
【BigQuery】ZetaSQLのフォーマッタで失われたコメントを取り戻す

※本稿はテックブログからの転載です。
こんにちは、JDSCの松井です。
BigQueryのフォーマットをどう統一するか、というのは結構悩みの種だったりしませんか?
自分のプロジェクトでも、ローカルで簡単に使えて、BigQueryの方言も含めて安心してフォーマットできるツールを探していたのですが、案外見つからないものでした。
そこで今回は、Googleが公開しているSQL解析器のZetaSQLに含まれていたフォーマッタを、プロジェクトに導入するまでのお話をしたいと思います。

具体的には
1. ZetaSQL内のフォーマッタの問題
2. パッチの詳細
3. Dockerイメージの最適化
4. 細かい修正点
といった内容になります。
今回の内容は、使いやすいようにバイナリやDockerイメージ、pre-commit-hookを用意してGithub上に公開しているので、忙しい方はそちらをご覧ください!
MacとLinux向けに高速なバイナリのリリースもありますが、フォーマッタを適用するだけなら以下のdockerコマンドだけでも大丈夫です。(. となっている部分には、複数のパスが指定できます)
***
$ docker run -it --rm -v `pwd`:/home:Z matts966/zetasql-formatter:latest .
***
1. ZetaSQL内のフォーマッタの問題
ZetaSQL内のフォーマッタは、チーム内ではBigQueryのWebエディタに搭載されているものよりもスタイルが好評だったのですが、以下の2つの問題がありました。
1. バイナリやDockerイメージといった形式でのリリースがなく、導入が面倒
2. SQLスクリプト内のコメントが丸々抜け落ちてしまう(タイトル回収)
前者は単にビルドすれば良いのですが、後者は実装に問題があるので修正が必要です。
2. パッチの詳細
まずはどの辺りでコメントの情報が抜け落ちてしまうのか原因を探ろうとしていたところ、以下の include_comments というフラグを発見しました。
ParseTokenOptions という構造体名からしても、パーサーがこのフラグを認識してくれる可能性は高そうです。そこで早速フラグを true にしてビルドしてみたのですが、コメントは相変わらず無視されたままでした。
ここからの調査が最も時間がかかった所なのですが、結論から言ってしまうと、 ParseTokenOptions というのはレキサーのオプションでしかなく、 include_comments を true にしてもパーサーはコメントを無視してしまうので、変更が反映されなかったという状況でした。
つまり、SQLのスクリプトをトークンのリストに分割するまではコメントの情報を維持することができますが、それを構文上のどこかに保存しておくことはできないようでした。
確かに、
・コメントが直前の構文要素の子になるのか?
・直後の構文要素の子になるのか?
・どの構文要素もコメントを子に持てるのか?
など考えることが多いので、パーサーがトークン列を読み込むタイミングでコメントを全て無視して捨ててしまう実装も仕方ないように思えます。
ここまでの調査で、トークンが分割されるところまではコメントが維持されていることが分かりました。この分割されたトークン列の情報は、C++で vector として取得できます。
そこで、このトークン列からコメントを取り出して使うことはできないだろうか、と考えました。
幸い、トークンも構文木もソースコード内での位置情報が取得できたため、これを使ってコメントを正しい位置に配置し直すことができそうでした。
実際の実装では以下のようなステップでコメントを出力しました
1.まずトークンのリストからコメントのみを抽出する。後から使いやすいように std::deque に入れる。
2.構文木を辿りながら整形した文字列を出力する段階で、現在の構文木よりも位置情報的に前のコメントがあれば、コメントを出力してから整形した文字列を出力する。
ZetaSQLのフォーマッタは、得られた構文木を再帰的に辿っていき、個々の要素を決まったフォーマットの文字列として出力する、という実装になっており、典型的なVisitorパターンに則っているのですが、その際個々のvisit関数は以下のように汎用ポインタで必要なデータを受け取れるようになっていました。

そこで、抽出したコメントのリストを引数として渡すことで、コメントと現在の構文木の位置情報を比較した上で出力できるようにしました。
コメントを出力する際には、 /* comment */ といった形式のコメントは問題ないのですが、 # comment といった形式の1行のコメントを末尾に改行がない状態で次の要素を出力してしまうと、次の構文要素も含めてコメントになってしまうので、必ず改行するように注意しました。
▼フォーマット前後
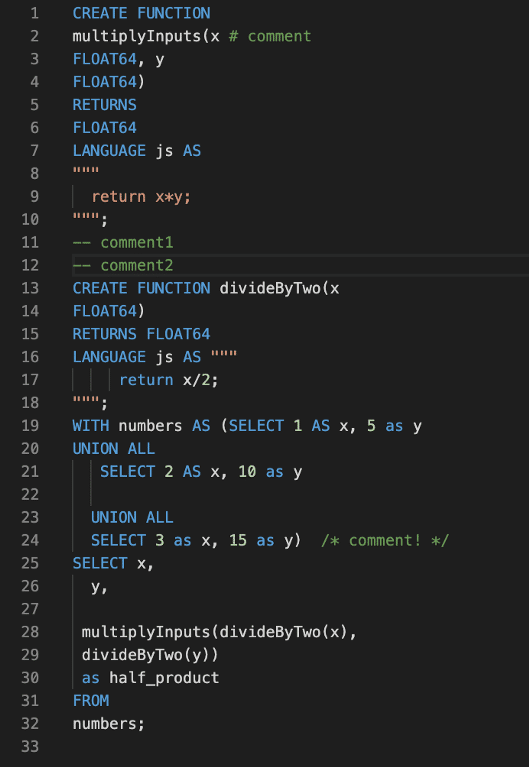

3. Dockerイメージの最適化
Dockerイメージは@apstndbさんのzetasql-format-serverのDockerfileを参考にさせていただきました。
今回の場合、ローカルでの利用やCIで毎回コンテナを起動する使い方を想定しているので、上記のDockerfileのようにマルチステップビルドによってビルド時のツールやソースコードなどはイメージから除外したいというモチベーションがありました。
しかし、そのままバイナリをコピーした所、C++でライブラリを使っている問題で、「ダイナミックライブラリが存在しない」といったエラーが発生してしまいました。
ZetaSQLで使われているビルドツールのbazelには、 fully_static_link という機能があり、最初はこれを使ってバイナリファイルをポータブルにすることを考えたのですが、意図したようには動作せず、issueも多く解決が難しそうな印象でした。
そこで、下記のようにライブラリファイルをコピーすることで対応しました。

これによって、3.11GBあったイメージサイズを32.7MBまで抑えることができ、体感でわかる程度の高速化を実現することができました。
4. 細かい修正点
フォーマットの問題
実際に今回パッチを当てたフォーマッタを導入する際、スタイルとしてウケの悪い点がいくつかわかってきました。 例えば以下の点です。
1.カラムのリストを改行しないで横に並べることがたまにあり、見づらい
2.複数行のコメントが途中に入ると、先頭行のみ必ず一つ上の行に配置されてしまう
3.最後がコメントで終わっていると ; が無限に追加されていく
4.たまにコメントの位置がワープする
1の問題は、どの構文が問題なのか分かりづらかったのですが、「 REPLACE, ORDER BY, EXCEPT が気になる」とコメントをいただけたので、比較的手早く修正することができました。
2の問題は、コメントを出力する段階で、複数行コメントであれば最初の行を出力する前に改行を入れる、という対策で修正することができました。
他には、3のように明らかなバグの場合は、問題の場所を見つけやすいのですが、visit関数だけで2500行超ある今回のフォーマッタでは、構文的にどういった要素に問題が起きているのか、という情報が分からないと、修正が難しいように感じました。
特に4のような問題がその一例です。
この問題は、構文木の訪問順が、実際の位置の通りの順番になっていないことで起きてしまうのですが、いろいろな構文要素があるため、なかなか根絶することが難しいです。
最終的にはJOIN句とCASE文で発生していることがわかり、構文要素への訪問時だけでなく、より細かく位置情報を確認することで対応することができました。
ただ、CASE文のキーワードの位置情報は一部失われてしまうため、微妙にコメントの位置がずれてしまう可能性はあります。理想を言えば、構文木を辿りながらフォーマットを編集して位置情報もずらしていくような実装ができると良いのですが、その場合全て書き直しになるため、今回はこのようなアプローチとなりました。
このように、フォーマッタは細かい点に問題が起きやすく、また、問題を言語化することも難しいことがわかりました。
特に、構文的な情報とともに問題点が言語化できていないと、なかなかどこを直していいのか分かりづらいように感じました。
今回のフォーマッタについて、気に入らない点などありましたら、是非上記のような構文的な再現性について言及して、できればサンプルコードをいただけると、スムーズに修正できると思います。
コメントの「文字化け」問題
上記の問題2を修正している際、コメントが「文字化け」する問題に遭遇しました。
問題の原因は、位置情報を確認してコメントを出力する以下の関数にありました。

コメントが複数行の場合に対応するために、この関数に加えられた変更の内容は以下です。
1.コメントが一度に複数行出力されるかについて確認するために、次に見るコメントの文字列を comment_string 変数に保持しておく。
2.コメントのリストが格納されている std::deque に対して pop_front を呼んで、更に次のコメントを確認する。
一見問題ないように見えるコードですが、C++で初心者がよくやってしまう問題が隠れています…。なんだかわかりましたか?
このコードの問題は、変数の生存期間を忘れていることにあります。
具体的には、 comment_string 変数が問題です。 absl::string_view は、 std::string と異なり、弱参照です。そのため、他の参照がなくなった後に参照すると、未定義動作になります。
15行目で初期化されている comment_string 変数の参照先は、19行目の pop_front の呼び出しで破棄されてしまいます。その結果、28行目の出力の際に、寿命が切れて微妙に解放されたメモリ領域が参照されることで、「文字化け」のような現象を引き起こしていた、というわけです。
それまでに文字コードの問題にも遭遇していたうえ、コメントはだいたい日本語だったので、また同じ系統の問題かと勘違いしてしまいましたが、最終的には pop_front が呼ばれる前に std::string で初期化を行うことで解決することができました。
後日談というか今回のオチ
今回のパッチで、コメントを保持しながらZetaSQLの良さげなフォーマッタを利用できるようになりました。
ただ、ZetaSQLはプルリクエストを受け入れていないため、今回の変更をすべてのZetaSQL利用者に届けることはできません。
そこで、Googleが既にフォーマッタのアップデートを予定しているのであればそれを進めてもらうか、自分の変更をプルリクエストとして取り入れてもらえないか、issueでリクエストを送ってみることにしました。
既に「ZetaSQLのフォーマッタでコメントが抜け落ちてしまう」という内容のissueがあったので、そこにコメントしたものがこちらです。
するとその日のうちにgooglerから返信がありました。
内容としては、Google内部には既にコメントを保持するように書き直されたフォーマッタが存在していたが、リクエストがないためリリースしていなかった、ということのようです。
最終的に、今回リリースしたフォーマッタは、今後Googleから新しいフォーマッタがリリースされるまでの短い命になるかもしれませんが、 pre-commit や Dockerfile といった周辺ツールの整備も含めて良い勉強になりました。
今後はGoogleがリリースする(かもしれない)フォーマッタの実装と、今回の実装の比較などもできると面白いと考えています。
今回リリースしたフォーマッタは導入もしやすく、やめるのも簡単なので、是非使ってみていただいてスターなど貰えると嬉しいです。
最後まで読んでいただきありがとうございました!
この記事が気に入ったらサポートをしてみませんか?