
テーブルデータ用ニューラルネットワークは勾配ブースティング木にどこまで迫れるのか?(補足編)

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でM-AISに所属する蕭喬仁です。
前回お話したテーブルデータ用ニューラルネットワークは勾配ブースティング木にどこまで迫れるのか?(本編)では、「テーブルデータ用ニューラルネットワークの検証」についてモデル間の精度比較に重点をおいて内容の共有をさせていただきました。
本記事では、個々のモデルの詳細な検証結果を「補足編」としてご紹介したいと思います。
個々のモデルの詳細な検証結果
ここからは個々のモデルの具体的な実験結果として、デフォルトパラメータ及びベストパラメータを用いた場合のシードによるCVの変化、ハイパラ探索の結果、どのようなハイパラが重要だったかなどを紹介していきます。
それぞれのモデルについて結果を羅列していきますので、気になる箇所だけ適宜お読みいただければ幸いです。
LightGBM / 13ヶ月分の生特徴量



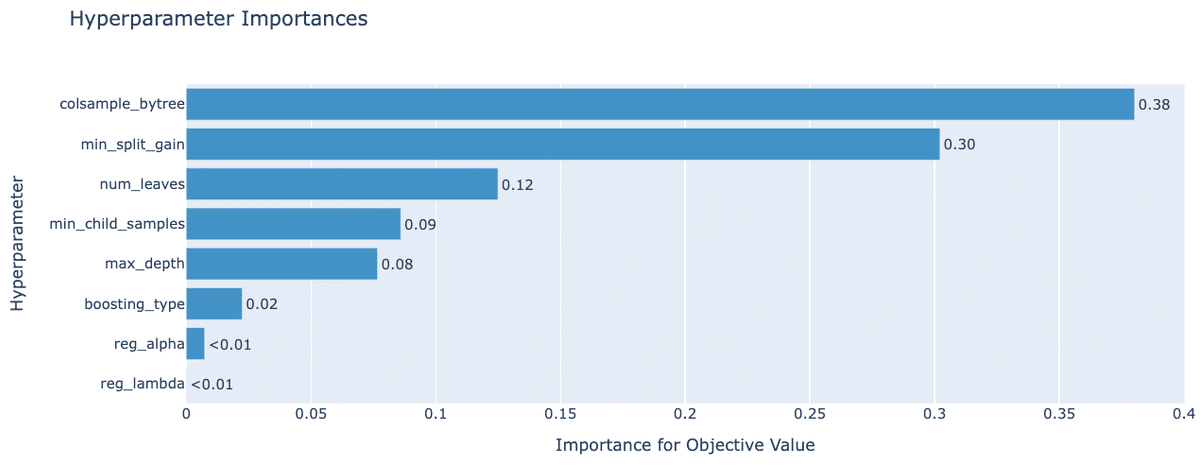
{ 'boosting_type': 'gbdt' 'num_leaves': 220, 'max_depth': 16, 'colsample_bytree': 0.3, 'reg_alpha': 2e-4, 'reg_lambda': 1e-07, 'min_child_samples': 38, 'min_split_gain': 0.25 }
デフォルトパラメータでもベストパラメータでも乱数シードがCVに与える影響は最大で0.001ポイントで、NN系のモデルと比べるとかなり安定した性能を出しています。
今回重要だったハイパラは特徴量をどれだけサンプリングするかを制御するcolsample_bytreeと葉の分割のしやすさを制御するmin_split_gainだったようで、reg_alphaとreg_lambdaはあまり調整する意味がなかったようです。
LightGBM / 最新1ヶ月分の生特徴量




{ 'boosting_type': 'gbdt', 'num_leaves': 300, 'max_depth': 14, 'colsample_bytree': 0.4, 'reg_alpha': 2e-08, 'reg_lambda': 4e-4, 'min_child_samples': 3, 'min_split_gain': 0.18 }
13ヶ月の特徴量を使う場合と同様で乱数シードがCVに与える影響はほとんどなく、こちらもNN系のモデルと比べて安定した性能を出しています。
重要なハイパラの傾向も13ヶ月の特徴量を使用する場合と同様で、colsample_bytreeとmin_split_gainが特に重要で、reg_alphaとreg_lambdaはあまり調整する意味がなかったようです。
GRU / 13ヶ月分の生特徴量



{'cat_embedding_dim': 5, 'latent_dim': 256, 'n_blocks': 1, 'dropout_rate': 0.01}
乱数シードがCVに与える影響は最大で0.002ポイントとLightGBMと比べると少し大きい結果となりましたが、基本的に安定しているようです。
ハイパラ探索ではGRUを何層重ねるか(n_blocks)や隠れ層の次元数(latent_dim)、全結合層でのドロップアウトの確率(dropout_rate)などをチューニングしましたが、latent_dimが最も重要という結果になりました。ベストパラメータでn_blocksが1となっていたので、今回は層を重ねる意味は無かったようです。
最も悪いパラメータを設定した場合と最良のパラメータの間に0.005ポイントの差があるので、チューニングはしっかりやった方が良さそうです。
1D CNN / 13ヶ月分の生特徴量



{ 'cat_embedding_dim': 5, 'kernel_size': 3, 'strides': 1, 'filter_num': 64, 'n_blocks': 3, 'dropout_rate': 0.45 }
乱数シードがCVに与える影響はGRUと同様で約0.002ポイントとなりました。
ハイパラ探索ではCNNを何層重ねるか(n_blocks)やコンボリューションフィルターの数(filter_num)やカーネルサイズ(kernel_size)、ストライドの幅(strides)などをチューニングした結果、全結合層におけるドロップアウトの確率(dropout_rate)とストライドの幅(strides)などが重要だったようです。
ベストパラメータではkernel_sizeが3、stridesが1となったので自然な結果が得られたと言えそうです。また、GRUと同様にベストパラメータではn_blocksが1となっていたので、CNNを用いる場合でも層を重ねるメリットは出なかったようです。
チューニング時の最低評価値は0.706とかなり悪い数値を引いていますが、基本的には0.783 ~ 0.788の値に収まっています。とはいえ0.005ポイントも変わるので基本的にチューニングは行った方が得策のようです。
Transformer / 13ヶ月分の生特徴量

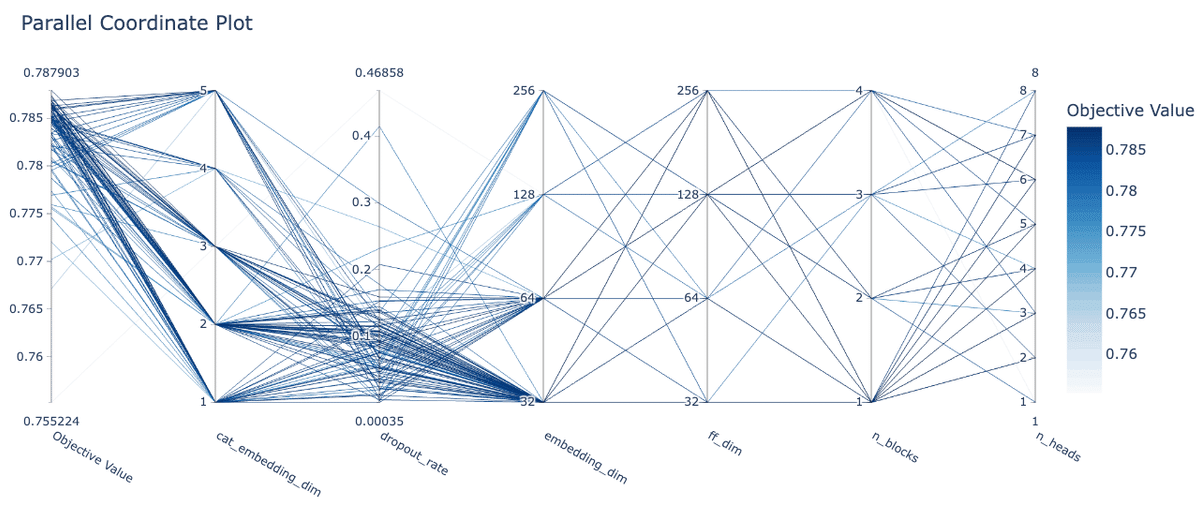

{ 'cat_embedding_dim': 3, 'embedding_dim': 64, 'ff_dim': 256, 'n_heads': 4, 'n_blocks': 1, 'dropout_rate': 0.091 }
乱数シードがCVに与える影響はその他の時系列NNと同様で約0.002ポイントとなりました。
ハイパラ探索ではTransformerを何層重ねるか(n_blocks)やTransormerへ入力する際の特徴量の次元数(embedding_dim)やattentionのhead数(n_heads)、FFを行う際の次元数(ff_dim)のチューニングを行った結果、全結合層におけるドロップアウトの確率(dropout_rate)とTransformerを何層重ねるか(n_blocks)が重要だったようです。
その他の時系列NN同様にベストパラメータではn_blocksが1になっているのが興味深いです。今回は13系列しかなかったため、あまり層を重ねる必要はなかったということでしょうか。
FTTransformer / 最新1ヶ月分の生特徴量



FTTransformerは1回あたりの学習時間がかなり長かったため、ハイパラ探索ではTransformerブロックを何層重ねるか(n_blocks)のみをグリッドサーチで探索しました。探索範囲は元論文と同じく1~6の範囲に設定し、乱数の影響も考えそれぞれ3回分実行しました。
FTTransformerはn_blocksを増やすと線型に学習時間が増え、5Foldにかかる学習時間はデフォルトの3の場合は3時間、6に増やした場合は6~7時間かかります。
探索結果は上記の通りで、n_blocksを大きくするほど精度が高くなる傾向が確認できました。しかし、n_blocksを6に設定し10通りのシードで学習した場合の精度を見てみると精度のブレがかなり大きく、グリッドサーチを行った際の3回がたまたま良かっただけで、精度自体はデフォルトパラメータと同程度と言えそうです。
GATE / 最新1ヶ月分の生特徴量

乱数シードがCVに与える影響は最大で約0.002ポイントとなりました。テーブル用NNにしては珍しく精度が安定しています。GATEのハイパラ探索結果も検証したかったのですが、上述した学習時のハングが解消できなかったので今回は省略します。
TabNet / 最新1ヶ月分の生特徴量
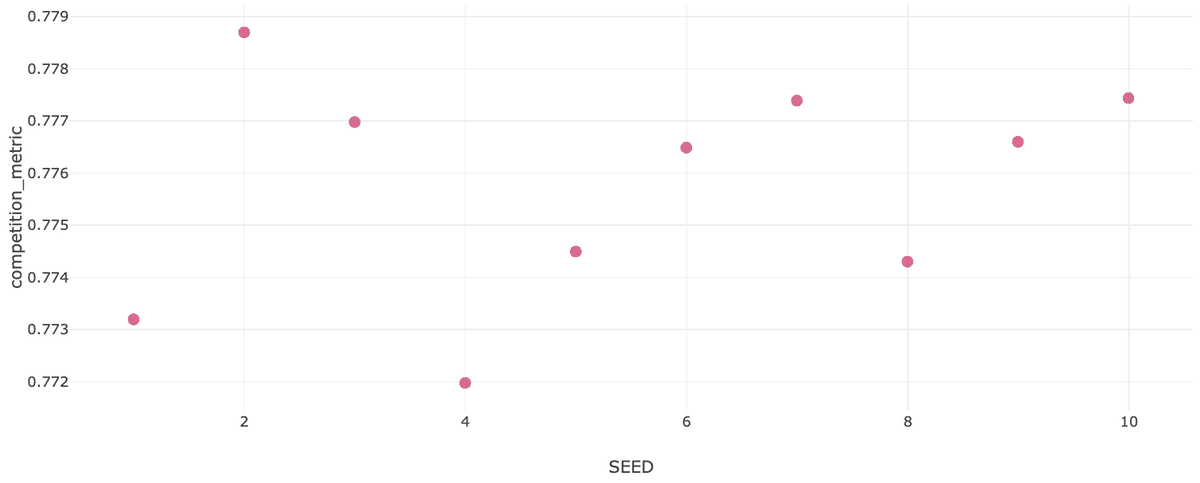
(事前学習無し)

(事前学習有り)

(事前学習無し)

(事前学習有り)
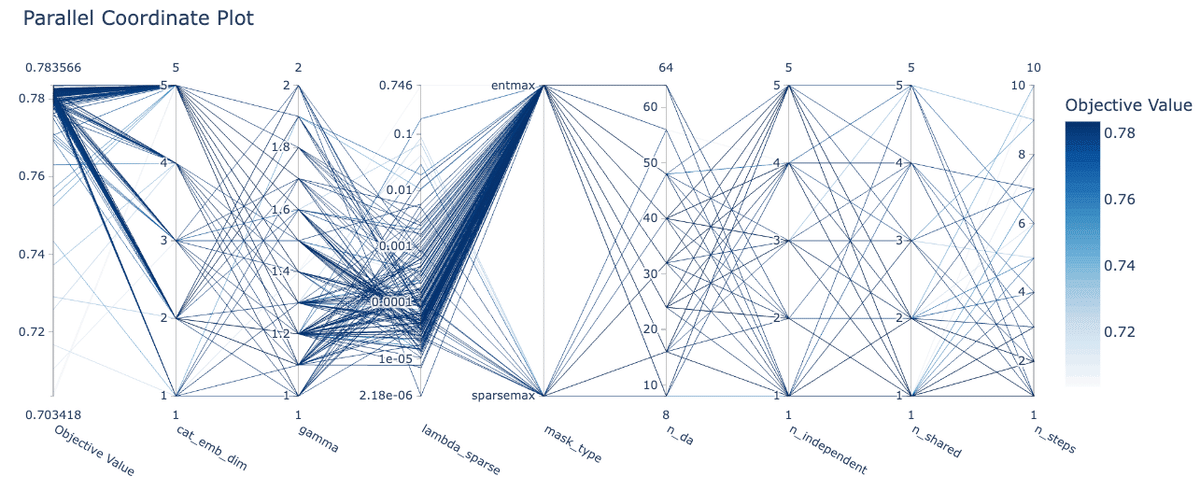

{ 'n_da': 32, 'n_steps': 1, 'gamma': 1.5, 'n_independent': 5, 'n_shared': 1, 'lambda_sparse': 4.8e-05, 'mask_type': 'entmax', 'cat_emb_dim': 5 }
デフォルトパラメータを用いて事前学習を行わない場合はシードによってCVが大きく変動していますが、事前学習を行うことである程度変動を抑えられるようです。一方、ベストパラメータを設定した場合はいずれのケースでもシードによる影響がほとんどなくなっています。
ハイパラの中で特に重要だったのは特徴量変換とモデルの予測を行うブロックを何層積み重ねるかを意味するn_stepsでした。デフォルトでは3に設定されていたものが探索によって1になっているので、時系列NNと同様に層を増やすことはあまり意味がなかった上に、学習を不安定にさせていたと言えます。
TabNet / 13ヶ月分の特徴量

(事前学習無し)

(事前学習有り)

(事前学習無し)

(事前学習有り)


{ 'n_da': 48, 'n_steps': 1, 'gamma': 1.6, 'n_independent': 1, 'n_shared': 2, 'lambda_sparse': 6e-05, 'mask_type': 'entmax', 'cat_emb_dim': 3 }
デフォルトパラメータを用いた場合は事前学習の有無に関わらず乱数シードによって精度が大きく変化しています。ベストパラメータを設定した場合は事前学習無しの方の精度が安定したものの、事前学習を行った方の精度は依然として不安定なままでした。
ハイパラの中で特に重要だったのは1ヶ月分の特徴量を利用する場合と同様でn_stepsでした。こちらの場合でもデフォルトでは3に設定されていたものが探索によって1になっているので、時系列NNと同様に層を増やすことはあまり意味がないようです。
最後に
今回の検証ではAmexコンペを題材に、普段の業務では利用する機会があまり無いテーブルデータ用NNを用いたモデリングを実施しました。実務の中で検証するには少々ハードルが高い乱数シードによる精度のブレやどのハイパーパラメータが効くのかといった点までを時間をかけて調査したことで、これらのモデルの使い方をかなり深いところまで理解できました。
検証結果はあくまで一例ではありますが、今後みなさんがテーブルデータ用NNを実務で利用する際の参考となれば幸いです。
JDDのM-AISでは今回実施した検証のように、各々のデータサイエンティストが自身の興味に沿って決定したテーマの分析・調査を行うR&D活動に取り組んでいます。今後も不定期で活動報告を実施していきますので、次回の報告をお楽しみにしていただければと思います。
以上、「テーブルデータ用ニューラルネットワークは勾配ブースティング木にどこまで迫れるのか?(補足編)」について内容の共有でした。
「本編」と「補足編」合わせて12,000文字長の長尺の記事となりましたが、最後までご覧いただきありがとうございました!
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
M-AIS
Kyojin Syo