【AI】kaggle : Titanic

Kaggle Titanic の忘備録
はじめに
kaggle Titanic は機械学習の初心者向けのデータ解析コンペティション
いろいろなTutorialがあるのでそれらを参考にPredictionのSubmitまでの一連の流れを行ってみる
EDA
まずはKaggleのデータページから学習用のデータをダウンロードする。
データの概要確認
まずは使用するデータの内容の確認を行ってみます。
head()を使いデータの構成を確認します
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
df = pd.read_csv('/content/drive/MyDrive/Kaggle/Titanic/train.csv')
df.head()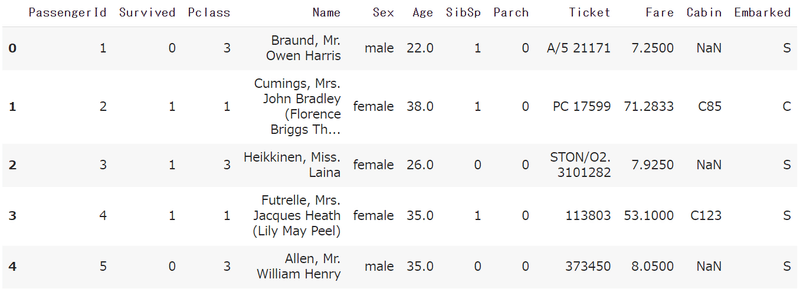
データとして含まれるのは以下
PassengerId – 乗客識別ユニークID
Survived – 生存フラグ(0=死亡、1=生存)
Pclass – チケットクラス
Name – 乗客の名前
Sex – 性別(male=男性、female=女性)
Age – 年齢
SibSp – タイタニックに同乗している兄弟/配偶者の数
parch – タイタニックに同乗している親/子供の数
ticket – チケット番号
fare – 料金
cabin – 客室番号
Embarked – 出港地(タイタニックへ乗った港)
次にdtypesを使い各列のデータ型を確認します。
int64/object/floatが混在しているのでデータ型を後ほどそろえる必要があります。
df.dtypes
今の段階で見れる統計量も表示してみます。
数値的に直感をもてるのはAgeぐらいでしょうか。
df.describe()
欠損値の処理
各列ごとに欠損値が含まれるか確認をします。
AgeとCabinに欠損値が含まれています。
df.isnull().sum()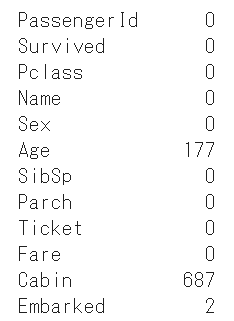
Ageの欠損値の補完を行います。
データのばらつきを見るためヒストグラムを表示します。
df["Age"].hist(figsize = (4,4))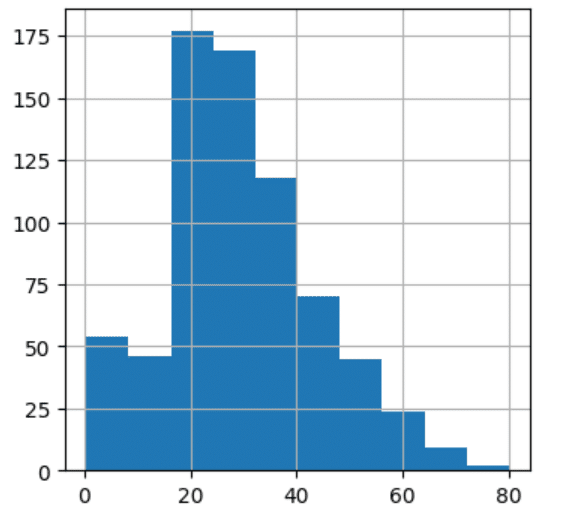
大きな外れ値はありませんので欠損値は平均値補完で行います。
sklearnのfit_transformを使用して補完を行います。
from sklearn.impute import SimpleImputer
df["Age"] = SimpleImputer().fit_transform(df.iloc[:,[df.columns.get_loc("Age")]])
df.isnull().sum()
df["Age"].hist(figsize = (4,4))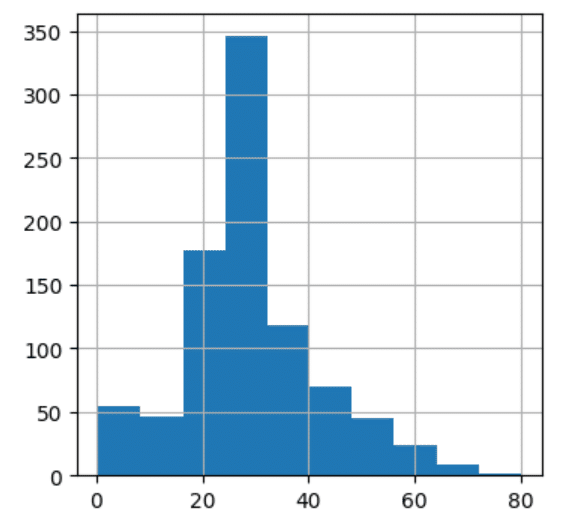
次にEmbardedの補完を行います。
欠損は二つだけなのでSで補完します。
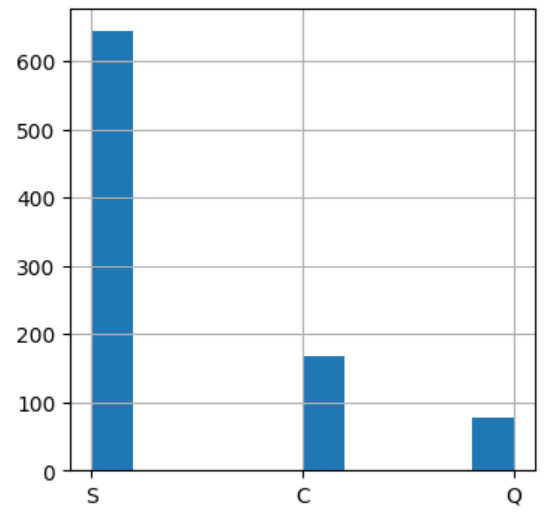
df['Embarked'] = df['Embarked'].fillna('S')Cabinの中身を見ると欠損が多いため今回は不要なデータとして除外します。(891データに対して697の欠損のため)
それ以外に個人の特定にのみ紐づくName, PassengerID, Ticketも除外します
df = df.drop(['Cabin', 'Name', 'PassengerId', 'Ticket'], axis=1)Object型の SexとEmbarkedをカテゴリ変数に変換します。
df['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0)
df['Embarked'] = df['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int)
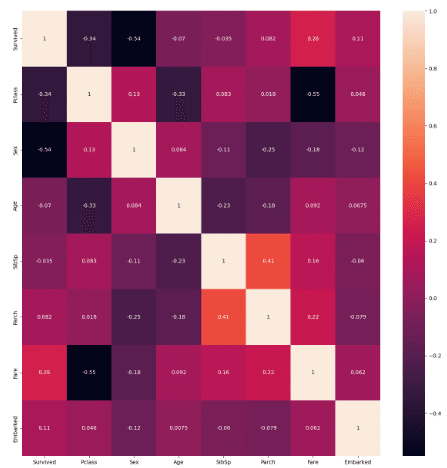
この状態でヒートマップを見てみます
Survivedとの相関が強いのがFareあたり。
訓練データと評価データに分割します
from sklearn.model_selection import train_test_split
X = df.drop('Survived', axis=1)
Y = df.Survived
(train_X , test_X , train_Y , test_Y) = train_test_split(X, Y , test_size = 0.3 , random_state = 0)学習コードの実装
ランダムフォレストを使用して学習をおこないます。
skleranが関数を用意していますのでそのまま使います。
RandomForestClassifer : ランダムフォレストのモデル
roc_curve : ROC曲線を作成する関数
auc : ROC AUCスコアの算出
accuracy_score : 正解率の算出
precision_score : 適合率の算出
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (roc_curve , auc ,accuracy_score)
clf = RandomForestClassifier(n_estimators = 12,max_depth=10,random_state = 0)
clf = clf.fit(train_X , train_Y)
pred = clf.predict(test_X)
fpr, tpr , thresholds = roc_curve(test_Y,pred,pos_label = 1)
auc(fpr,tpr)
print(accuracy_score(pred,test_Y))
print(precision_score(pred, test_Y))正解率:0.8432835820895522
適合率:0.7
ハイパーパラメータの調整で正解率は80-84ほどで推移します
提出用モデルの作成
提供されているtest dataを使って提出用のモデル作成を行います。
from sklearn.impute import SimpleImputer
passsengerid = testDf['PassengerId']
testDf["Age"] = SimpleImputer().fit_transform(testDf.iloc[:,[testDf.columns.get_loc("Age")]])
testDf["Fare"] = SimpleImputer().fit_transform(testDf.iloc[:,[testDf.columns.get_loc("Fare")]])
testDf['Embarked'] = testDf['Embarked'].fillna('S')
testDf['Sex'] = testDf['Sex'].apply(lambda x: 1 if x == 'male' else 0)
testDf['Embarked'] = testDf['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int)
testDf= testDf.drop(['Cabin','Name','Ticket','PassengerId'],axis =1)
pred = clf.bs.predict(testDf)
submission = pd.DataFrame({'PassengerId':passsengerid, 'Survived':pred})
submission.to_csv('/content/drive/MyDrive/Kaggle/Titanic/submission.csv' , index = False)おわりに
Kaggleの入門として使われるTitanic。
BoarderのTopは1.00のScoreということでこの課題に対していろいろと試行錯誤してみると楽しそうです。
EDAの部分がやはり大事なようですね。
https://www.kaggle.com/competitions/titanic/leaderboard
この記事が気に入ったらサポートをしてみませんか?