
国立がん研究センターで、データサイエンス人材講義を実施しました

こんにちは、ヒューマノーム研究所の加藤です。
当社は、昨年の9月から今年の1月にかけて、国立がん研究センター東病院内講義「2023年度第3回データサイエンス人材開発セミナー」を担当しました。今回は講義とあわせて、受講者の皆様が参加するAI開発コンテストも開催し、こちらも無事に終了しました。
今回は、私達が携わった講義やコンテストを運営するなかで得た気づきや学びについてまとめました。
これからデータサイエンスを学ぶ方に少しでも参考になれば幸いです。
講義内容
講義はプログラミングは初心者の、機械学習/深層学習(AI)について学びたい方を対象として実施しました(図1)。講義は国立がんセンター東病院内で行いましたが、Zoomでのオンライン配信や、アーカイブ配信も実施しました。
実施期間は半年の長丁場、しかも土曜開催にもかかわらず、授業後アンケートは第1回で150名、第6回でも80名からの回答がありました。各回の参加者平均も100名を超えました。

第一回:AI入門 ノーコードツールによる画像認識AIの作成(9月2日)
第一回の講義は私が担当しました。
機械学習や深層学習の概要について紹介し、現在でも多くの分野で活用されている画像の物体検知について、当社が提供・開発するノーコードツール「Humanome Eyes」を使ったAIモデルを作成するまでの一連の流れを演習しました。
演習にノーコードツールを取り入れた理由は、まずは初学者のみなさまに画像のアノテーションと学習に触れ、機械学習の流れを体感いただくためです。機械学習を学ぶにあたってはある程度の専門用語を知る必要があります。この知識とツール操作を通じたAI開発の工程が結びつくことで、初心者の方でも機械学習の流れを理解しやすくなると考えました。

第二回:表データを可視化して、データの気持ちになる(9月30日)
第二回、第三回では、第一回で取り扱った画像データから趣向を変え、表形式データをつかった解析の基礎について学びました。第二回は当社が提供・開発するノーコードツール「Humanome CatData(以下「CatData」)」を使って可視化する流れを演習しました。
可視化を通じてデータのもつストーリーについて想像し、「こういうデータであれば、AI開発に使いやすい」という勘所を理解できるようになることを目標としました。

第三回:表データを用いた機械学習の流れを理解する(10月14日)
第三回は、前回に引き続き表形式データを使ったデータ解析の基礎について、CatDataの操作を通じて学びました。今回は可視化からさらにステップアップして、機械学習で使われる用語の説明や表形式データを機械学習させた時のAIモデルの性能の確認方法まで、丁寧に演習しました。
今回は参加者の方に前回使ったデータよりもくせのある、欠損値や外れ値があるデータを使い、解析につきもののトライアンドエラーに取り組んでいただきました。

第四回:Pythonで実践する表データ可視化の入門(10月28日)
第四回は、いよいよノーコードツールを卒業し、Pythonを用いたプログラミング演習に入りました。プログラミング初心者にもわかりやすいように、プログラムの概念からPythonの文法など、解析に必要とされる基礎的な内容についてGoogle Colabを使って演習しました。
受講後のアンケートでは、難しいと感じた人と簡単と感じた人が同程度であったものの満足度は概ね高く、まず大きな流れを知ったあとに専門的な知識を学ぶ、というステップアップの効果を感じました。

第五回:Pythonで機械学習の実施(11月11日)
第五回はふたたび私が講師を担当しました。
今回はさらに深層学習の実践的な内容をPythonで演習する内容でした。正直、Pythonをはじめて半月の人にこのレベルを理解してもらうのはとても難しいのですが、この講義を通じてPythonで深層学習する道筋を示すために、これからAI解析に携わる方にはここまでは理解してほしい、という内容をスパルタで実施しました。
一般的に、セグメンテーションは公開されているデータセットも少ないので手軽に試せない事が多いです。そこで今回は過去に私が作成していたセグメンテーションのサンプルプログラムを使い、自動でデータセットを生成しました。
また、Google Colabでポチポチするだけで簡単に実行できるようにカスタマイズしたり、一部のパラメータを変えることで精度が劇的に改善する過程も紹介しました。
Google Colabは、何度も繰り返しGPUを使用した時の制限さえなければとても快適ですね。
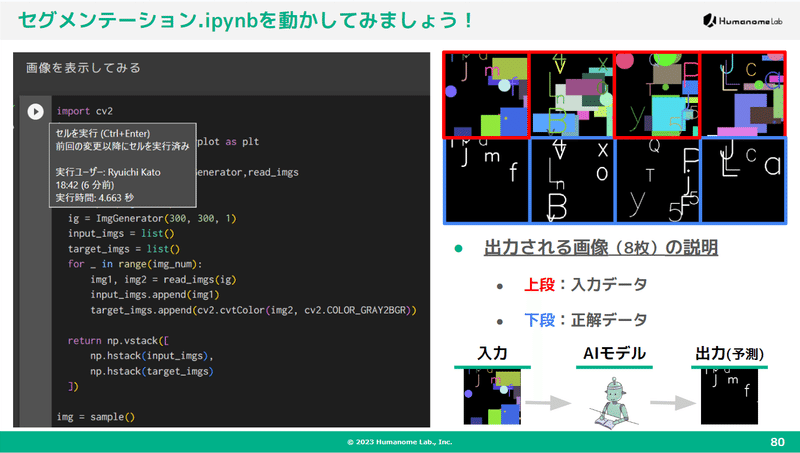
第六回:ChatGPTを活用したPythonプログラミング(12月9日)
最終回となる第六回は対話型AI・ChatGPTを使ったプログラミングに関する講義を実施しました。ChatGPTの紹介に始まり、ChatGPTを活用したプログラミングのアイデアなどを紹介しました。
初心者がつまづきがちなエラーメッセージへの対応方法をChatGPTに解説してもらう方法については、受講者から「今まで見いだせなかったChatGPTの利用方法を知ることができました」という感想もあり、好評だったようです。

コンテスト(1月13日)
講義の番外編として、受講者の方を対象に、これまでの講義で得られたことを活かし様々な課題に挑戦してもらい、その結果を報告してもらうコンテストを実施しました。
このコンテストには10名以上の方に参加いただきました。
講義を受けるだけにとどまらず、自身の私生活や研究にノーコードツールやPythonを活用するという非常にモチベーションの高い方がこれだけ集まったことに大変驚きました。
さらに、発表内容も第五回のハイレベルな内容をさらに超えてくる参加者の方や、面白い視点で問題に取り組んでいる方など、当初私が想定していたよりもかなり充実した会となりました。いい結果が得られなかったという発表者もいたのですが、もう一工夫すると良い結果につながりそうという道筋が見えていたのが良かったです。

講義を通じて得られたこと
この講義は5名で資料作成から当日運営まで実施しましたが、メンバー全員で一丸となって取り組んだ結果、大きなトラブルもなく無事に終了することができました。この講義を通して得られたことはたくさんありました。
ハイブリッド開催は大変だし、アーカイブ配信まで考えるともっと大変
現地要員として、登壇者の他にもトラブル対応に数名が必要となり、さらにオンライン参加者も多かったため、毎回3~4人が当日待機していました。人的コストが想定よりもかかってしまった点については、次回以降改善していきます。
ハイブリッド開催かつ演習を含めた講義というのは、とても難しいなというのを実感しました。
難しさと面白さの二軸が大切
受講者の層にもよりますが、難しい授業が良くないかというとそうでもないことがわかりました。第一回から、各回の終了時にアンケートを取っており、講義の難易度についても調査していたのですが、第三回からは満足度もあわせて調査することにしました。
今回、特に第五回の講義は難しい内容だったので6割以上の方が「難しい」もしくは「少し難しい」と回答していたのですが、8割以上の方は不満がなかったと回答していました。つまり「難しかったけど満足した」という層が一定数いたことが推測できます。また、第六回のChatGPTの回は最も満足度が高いという事もわかりました。


おわりに
全六回、半年に渡る講義でしたが、多くの方に継続して参加していただけたことに心から感謝申し上げます。
また、関係各所へのフォローや講義内容に対するアドバイスなど、親身になってご対応くださった国立がん研究センター東病院の先生方、TAとして我々をサポートしてくださった学生さんのサポートなど、多くの皆様の支えがあってこの講義は成り立っていました。重ね重ねになりますが、本当にありがとうございました。
ここで得られた知見をさらにブラッシュアップし、今後に活かします。そしてまた、今回のような授業を通して、みなさまにデータサイエンスの楽しさをお伝えできる機会があることを願っています。
データ解析・AI構築の初学者向け自習テキスト
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?