
【Python】製造業コミュニティのTwitter botくんのツイート分析(^^)/

こんにちは(@t_kun_kamakiri)
数か月前から運用しているPythonで作ったbotくんがありまして・・
Googleスプレッドシートに書き込んだ内容をランダムにツイートするといった完全自作のbotくんなのです。
Pythonでのbotくんの作り方を知りたい方はこちらをどうぞ。
さて、本日はこのbotくんのTwitter分析をしたいと思います。
現在100ツイートくらい登録しているのですが、同じツイートが何回もツイートされていて、どのツイートがウケがいいのかを分析したことがありませんでした。
着眼点はフォロワーに直結する「プロフィールクリック率」ですね。
今回使用するデータは↓こちらです。
データを取得
まずはTwitterのアナリティクスからデータを取得します。
2021年1月1日から運用しているので3か月分のデータを取得しましょう。
●2021年1月
●2021年2月
●2021年3月

Pythonでデータ分析
では取得したデータをPythonで分析していきます。
インタラクティブに分析結果を確認するためにjupyter labを使用しています。
ファイル構成は以下のようになっています。
dataにTwitterアナリティクスのcsvファイルを保存しています。

まずはデータを読み込むために必要なライブラリをインポートし、csvファイルのリストを作成します。
import pandas as pd
import glob
csv_list = glob.glob(r'.\data\*csv')
csv_list
3か月分のcsvファイルが別々なので、csvファイルを読み込みながら行方向に結合します。
df = pd.DataFrame()
for csvfile in csv_list:
df_ = pd.read_csv(csvfile)
df = pd.concat([df, df_], axis=0)
dfこれで結合ができました。

不必要な行は削除しましょう。
df.columns
プロモーションなどはやっていないので不必要ですね。
data_list = ['ツイートID', 'ツイート本文', '時間', 'インプレッション', 'エンゲージメント',
'エンゲージメント率', 'リツイート', 'いいね', 'ユーザープロフィールクリック', 'URLクリック数',
'ハッシュタグクリック', '詳細クリック', 'メディアの再生数', 'メディアのエンゲージメント数']
len(data_list)df = df[data_list]
dfこれで必要な列だけとなりました。

カラム名が日本語だとmatplotlibで文字化けしてしまうので英語表記にしておきましょう。
data_list_columns = ['ID', 'text', 'date', 'impression', 'engagement',
'engagement_ratio', 'RT', 'fav', 'profile_click', 'URL_click',
'hashtag_click', 'detail_click', 'media_click', 'media_engagement']
df.columns = data_list_columns
df
プロフィールクリック数が多いツイートは?
今まででプロフィールクリック数が多いツイートを調べましょう。
df.sort_values('profile_click', ascending=False).head(30)
ふむふむ( ..)φメモメモ
世間では個の時代なんて言われることも多いけど、製造業のような大きな設備投資が必要な業界では組織に入らないと学べないことがとても多い。お金をもらいながら教育も経験ももらえるという意味で就職は最高の手段。個人で出来ることなんて働きながらでもいくらでも出来るから何も心配しなくていい。
このツイートが最もプロフィールクリック数が多いですね。
いいね数も見てみましょう。
df.sort_values('fav', ascending=False).head(30)
最もいいね数を得たツイート内容の結果は同じでした。
なるほど、これはとても参考になります。
ただ、このbotくんは同じツイートを何度もしているためたまたまこのツイートがバズっただけかもしれません。
複数回ツイートしたものは平均値をとった数字を表記するようにして公平さを持たせようと思います。
複数回のツイートの平均値を比較する
同じツイートに対してはgroupbyメソッドを使って簡単に平均値を求めることができます。
df_text = df.groupby('text', as_index=False).mean()
df_text.drop('ID', inplace=True, axis=1)
df_text
データを保存したいので現在までのパスとresultというcsvファイルを保存するためのディレクトリを用意します。
import os
path = os.getcwd()
result_csv = fr'{path}\result'
result_csvまずはプロフィールクリック数順に並べましょう。
※ついでにcsvファイルも出力します。
df_text.sort_values('profile_click', ascending=False).head(30).to_csv(fr'{result_csv}\20210101-20210331_profile_click.csv', index=False)
df_text.sort_values('profile_click', ascending=False).head(30)
この結果からツイキャスの告知がプロフィールクリック数上位に来ていることがわかります。
確かにツイキャスした後のフォロワー数増加は大きい!!
おーつながった('ω')
ついでにインプレッション数といいね数とRT数についても見てみましょう。
df_text.sort_values('impression', ascending=False).head(30).to_csv(fr'{result_csv}\20210101-20210331_profile_click.csv', index=False)
df_text.sort_values('impression', ascending=False).head(30)
インプレッション数が多いのもツイキャスの告知ですね。
いいね数はどうでしょうか。
df_text.sort_values('fav', ascending=False).head(30).to_csv(fr'{result_csv}\20210101-20210331_fav.csv', index=False)
df_text.sort_values('fav', ascending=False).head(30)
こちらのツイートがいいね数トップです。
1万時間の勉強、練習でその分野のエキスパートになるという「1万時間の法則」というものがある。
しかし、1,000時間でもそれなりにはなると思う。
自分の武器となる分野をどれにするかにもよるが、仮に3つの分野を極めようとすると、年間1,000時間の学習を「3年間」継続すれば良い
次にRT数。
df_text.sort_values('RT', ascending=False).head(30).to_csv(fr'{result_csv}\20210101-20210331_RT.csv', index=False)
df_text.sort_values('RT', ascending=False).head(30)
結果はいいね数と同じでしたね。
データの可視化
次にseabornを使ったデータの可視化を行います。
まず必要なライブラリをインポートします。
import seaborn as sns
import matplotlib.pyplot as plt相関係数を見るのにツイート内容は邪魔になるので削除します。
df_sns = df_text.drop('text', axis=1)
df_sns
相関図を見てみましょう。
ついでにimgディレクトリに画像として保存します。
img_file = rf'{path}\img'
sns.pairplot(df_sns).savefig(fr'{img_file}\pairplot.jpg')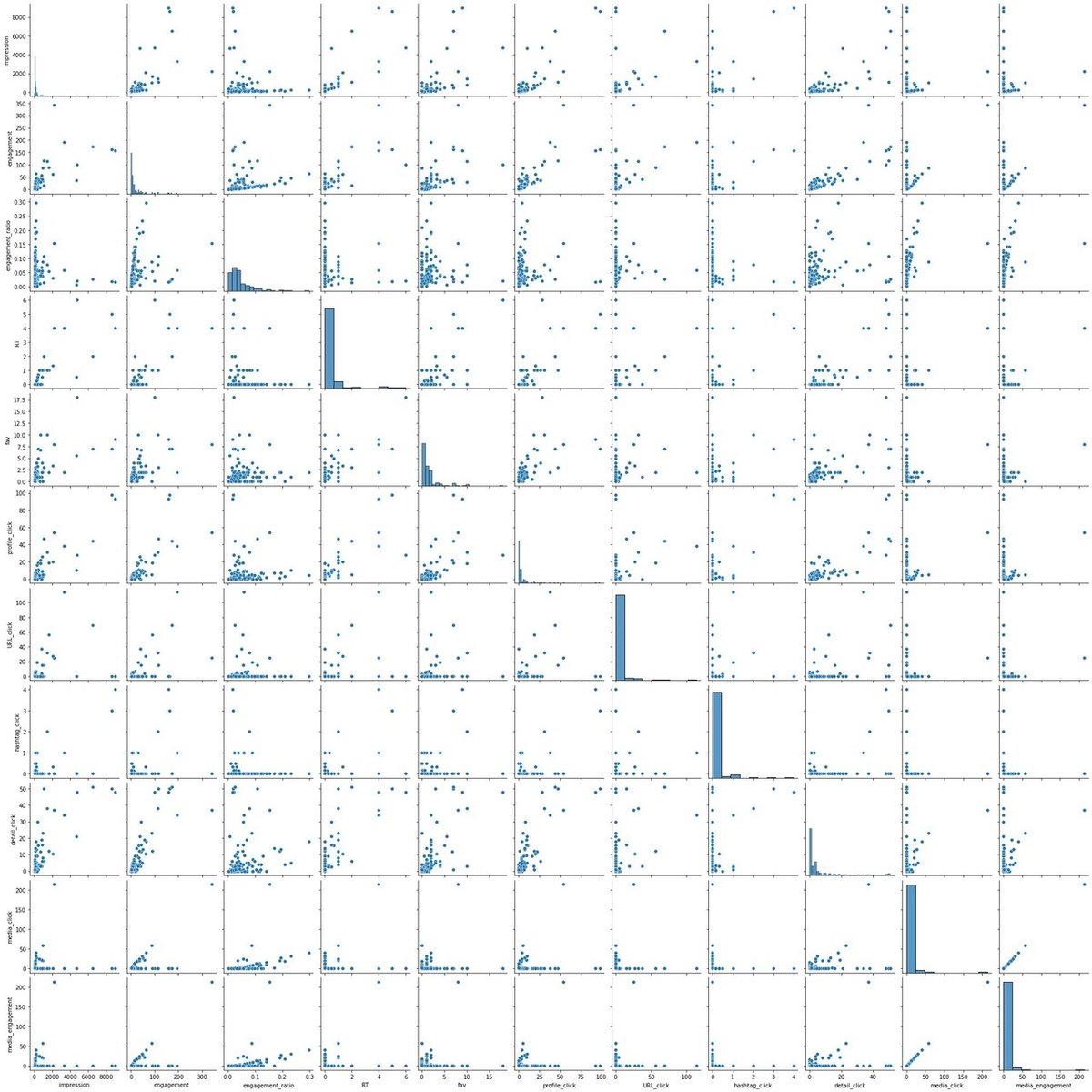
相関係数を見てみましょう。
df_corr = df_sns.corr()
df_corr
数字だけ見てもよくわかりませんね。
数字をマッピングしてみましょう。
plt.figure(figsize=(16,10))
sns.heatmap(df_corr, annot=True, cmap='Greens', center=df_corr.loc['profile_click', 'impression'])
プロフィールクリック数(profile_click)と何が相関が高いか確認すると、
●インプレッション数
●いいね数
●RT数
●ハッシュタグ
であることがわかります。
これらをグラフにしてみましょう。
sns.pairplot(df_sns, x_vars=["impression", "fav", "RT",'hashtag_click'], y_vars=["profile_click"],height=5, aspect=.8, kind="reg").savefig(fr'{img_file}\params_profile_click.jpg')
インプレッション数、いいね数、RT数、ハッシュタグクリック数が多い場合はデータの数が少ないですが傾向として右肩上がりですね。
1インプレッション数あたりのプロフィールクリック数
先ほどのデータの可視化からインプレッション数はプロフィールクリック数に影響があることがわかりましたが、1インプレッション数で多くのプロフィールクリック数を稼いでいるツイートがわかればどのツイートが効率よくプロフィールクリックに誘導できているのがわかります。
そこで新たな列として「プロフィールクリック数÷インプレッション数」を追加します。
df_text['profclick_per_imp'] = df_text['profile_click']/df_text['impression']
df_text
作成できました。
では「プロフィールクリック数÷インプレッション数」順に並び変えましょう。
df_text.sort_values('profclick_per_imp', ascending=False).head(30).to_csv(fr'{result_csv}\20210101-20210331_profclick_per_imp.csv', index=False)
df_text.sort_values('profclick_per_imp', ascending=False).head(30)
こちらのツイートがトップでした。
仕事が楽しいと思えたら人生イージーモードになる。
イージーモードになるためには読書をしよう!
2000円で偉人の話を聞ける!コスパがいい!
気に入った習慣を少しずつ取り入れていけば5年後にはイージーモードだ!
#新入社員
#若手社員
#製造業
ここで気になるのは「プロフィールクリック数」と「プロフィールクリック数÷インプレッション数」の相関係数ですよね。
df_sns = df_text.drop('text', axis=1)
df_corr = df_sns.corr()
# 相関関係
plt.figure(figsize=(16,10))
sns.heatmap(df_corr, annot=True)
「プロフィールクリック数」と「プロフィールクリック数÷インプレッション数」の相関係数は0.23でした。
相関係数0.23なので相関が低いということになります。
散布図を見てみましょう。
sns.lmplot(x='profclick_per_imp', y='profile_click', data=df_sns)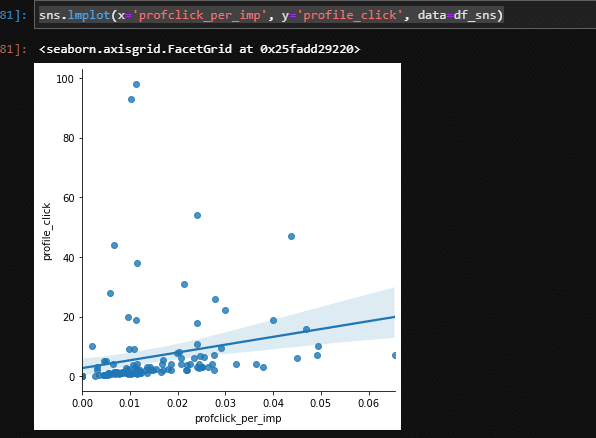
データとしてばらつきが大きいのがわかります。
確かにプロフィールクリック数はインプレッション数と相関があるため、「プロフィールクリック数」と「プロフィールクリック数÷インプレッション数」の関係性は一定値になるのではないかと考えられ有益な情報は得られないと考えられる。
まとめ
今回はbotくんのツイート分析を行いました。
プロフィールクリック数を稼ぐためにはツイキャスの告知が最も効果的であることがわかりました。
引き続きより良い分析方法やウケがいいツイートの分析を進めていきます。
今回のデータを使ってPythonの練習をしたい方は↓こちらをお使いください。
Pythonの勉強は↓こちらの参考書を使っています。
Twitter➡@t_kun_kamakiri
Instagram➡kamakiri1225
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス
コミュニティ➡製造業ブロガー
この記事が気に入ったらサポートをしてみませんか?