
【5.字数、語数、品詞率】現代短歌のテキストマイニング――𠮷田恭大『光と私語』(いぬのせなか座)を題材に

(承前)
5-1.形態素解析による語彙の計量
5-1-1.形態素解析による語彙の計量
まずは下拵えを行う。『光と私語』データセットを、ある言語圏で意味をなす最小の記号・文字列の単位(形態素, morpheme)にまで分解し、記号・文字列の名称や原型、品詞を付与する。この作業を形態素解析という。国語の授業で、単語と単語のあいだに線を引いたり、読みがな(ルビ)を振ったり、品詞を書き添えたりしたと思う。それと同じような手続きだ。扱う情報があまりにも膨大で、その処理が驚くほど速いことを除けば。
今回の解析にはjuman++を用いた。京都大学で森田一、黒橋 禎夫らが2015年に開発した日本語の形態素解析器だ。係り受け解析が行えるjuman(1993-)の辞書・文法・出力フォーマットを引き継ぎ、WikipediaやWiktionalyなどの大規模Webコーパスから語彙獲得を行い、再帰型ニューラルネットワーク言語モデル(RNNLM)を用いている。そのおかげで、単語の並び順を考慮した、誤りのより少ない形態素解析が行える。開発者らの例示でいえば、「外国人参政権」「あさって」を「外国/人参/政権」「あさ/って」ではなく、「外国/人/参政/権」「あさって」と分類できる。これから先は、「外国人」のように、複数の形態素(外国、人)が結びついたものを「単語」と呼ぶ。どちらで呼んでも意味が通じるときは、簡単に「語」ということにする。
まずはこの歌集にいくつの「文」が含まれているかを数えておく。次に、この形態素解析器を用いて、この歌集に含まれる形態素の数や、品詞別の割合、頻出語などを算出する。その結果は、これから算出するすべての指標の前提として使うことができる。
5-1-2.歌集が含む「短歌」を数える
手法
これから行う分析の基礎となる数値を得るために、この歌集全体の文書数を計量する。この歌集に含まれるすべての1行を「1つの文書」と見なし、この歌集はいくつの文書で構成されるかを数え上げる。次に、すべての文書を人的目視で読み、「短歌ではない可能性がある文書」に目印をつける。31音前後に収まらない場合と、57577の定型に当てると、正調よりも破調のほうが多い場合に、目印「短歌じゃないかもフラグ」をつけていった。そして、フラグがつかなかった文書を「短歌作品」だと見なし、この歌集がいくつの「短歌作品」で構成されるかを数え上げた。
結果
得られた値は、次のとおり。
- 文書の数: 240
- 短歌作品数: 203(84.6%)
- 短歌じゃないかもしれない文書数: 37(15.4%)
考察
この歌集は約15%が「短歌じゃないかもしれない文章」で出来ている。よくある歌集なら、詞書くらいしか「短歌じゃない文章」を含まないから、この比率はさらに下がるだろう。古い歌物語なら、「短歌じゃない文章」が過半数を占める。つまり、この歌集は、短歌「らしくない」文章が、「やや多い」歌集だと言える。なお、分類は人的目視で行われた。数件の見落としがありうることに注意。
5-1-3.1首あたりの字数の相場
手法
続いて、1行(1文書)ごとの文字数にどれくらいのばらつきがあるかを集計してみた。「短歌作品」がどのような分布をするか分かれば、「短歌ではない作品」を作るのに役立つ指針が得られるから。1行(1文書)ごとの総文字数を計測し、「短歌作品」「短歌じゃないかもしれない文書」の2区分で、分布表とヒストグラムを描画した。
結果
1行(1文書)ごとの総文字数を、「短歌作品」「短歌じゃないかもしれない文書」の2区分で、散布図とヒストグラムを描いた。
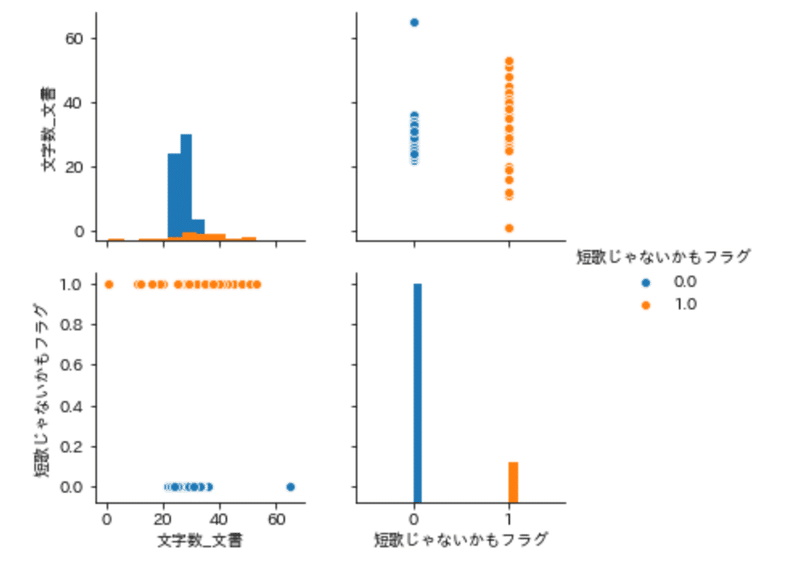
左上の図をみると、「短歌じゃないかもしれない文書」は、0字から60字弱までばらついた分布をとる。それに比べて「短歌」は、20字前半から30字後半の間でより緊密に分布する。
考察
日本語による短歌はほとんどが漢字かな交じり文で書かれる。31音をすべて1音1字で書き、拗音や促音を用いなければ、1首は31文字で書ける。漢字変換で、自然と字数調節がなされると、これくらいの値域に収まるのは納得できる。この統計は歌集の余白と字サイズの設計に役立つだろうか。
1点だけ異常値を示したのは、英単語だけを用いた1首「Smoking kills. Smokers die younger. Smoking harms you and others.」(65字)だった。この1首は七五調で読みづらく、日本語訛りで無理に「すもーきん/きる、すもーかー/だい、やんがー/すもーきん、はーむ/ゆー、えん、あざー」とでも読めば、31音に収まる。そうして苦戦しながら読み終えると、この歌集を読むとき、私たちは、読み手の音律意識によって「作品か否か」を判定していることに気づかされる。
仮説
日本語で書かれた短歌は、20字強から40字弱に大量に密集しているのかもしれない。少なくとも、短歌という表現が、他の文章を書く時とちがって、より強い制約のなかで生まれていることの、ひとつの傍証にはなる。異常値を示した1首からは、日本語の韻律は、もしかすると、ローカルな言語の歴史的な慣習に過ぎないのではないかと気づかされる。
5-1-4.1首あたりの語数の相場
手法
今度は、1行(1文書)ごとの単語数にどれくらいのばらつきがあるかを集計してみた。狙いは同じだ。1行(1文書)ごとの総語数を計測し、ヒストグラムを描画した。「短歌作品」「短歌じゃないかもしれない文書」のどちらも含まれることに注意。
結果
縦軸に単語数、横軸に行数(文書数)をとったヒストグラムを描いた。
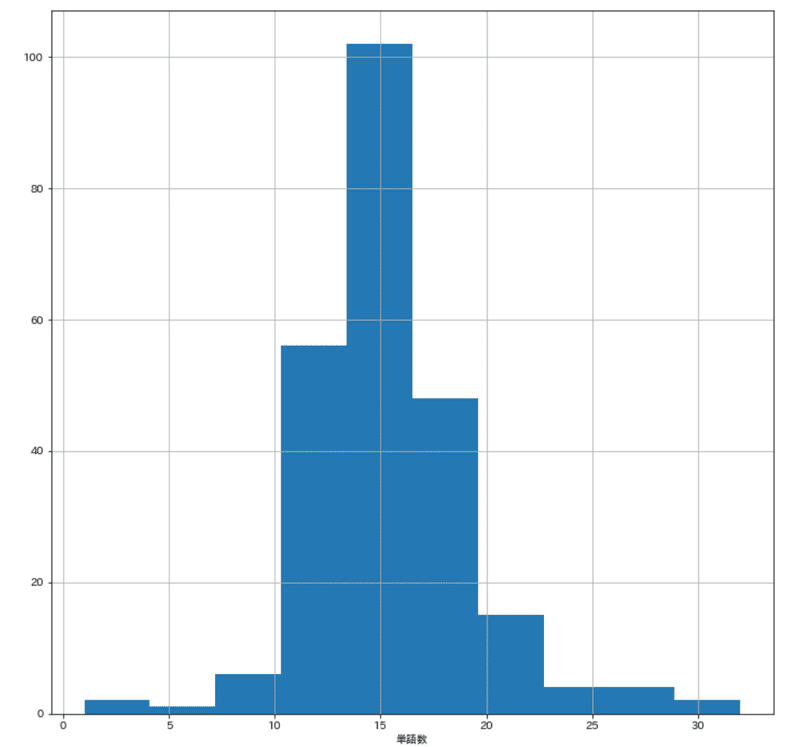
15語前後の行(文書)が100程度と最多で、10語前後が60弱、20語前後が40弱ある。その他の語数で作られたものは少数だった。
考察
短歌は31音(無音の拍を含めば最大40音ほど)で作られる。先ほどの分析によれば、この歌集の「短歌」は20字前半から30字後半のものが多い。1語が2~3字で構成されるとすれば、15語前後の短歌が多いことにもうなづける。裏返すと、1首あたりの語数を10語未満としたり、20語以上にすると、いっぷう変わった、珍しい作品が作りやすいと言えるのではないか。
5-1-5.この歌集はどんな品詞で出来ているか
手法
文書数や文字数は、ある歌集が他の歌集と比べて、似ている/外れているかを知る手がかりになる。とはいえ、ひとのからだで言えば、身長・体重のようなもので、その歌集がどんな内容で作られているかを説明しない。かといって、その歌集から数首を選んで、その語彙や文法を論じるだけでは、その歌集が全体として持つ傾向は言い表せない。ひとつの歌集が全体として、どういった文法意識のなかで作られているかを知りたい。
そこで、形態素解析の結果をもとに、品詞別の出現頻度を集計した。ちなみに、日本語文法にはいくつかの体系がある。juman++は、そのなかでも、益岡隆志・田窪行則『基礎日本語文法』(1992)の品詞体系を拡張して用いる。「形容詞」には「形容動詞」も含まれ、接頭辞・接尾辞を含む14種の形態品詞に分類される。なお、今回の分析では、品詞の活用形を考慮せず、原型を用いた。(参考)
結果
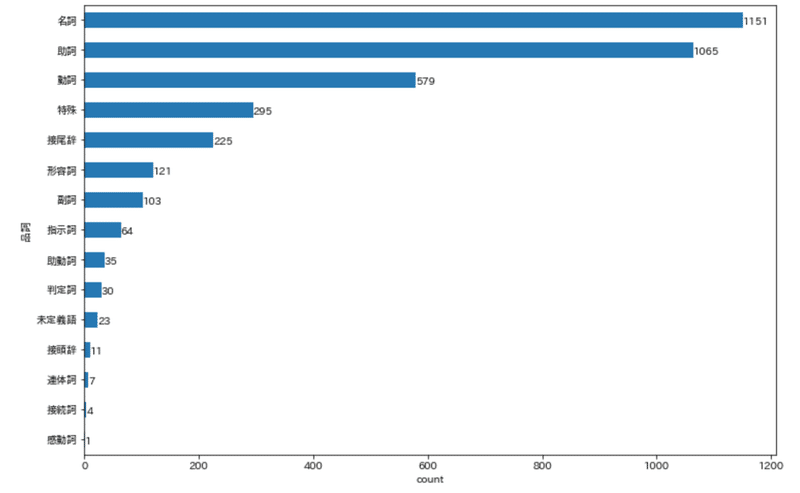
名詞(1,151)が、動詞(579)の約1.98倍出現する。助詞(1,065)は名詞の92%ほどで、複合名詞や体現止めの分量が示唆される。形容詞(121)や副詞(103)は、名詞10回につき1回使われるかどうか。感動詞(1)や接続詞(4)、連体詞(7)はごく少ない。
考察
この歌集は大部分が「名詞」と「助詞」で構成され、形容詞・副詞の使用は(おそらく)控えられている。感動詞・連体詞の使用は、明らかに避けられている。
仮説
この歌集は、多くの名詞、少ない形容詞、極少ない感動詞で構成される。他の歌集や、現代短歌一般と比べても、この特徴が成り立つとすれば、この歌集が独自に持つ性質だと言える。そうではなく、現代短歌一般が、日本語のテキスト一般と比べて、この特徴を持つ可能性もある。ある時代が想定する「短歌らしい短歌」は、どのような文構造から成り立つのか。それが分かれば、経年変化のなかで係り結びが消えていったように、現代短歌の自己同一性を規定する基本条件の見直しができるようになる。この結果は、以降の解析にも用いることとする(第6章、第7章、第8章へ)。
5-2.語の出現頻度とその予測
5-2-1.よく使われる単語は
手法
品詞の多寡は、この歌集がどのような構文を基礎に成り立つかを示唆する。しかし、語彙の偏り・散らばりまでは分からない。品詞の種類ではなく、個々の単語ごとの用法を調べることで、この歌集の成分構成を見極められないか。形態素解析の結果をもとに、語の出現頻度が高い順に、上位20までを並べた。ただし、 ['特殊', '助詞', '判定詞']を除外して集計した。
結果
- 頻出語ランキング
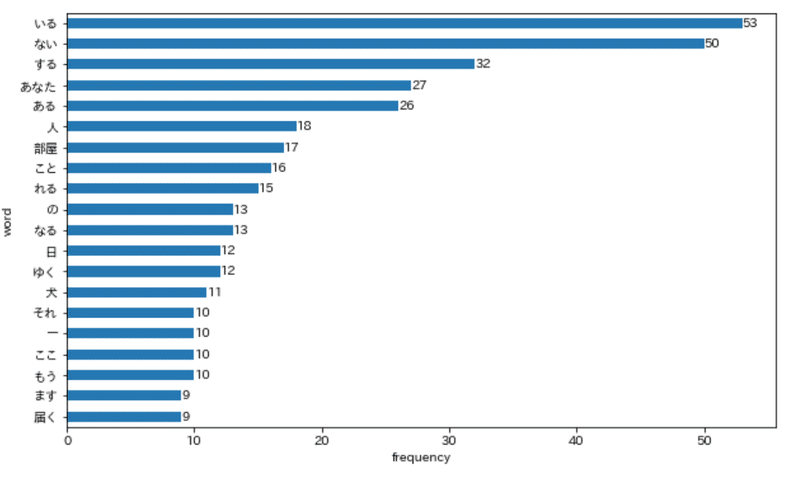
「いる」(53)が最多で、「ない」(50)、「する」(32)、「あなた」(27)、「ある」(26)と続く。「人」(18)、「部屋」(17)も頻出する。
考察
「~ている」「いる」(53)が「する」(32)の1.6倍、「なる」(13)の4.0倍多く使われている。個別作をみていくと、「枚数を数えて拭いてゆく窓も尽きて明るい屋上にいる」「トラのいる檻でボタンを押して鳴るさびしい時のトラの鳴き声」のように、主体・客体の存在を言う「いる」の用法は、数例ほどと多くない。ほとんどは、「~ている」型だ。つまり、この歌集には、行為とその結果・変化よりも、持続や推移、状態を描く歌が多い。例えば、次のように。
- これまでの恋人がみな埋められているんだそこが江の島だから
- 必要なものを探しているような顔で靴屋に寄って帰る日
- 地図を正せばもう消えている場所だろう こんなにも猫しかいない
何かが「ない」歌集
また、「ない」(50)が「ある」(26)の1.9倍出現する。どういった文脈で使われるか。「否定」(海じゃない、恋人じゃない、闇ではない、眠くない)のほかに、「不能」(踊れない、知らない、乗れない)、「不在」(みていない、猫しかいない)、「回避」(行かない、いらない、追わない)、「禁止」(いけない、許さない)、「義務」(覚えなくてはならない、二度書きしてはいけない)などが挙げられる。これらの積み重ねが、この歌集のトーンを形づくっているのだろう。この歌集では、何かが失われ、消えている。作中主体は、明示されない制度に禁じられ、義務づけられる。作中客体には、できないことがあり、したくないことがある。そのような場面がしばしば描かれる。
被写体としての「あなた」
この歌集には一人称と三人称がほとんど出現しない。代わりに「あなた」(27)が多用される。それも、この歌集の読者に呼びかけるのではなく、作中主体の意識や視線の届くところに「いる/いない」客体として描かれる。「あなた」は都市生活の一場面のなかで、同伴したり、同居したり、同定される対象としてある。「人」(17)は「老人」(7)と「恋人」(5)と群衆または一般名詞の集合であり、たいてい写生の被写体として出現する。
光と私語が集まる「部屋」
「部屋」(17)は連作「ト」で9回出現したあと、第3章では「きらきら」「輝いて」「明るく」「真昼間の」「窓を拭く」場所として描かれる。この歌集にとって、部屋は光が差し込む空間であり、配達物(乗り物の模型、不在通知、朝刊、便箋)が「届く」(9)宛先でもある。「犬」(11)にまつわる生活の場でもある。
5-2-2.頻出する助詞・助動詞は
手法
短歌は助詞・助動詞の使い分けで作中世界を立ち上げ、描き出し、動かし、制御する。名詞・動詞のあり方だけでなく、助詞・助動詞の用法を見ることで、この歌集に独自のスタイルが見出せないか。 ['特殊', '助詞', '判定詞']を除外せずに、単語の出現頻度を集計し、頻度が高い順に、上位20までを並べた。
結果
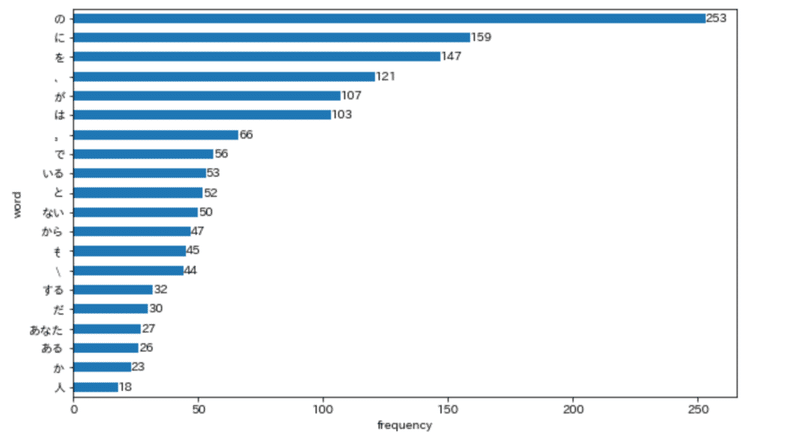
「の」(253)がもっとも多く、この歌集の総文書数(240)を上回る。「に」(159)「を」(147)が続く。「が」(107)「は」(103)はやや少ない。「と」「も」はより少ない。「、」が「が」「は」より多いことにも注目される。
考察
上位5位の助詞(の、に、を、が、は)を含まない短歌は2首しかない。「Smoking kills. Smokers die younger. Smoking harms you and others.」と「Napoli is Not Nepal 交差点振り返るときハローと言えり」だ。この5語が、この歌集が短歌を構成する基本要素として用いられていると分かる。
他方で、上位5語すべてを使った首は意外に少なく、「丸ノ内線に光が差すたびに意識の上では目を覚ますけど」と「本は木々には還らぬとして(知らないが)あなたのことをあなたより好き」の2首だけ。総じて、人称の省略がしばしば行われるけれど、主題ないし主語の提示はあり、連体修飾で1首の骨子を作り、連用修飾で記述対象を指定する。そういった作りをしている歌集だと言える。
第2章では地名の列挙や散文の挿入が盛んに行われ、全41文書で「、」が用いられる。加えて、第1章で22文書、第3章でも16文書使われており、合わせて76文書ある。「少なくない」といった使用頻度か。
仮説
「の」(253)がもっとも多く、「が」「は」の総和(210)を上回るのはなぜか。この歌集の特徴か、現代短歌に共通して見られる性質か。「に」「を」「で」の多さは、この歌集が観察と描写に重心を置く(と見られる)ことと関わりがあるか。「と」「も」が少ないことは、この歌集が、事物の並立や共同、併存をことさらに強調しないことの傍証となるのか。
5-2-3.すべての異なる語の数
手法
テキストデータを分析するときには、語の出現頻度に、極端な偏りがしばしば観察される。少数の語(いる、ない、ある…etc.)が数多く登場し、その他の語はあまり出現せず、むしろ1回しか出現しない語が多くなる傾向がある。(ぱーじぇーろ、TSUTAYA…etc.)。
この歌集もその性質を持つのか確かめよう。この歌集に出現する、すべての異なる語の数を集計する。厳密には異なり形態素数という。異なり語数を出現頻度と順位の2軸で可視化し、どのくらい極端なのか計量を試みる。特にことわりがない場合、['特殊', '助詞', '判定詞'] を除外している。
結果
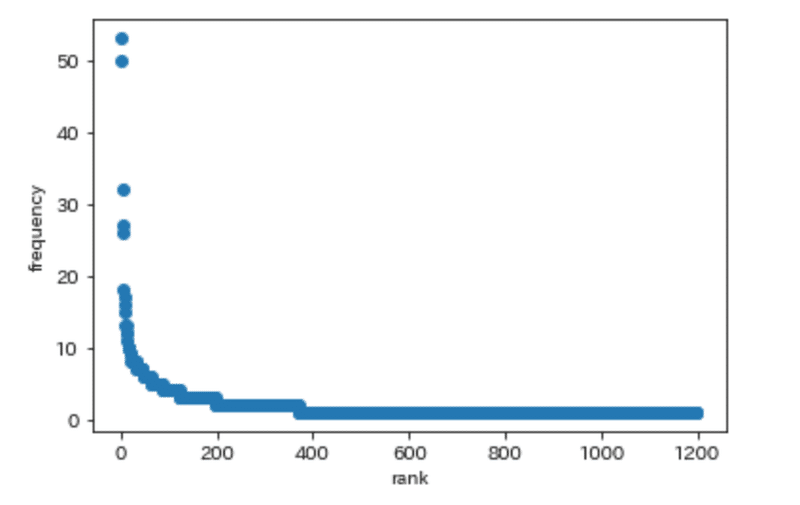
縦軸に出現頻度、横軸に出現頻度でつけた順位をプロットした。
考察
見ての通り、裾の長い分布になっている。10回以上用いられた語はせいぜい数十語しかなく、ほとんどの語は数回しか出現しない。最上位と大多数に際立った格差が観察される。
5-2-4.パレートの法則
パレートの法則と呼ばれる経験則がある。1896年にジョセフ・モーゼフ・ジュランが発見し、イタリアの経済学者ウィルフレッド・パレートが命名した。所得分布や経済効率を論じるに当たって、「イタリアの国土の80%は20%の人口が所有している」と述べたことから転じて、「売上の8割は全顧客の2割が生み出す」といった言説で用いられるようになった。さまざまな経済現象がこの法則におおむね当てはまったことから、現代も、経験則として広く語られている。
手法
この歌集にもそれが当てはまるのかを確かめる。この歌集のデータセットの形態素解析を行い、上位20%を占める語の出現頻度を計量した。この計量を行うときには、品詞の活用形を考慮せず、原型を用いた。
結果
['特殊', '助詞', '判定詞']を除外した場合
上位20%の語の頻度の全体に対する割合を計算してみると、
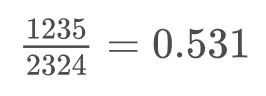
助詞などを除いた場合、単語の出現頻度は全体の53.1%を占める。
すべての品詞を用いた場合
上位20%の語の頻度の全体に対する割合を計算してみると、
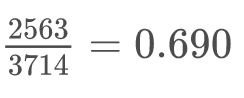
すべての品詞を用いた場合、上位20%を占める語の出現頻度は全体の69.0%を占める。
考察
どちらの場合も、パレートの法則には当てはまらないとわかる。
パレートの法則が、単なる経験則ではないとすれば、この歌集は、何らかの性質から、パレートの法則が当てはまらないと解釈できる。この歌集は、何も考えずに書かれた文章と比べれば、語彙選択に配慮がなされた文章だと仮定できるだろう。
5-2-4.zipfの法則とは
パレートの法則が着目したような、ある事物の出現頻度に極端な偏りが見られる現象に、より厳密な説明を与えた数学者がいる。彼が発見した法則は、考案者の名を冠して、zipfの法則と呼ばれる。1923年に提唱されたこの法則は、「出現頻度が k 番目に大きい要素が全体に占める割合が 1/k に比例するという経験則」である。(出典)
手法
zipfの法則は次のように定式化できる。ある語の頻度を f , 出現頻度の順位を r , 定数 c とすると、
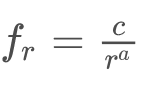
と表される。この等式の対数をとると、
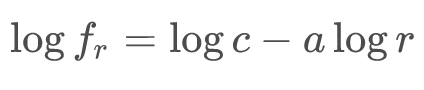
と書ける。この変換を行うことで、計算結果を線形グラフで表現できる。縦軸に頻度 f の対数、横軸に順位 r の対数を 描いた時の傾きが a を表す。こうすれば、線形回帰を行って直線近似することで、順位に対する単語の出現数が予測できるようになる。
これを私たちの分析に用いることにする。(参考)語の出現頻度とそのランキングの両対数をプロットし、線形回帰による直線近似を行って、zipfの法則に当てはまるかを調べた。
結果と考察
近似結果により傾き(-a)、切片(log c)は次のように求まった。
傾き: -0.65
切片: 4.33
この結果を元に a と c の値を求めると、次のようになる。MSE(平均二乗誤差)は値が低いほど、予測モデルの当てはまりがよい。
a = 0.65
c = 75.69
# 誤差
MSE: 35.87
得られた a と c の値を元の定義式に当てはめると、次のように書ける。
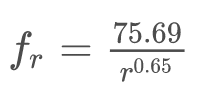
さらに、出現頻度と順位について対数を取ったものと、直線近似したものをプロットすると以下のようになる。
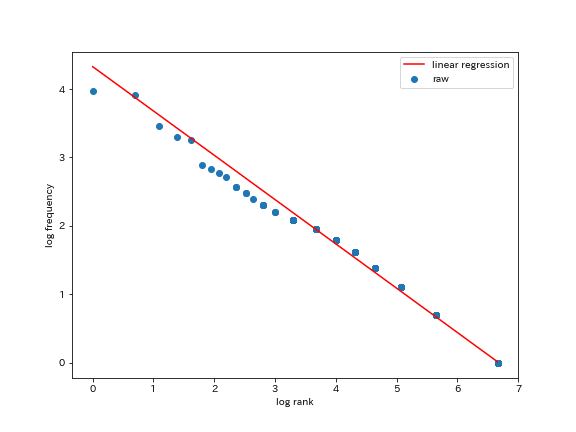
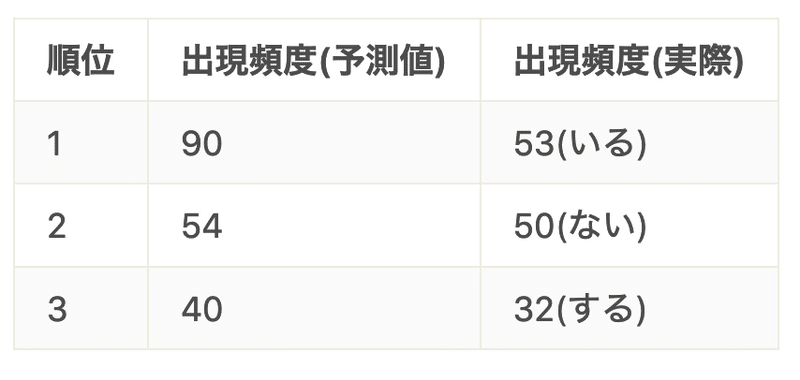
直線になんとなく乗っており、なかなか当てはまりがよいと分かる。近似直線について順位 r を入れてやることで出現頻度 f を計算できる。すなわち、ある順位にある語の、出現回数を予測することもできる。たとえば、1位の時は縦軸の値は4.5とし、横軸の値は0に……などとして、指数を計算してやればいい。実際の値と予測結果を以下に示す。予測性能は「悪くない」くらいだろうか。
この記事が気に入ったらサポートをしてみませんか?