
Pythonで学ぶExcelデータ処理

はじめに
このnoteでは、AI AcademyなどでPythonの入門は学んだけど、実際に業務で活用したい!という方への記事です。
このnoteでは主にExcelを普段扱っている方がPythonでも同様にデータ処理をしたい!という方に向けて書いております。内容は基本的な事を扱いますが、業務で扱える部分あるかもしれないので是非参考にしてみてください。
PythonでExcelを扱うために
PythonでExcelを扱うには、PandasかOpenpyxlがあります。
このnoteではデータ分析でも用いられるPandasを利用していきます。
Pandasのインストール
Pandasをインストールするには次のコマンドをターミナル(Macの方)、WindowsではコマンドプロンプトやWindows PowerShellをご利用ください。
※お使いのPCにPython3.7系がインストールされている前提です。
pip install pandas
Pandasを利用する
以上のコマンドを実行するとPandasがインストールされます。
Pandasを使うには次のようにします。
import pandas as pdPandasでExcelファイルを読み込む
では実際に、Excelファイル(.xlsx)を読み込みましょう。
今回読み込むExcelファイルは次のようなファイルです。
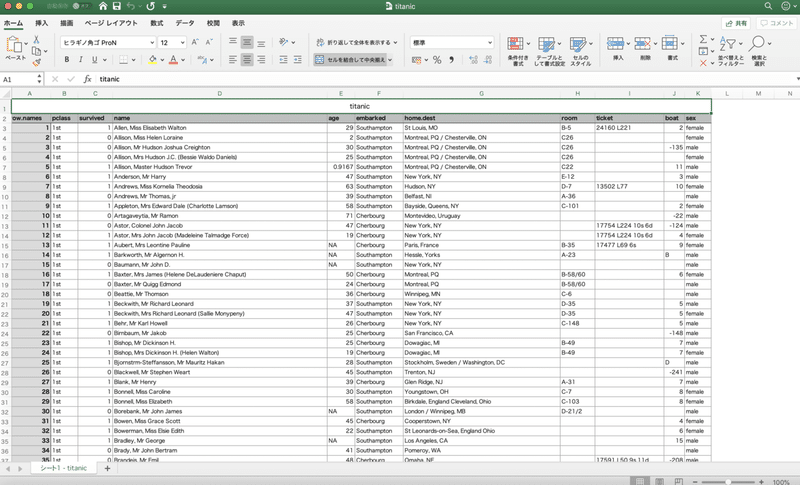
PandasでExcelファイル(.xlsx)を読み込む場合は、read_excel()を利用します。
下記で読み込んでいるデータはこちらのデータをExcelファイルに書き出したものです。
import pandas as pd
df = pd.read_excel("titanic.xlsx", header=1)
df.head()read_excel()にはいくつか引数を渡すことが出来ます。
読み込むシートを番号・シート名で指定: 引数sheet_name
ヘッダー、インデックスを指定: 引数header, index_col
引用元
今回header=1としているのは、1行目から読み込んでいます。
Jupyter Notebookで読み込むと次のようになります。
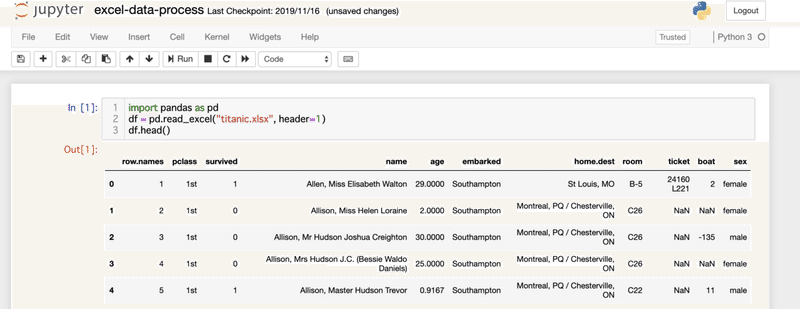
上記のコードでdfという変数名をつけているのは、Pandasのread_excel()を用いると、変数のデータ型がDataFrameという型になるのですが、そのDataFrameの単語の頭文字dとfから名付けています。
(よくこの変数名で命名されることが多いです。)
データの欠損値を集計する
ではまず始めにデータの欠損値を集計してみましょう。
先ほどのコードの続きです。
df.isnull().sum()コードを実行すると次のような出力になります。
row.names 0
pclass 0
survived 0
name 0
age 680
embarked 492
home.dest 559
room 1236
ticket 1244
boat 966
sex 0
dtype: int64
これは各列名(カラム名)に対して、欠損値(データがないこと)の数を集計しています。
左側のrow.namesやpclassは0となっていますが、これは欠損値がない事を表しています。対してageやembarkedは680や492という数値が表示されています。これらの数値はその数値分データが欠損している事を表しています。
各カラム毎(列毎)の値の件数を集計する
次に、各カラム毎に含まれるデータの件数がそれぞれ何件あるのか調べてみましょう。
文章だけですとイメージがつきにくいため、次のコードを実行してみてください。
df["embarked"].value_counts()実行結果は次のようになります。
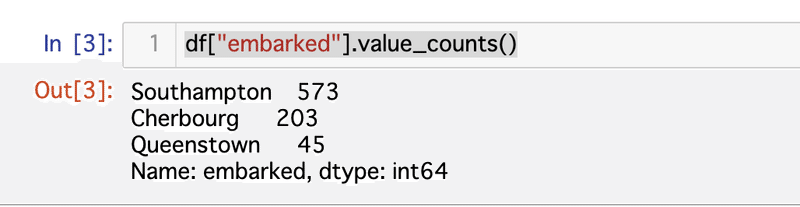
embarkedというカラムには『Southampton』、『Cherbourg』、『Queenstown』の3つのデータがあり、それぞれがこの列全体で何件ずつ存在しているのかを一瞬で集計してくれます。
Southampton 573
Cherbourg 203
Queenstown 45
またPythonにはseabornという可視化ツールもあり、これを使うと次のようなグラフを簡単に描けます。
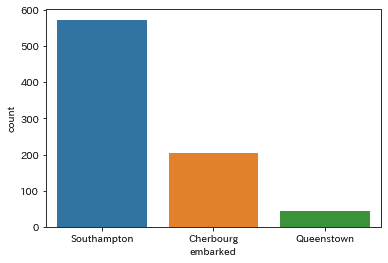
インストールは次のようにします。
pip install seabornコードは次のように書きます。
import seaborn as sns
sns.countplot(df["embarked"])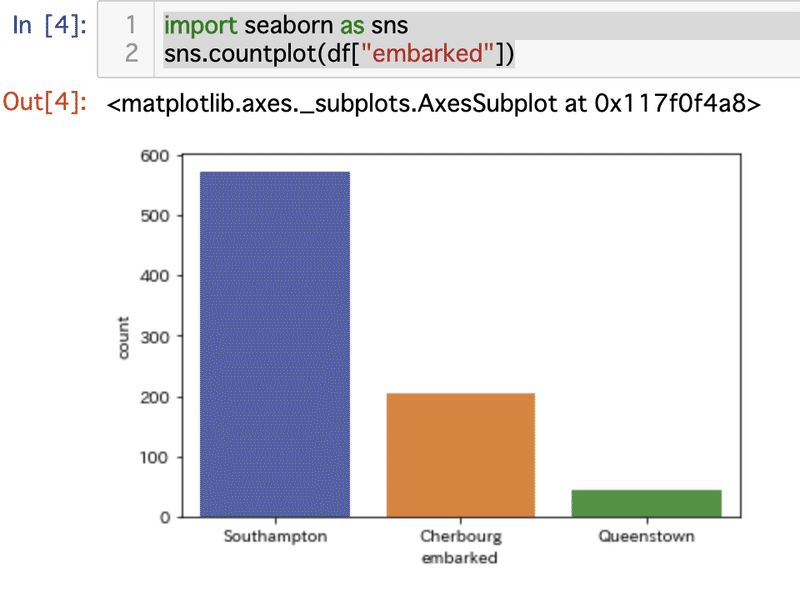
基本統計量を算出する
次に、読み込んだデータの中から数値データに対して、基本統計量を算出してみます。基本統計量は、最小値や平均、標準偏差などのいくつかの数値で表されます。
describe()を用いると、様々な統計量を算出してくれます。
df.describe()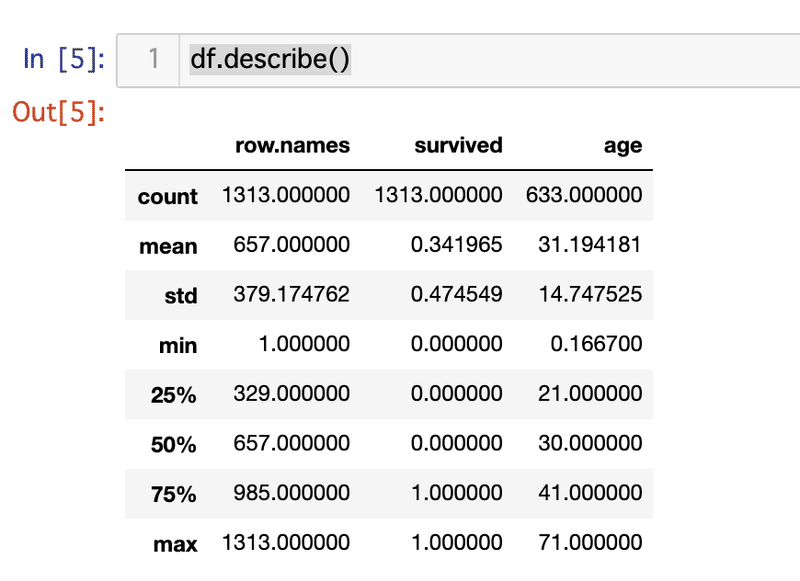
countはデータの行数で、meanは平均値、stdは標準偏差、minは最小値、25%は第一四分位数、50%は第二四分位数、75%は第三四分位数は、maxは最大値となります。
もっとPythonを学ぶなら
AI Academy BootcampのPythonコースでは、本日学んだような内容に比べ、統計学の基礎(分散や標準偏差、四分位数、相関係数など)や、Webスクレイピング入門や自動化ツールの作成などを1ヶ月で学びます。
(1ヶ月8時間の講義+課題+Slackを用いた質問し放題が出来て5 万円(税込)で受講可能です。)
動画受講やオンラインマンツーマン受講も出来ますので、是非検討してみてください!(毎月少人数4人程しか募集していないので申し込みはお早めに)
この記事が気に入ったらサポートをしてみませんか?