネルデータであることから、クロスセクションの分布だけではなく、各個人の所得成長率がどのような分布をしていて、生涯を通じて所得がどのように変化するかについても分析することができる。図6は25~59歳男性の所得$${y_{t}}$$の変化率$${\Delta \log y_{t}}$$の分布を棒グラフで示している。なお、計算では年齢の影響や年固定効果を取り除いている。
この分布における分散は0.078、標準偏差は 0.28と高い数字を示している。仮に、図6の曲線で示すように、所得成長率が正規分布に従うとすれば、平均的な男性は毎期30%程度の所得変動に直面しているということになる。しかし、実際の分布の形状は正規分布とは大きく異なり、多くのデータはゼロ周辺に集中しており、所得は非常に高い確率で前期とあまり変わらない水準を維持することがわかる。また、分布の裾が両側に非常に細く長く広がっており、ごく低い確率で大きなショックに直面することを示している。正規分布においては3である尖度が32.1という高い値をとっていることと整合的である。また、歪度は負の値で、右の裾に対して左の裾が厚くなっている。

また、ここでは詳細な説明を省くが、所得成長率の分散や歪度といった高次のモーメントの値は所得パーセンタイルごとに大きく異なっており、所得水準の上昇とともに所得変動リスクは減少する傾向が確認されている。
次に、年齢階級別の所得リスクを見てみよう。対数化した所得を前期の所得に回帰したAR(1) 過程はAiyagari (1994) をはじめ、多くの研究において所得リスクを捉えるモデルとして使われてきた。25〜59歳男性の年収(年間所得)をプールして回帰式を推定すると、自己相関係数は0.87、残差の分散は0.091となる。しかしこの推定を年齢別に行うと、図7で示すように、若年層と中高年では慣性パラメータ(左図)や分散(右図)の値は大きく異なり、若いときのショックは高齢者に比べてバラツキが大きい一方、ショックの効果はあまり長く続かないことがわかる。

このように、データが豊富にあることで、所得リスクの実態を各個人の属性ごとにより精緻に把握することができる。前節でも解説したように、こうした分析によって格差構造をより深く理解することができ、政策設計にも役立てることができるのである。
参考文献
アトキンソン、アンソニー・B.(2015)『21世紀の不平等』山形浩生・森本正史訳、東洋経済新報社。
ピケティ、トマ(2014)『21世紀の資本』山形浩生・守岡桜・森本正史訳、みすず書房。
ピケティ、トマ(2016)『格差と再分配——20世紀フランスの資本』山本知子他訳、早川書房。
Aiyagari, R. (1994) “Uninsured Idiosyncratic Risk and Aggregate Saving,” Quarterly Journal of Economics, 109 (3): 659-684.
Altonji, J. G., Hynsjö, D. M. and Vidangos, I. (2022) “Individual Earnings and Family Income: Dynamics and Distribution,” Review of Economic Dynamics, in press.
De Nardi, M., Fella, G. and Paz-Pardo, G. (2020) “Wage Risk and Government and Spousal Insurance,” NBER Working Paper, 28294.
Guvenen, F. (2009) “An Empirical Investigation of Labor Income Processes,” Review of Economic Dynamics, 12 (1): 58-79.
Guvenen, F., Karahan, F., Ozkan, S. and Song, J. (2021) “What Do Data on Millions of U.S. Workers Reveal about Lifecycle Earnings Dynamics?” Econometrica, 89(5): 2303-2339.
Halvorsen, E., Ozkan, S. and Salgado, S. (2022) “Earnings Dynamics and Its Intergenerational Transmission: Evidence from Norway,” Quantitative Economics, 13 (4): 1707-1746.
Hoffmann, F. (2019) “HIP, RIP, and the Robustness of Empirical Earnings, Processes,” Quantitative Economics, 10(3): 1279-1315.
Hoffmann, E. B., Malacrino, D. and Pistaferri, L. (2022) “Earnings Dynamics and Labor Market Reforms: The Italian Case,” Quantitative Economics, 13(4): 1637-1667.
Imrohoroğlu, A. (1989) “Cost of Business Cycles with Indivisibilities and Liquidity Constraints,” Journal of Political Economy, 97(6): 1364-1383.
Kitao, S. and Yamada, T. (2019) “Dimensions of Inequality in Japan: Distributions of Earnings, Income and Wealth between 1984 and 2014,” RIETI Discussion Paper Series, 19-E-034.
Lise, J., Sudo, N., Suzuki, M., Yamada, K. and Yamada, T. (2014) “Wage, Income and Consumption Inequality in Japan, 1981-2008: from Boom to Lost Decades,”Review of Economic Dynamics, 17(4): 582-612.
「自治体税務データ活用プロジェクト」の最新情報については、以下の文部科学省科学研究費補助金学術変革領域研究 (B)「税務データを中心とする自治体業務データの学術利用基盤整備と経済分析への活用」のウェブサイトをご覧ください!

*本稿は、『経済セミナー』2023年6・7月号からの転載です。
サポートに限らず、どんなリアクションでも大変ありがたく思います。リクエスト等々もぜひお送りいただけたら幸いです。本誌とあわあせて、今後もコンテンツ充実に努めて参りますので、どうぞよろしくお願い申し上げます。