
【抄録版】現代短歌のテキストマイニング――𠮷田恭大『光と私語』(いぬのせなか座)を題材に

要旨
英語圏では、自然言語処理の技術を実作の助けになるかたちで応用する学術研究が盛んだ。『ベストセラー・コード』のように、普及書の邦訳が日本でも続々と出ている。日本語圏にも、半世紀以上に渡る、計量文体学や日本語コーパス構築の積み重ねがある。
それらの手法を日本語の現代短歌に試してみようと私たちは考えた。単語の数量や距離関係、感情の流れ、品詞構成などを計量すれば、文献の精読 (close reading)ではなく、テキストの遠読 (distant reading) ができると期待したのだ。
そこで私たちは、𠮷田恭大が執筆し、いぬのせなか座が刊行した歌集『光と私語』のテキストデータを用いて、単語、文章、連作および歌集単位の分析を行った。この作品が持つ特徴を計量し、描写し、考察した。また、他の日本語コーパスと比較することで、この歌集や、現代短歌というジャンルが持つ性質を明らかにした。
ひとが機械で読み、書く時代に
近年、「読み書き」が工業化している。20世紀半ばに始まった基礎研究が、テキストデータの整備や自然言語処理の進歩で、実際の問題に応用できるようになったからだ。短歌を自動生成する試みもある。専門誌では、なぜか、人間「らしさ」短歌「らしさ」が問題視された。その背景にはありふれたサイロ効果が観察される。短歌の共同体は構造的な供給過剰にあり、作品の自動生成はこの共同体の課題を改善しないと見られる。むしろ、それぞれの試みが何を短歌「らしさ」の根拠に置いたかを分析したほうがよい。市場の原理に沿わない歌群の評価手法が確立できる期待がある。
なぜ「らしさ」が問われるのか
2010年代の日本語による短歌を用いた自然言語処理は、人間「らしさ」を再現するために、短歌「らしさ」を生み出すアルゴリズムの設計を試みてきたと要約できる。その目標は2つに大別できる。A.自立した文章を生産-消費する「装置」を開発すること。昔ながらの「書き手/読み手(プレイヤー)」を模した、人間「らしさ」を作ること。B.価値を持ちうる文章が生産-消費される「条件」を明らかにすること。短歌「らしさ」を作り出す、「読み・書き(リテラシー)」の分解と再点検。
短歌の共同体では、他の言語表現がそうであるように、日常的に生産される短歌全体に占める、市場流通する歌群の割合が低い。人間「らしい」短歌「らしい」文章の生産-消費装置を作るよりも、共同体が抱えるボトルネックを特定し、対処する「条件」を分析したほうが有益だろう。B.の試みのほうが、現状改善に資するのではないか。しかしおそらく、この試みは共同体に歓迎されない。詳しい「条件」の開示はキュレーション(選歌)の権威への挑戦だと受け止められかねないし、偶然や偏りの介在しない選定には「ありがたみ」を感じにくいのが人情というものだから。
とはいえ、テキスト単体の性質評価は、読者自身の知識や経験を、むしろ介在させずに、テキストをどのような単位で、どんな分別法で、どのように数え上げ、いかにして読みとくかという問題に落とし込める。評価手法に恣意が入り込む余地はあるけれども、無防備な自分語りよりは透明性のある分析が行える。いくつかの揺るぎない規則で、基礎的な事実を導き出すことで、「当たり前に確からしいこと」の合意形成を促せる。私たちの分析は、おそらくそれに資する潜在性(ポテンシャル)がある。
解くべき問題
『光と私語』は短歌「らしくなさ」を志向する(と言われる)。本当にそうなのかを分析してみたい。「らしさ/らしくなさ」は5の視点で論じられる(1.個性、2.定型性、3.独自性、4.作為性、5.時代性)。ただし、十分なデータがなければ解けない問題もある。解けない問題に取り組むことは、求道的には正しいが、分析的には避けたほうがよい。
私たちが使える材料は、『光と私語』のテキストデータのみ。分析に用いたツールは、学術研究や私的使用の範囲で、個人の分析者がオープンにアクセスでき、分析結果を公表できるものに限る。先述した問題意識のうち、私たちが持ちうるデータと手法で解ける問題は、1-2.文体分析、2-2.連作単位の分析、2-3.歌集単位の分析の3通りだ。

私たちの関心
私たちには素材的な関心、手法的な関心、道具的な関心があった。現代短歌のテキストデータと、近年に登場した新しい自然言語処理アルゴリズムの両方を用いた分析は、私たちの最善によって知りうる限り、日本語圏ではまだ誰にも書かれていなかった。探せばあるのかもしれないが、少なくとも私たちにとっては初めてだったから、それだけでも試してみる理由になった。簡単にいえば、「おもしろそうだった」からだと言えば済むのかもしれない。
採用手法
今回の分析を行うために、私たちは、特定の著者が現代の口語で書いた、単一の歌集を分析対象とした。だから、複数の作品群の差は評価できないし、著者推定はそもそも必要ない。代わりに、1冊の歌集のなかで、連作の「流れ」がどのように構成されているかを明らかにしようとした。品詞(形態素)の含有率を基本指標とした統計を作成した。後述するように、私たちは音韻を変数に持つデータセットを作成していない。

データセット
『光と私語』の著者から快諾を受け、版元であるいぬのせなか座から、装釘前のテキストデータをMicrosoft Word形式で受け取った。それをGoogle SpreadSeetに1行ずつ転記したうえで、1首または1文に対して、通し番号と連作区分を採番した。出現順、句切れ、句またがり、約物の有無なども、そのデータセットに加えた。係り受け解析も先行例は多い。今回の分析に用いなかったが、それらに着目した分析も有益だろう。音数や音素も加えなかった。「読み」のリズムを分析するには、それらのメタデータを付与する必要がある。

形態素解析による語彙の計量
まず、juman++を用いた形態素解析を行って、抽出語数、異なり語数、品詞含有率といった基礎的な指標を算出した。
この歌集は約15%が「短歌じゃないかもしれない文章」で出来ている。よくある歌集なら、詞書くらいしか「短歌じゃない文章」を含まないから、この比率はさらに下がるだろう。このうち、「短歌じゃないかもしれない文書」は、0字から60字弱までばらついた分布をとる。それに比べて「短歌」は、20字前半から30字後半の間でより緊密に分布する。15語前後の行(文書)が100程度と最多で、10語前後が60弱、20語前後が40弱ある。その他の語数で作られたものは少数だった。1語が2~3字で構成されるとすれば、15語前後の短歌が多いことにもうなづける。

また、この歌集には名詞(1,151)が、動詞(579)の約1.98倍出現する。助詞(1,065)は名詞の92%ほどで、複合名詞や体現止めの分量が示唆される。形容詞(121)や副詞(103)は、名詞10回につき1回使われるかどうか。感動詞(1)や接続詞(4)、連体詞(7)はごく少ない。

語の出現頻度とその予測
続いて、頻出語ランキング、頻度分布を作成した。上位20%を占める語の出現頻度は全体の69.0%を占める。この歌集には、「いる」(53)が「する」(32)の1.6倍、「なる」(13)の4.0倍多く使われている。この歌集には、行為とその結果・変化よりも、持続や推移、状態を描く歌が多い。主体・客体の存在を言う「いる」の用法は少ない。また、「ない」(50)が「ある」(26)の1.9倍出現する。「否定」「不能」「不在」「回避」「禁止」「義務」などの用法で用いられる。この積み重ねが、この歌集のトーンを形づくっているのだろう。この歌集では、何かが失われ、消えている。作中主体は、明示されない制度に禁じられ、義務づけられる。作中客体には、できないことがあり、したくないことがある。そのような場面がしばしば描かれる。
この歌集には一人称と三人称がほとんど出現しない。代わりに「あなた」が多用される。それも、この歌集の読者に呼びかけるのではなく、作中主体の意識や視線の届くところに「いる/いない」客体として描かれる。「あなた」は都市生活の一場面のなかで、同伴したり、同居したり、同定される対象としてある。

この歌集に頻出する助詞・助動詞をみると、「の」(253)がもっとも多く、この歌集の総文書数(240)を上回る。「に」(159)「を」(147)が続く。「が」(107)「は」(103)はやや少ない。「と」「も」はより少ない。「、」が「が」「は」より多いことにも注目される。この歌集は、総じて人称の省略がしばしば行われるけれど、主題ないし主語の提示はあり、連体修飾で1首の骨子を作り、連用修飾で記述対象を指定する。そういった作りをしているのだろう。
助詞・助動詞の分布は、さらなる検証に値する。「の」(253)がもっとも多く、「が」「は」の総和(210)を上回るのはなぜか。この歌集の特徴か、現代短歌に共通して見られる性質か。「に」「を」「で」の多さは、この歌集が観察と描写に重心を置く(と見られる)ことと関わりがあるか。「と」「も」が少ないことは、この歌集が、事物の並立や共同、併存をことさらに強調しないことの傍証となるのか。

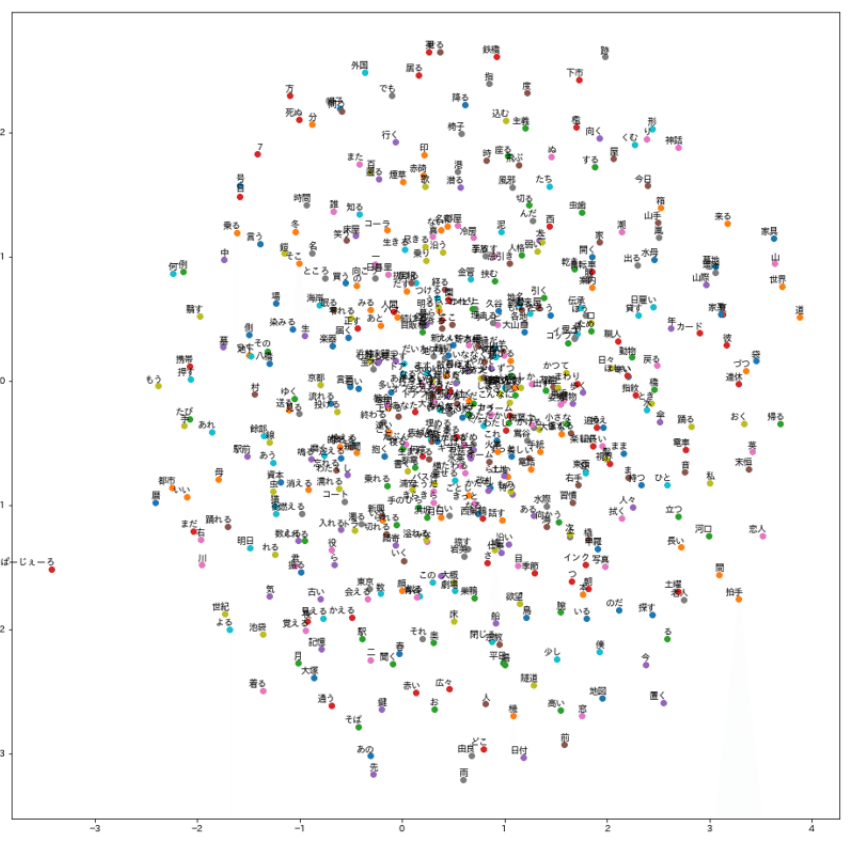
単語ベクトルによる類似度の学習
言葉の意味は、その語が置かれる文脈のなかで決まる。文脈とは、より大きな言語の総体から、いくつかの語群が選ばれ、何らかの規則に沿って並べられる順番から生まれる。よく似た文脈で扱われる単語は、意味が近いと言える。だとすれば、あるテキストが含むすべての単語が持ちうる文脈を、単語間の「位置」「距離」「角度」として数値化できれば、ひとが目視では気づけなかった、ある語の新しい意味を見出せないか。
このような着想をもとに、1980年代ごろから、単語をベクトル空間内の座標と見なし、ある単語と別の単語の関係を表現したり、類推する技術が考え出されてきた。それらの表現・技術は、「単語埋め込みベクトル」(または、縮めて単語ベクトル)を用いた「分散表現」などと呼ばれる。私たちも、この手法を取り入れて、この歌集から単語ベクトルの分散表現を得る教師なし学習を行うことにした。近代短歌への適用例は1つだけ見つかっている。現代短歌への適用は、日本で初めてかもしれない。
分析には、Facebookが公表するオープンソースライブラリ「fasttext」を用いた。word2vecの速いやつである。特定の品詞や散文を除外したうえで、単語ベクトル(500語)や連作ベクトルのt-SNE(t分布型確率的近傍埋め込み)を出力した。また、"あなた"を始めとして、本作に頻出する名詞と近い単語の抽出も試みた。
分かったのは、この歌集のなかでは、「あなた」は「わたし」と少し近くて、「私」からは遠い。「私」は「恋人」よりも「電車」に近い。「外国」は遠い。「死ぬ」のと同じくらい遠い。さらに、「あなた」から「私」を引き算したら分かったのは、「私」という語は、「存在(ある)」や「修辞(アネクドート)」に近づくような用法では使われていないのかもしれない。少なくとも、「あなた」ほどには。
極性分析による作品の変遷
さらに、Googleの極性分析APIである「sentiment analyzing」を用いて、1文ごとの肯定スコア、否定スコアを算出。文書単位、連作単位それぞれで集計した。その結果、この歌集のことがさらに分かった。全体として、肯定スコアが高い連作が多く、著しく否定スコアの高い連作は少ない。各章の初め(「わたしと」「大きい魚」「ともすると」)で盛り上がりが起こる。1章(「わたしと〜」から「部屋から〜」)と2章(「大きい魚〜」から「象亀〜」)は肯定的に始まり、段々盛り下がる。3章(「ともすると〜」から「明日の〜」)は、どれも肯定的で、段々盛り上がる。
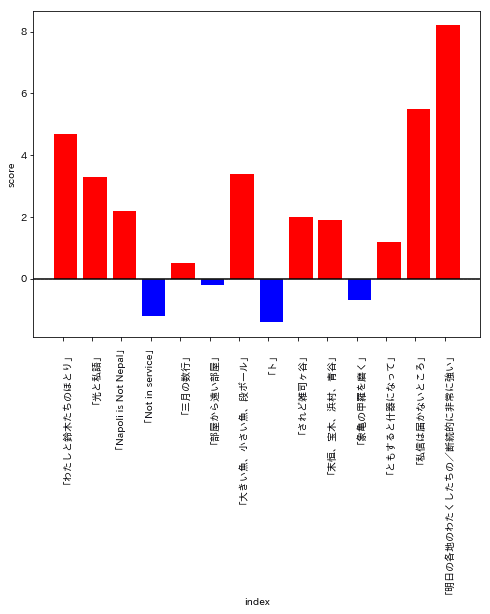
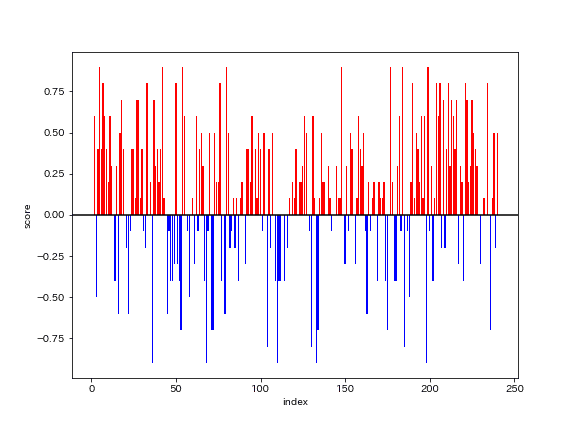
ニュートラルな歌は少ない。否定的なセンチメントの歌が集中的に出現するわけではなく、肯定/否定の起伏が、より細かい単位で生じている。1冊の歌集のなかで、極性スコアの起伏が数多く生じている。数え方次第だが、十数個の「やま」が作られている。また、ごく大まかにみて、1文目から150文目にかけて、ゆるやかな下降線を辿っていて、そこから230文あたりにかけて、大きな盛り上がりが続く。230文あたりで急落があって、240文目に向けて、もうひと盛り上がりがある。

著者によると、連作の構成にはいくつか定番があって、終盤で盛り上げるパターンもよく採用されるらしい。他の歌集でもやってみたい。極性の増減から散文のストーリー構成を評価できるように、短歌の連作にもストーリー構成の効果が観察できるとすれば、歌集の編集とその評価システムに、新しい観点を付け加えられるからだ。
いまのところ、「連作」や「歌集」の単位での客観的な分析は多くないようである。分析単位が大きくなり、共通理解が作りにくいからだろう。この分析結果は、いぬのせなか座の連続講座でも発表した。映像や文章、図像は、「作品」として鑑賞され、批評の語彙で語られるのに、図表・グラフには同じ語りが発動しなかった。言うまでもなく、それが芸術の暗黙の慣習だからで、その慣習が少しずつ変わっていけば、芸術表現と情報処理の根深く、しかし根拠のない断絶を埋められるようになる。
品詞構成の比較(他ジャンルとの)
この歌集はどのような文体で書かれているのか。一般文書とは異なる特徴が見られるか。大規模語彙コーパスBCCWJ、CSJの品詞別含有率を用いた。文書ごとの名詞率、用比率、相比率を集計し、BCCWJコーパス全体との差を計算した。

この歌集は、ベストセラー、国会議事録に似て、名詞が少なく、動詞と形容詞が多いと分かった。やはり韻文(短歌・俳句・詩歌)にも似ていた。けれども、他の韻文と比べると、動詞が多く、名詞と形容詞が少なかった。常識的な理解に反して、韻文(詩歌の言葉)は国会会議録(政治の言葉)やベストセラー(通俗の言葉)によく似ている。『光と私語』がそれらと似た性質を持つことは興味深い。ポピュラーであるとは言い切れないまでも、読み上げやすい文体であるとは言えるだろう。

つまるところ、『光と私語』は、どちらかといえば硬めの、話すように書く言葉に近い。とはいえやはり韻文の文体であり、韻文と同じかそれ以上に形容表現が多い。「短歌らしくなさ」は、名詞の少なさと動詞の多さを手がかりに説明できるかもしれない。
品詞率を用いた指標(MVR)による文書分類
そこで、連作ごとに、各品詞率を算出し、特徴ごとに分類した。名詞率とMVR(用比率/相比率)の2軸をとって、それぞれの平均値を補助線とする、四象限図を描画した。第1章、第2章、第3章ともに、特定の象限に偏った分布はしていないけれど、章ごとに、連作が進むにつれて、おおむね名詞率が高まると分かった。「ト」は韻律のない、ト書きのような単文が多く、動き描写的な文章だとの判定に整合する。

ちなみに、名詞率とMVRによる比較は、先行研究でもポピュラーな手法である。しかしこの手法では、名詞率が高く、MVRが高い文書の特徴が説明できない。それはいわば、形容表現に禁欲的な、「硬い、書き言葉」に近い文章である。新しい指標を考えたほうがいいのかもしれない。
異なり形態素比率による文体分析
最後に、異なり形態素比率による「文体診断ロゴーン」対象作との比較を行った。比較対象とした文書群の両極には、政治演説と哲学論考がある。政治演説は、ごく短いテキストのなかで話題を次々と変える分、異なり語数も増えてくる。哲学論考は、論理命題の展開によって同語反復が連続する。異なり語数が少ないのは、そのためだろう。
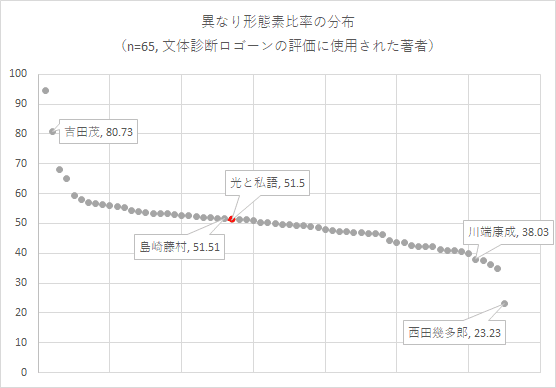
そして、40%-60%区間にほとんどの文芸書が含まれている。『光と私語』は51.5%で、中間的な位置づけにあった。ここから2つのことが言える。まず、『光と私語』は、とくに奇を衒って語彙を大きく見せたり、少なく見せようとしていない。スタンダードな語彙が選ばれていると言ってよい。「語彙の豊かさ」は文芸書を評価する初歩的な指標みたいに思われがちだけれど、どうやらそれは不正確な理解なのだろう。私たちがあるテキストに「語彙の豊かさ」を感じるとき、それは「実際に多くの語彙が用いられていること」ではなく、別の「何か」にその印象を抱いているのかもしれない。
結論1:「話す」ように「描く」
この歌集は模範的な構成と良心的な展開を持つテキストだ。連作ごとに明らかなまとまりがあり、終盤に向けて名詞が増え、肯定極性値が高まる。字数・語数の分布からして、定型性への挑戦は控えめで、異なり形態素比率からみて、スタンダードな語彙が選ばれていると言ってよい。品詞含有率からは、ベストセラーや国会会議録といった「話すように書く言葉」に近く、他の韻文よりも有り様描写的であると言える。
結論2:いくつのも「なさ」が続いて「いる」
この歌集には「ない」と「いる」が多用される。作中では何かが失われ、消えている(否定、不在)。作中主体は、明示されない制度に禁じられ、義務づけられる(禁止、義務)。作中客体には、できないことがあり、したくないことがある(不能、回避)。
結論3:「あなたの部屋」に届く「光と私語」
頻出する「あなた」をはじめとする被写体が、都市生活の一場面のなかで、作中主体の意識や視線の届くところで、持続し、推移している。そのあり様を描く。単語ベクトル平面のなかで、「あなた」は「わたし」と少し近くて、「私」からは遠い。「私」は「恋人」よりも「電車」に近い。「外国」は遠い。「死ぬ」のと同じくらい遠い。「部屋」は光が差し込む空間であり、配達物(乗り物の模型、不在通知、朝刊、便箋)が「届く」宛先でもある。

おわりに
たのしかった。豊富なテキストデータがあるなら機械学習を行える。もし少なくても、すぐにできる簡単な集計でもたくさんのことが分かる。まずはやってみることが大切だ。分析作業を通じて、初めてわかることもあった。歌集の構成要素が見え、機械学習アルゴリズムの癖も分かった。極性分析(ポジネガ分析)は、指標の算出式や、判定のもとにするコーパスによって結果が変わる。ポジネガ辞書の設計思想や計算方法を調べることで、物語(ストーリー、シナリオ、プロット)とは何かをめぐる、新しい視点が見いだせるかもしれない。単語埋め込みベクトルは、単独著者の単著ではなく、複数人の手による文書群に適用したほうが、思いがけない意味のつながりを見つけやすいかもしれない。品詞構成率は、ジャンルごとの基準値を算出して、全体と比べて月並みであるとか、突出しているとか言えるといい。
今回は、約物やかな・仮名変換など、表記レベルの分析には踏み込なかった。かっこや一字空け、改行の効果を分析する余地はある。句切れの判定や、係り受け構造との関係も重要だ。単語の出現順やページ数などの、時系列を考慮した分析も行わなかった。ひとことで「作品」と言っても、単語、文節、一文、連作、章、全体といった切り口によって、その性質は大きく変わってみえる。概念レベルの異なる関係性を評価できると、さらに発見があるだろう。ある単語の出現傾向が、連作の流れをどう方向づけるのか。提案手法はすでにいくつかある。文芸書の著者/読者にとって、何が分かると嬉しいかを先に考えたい。
ところで、データの調達が難しいと、テキスト分析を気軽に始めづらい。歌集を刊行する出版社が合同で、テキストデータのデジタルアーカイヴを構築し、学術研究のために専門家へ提供する仕組みが作られないものか。長い歳月をかけて、古典籍の研究がそうなったように。信頼できる書誌データも欠かせない。出版社の枠を越えたリストの元データが、研究者向けに開放されるだけでも意義はある。
著作 笠井康平 uni
協力 𠮷田恭大『光と私語』(いぬのせなか座)
この記事が気に入ったらサポートをしてみませんか?