
【検証】古典籍の全文検索はできるのか【くずし字OCR/#次世代デジタルライブラリー/#NDL全文使ってみた】

本稿では、「次世代デジタルライブラリー」で用いられたNDL古典籍OCRの精度について、検証します。
古典籍20本の可読状況を可読率順に確認し、可読状況について、若干の考察を行います。
はじめに
国立国会図書館の実見的な検索サービス、「次世代デジタルライブラリー」に6万点の古典籍資料が追加され、古典籍資料の全文検索が可能となりました。
「次世代デジタルライブラリー」は国立国会図書館デジタルコレクションで公開されている図書と古典籍資料約35万点を独自のOCRにかけ、全文検索を可能にしたサイトです。
これにより、今までくずし字で読めなかった資料についても、全文を検索することができるようになりました。しかも、OCRの結果を公開しており、ダウンロードもできるので、普通に翻刻資料としても利用することができます。
AIくずし字OCRとしては、人文学オープンデータ共同利用センターが公開しているKuroNrtや、スマホアプリのみを(miwo)があります。
昨年このサービスのOCRの精度を検証しました。
可読率が95%と言うことなのですが、実際には、資料によってバラつきがあり、読めない本は読めず、読める本は良く読めるというのが現状です。
くずし字OCRはまだまだ万全と言えるものではありませんでした。
みを(miwo)は2022年10月にRURI(瑠璃)にバージョンアップしていますし、来年三月には凸版印刷のAI-OCR「ふみのは」が正式リリース予定です。
これから益々発展していく分野だと言えます。
「次世代デジタルライブラリー」は全文検索というOCRの次の段階のサービスを展開しており、このサービスをいかに活用していくか、も大事なことなのですが、そもそもOCRの精度がどの程度なのかは重要な問題です。
全文検索に耐え得る精度のOCRなのか、これを確かめないではいられません。
国立国会図書館デジタルコレクションでは、あらゆるジャンルが取り揃っていますが、私は国文畑なので、国文関係の資料に絞って確認します。
取り上げたい作品は多いのですが、全て扱うとキャパオーバーなので、苦渋の選択で絞った20種類を紹介します。
国立国会図書館デジタルコレクションには古活字本や版本が多く、古写本は数が少ない印象があります。
作品自体は古くても、書写や出版が新しければ紙面の雰囲気も異なりますし、読みやすさにも違いが出ます。その辺りも考慮して、なるべく字形や紙面の異なるものを集めたつもりです。
また、11月1日に追加されたのは「古典籍資料」ということですが、影印など、近代以降の出版でも、古典籍同様に扱えるものがあるので、これも検討範囲に加えています。
活字を読むNDLOCRと、くずし字を読むNDL古典籍OCRがありますが、複製本のくずし字もちゃんと読んでいるので、おそらく精度に差はないでしょう。
動画では上代韻文から近世散文まで、一応時代順に紹介したのですが、noteでは可読率の高い順で紹介します。
古典籍20本の可読状況確認
99.3%平家物語 古活字版中院本
20本確認したなかで、最もよく読めていたのは、古活字本の中でも中院本の『平家物語』でした。
99.3%は驚異的な数字です。

平家物語第一
たゝもりせうてんの事
祇園しやうしやのかねのこゑ。しよきやう
むしやうのひゝきあり。しやらさうしゆの
花の色。しやうしやひつすいのことはりを
あらはす。をこれる人も久しからす。たゝ
春の夜の夢のことし。たけきものもつゐに
ほろふ。ひとへに風の前のちりに同し。とを
くいてうのせんせうをとふらへは。しんの
てうかう。かんのわうまう。りやうのしゆう
平家物語第一
たくもりせうてんの事
祇園しやうしやのかねのこゑ。しよきやう
むしやうのひゝきありしやらさうしゆの
花の色しやうしやひつすいのことはりを
あらはす。をこれる人も久しからす。たゝ
春の夜の夢のことし。たけきものもつゐに
ほろふ。ひとへに風の前のちりに同し。とを
くいてうのせんせうをとふらへは。しんの
てうかう。かんのわうまう。りやうのしゆう
バッチリ文字を捉えて認識しており、読み間違いも踊り字が「く」になっている一例のみです。
抜けているところもありますが、句読点も読んでいます。特に句読点は、他では抜けていることが多いので、ここまで認識しているのは凄いことです。
間違えているところがないと、特に指摘するところもないのですね。
94%宇津保物語
次は『宇津保物語』です。
近世に写された写本ですが、かなり綺麗に認識しています。

〈今はイ〉
むかし式部大輔左大弁かけて清原の大君〈有けり〉御
こはらにおのこ子一人もたりそのこ心のさとき
事かきりなし父はゝいとあやしきこなりお
ひいてむやうをみむとてふみ〈うたイ〉もよませすいひお
しふることもなくておほしたつるに年にもあは
すたけたかく心かしこし七歳になる年ちゝかこ
まうとにあふにこのなゝとせなるこ父をもときて
こまうとゝふみつくりかはしけれはおほやけきこ
しめしてあやしうめつらしき事なりいかて心み
むとおほすほとに十二歳にてかうふりしつみかと
むかし式部大輔左大弁かけて清原の大君御
酉けり
こはらにおのこ子一人もたりそのこ心のさとき
事かきりなし父はゝいとあやしきこなりお
もいてむやうをみむとてふみもよませすいひお
しふまこともなくておほしたつるに年にもあは
すたけたかく心かしめ七歳になる年ちゝかこ
まうとにあふにこのな■と勢なるこ父をもときて
こまうとくふみつくりかはしけれはおほやけきこ
しめしてあやしうめつらしき事なりいかて心み
むとおほすほとに十二歳にてかうふりしつみかと
朱印が被っていますが、抜けはありません。
読み間違いも、朱印の所為ではなく、字形の近さが原因でしょう。
書入れは〈今はイ〉〈有けり〉〈うたイ〉の三つあります。
〈有けり〉の一つだけ認識していますが、〈酉けり〉になっていますね。
後ろから二行目の「めつらし」には虫食いがありますが、なぜかちゃんと読めています。
92.9%風葉和歌集 丹鶴叢書
丹鶴叢書は紀州藩付家老で新宮城 (丹鶴城) 主の水野忠央が中心となって編集した叢書です。今回はその内、『風葉和歌集』を取り上げます。
『風葉和歌集』は、平安時代から鎌倉時代初期にかけての、だいたい200作品ぐらいの作り物語から、そこで詠まれた和歌を集めた歌集です。現存物語は24しかありませんので、散佚物語の世界を垣間見ることができます。
版本で、紙面は綺麗ですね。とても読みやすそうです。

丹鶴叢書 辛亥帙
故榊原芳埜納本 榊原家蔵
従五位下行土佐守源朝臣忠央輯刻
やまとうたはやくもたついつもやへかきにはし
まりならのはの名におふ宮にあつめられしより
ことのはしのたのもりのちえよりもしけくえら
はらるゝこともうらのはまゆふたひかさなりぬるに
つくりものかたりのうたといふものなむいつはりな
れたる人のいひ出たることにのみなりてまめなる所
にはほにいたすへきにもあらさめれはわかの
辛亥映
最書
上宦
故■原芳禁納本
従五位下行土佐守源朝臣忠史輯刻
やまとうたはやくもたついつもやへかきにはし
まりならのはの名におふ宮にあつめられしより
ことのはしのた■■りのちえよりもしけくえら
はらるゝこともうらのはまゆふたひかさなりぬるに
つくりものかたりのうたといふものなむいつはりな
れたる人のいひ出たることにのみなりてまめなる所
にはほにいたすへきにもあらさめれはわかの
牛鳥支旧
上に付箋があります。その付箋をペラっと捲った状態の写真なのですが、墨が透けて見えているので、文字と認識してしまっています。ただ、当然まったく読めないので、□□になっていました。
冒頭三行は丹鶴叢書のもので、風葉和歌集ではありませんが、確認してみましょう。
朱印が重なっていて上手く読めていないところが目立ちますが、全体としては読めている方ではないかと思います。
「故榊原芳埜納本」は認識していますが「榊原家蔵」は認識しないんですね。
『風葉和歌集』の序文はさらに良く読めています。
二文字抜けがありますが、読み間違えているところはなく、非常に惜しいです。
柱に「丹鶴叢書」とありますが、折り目なので半分になっており、正しく読めていません。
まぁこれは許容範囲でしょう。
92%万葉代匠記 初稿本
契沖の『万葉代匠記』は近世の注釈書ですが、現在も必ず参照される重要な注釈書です。

万葉巻第一上
此集を萬葉となつくること萬は十千也和語には
與呂豆といふ今はかならす十千にかきるにあらす
たゝ物のおほかるをいふ也史記魏世家にいはく萬満也
左傳にいはく萬盈数也荘子秋水篇には號物之数
謂之萬といひ則陽篇には今計物之数不止於萬
而期曰萬物有以数之多者號而読之也といへり
此心也葉の字はこれにふたつの義有ひとつには世の義毛
萇か詩傳に葉世也といへり葉の字世の字ともに
與とも津疑ともよめり父子相かはるを世といひ或は
三十年をも世といふ文選左太仲か呉郁〈都賦〉には雖累
万葉巻第■■
紫を万葉となつくること万は十千也和語には
与昌豆といふ今はかならす十千にかきるにあらす
たゝ物のおほかるをいふ也史記魏世家にいはく万満也
た傳にいはく万孟数也荘子秋水篇には号物之数
謂之万といひ則陽篇にハ今計物之数不止於万
而期曰万物有以数之多者号而読之也といへり
此心也葉の字はこれにふたつの義有ひとつには世の義も
長か詩傳に葉世也といへり葉の字世の字ともに
与ともつともよめり父子相かはるを世といひ或は
三十年をも世といふ文選左太仲か呉都に■維景
OCRは結構認識できています。
抜けているのは内題の「一上」の二文字と、末尾の虫に食われている「は」と、同じく末尾の訂正で朱書きされた〈都賦〉の三箇所だけでした。
冒頭の「此集」は「紫」の一文字になってしまっています。
末尾の「尓」は虫食いで削れていますが、しっかり読めていますね。
大方の旧字体は新字体に直されていますが、傳など、直されていない文字もあります。
萬→万 號→号 與→与 數→数 讀→読
88.8%小倉百人一首
続いて『小倉百人一首』です。
延宝8年の版本で、歌人絵と歌が書かれています。
歌も意匠的に書かれているので、どうでしょうか。

天智天皇
秋の田の
かりほの
庵の苫を
あらみ
わかころも
手は
露にぬれつゝ
持統天皇
春過て
夏きに
けらし白妙
の
ころも
ほすてふ
あまのかく山
《天智》天智天皇《□》
秋の田の
かりその
庵の苫を《苫を》
あら□
わかころも
手は
露にぬれつゝ
持統天皇
春過て
夏きに
けはし白妙
の
ころも
ほすてふ
あまのかく■
文字をしっかり捉えて、認識していますね。
少し抜けや間違いがありますが、全体としてはよく読めています。
第一首の第二句「かりほの」が「かりその」になっています。
「ほ」の字母「本」の最後の点が抜けているので、「曽」と判断したのでしょう。
もう1コマ見てみましょう。

柿本人丸
あし
曳の
山とりの
尾の
したりおの
なか〳〵し夜を
独かもねむ
山邊赤人
田子のうらに
うち出て
見れは
白妙の
ふしの
たかねに
雪はふりつゝ
■■■■
《同》一のし
曳の
山とりの
尾の
したりおの
なか■し夜を《夜を》
独かもねむ
山邊赤■
田子のうらに《ヲ》
うち出て
見れは
泉■の
ふしの
たかねに
雪はふりつゝ
これは、「柿本人丸」と赤人の「人」が認識されていません。
疊の縁と被っているのが原因でしょうか。
第三首、「あし曳の」の一文字目「あ」の字母は「阿」ですが、こざとへんが別に認識されてしまっています。
第四首、「田子のうらに」の「に」も、右側を別に読んでしまっている上に、「こ」とかなら分かるのですが、「ヲ」と読んでいます。
また、第二首では「白妙」をちゃんと読んでいましたが、第四首では「泉」になっています。
88.7%古今著聞集
説話集からは『古今著聞集』をもってきました。
せっかくなので、巻第四の文学を確認してみましょう。

古今著聞集巻第四
文学弟五
伏犠(フクキ)号氏の天下に王としてはしめて書契を
つくりて縄をむすひし政にかへ給ひしより文籍
なれり孔丘の仁義礼智信をひろめしより此道
さかり也書ニ曰ク玉不レハ琢不成器ニ人不レハ学不知道ヲ
又云弘風導俗莫尚於文敷教訓氏莫善於
学文学の用たる蓋かくのことし
應神天皇十五年に百済国より博士経典を相
具して来りしかうして後経史我国に学ひつ
たへたり抑詩は志(コヽロサシノ)の行所也心にあるを志とす
古今著聞集巻第四
文学弟五
伏蟻号氏の天下に王としてはしめて書契を
つくりて縄をむすひし政にかへ給ひしより文籍
なれり孔丘の仁義乱智信をひろめしより此道
さかり也書ニ曰ク玉不レルニトレ斑レ必レ器ニ不ル子不一レ知レ道ニ
又云弘風導俗莫尚於文敷教訓氏莫善於
学文学の用たる蓋かくのことし
應神天皇十五年に百済国より転七経典を相
具して来りしかうして後経史我国に学ひつ
たへたり抑詩は志の行所也心にあるを志とす
礼記を引用しているところには、訓点が付されているため、かなり頑張って読んでいますが、正しくはありません。
書ニ曰ク玉不レハ琢不成器ニ人不レハ学不知道ヲ
書曰、玉不琢不成器、人不学不知道
玉琢かざれば器を成さず、人学ばざれば道を知らず
訓点を含めると白文での検索では見つからなくなるので、難しいところですね。欲を言えば、白文と訓点アリの両方で検索できるといいのですが……。
漢字が並んでいるところに片仮名が小さく書かれていたら訓点と判断して処理するみたいな。
まぁ言うは易しですが、いずれにしても統一的な扱いができていると検索もしやすくなる気がします。
個人的に、読みにくいタイプの文字ではないかと思っていたのですが、訓点を除けば、かなりよく読めている方ではないでしょうか。
88.3%平家物語 古活字版下村本
古活字本『平家物語』は二つ目ですが、これは下村本です。

平家物語巻第一
祇園精舎
祇園精舎の鐘の聲諸行無常の響(キ)あり
沙羅雙樹の花の色盛者必衰の理(ハリ)を顕す
奢れる人もひさしからすたゝ春の夜の
夢のことし猛き者も遂にはほろひぬ偏に
風の前の塵に同し遠く異朝をとふらへは
秦の趙高漢の王奔(マウ)梁の周伊唐の禄山
是等は皆𦾔主先皇の政(ト)にもしたかはす
楽を極め諫(メ)をも思入す天下の乱ん事を
平家物語巻第一
十
祇園精舎
祇園精舎は鐘の聲諸行無常の響あり
沙羅■樹洗花の色盛は必衰の理を顕す
奢れる人もひさしからすたゝ春の夜洗
夢ことし猛きしも遂にはほろひぬ偏に
風の前の塵に同し遠く異朝をとふらへは
秦悦趙高漢法王華梁の周伊店の禄山
是等は皆旧王先皇の政とにもしたかはす
楽を極め諫をも思入す天下の乱ん事を
中院本『平家物語』と比べると読み間違いは増えていますが、これもしっかり認識していますね。
内題の下の汚れを読んでしまっている他、五つある送り仮名の内、トの一例のみ読んでいます。
良く見ると漢字に濁点が打ってあるのですが、これはどうしようもありませんね。
読み間違いを確認してみると、
「は」になっている文字は、「農」を崩したノや、ハの字母にもなっている「者」です。
祇園精舎「は」→者→農→の
盛「は」必衰 →者
「洗」になっている文字は、サンズイのある濃でした。
沙羅双樹「洗」花の色 →濃→の
春の夜「洗」夢■ことし→濃→の
なんだか納得してしまう間違いですね。
86.7%河海抄
古典の本文は整備され、検索の便も多くありますが、注釈書はまだまだそこまで整備されていません。個人的には、古典の本文よりも、古注釈書の本文が検索できた方がありがたいです。
そこで、『源氏物語』の注釈書から、『河海抄』を確認してみたいと思います。
『河海抄』は室町初期に四辻善成が著したもので、非常に多くの文献を引用しており、「文献学者の参考とすべき宝典(源氏物語事典)」と言われています。この中身が検索できれば、言うことないですね。
みんな大好き若紫巻を見てみましょう。

河海抄巻第三
正六位上物語博士源惟良撰
第三若紫
巻名
てにつみていつしかもみむ紫のねにかよひける野への若草
わらはやみにわつらひ給て 巻頭詞
ワラハヤミ ヲコリ キヤ
瘧病 痁〈俗云発心地也〉 瘧疾〈二日に一度発也〉
可海抄巻第三
■参位上物語博士源惟良撰
《右筆三》一筆三若紫《いふ紫》
巻前
てにつみていつしかも見む紫の祝にかよひけき野への若原
わらはやみにわつらひ給て 巻頭詞《巻頭記》
ワラハヤミ ヲコリ キヤ 《二日に一度》
《病》■病店《店》 仕云敷心地也 痛上候二日に一度■■
確認してみると、かなり文字を捉えていますね。
抜けることの多かったルビも認識しています。
ついでに二重に認識しているところも6カ所あります。

きた山になにかし寺といふ所に
キタヤマ
向南山 万葉
万
北山にたなひく空のあをくものほしわかれかく月もわかれて
此寺鞍馬寺也昔四十九院ありけり仏法盛地也云々
河原院をなかにかしの院といふ同躰也
六帖哥にさゝ波やしかの山ちのつゝらおりくる人たえ
てかれやしぬらん 此哥につきてつゝらおりは
きた山になにかしちといふ所に
キタヤマ
向南山万葉
□
北山にさつひる雲のあをたものほしわかねかく月もわかりて《わかれて》
此寺鞍馬寺也昔四十九院ありけり仏法或地也々
河原法をなかにかしの院といふ同躰也
六帖哥にさく波やしかの山ちのつゝらおりくる人た■
てかれやしはらん此哥につきてつゝらおりは
読み間違いがまばらにありますが、まぁまぁ読めているのではないでしょうか。
ただ、流石に54帖もある『源氏物語』の注釈書ですから、もう少し精度が高いと嬉しいですね。
79.1%古事記伝
『古事記』の注釈書、本居宣長の『古事記伝』です。
これは美麗ですし、文字も整然と並んでいるのでかなり期待できますね。
序文の注から見ていきましょう。

臣安萬伯言ス。夫レ混元既ニ凝テ。気象未タ効(アラハレ)。無ク名モ無シ為モ。誰レカ知ム其ノ形ヲ。
此(コ)は天地のいまだ剖(ワカ)れざりし前(マヘ)の状(アリサマ)を。漢籍(カラブミ)に云る
趣もて云るなり。混元は混沌ともいひで。元気未タ分レ也
と註せり。既ニ凝ルとは。分れむとするきざしあるなり。気
象は。天地を始め凡て気と象とをいへり。
然シテ乾坤初テ分レテ。参神作(ナシ)造化ノ之首(ハジメヲ)。陰陽斯開ケテ。二霊為リ群品ノ之祖。
参神は。天之御中主高御産巣日神産巣日の三柱ノ神を
臣安萬伯言夫■元既疑気象未故無名無為謀知其形
此は天地のいまだ剖れざりし前の状を■籍に云る
趣もて云るなり混元は混ともいひで元気未分也
と註せり■凝とは分れむとするきざしあるなり気
象は天地を始め凡天気と象とをいへり
然乾坤初分参神作造化之首陰陽斯■二霊為群品之祖
参神は天之御中主高御産巣日神産菓日の三柱神を
予想通り綺麗に認識しています。
ただ、『古事記』の本文に付されている訓点は、全く読まれていません。

申す。即チ本文の始メに出ツ。造化は漢籍に。天地陰陽の運行(ハコビ)
によりて。萬ノ物の成リ出るをいへり。二霊は伊邪那岐伊
邪那美二柱ノ神を申す。群品は萬の物なり。此処(コヽ)の文二
句づゝ対にかけり。次〻もみな対句なり。さて此序の
此ノあたりの文を見て。陰陽乾坤などの説を。古ヘノ伝ヘにも
其ノ意ありければこそ。撰者もかく取リ用ひられつらむ
を。ひたぶるに廃(ステ)むこといかゞと思ふ人あるべけれ
ど。然らず。もし古伝に其ノ意あらむには。序ノ文の短き間ダ
にすら。かくあまた云ヘるほどなれば。本文にも必ス言イフべ
きわざなるに。本文に至(ナリ)ては。一字もさることなし。さ
申す即本文の始に出造化は漢籍に天地陰陽の運行
によりて万物の成出るをいへり二■は伊■那岐伊
邪那美二柱神を申す群品は万の物なり此処の文二
向びし対にかけり次々もみな対句なりさて此序の
此あたりの文を見て陰陽乾坤などの説を古伝にも
其意ありければこそ撰者もかく取用ひられ都ら年
をひたぶるに廃むこといかゞは思ふ人あるべけれ
ど。然らずもし古伝に其意あらむには■文の短き間
にすら。かくあまた云るほどなれ。安本文にも必言べ
きわざなるに本文に至ては。一字もさることなし。さ
○古事記伝二
この版本にはくずし字に濁点が打ってありますが、これをしっかり反映していて凄いです。
句読点は、最初全く読んでいなかったのですが、最後の数行だけまばらに読んでいます。
77.1%萬葉集 清水濱臣本
清水濱臣の『萬葉集』を確認します。
漢字本文の横に小字で朱の訓と、墨の注が書かれています。
注の内容は濱臣のものではないらしいのですが、手書きで書かれているので、どこまで読めているかは気になるところです。

萬葉集巻十九
天平勝寶二年三月一日之暮眺矚春苑
桃李花作歌二首
〈以下専ら家持郷の歌なり〉
春苑紅尓保布桃花下照道尓出立𡢳嬬
はるのそのくれなゐにほふもゝのはなしたてるみちにいでたつをとめ
花の如きをとめが桃花の木の下に出立たるが花の(も)をとめも
共に艶を増たるさまなりしたてるの詞は赤き事をいひて
既に出
吾園之李花可庭尓落波太禮能未遺
有可母
万草集巻十九
天平勝宝二年三月一日之暮眺二属春苑
桃李花一作歌二首
以下専ら家持郷の歌なり
春苑紅尓保布桃花下照道尓出立■■
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
花の如きなとめが桃花の木の下に出立たるが花のをとめも
共に艶を増たるさまなりしたてるの詞は赤き事をいひて
既に出し
吾園之李花可庭尓落波太礼能未遺
有可母
朱の書入れが抜けていますね。
これは次のページでも同じく抜けていたので、認識するのが難しいのでしょう。
この朱の書入れ訓さへ除けば、かなり読めているのではないでしょうか。
結句「𡢳嬬」の部分が複雑なためか、認識範囲には入っていますが、活字にはなっていません。
内題の「萬葉集」が「草」になっているのは、朱印の枠が重なって認識できなかったのでしょう。
76.7%土佐日記解 田中大秀草稿
『土左日記』の近世注釈書を取り上げます。
これには夥しい書き込みがあり、文字が小さすぎて拡大しないと読めません。
田中大秀が『土佐日記解』を著したときの草稿で、ここに書き入れられた修正の殆どを反映したものが、活字本になっています。
折口信夫編『土佐日記解 田中大秀』(国文学註釈叢書)名著刊行会 182コマ
https://dl.ndl.go.jp/info:ndljp/pid/1218147
国文名著刊行会『土佐日記古註大成』(日本文学古註大成 第5巻)国文名著刊行会 184コマ
https://dl.ndl.go.jp/info:ndljp/pid/1236934
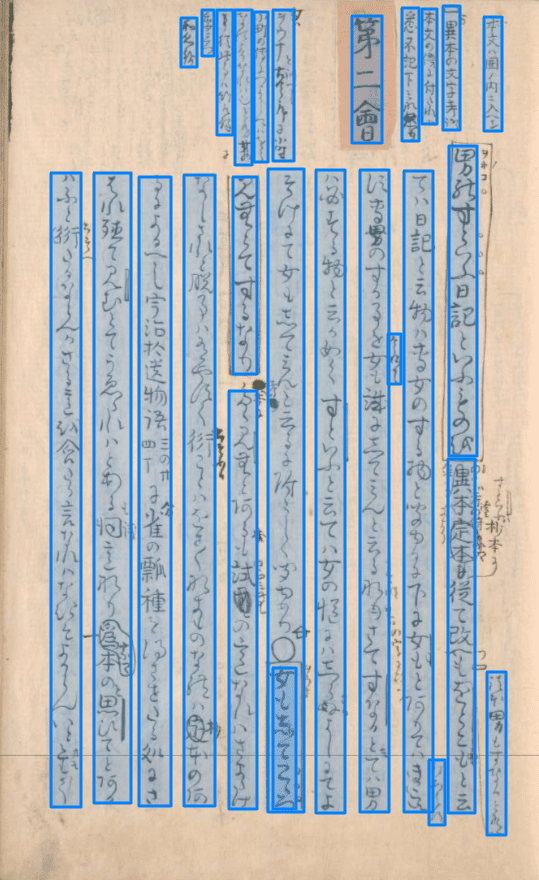
最初の1行を確認してみましょう。
ヲト(ノ)コ
男のすといふ日記といふものを(の字は考(証)の傍に家卿)(注たる)
異本(により)定本に(すといふは抄本に)従て改へ(←見消)(つ)し(←見消)(証本男もすなると有)をとこもと云
諸本男もすなると有
男のすといふ日記というものを
異本定本も従て改へもをとこもと云
「男のすといふ日記といふものを」という土佐日記の本文に対して、注が付いています。
注の本文は、もと「異本定本に従いて改べし」とあったのですが、書き入れたり、消したりして、「の字は、考証の傍に家卿注たる異本により、すといふは、抄本に従いて改つ」となっています。
OCRは書入れを悉く認識していないので、もとの文が活字になっています。
「改へし」の「へし」は、チョンチョンと点を打つことで、文字を消しています(見セ消チ)。
そのせいで、OCRでは「も」と読んでいます。
続きの文は、書入れさへ除けば、かなりよく読めています。
ては日記と云物は専女のする物と聞ゆるに下に女もとありてはき(←見消)こ(←見消)え(←見消)(打あはす)
す専男のする事を(今始て)女も試にしてみんと云る(にて明)な(れはの字に改つ)り(←見消)さてすなると(云)ては男
は必する物と云か如くすといふと云ては女の慥にはしらぬ(←見消)(さる)よしにてよ
そけにて女もしてみんと云るに附〻しく聞ゆめり
打あはす
ては日記と云物は専女のする物と聞ゆるに下に女もとありてはきこえ
けられて
す専男のする事を女も誠にしてみんと云るなりさてすなるとては男
は必する物と云か如く寸といふと云ては女の慥にはしらぬよしにてよ
そけにて女もしてみんと云るに附々しく聞ゆめり
二行目末尾、「きこえず」とあるところ、ここも見セ消チにして「打あはず」としています。
癖があって読みにくいのではないかと思うのですが、両方綺麗に読めているのは却って奇妙な感じがします。
○女(ヲウナ)もしてこゝろ
みむとてするなり
(考証-抄本に)
たゝみむとある(本(←消))も試(コヽロミむ)む(←消)の意なれはさまたけ
なしされと脱事は有やすく(書そふる)衍ことはをさ〳〵なきものなれは定(抄)本のあ
るによるへし宇治拾遺物語〈三の廿四丁〉に雀の瓢種を得させたる処にさ
はれ殖てみむとてうゑたれはとある(も)同(←見消)(試)意なり爲(家卿)本の(と)思ひてとある
はふと衍(←見消)(書そへ)たるならんかさる意を含たる意なれはなきそよからんいと重(オモ)く
「きこえたり」
○女もじてこゝろ
《女もしてこゝろ》
見むとてするなり
たゝみむとあるも試みの意なれはさまたけ
なしされと腹事は有やすく行ことはをす■なまものなれは近本のあ
はれ殖て見むとてうゑられはとある同意なり為本の思ひてとあか
るによるへし宇治拾遺物語四丁の廿に雀の瓢種を得させたる処にさ
はふと行たるならんかさる意を含たる言なれはないそよからんいと無して
後半「女もしてこゝろみむとてするなり」以降の注も、認識はできていますし、抜けも殆どありませんが、読み間違いが増えています。
書入れさへ除けば、調子は良い方かもしれません。
本文ハ囲ノ内ニ入ヘシ
□異本の文字考証
本文の傍に付たれは
悉不記下みな然り
第二會
女は
ヲウナ(と訓へし)古今序に小野
小町の傳につよからぬはをう
なの哥なれは也と有女の
事猶此事は竹取解 に
委云つ
和名抄
本文ハ囲ノ内ニ入ヘシ
異本の文字考語
本文の傍に付たれは
悉不記下みな然り
第二日
ヲウナと古今序に■時
小町の伝につよからへはをら
なの哥なれは也と有世の
より猶此事は行ける■
委三つ
和心附
頭注もよく認識しています。
後半は崩れていますね。「和名抄」ぐらいは読んで欲しいです。
55.7%古事記 真福寺本
国宝の真福寺本は『古事記』の現存最古写本ですが、南北朝期に写されたものです。
決して綺麗な文字とは言い難い書きぶりとなっています。

古事記上卷〈序幷〉
臣安萬侶言夫混元既凝氣象未效無名無爲誰知其形然
乾坤初分參神作造化之首陰陽斯開二靈爲群品之祖
所以出入幽顯日月彰於洗目浮沈海水神祇呈於滌身故太
素杳冥因本教而識孕土產嶋之時元始綿邈頼先聖
而察生神立人之世寔知懸鏡吐珠而百王相續喫劒切蛇
以萬神蕃息與議安河而平天下論小濱而淸國土是以番
仁岐命初降于高千嶺神倭天皇經歷于秋津嶋化熊出
右事記上巻席才
臣女高品商■■光既潔氣氛來敷麥石墨魚誰望■秋然
乳■初分参神作造化名前限陽斯開二靈烏君半品之祖
■■出入幽須日月載於洗目浮洗海火神、坐里於淋平談太
索香真目本教師識孕五産湯之特元佑歸觀額先聖
而茶生神主人之世愛知縣金鯱吐味而百王相續與飼切地
以神神番■與議去何而手天下論小漢而〓国上■二番
仁政命初降子髙千嶺神体天皇经應千秋津場化〓乳
全体的に認識はできていますが、朱印が被っているせいか、三箇所抜けているところがあります。
また、認識できている範囲でも3文字抜けており、2文字は下駄になっています。
そして、かなりの文字が間違っています。
最初から「右事記」になっていますし、これでは読めませんね。
一行目末尾の「知其形」の三文字を「望秋」に誤るなど、面白い間違え方をしています。
48.6%後撰和歌集 片仮名本
勅撰集からは、片仮名本の『後撰和歌集』です。
片仮名にもくずし字がありますので、どの程度読めているのか気になるところです。

於小石見賢教入道之
明應ノ時◆◆
後撰和歌集巻第一
卌五首 春上
正月一日二條ノ后宮ニテシロキウチキヲ
タマハリテ
〽入歌三首
藤原敏行朝臣
〽右兵衛督
〽シロキ夜トイハムトテフルユキノミノシロコロモ
トヨメルヲカカテ蓑代衣トヨメルナルヘシ
フルユキノミノシロコロモウチキツヽ
ハルキニケリトヲトロカレヌル
別紙考
春立日ヨメル
吉川万人營教のたす
開店して
後權和歌集卷第一
卅五首
春上
四月一日二除治〓三シロキウチーツ
タミ■リテ
〓■三首
藤泉敏行朝长
右兵衛舊
シロキ和トイハムトテフツヒーノミノシワフロを
トヨメリツカカテ菜仲■■■■■■■■■
■■■■■ミノしロフロ乞らん■■■
■■■ニニリーシトロカしの■
春主日りめ■
認識は、行の最初や最後に抜けているところがあります。
最初の、下に書き入れられている部分は、私も読めませんでした。
山田孝雄の解説でも、よくわからないとあったので、ご容赦願います。
左下隅に一行の識語あり、その字悉くは未だ讀み得ず、たゞし「賢教入道」といふ人名は明かなり。
第三張表とり本文となるが、その第一行、内題の下隅に上の「賢教入道云々」の文字と同じ人の筆とおぼしく一行の識語あり、これも未だ明かには讀み得ぬが「明應之時」といふ文字は明かなり。
而して上の識語は本文とは筆蹟を異にせりと見ゆ。
また、小松茂美は「明応之時、不(一見)」と判じられるとしており、下の二字は「一見」ではないかとしています。ただし後の説明で
下の二字分が判読できないので明らかでない。ことに一番下の文字は重書していて、いっそう解読をさまたげている
二荒山本後撰和歌集の研究二/Ⅱ後撰和歌集の諸本系統/Ⅰ後撰和歌集諸本の類別/3現存古写本/B別系統/4片仮名本/a宮本長則旧蔵 加納諸平旧蔵本
と述べているので、やはり決しがたいです。
読み間違えているところがかなりあります。
右下の書入れも、「開店して」になっていますね。ちょっと面白いです。
平仮名に複数の字母があり、崩し具合によっても様々なバリエーションがあるように、片仮名にも現在とは異なる文字があります。
歌の右側に小字で注がついていますが、その一行目に「フルユキノ」とあります。このユとキは見馴れない形をしています。
ユの字母は現在と同じ「由」ですが、横棒がありません。
キは現在と異なり「支」が字母だそうです。どの部分からこの斜めの棒を抜いてきたのかよくわかりませんが、キと読みます。
残念ながらOCRは伸ばし棒で読んでいますね。
ユもヒになっています。
その上の字もツになっていますね。
片仮名の学習データは、平仮名に比べても圧倒的に少ないのではないかと思われますので、OCRにはまだ難しいのかもしれません。
この写本は横への伸びが気持ちいいのですが、行を越えて食い込んでいるので、読みにくくなっています。

漢字では、藤原の雁垂れが細いせいか、泉になっています。
いずれにしてもこの状態では、第一句や第二句から歌を検索することすらできませんね。
47.6%後拾遺和歌集
勅撰集からもう一つ、『後拾遺和歌集』を取り上げます。
これは序文を書道作品として仕上げたもので、文字は大きくダイナミックに書かれているのでOCR的には厳しい作品です。

根岸信輔氏寄贈
後拾遺和歌抄序
藤原通俊
わが君あめの
したしろ
しめして
よりこのかた
よつのうみ
浪の聲
聞こえずこゝのつ
の國
みつぎもの
横岸信補氏寄贈二
後拾遺和歌楽序
即角いて通■
わか君あめの
《十三文》
■御座候三左衛門
家
いし■
よりこのかた
るつのうかり
浪の声
■■■十一文十六々の考
■■
いみつき■の
結構大きな字が見事に抜けています。
一行目「藤原通俊」の「俊」が抜けているほか、三行目には細長い「し(之)」があるのですが、薄すぎて見えませんし、認識されていません。
汚れもあるので、選別はかなり難しいです。

三行目の文字がOCRで「御座候三左衛門」になっているのは興味深いです。
試しに「御座候」の例を探してみました。
流石にピッタリのは見つかりませんでしたが、そう読めなくもないなという印象を得るぐらいには、雰囲気が似ています。
このレベルで「御座候」と読んでしまえるのは、学習サンプルが多いからでしょうか。
西村茂樹日記. [5]
国立国会図書館デジタルコレクション
諸宗作事図帳. [48] (百四十七) (曹洞宗)
国立国会図書館デジタルコレクション

たゆる
ことな
し
おほ
よそ
日のうちに
よろづの
ことわさ
多かる
なかに
春の
花
月の秋
をりにつけ
ことにのそ
小笠やける
十八とめ
■
物に
申候以上
日のこ達に
よけて考の
ことわけ
夕このるふ
大しのかくい
十
十八の
いつし
十月辺の
《を小兵衛》
を小子供け
《右書中》
十八とにの■
次の見開き二ページでは、結構文字を認識できていますが、やはり「し(之)」は薄すぎて見えません。
墨の汚れがあちこちにありますが、それを認識してしまっていますし、文字に含めてしまっています。
頑張って読んではいますが、文字が大きすぎるせいで、正しく一文字を判断することができていませんね。
41.6%萬葉集 西本願寺本
西本願寺本萬葉集です。
この本は現在一般に読まれる活字本の底本として用いられている、大変重要な写本です。
画像はその複製本ですので、国立国会図書館デジタルコレクションでは古典籍資料の扱いになってはいませんが、確認してみましょう。

雜歌
〈雄略天皇〉
(ハツセアサクラ)泊瀬朝倉宮御宇天皇代
〈太泊瀬稚武(オホハツセワカタケ)天皇〉
〈系図云長谷朝椋宮云〻大和國城上郡磐坂谷是也〉
天皇御製歌〈興毛興呂毛(コケコロモ)〉
〈籠毛與美之美字古本在之其理尤冝或本無美字依之點又欠美字〉
(コモヨミコミチフクシモヨミフクシモチ)
籠毛與美籠母乳・布久思毛與美夫君志持・
(コノヲカニナツムスコイヘキカナツケサネソラミツ)
此岳尒・菜採須兒・家吉閑・名告沙根・虚見津・
(ヤマトノクニハヲシナヘテワレコソヲラシツケナヘテ)
山跡乃國者・押奈戸手・吾許曽居師・告名倍手・
(ワレコソヲラシワレコソハセナニハツケメイヘヲモナヲモ)
吾己曽座・我許者・背齒告目・家呼毛名雄母
〈舒明天皇〉
高市岡本(タケチヲカモト)宮御宇天皇代 〈息長足日廣額(オキナカタラシヒヒロヌカタノ)天皇〉
本朱
神代事也
櫛玉饒速日命(クシタマニキハヤヒノミコト)
乗リ天磐船而廻
行給フ虚空故此ノ國ヲ
号虚見津大和
之國天磐舟鳥
也見古事記序
雜歌
雄畧天■
泊瀬朝倉宮御宇天皇代
茶ツせ〓〓
太泊〓稚武
天皇
条満云長谷朝棟宮云こ
条満云長谷朝棟宮云こ
大和〓域上郡磐〓谷是也
大和〓域上郡磐〓谷是也
天皇御梨歌
興も與品毛
龍毛與張之美字古今在之其理を恒我本要美学園之〓大火美字
罷毛與美籠母乳布久思乙與美夫君志持
此岳介·採採須兒家奇跡局■的很虛見津
山脉乃國者押奈戸手吾評曾居師告名倍手
吾己曾座利許者背歯告目家呼■名雄母
舒明天星
都市品不宮御宇天皇代
悲衣是日廣塲天皇
本朱
神代事也
盛玉候遠日令
宋天變触而回
行■虐空及此國
号廣■津大和
之國天磐舟鳥
也見事事記第
〓〓축??R3廿二二人本ㄷ占咨
あらかた主要な文字は認識していますが、流石にルビは少ししか認識できていませんね。
二重に読んでいる部分もあります。
部分的に読んでいたルビが謎の記号となってあちこちに散らばっていたので、最後にまとめてあります。
総文字数に対して正答率は41.6%でした。全然認識できていなかったルビを除いても、68.9%なので、可読率が高いとは言い難いです。
34.5%おくのほそ道
松尾芭蕉の誹諧紀行文『おくのほそ道』です。
画像は向井去来が元禄八年に書写したものの複製本です。
紙面も文字も綺麗に見えますが、OCRの認識は酷いものになっています。

月日は百代の過客にして行かふ
年も又旅人なり舟の上に生涯
をうかべ馬の口とらへて老をむ
かふる物は日〻旅にして旅を栖とす
古人も多く旅に死せるあり
予もいつれの年より片雲の風に
さそはれて漂泊の思ひやます
海濱にさすらへ去年の秋江上の
■■■百代のるあ■してり■う
■■■以人なりあ■とよ■■
■■■■■の口■しえてた■■
■■■■■タ~《タ~》議う■て旅を価とす
五人七号く旅を気ひえ■5《5》
やしいつ■ののよう片その日2《2》
■■■れて漂泊のらいやしす
海濱よさ■■■■■■■江との
朱印が被っているところを見事に避けているのはまだ理解できますが、それ以外の部分も抜けているのはどうしてなんでしょうか。
また、青色が他より少し濃いのは、二重に認識しているからです。
読み間違いも多く、これは全く読めていません。
読みにくい文字なのでしょうか。それとも、紙の色が悪いのでしょうか。
順集 群書類従本
私は性格が歪んでいるので、やはり読みやすそうな本を確認しても面白くありません。
順集には、面白い取り組みの歌があります。

詞書には「雙六盤の哥、これもありただが、よみはじめたるに、よみつく」とあり、雙六盤の形になるように歌が詠まれています。
縦にも横にも歌が置かれており、文字が寝ていたりひっくり返っていたりするので、OCRでは読めないだろうことは承知のうえで、確認してみましょう。

【外周】右縦→右下→左下→左縦→左上→右上
ろくろにやいともひくらむひきまゆのしらたまのをにぬけとたえぬい
いつこなるくさのゆかりそをみなへしこころをおけるつゆやしるとち
ちりもなきかかみのやまにいととしくよそにてみれとあかきもみちは
はなかとてゆきのまにまにおりくれとかつきえかへりてにもたまらす
するかなるふしのけふりもはるたてはかすみとのみそみえてたなひく
くさしけみひともかよはぬやまさとにたかうちはらひつくるなはしろ
【中横上段】左→右
かたいとにへつつわふるはしるやひとよらむとおもひてかつやたえなむ
むくらふのまなきあらのとやとはあれてわかせはみえすまてとひさしく
【中横下段】右→左
のこりなくやそしまもみむおきつなみはなれむそらのくものしらはの
のとのととにほへわかやとさくらはなをりからххххぬやまさとに
【中央縦】
くさまくらつゆさへむすふたもとなりかれつつのちのゆめのかよひち
【左上段】
へにかよふ
るいのきしより
ひくつなて
とまりはここと
つけよなにはえ
【右上段】
まつもおひ
のやまもときは
あきくれと
ははそのもみち
てるとやはきく
【右下段】
やまもかく
みなもみちけり
なとかりへ
むしのなくねを
もとくしらつゆ
【左下段】
にほとりか
やとりせるあま
はかもなく
らうたくぬれて
ぬめるこよひか
ろくろにやいともひへらん弥両の白■玉をもぬ気とははぬ此
いといたる也 まもか
一同十一人 一なもみち気
《十一日》□□□《もの也》 とかり《つわ》
さま丁 ○しろなくね
一升ツゝ 公 とくしら川へ
山
港二百四十九
■さまくらつ遊さへ又すふ社な■■れつゝ■ちのゆめの末よひた
とて七日より 〽ほとり■
一□□□ 身とりせるあ■
七十郎 ■ かもな■
一よしや さうたくぬれ■
十一文 《める》しめる六よひ■
一ことくに十一人もしかること幾人をしきこと山手在野川よりいさゝかにして七日へく
案の定横に寝ている歌は認識できていません。
そもそも人が見てもどうなっているのか分かり難いですね。
右にある縦一行の歌は、まだ何とか読んでいますが、横に寝ている歌の最後と最初がくっついており、文字も寝ているので上手く読めていません。
下段の歌は、実は上と下で寝ている歌の、文字が大きく書かれているところを含めて読むので、一層やっかいです。
右へ左へ縦横無尽なので、大変ですね。
まぁこれは無理そうな例を持ってきたので、しょうがないでしょう。
0%岷江入楚 飛鳥井雅章写
『岷江入楚』は中院通勝が著した『源氏物語』の注釈書で、それまでの注釈書をまとめているため、古註釈を調べる時に便利な本です。
若紫巻を見てみましょう。

○若紫 以哥為巻名
〈哥源〉手につみていつしかもみむ紫のねにかよひける野へのわか草
箋曰わか紫と引つゝきたる詞はみえす 秘花にくはし
〈花〉源氏君の哥手につみ――此哥をもて巻の名とせり
わか紫とつゝきたる詞はみえす式部卿姫君を紫上となつ
け侍るは藤壺女御のゆかり尋出たるによれりされは
此巻の詞に秋の夕はまして心のいとまなくおほしみたるゝ
人の御あたりに心をかけてあなかちなるゆかりもたつね
まほしき心もまさり給なるへしとあり源氏十七歳の三月
より冬まての事みえたり
わらはやみにわつらひ給て 〈河〉巻頭詞
瘧病(ギヤヘイ) 痁(ワラハヤミ)〈俗云發心也(ヲコリコヽチナリ)〉 瘧疾〈二日(ニ)一度發也〉
〈花〉瘴瘧(シヤウギヤウ)なり寒熱あり毎日にやむをは日をこりといふ
日ませをは隔日瘧といふ
〈秘〉箋痁〈古慕切〉通作痼久病也一日小児(箋ニナシ)口生瘡通作痼
箋夕皃巻河原院にて霊氣にあひ給し故也
実は一文字も認識していません。
確認したところ、最初から最後まで一文字も読んでいませんでした。
最初の6帖分を見たのですが、全文テキストデータをダウンロードすると、テキストファイルが全て0バイトになっていました。
「資料のタイトルや目次」から検索することができるので、この本を見つけることはできますが、『岷江入楚』の全文は検索できないということになります。
0%梁塵秘抄口伝集
『梁塵秘抄』は平安末期に後白河院が今様の歌謡を集めた歌謡集です。
本編10巻と、口伝集10巻の計20巻からなりますが、現在は一部しか残っておりません。
さらに、11巻から14巻が後から付け足されたと考えられています。
そのため、口伝集10巻までで残っている部分については校注がありますが、11巻以降については活字があるのやらないのやら、よくわかりません。
ここで活字が読める上に検索もできれば申し分ありませんね。
これは図が書かれていたり、表になっている部分があります。

残念なことに、認識していません。
ただ、これは全てではありませんでした。
13コマしかありませんので、全部確認してみました。
認識している:○ 認識していない:×
1/13 認識○
2/13 認識○
3/13 文字ナシ
4/13 認識○
5/13 認識×
6/13 認識○
7/13 認識×
8/13 認識×
9/13 認識×
10/13 認識○
11/13 認識○
12/13 認識○
13/13 認識○
最初は行に沿って書かれているのでしっかり認識しています。
数字が並んでいて表になっている部分が認識できないのは、まだ分かるのですが、その他の部分も含めて一面全く認識していないところがあります。
しっかり全面が文章になっていると認識するのですが、図表が混じっていると全てダメになっているようです。
NDL古典籍OCRで認識できていなかった部分を、CODHのKuroNetに読ませてみました。
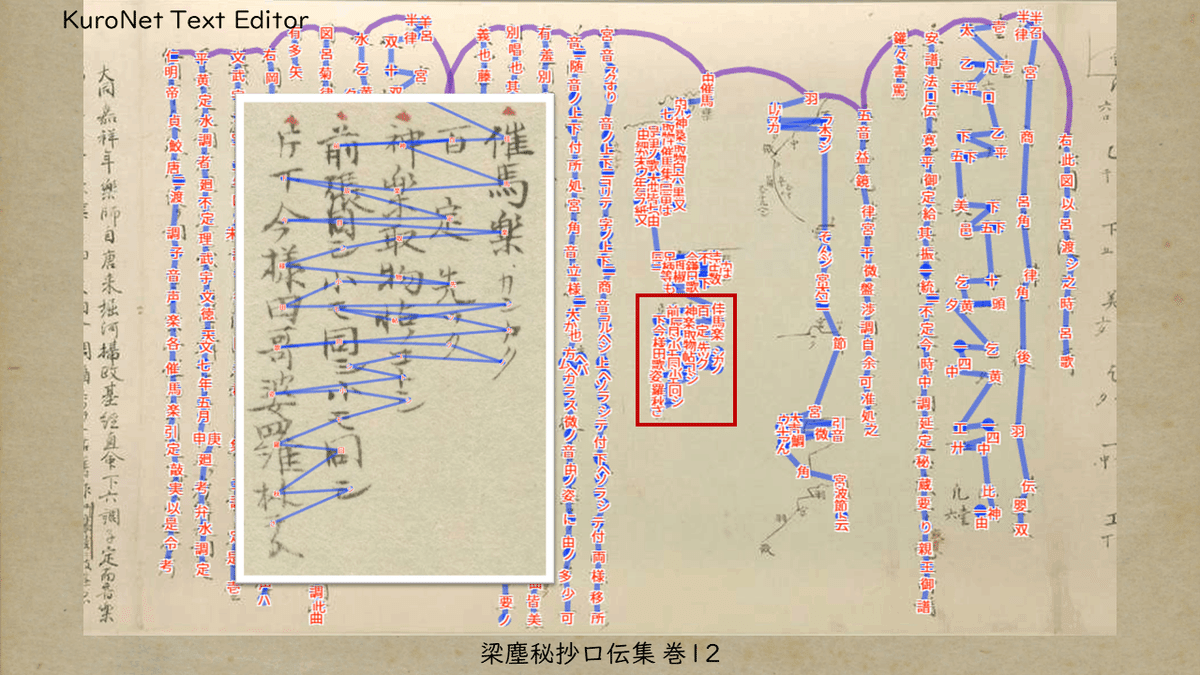
抜けている部分はありますが、あらかた読んでいますね。
KuroNet Text Editorを使えば、AIが一行をどのように判断したのかがわかります。
真っすぐ認識しているところは良いのですが、ジグザグになっているところがあります。
縦書きの中に横書きがあるという認識なのでしょうか。
0%偐紫田舎源氏
さて、最後は『偐紫田舎源氏』です。
絵入の娯楽本である草双紙の合巻で、『源氏物語』の翻案作品です。
江戸時代と言えば、絵の周りが文字で埋まっているこのタイプの印象が個人的には強いです。

これも0文字でした。
最初にある、本文に入るまでの7コマと、最後の綴じ紐だけで、大事な本文は抜けています。綴じ紐は完全に誤読です。
こういうのはKuroNetが得意な印象があります。

はなのみやこのむろまちにはなをかざりしひとかまへ
はなのごしとてときめきつあさひののぼる
いきほひにもじもえんあるひがし山
よしまさかうのきたのかたとよしの
まへときこえしは九ごく四こくに
かくれなき大内ためみつが
むすめにてすでにさる
としごさんのひも
やすらかにときたまひ
をのこゞもうけたまひ
しかばむかしにいやまし
人〳〵のそんきやう
おほかたならざりけり
ころはむつきの
すゑつかた
ついまつじゆ
しゆがう
かひおほひ
さま〴〵
あそびを
確認してみると、バッチリ読んでいます。
ただ、KuroNet Text Editorで、AIが判断した行見ると、上と下が繋がってしまっています。
こんなに間が開いているのに、一行だと認識したんですねぇ
また、最初の四行は、二行をジグザグに読んでいるので、テキストの文字列は上手くいっていません。
読みは間違ってないんですけどね。もったいないです。
KuroNetは文字列を自分で修正することができます。
手間ではありますが、手立てがあるのはありがたいですね。
可読状況について
一番読めているのが99%というのは驚きですが、0%があるのも衝撃です。
全ての画像を確認したわけではありませんので、一番読めていた中院本平家物語も、後々には全然読めていないページが出てくる可能性があります。
一応確認してみたのですが、最初の一冊は最後までしっかり読まれていました。
ところが、第二冊、第三冊を見ると、最初から最後までゼロ認識になっていました。
文字として認識することと、正しくくずし字を読むという少なくとも二段階が必要なので、どちらかがダメだと上手くいきませんね。

このグラフは確認した範囲の総文字数に対して、OCRが認識していた文字数の割合と、正答率です。100%を超えているのは、実際の文字数よりも多く認識してしまっているということです。
開きがあるところは、認識している割に正しく読めていないところです。
後拾遺和歌集は100%を超えて認識していますが、半分以上間違えていました。
逆に開きが小さいところは、認識した文字の殆どを間違えずに読んでいるということになります。
どちらも100%に近い程、過不足なく文字を認識し、正しく文字を読んでいるということです。
例えば、古事記伝と濱臣本万葉集は、割合文字を正しく読むことができているので、問題は抜けなく認識することにあります。
古事記伝はルビや返り点が抜けているので、それを除けば評価は高いです。
濱臣本万葉集は朱の書入れが一行抜けているので、そこさへ認識できていれば、改善されるでしょう。
対して、真福寺本古事記は、認識率が96.9%なのに、正答数は55.7%でした。文字の認識は概ね好調なものの、誤読が多いということです。
0%について
残念ながら0%だったものが三つもありました。
岷江入楚、梁塵秘抄口伝集、偐紫田舎源氏です。
正直、岷江入楚がなぜ全く認識していなかったのかはよくわかりませんが、傾向としては、『梁塵秘抄口伝集』の状況からすると、図や絵と判断されると認識されにくいのかもしれません。
『偐紫田舎源氏』は、あの密集がいけなかったのでしょうか。
流石にこれだけではよくわかりませんので、もう少し資料を足してみたいと思います。
鎌倉山百人一首
『鎌倉山百人一首』は草双紙の合巻です。
紙面は『偐紫田舎源氏』と同じく絵の周りを文字が埋め尽くしています。

これを確認してみると、なんと結構認識しています。
抜けているところもありますが、ゼロよりは可能性を感じます。
認識する能力はあったんですね。
河内名所図会
次は『河内名所図会』です。
これは河内の名所を絵で紹介しているものです。
これを確認してみると、しっかり文字を捉えていますね。

歩いている人も認識してしまっていますが、ゼロではありません。

よく読んでいると思ったのですが、絵が描かれていない、文字ばかりのページがゼロ認識になっていました。
地名の下に二段の割書で説明が書かれているため、体裁を認識できなかったのが原因でしょうか。
機巧図彙
もう一つ、別ジャンルで図と文字が交ざっているものとして、『機巧図彙』を見ておきましょう。
ここには茶運び人形の設計図がかかれて います。

最初読めているかと思ったのですが、次のページはゼロ文字でした。
因みにレイアウト認識モデルに使用された「NDL-DocLデータセット」を確認したところ、『機巧図彙』も入っていたので、学習データとしては正解を持っているはずなんですけどね。
図式的な配列などで、レイアウトがわからないと、認識できないということなのでしょうか。
今回紹介した作品は、文学史から適当に選び、デジタルコレクションにあるか探し、見つかった20本の可読率を確認したものです。
その中で、そもそも認識していないページがこれだけ見つかるというのは、正直びっくりです。
「全文検索」と聞くと、図書及び古典籍資料、約35万点の全てから検索した結果が表示されていると思うわけですし、NDLラボとしてもそのつもりだと思うのですが、実際にはかなりの量のページ(コマ)が検索から漏れていると思われます。
読み順の問題 全文検索について
認識如何の問題もありますが、順番にもかなりの問題があります。
今回の検討では比較しやすいように並べ替えや改行を行いましたが、実際に提供されているテキストはベタ打ちです。
例えば、『土佐日記解』の実際のテキストはこのようになっています。
合さて為はしするすること活き又せムせんせりせし何者と云本文ハ囲ノ内ニ入ヘシ凡十諸本男もすなると有せヨと云仰取言ニ一異本の文字考語男のすといふ日記というものを本文の傍に付たれは異本定本も従て改へもをとこもと云悉不記下みな然り第二日ては日記と云物は専女のする物と聞ゆるに下に女もとありてはきこえヲウナと古今序に時小町の伝につよからへはをらなの哥なれは也と有世のす専男のする事を女も誠にしてみんと云るなりさてすなるとては男より猶此事は行ける見むとてするなりは必する物と云か如く寸といふと云ては女の慥にはしらぬよしにてよ和心附委三つそけにて女もしてみんと云るに附々しく聞ゆめり○女もじてこゝろけられて女もしてこゝろたゝみむとあるも試みの意なれはさまたけ打あはすなしされと腹事は有やすく行ことはをすなまものなれは近本のあはれ殖て見むとてうゑられはとある同意なり為本の思ひてとあかるによるへし宇治拾遺物語四丁の廿に雀の瓢種を得させたる処にさはふと行たるならんかさる意を含たる言なれはないそよからんいと無して
実際の順序と照らすと、以下のようになっていました。
・前ページの本文と本ページの書入れが交互に交ざっている
・本文と頭注が交互になっている
・本文の順番が前後している
順番がめちゃくちゃですね。
これがベタ打ちになっているので、絶対にありえない文字列が作られてしまっています。
例えば上のテキストから、太字にしている「語男」を全文検索してみると、古典籍で64件ヒットし、この『土佐日記解』を見つけることができます。
本当は「異本の文字考証」と書かれている頭注の途中と、「男のすといふ」という本文なので、読み間違いと読み順誤りのダブルパンチです。
これは決して稀有な例ではなく、「こゝろけられて」や「あはれ」など、実際には書かれていない言葉から、この『土佐日記解』を見つけることができます。
OCRで古典を読む分にはいいんですが、全文検索をするには致命的です。
頭注、脚注、書入れ、割注など、古典籍のレイアウトは様々ですから、色々な古典が読めるようになるといいですね。
余談
余談ですが、私はデスクトップと、ノートPCと、スマホの三つを使って資料を作成しています。
OCRのテキスト表示が、それぞれ以下のようになっていました。



出入があります。文字数も違います。
これはどういうことなのでしょうか。
画面の縦横比に合わせて表示が変化するようになっているので、デスクトップのウィンドをできるだけ縦長にした状態で改めて表示させてみました。

案の定テキストが異なっています。
スマホに似たテキストになっていますね。
色々変更がありますが、特に末尾からどんどん削れているようです。
全文検索に影響がでるのか、そこまではもう立ち入りませんが、テキストを表示して確認したいときは、なるべく大きな画面を使った方がいいです。
ちなみに、画面サイズの違うスマホで試したところ、また少し異なったテキストが表示されました。
所見
次世代デジタルライブラリーを用いた分析結果が信用できるものかどうかは、OCRの精度にかかっていますが、現状のNDL古典籍OCRの精度では、正直、全文検索に耐え得るものとは言い難いです。
現状でも資料探しにはいくらか役立ってくれますが、古典籍資料に関しては、活字と違ってくずし字が読めないと検索結果が正しいか判断できませんし、結果を鵜呑みにしない態度が必要です。
良く読めている資料の一覧や、90%以上読めている資料だけの絞り込み検索ができると、全文検索を用いた分析でも、或程度の信用を得ることができるのですが、それを可能にするには人力になってしまいますかね。
逆に読めていない資料や、抜けている画像があったら、報告できるボタンがあってもいいですね。
毎月一回ででも読み直ししてくれれば、結構改善される気がします。
0バイトは明らかにおかしいので、自動で検知してやり直すとかできれば、速そうな気がします。
まぁ細かい事情も知らない素人の思い付きですが、できることは沢山ありそうです。
おわりに
以上、NDL古典籍OCRについて、二十本+αの写本や版本、影印本を確認しました。
全文検索の厳しい現状が見えてきましたが、OCRの可読率が99%という凄い数字も出て来ました。
個人的な希望を言えば、古典の本文よりも、書入れや注を読んでいて欲しいです。
本文のデータベースは幾つかありますが、書き入れられた注は活字もデータベースもありませんので、それが検索できると、意外な掘り出し物に出合えそうな気がします。
「古典籍資料のOCRテキスト化実験」の情報によると、
文字列認識モデルの学習には、資料の画像と翻刻データについて1行単位で対応付けされたデータセットが必要ですが、このようなオープンな既存のデータセットは多くありません。 したがって、必要な形式に近い既存のデータセットを加工することで、目的に沿ったデータセットを可能な限り省力的に構築することが大きな課題となりました。
とあります。
一般に募れば、意外と資料が集まるのではないかと個人的には思っています。サービスには期待していますし、協力したいという人も多いのではないでしょうか。
どういうデータが必要か、詳細を明らかにしておいてくれれば、これから翻刻する際にも、所定のフォーマットで作成しておくことができます。
どうせくずし字を読むなら、汎用性のある翻刻にしたいです。
苦い評価をしてしまいましたが、実験的なサービスですし、これから益々発展していくと思っています。
現状でも、埋もれていた資料の発見につながるなど、その功は計り知れません。
サービスを展開してくださっているNDLラボには感謝しかありません。
これからどうなっていくのか、とても楽しみです。
出典・参考
NDLラボ 古典籍資料のOCRテキスト化実験
https://lab.ndl.go.jp/data_set/r4ocr/r4_koten/
次世代デジタルライブラリー
https://lab.ndl.go.jp/dl/
国立国会図書館デジタルコレクション
https://dl.ndl.go.jp/
NDL Ngram Viewer
https://lab.ndl.go.jp/ngramviewer/
CODH AIくずし字OCRサービス
http://codh.rois.ac.jp/kuzushiji-ocr/
凸版印刷 ふみのは
https://www.toppan.co.jp/biz/fuminoha/
万葉集 : 西本願寺本. 巻1
https://dl.ndl.go.jp/info:ndljp/pid/1242401/9
DOI:10.11501/1242401
https://lab.ndl.go.jp/dl/book/1242401
万葉集. [20]
https://dl.ndl.go.jp/info:ndljp/pid/2551537/3
DOI:10.11501/2551537
https://lab.ndl.go.jp/dl/book/2551537
万葉代匠記. [1]
https://dl.ndl.go.jp/info:ndljp/pid/2552053/3
DOI:10.11501/2552053
https://lab.ndl.go.jp/dl/book/2552053
古事記 : 国宝真福寺本. 上
https://dl.ndl.go.jp/info:ndljp/pid/1184132/3
DOI:10.11501/1184132
https://lab.ndl.go.jp/dl/book/1184132
古事記伝 44巻. [2]
https://dl.ndl.go.jp/info:ndljp/pid/2556362/5
DOI:10.11501/2556362
https://lab.ndl.go.jp/dl/book/2556362
後撰和歌集. 1
https://dl.ndl.go.jp/info:ndljp/pid/1188497/5
DOI:10.11501/1188497
https://lab.ndl.go.jp/dl/book/1188497
後拾遺和歌集序
https://dl.ndl.go.jp/info:ndljp/pid/2538991/2
DOI:10.11501/2538991
https://lab.ndl.go.jp/dl/book/2538991
[小倉百人一首]
https://dl.ndl.go.jp/info:ndljp/pid/2541162/4
DOI:10.11501/2541162
https://lab.ndl.go.jp/dl/book/2541162
(順集)群書類従. 第316-317
https://dl.ndl.go.jp/info:ndljp/pid/2559159/42
DOI:10.11501/2559159
https://lab.ndl.go.jp/dl/book/2559159
(風葉和歌集)丹鶴叢書. [91]
https://dl.ndl.go.jp/info:ndljp/pid/2558982/3
DOI:10.11501/2558982
https://lab.ndl.go.jp/dl/book/2558982
土佐日記解 2巻. [1]
https://dl.ndl.go.jp/info:ndljp/pid/2575497
DOI:10.11501/2575497
https://lab.ndl.go.jp/dl/book/2575497
宇津保物語. 巻1
https://dl.ndl.go.jp/info:ndljp/pid/2591949
DOI:10.11501/2591949
https://lab.ndl.go.jp/dl/book/2591949
河海抄. [3]
https://dl.ndl.go.jp/info:ndljp/pid/2563567
DOI:10.11501/2563567
https://lab.ndl.go.jp/dl/book/2563567
平家物語 12巻. [1]
https://dl.ndl.go.jp/info:ndljp/pid/2543842
DOI:10.11501/2543842
https://lab.ndl.go.jp/dl/book/2543842
平家物語. 巻1
https://dl.ndl.go.jp/info:ndljp/pid/1288262
DOI:10.11501/1288262
https://lab.ndl.go.jp/dl/book/1288262
古今著聞集 20巻. [1]
https://dl.ndl.go.jp/info:ndljp/pid/2551724
DOI:10.11501/2551724
https://lab.ndl.go.jp/dl/book/2551724
おくのほそ道 : 去来本. [本編]
https://dl.ndl.go.jp/info:ndljp/pid/1187059
DOI:10.11501/1187059
https://lab.ndl.go.jp/dl/book/1187059
岷江入楚. [5]
https://dl.ndl.go.jp/info:ndljp/pid/2585041
DOI:10.11501/2585041
https://lab.ndl.go.jp/dl/book/2585041
梁塵秘抄口伝集. 巻12
https://dl.ndl.go.jp/info:ndljp/pid/2540723
DOI:10.11501/2540723
https://lab.ndl.go.jp/dl/book/2540723
偐紫田舎源氏. 初編上
https://dl.ndl.go.jp/info:ndljp/pid/2605023
DOI:10.11501/2605023
https://lab.ndl.go.jp/dl/book/2605023
鎌倉山百人一首 3巻
https://dl.ndl.go.jp/info:ndljp/pid/10301110
DOI:10.11501/10301110
https://lab.ndl.go.jp/dl/book/10301110
河内名所図会 6巻. [1]
https://dl.ndl.go.jp/info:ndljp/pid/2563471
DOI:10.11501/2563471
https://lab.ndl.go.jp/dl/book/2563471
機巧図彙 2巻首1巻. [2]
https://dl.ndl.go.jp/info:ndljp/pid/2568592
DOI:10.11501/2568592
https://lab.ndl.go.jp/dl/book/2568592
・『萬葉集』(新編日本古典文学全集)小学館
・『契沖全集』第1巻 岩波書店
・西宮一民『古事記』桜楓社
・『本居宣長全集』第九巻 筑摩書房
・『後撰和歌集』(新日本古典文学大系)岩波書店
・小松茂美『二荒山本後撰和歌集の研究2』(小松茂美著作集8)旺文社
・川村晃生『後拾遺和歌集』(和泉古典叢書)いずみ書房
・日文研「順集」(和歌データベース)https://lapis.nichibun.ac.jp/waka/waka_i102.html
・『風葉和歌集』(和歌文学大系50)明治書院
・折口信夫編『土佐日記解 田中大秀』(国文学註釈叢書)名著刊行会 182コマhttps://dl.ndl.go.jp/info:ndljp/pid/1218147
・国文名著刊行会『土佐日記古註大成』(日本文学古註大成 第5巻)国文名著刊行会 184コマhttps://dl.ndl.go.jp/info:ndljp/pid/1236934
・中野幸一『宇津保物語』(新編日本古典文学全集14)小学館
・玉上琢彌編『紫明抄 河海抄』角川書店
・市古貞次『平家物語』(新編日本古典文学全集45)小学館
・永積安明、島田勇雄校注『古今著聞集』(日本古典文学大系48)岩波書店
・井本農一、久富哲雄、村松友次、堀切実校注訳『松尾芭蕉集(2)』(新編日本古典文学全集71)小学館
・小林芳規、武石彰夫校注『梁塵秘抄』(新日本古典文学大系56)岩波書店
・馬場光子 全訳注『梁塵秘抄口伝集』(講談社学術文庫)講談社
・中田武司『岷江入楚 第一巻』(源氏物語古注集成 第11巻)桜楓社
・鈴木重三校注『偐紫田舎源氏』(新日本古典文学大系88)岩波書店
サムネイル:どてらぞぬ
https://twitter.com/zonu_summer
立ち絵:akihiyo
https://twitter.com/AKlHlYO
https://seiga.nicovideo.jp/seiga/im10559196
この記事が気に入ったらサポートをしてみませんか?