
S3のイベント通知でAWS Batch on Fargateを実行する

前回はS3のイベント通知で、Lambdaを実行するというパターンをやってみましたが、今回はAWS Batch on Fargateを実行するというパターンをやってみました。
AWS Batchの概要
AWS Batchは、ジョブを実行するためのサービスです。AWS Batchの主な構成要素は、ジョブ定義、ジョブキュー、コンピューティング環境になります。
ジョブ定義は、ECSで言うとタスク定義のことで、ジョブ定義を作成するとECSでタスク定義が作成された状態になります。
ジョブキューは、ジョブを溜めておくためのキューです。AWS BatchではSQSなどのキューを別途用意する必要はなく、AWS Batchが提供するキューを利用する形になります。デットレターキューも設定することはできますので、その場合はSQSを利用することになります。
コンピューティング環境は、実際に処理を行う環境となり、固有の実行環境があるわけでなく、ECSを利用することになります。そのため、ECS on EC2、ECS on Fargate、EKSのどれかを使うことになります。実際に作成するとECSのクラスターなどが作成されます。
また、今回のFargateであれば最大vCPUという設定項目があり、その数の分までコンテナを立ち上げることができます。vCPUを使い切ってしまったら実行はSTOPされて、vCPUの空きが出来次第、実行が再開されます。
例としては、最大vCPUが256で、コンテナが1vCPUであれば、256タスクまで実行することができます。ただし、タスク1つにつきIPを1つ消費するため、サブネットで作成できるIP数以上には実行することはできません。もしそれ以上実行してしまったら、エラーになってジョブが失敗することになりますので、最大vCPUの設定は、サブネットのIP数を考慮して設定する必要があります。
料金としては、AWS Batch自体ではかからず、利用するECSなどの料金のみがかかる形です。そのためSaving Plan、スポット系の割引が利用ができるので、要件によってはコストを抑えることもできます。
処理の流れ
S3バケットにファイルをアップロードする
EventBridgeがイベントを拾い、AWS Batchのキューに登録
AWS BatchがFargateのタスクを立ち上げてJobを実行する
ジョブのプログラムでは、S3からファイルをダウンロードする
処理後のファイルをS3バケットの別のフォルダにアップロードする
構成図

S3バケットの作成
イベント通知、処理済みファイル用のS3バケットを作成します。バケット名を入力して、バージョニングは有効にし、それ以外は今回はデフォルトで、バケットを作成します。

バージョニングを有効にする理由は以下の記事のとおりです。
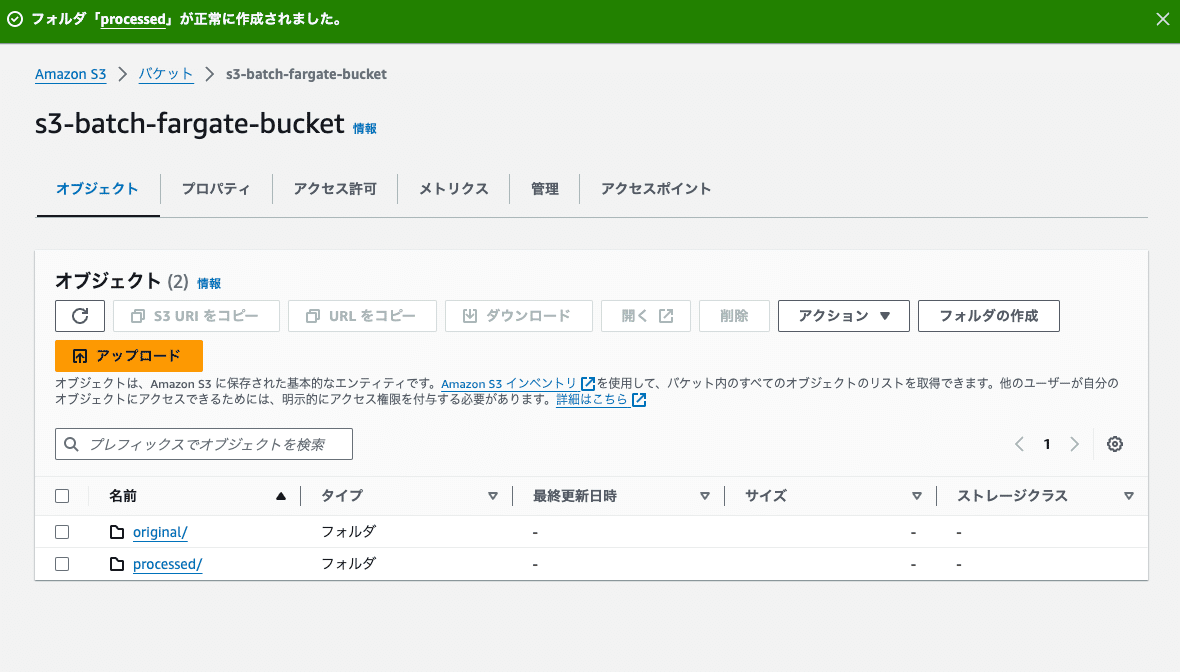
作成したバケットの詳細画面に入り、original、processedフォルダを作成します。
次にEventBridgeへの通知を送るための設定を行います。プロパティのイベント通知という欄に、Amazon EventBridgeに通知を送信するかを設定できる箇所があります。編集ボタンをクリックして、変更モーダルを開きます。
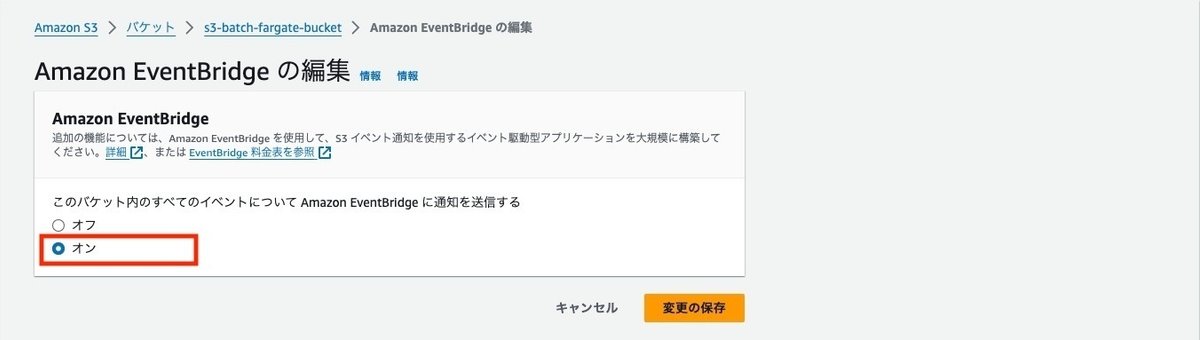
オンを選んで変更します。
VPC関連を作成
Fargateを配置するためのVPCを作成します。本来はプライベートサブネットに配置し、しかるべき設定をした方がセキュリティとして良いですが、VPCエンドポイントなど少し手間なので、今回はパブリックサブネットに配置し、インターネット経由で各サービスと通信することにします。
サブネットなども一緒に作成できるVPCなどを選択して、名前タグ、IPv4のCIDR、AZは1つで、パブリックサブネットを1つで、他は無しで作成します。
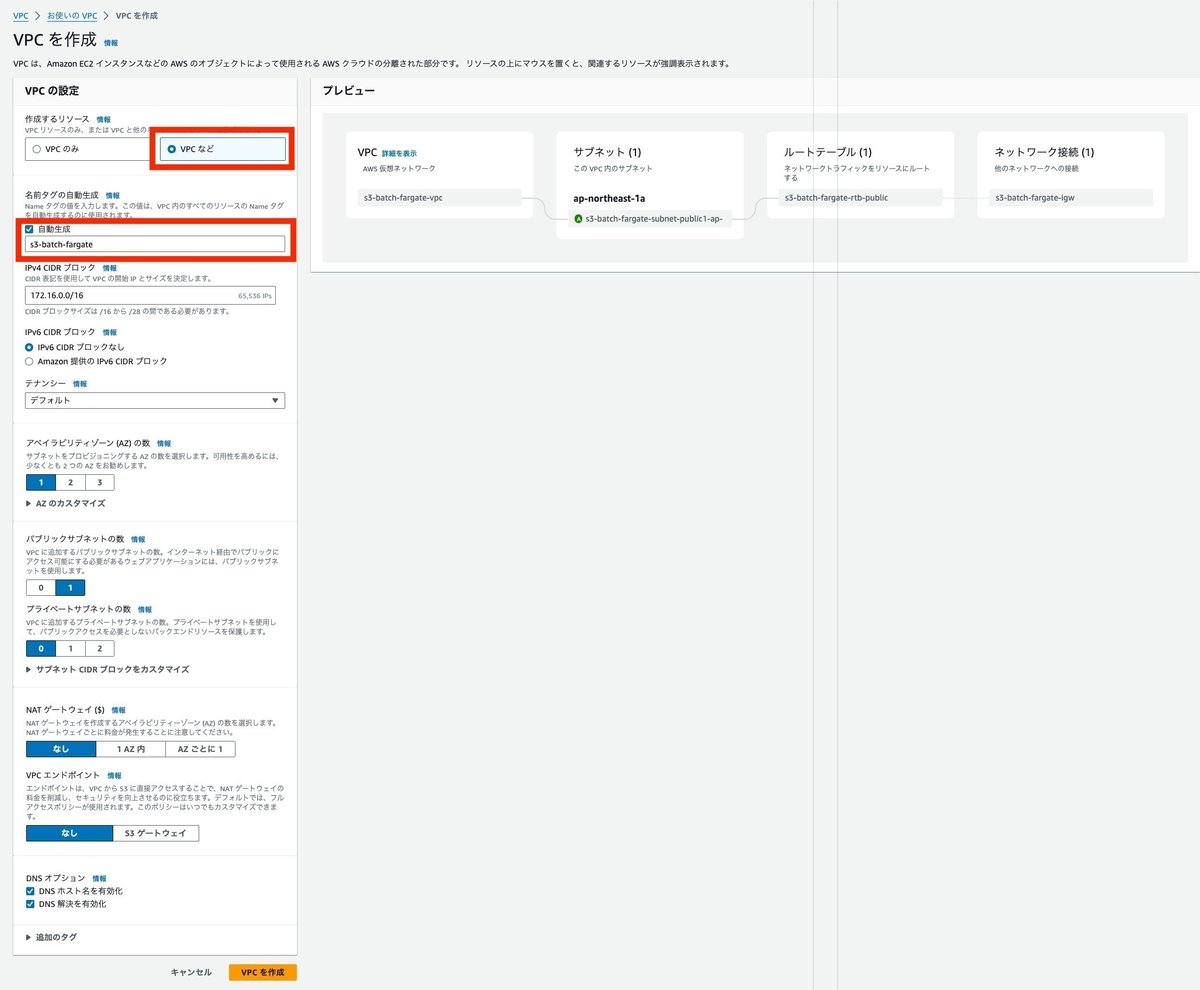
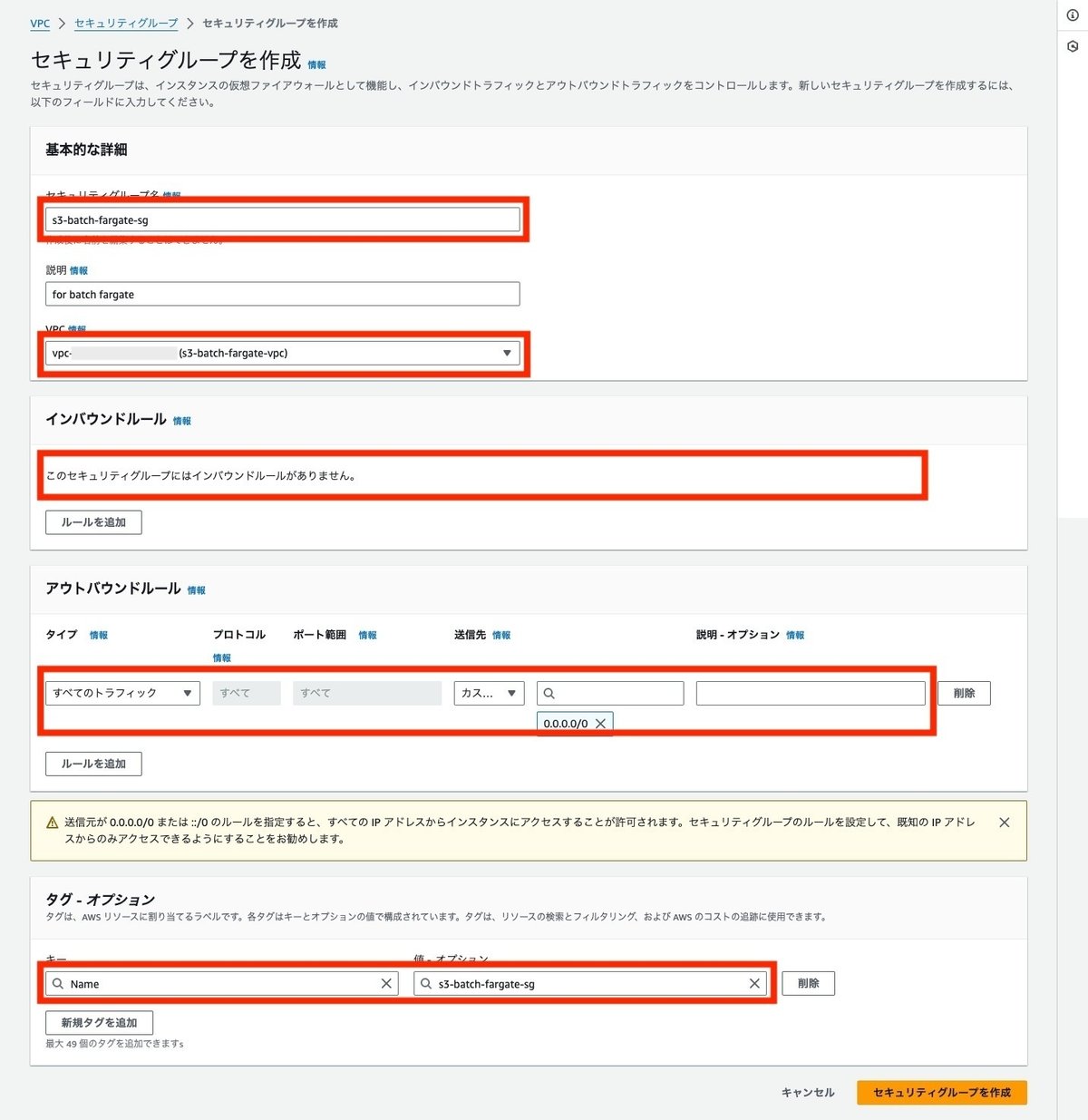
セキュリティグループを作成
Fargateに設定するセキュリティグループを作成します。VPCは先ほど作成したVPCを選択します。インバウンドの通信は発生しないため、インバウンドの定義は無しとします。アウトバウンドはデフォルトのすべてのトラフィックを許可する設定のままでいきます。
Fargateのタスク用のIAMロール、ポリシーを作成
Fargateのタスク用のロールを作成します。 これは各コンテナで動作するプログラムが持つ権限になるため、今回であればS3バケットのファイルのGetやPutが必要になります。
IAMポリシーの作成
IAMポリシーは、作成したS3バケットへのGetとPutを許可する権限とします。

ポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowS3Access",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::{バケット名}/*"
}
]
}ポリシー名を入力して、内容を確認してポリシーを作成します。

IAMロールの作成
IAMロールの信頼されたエンティティタイプは、ECSのタスクを実行するために、Elastic Container Service Taskを選択します。
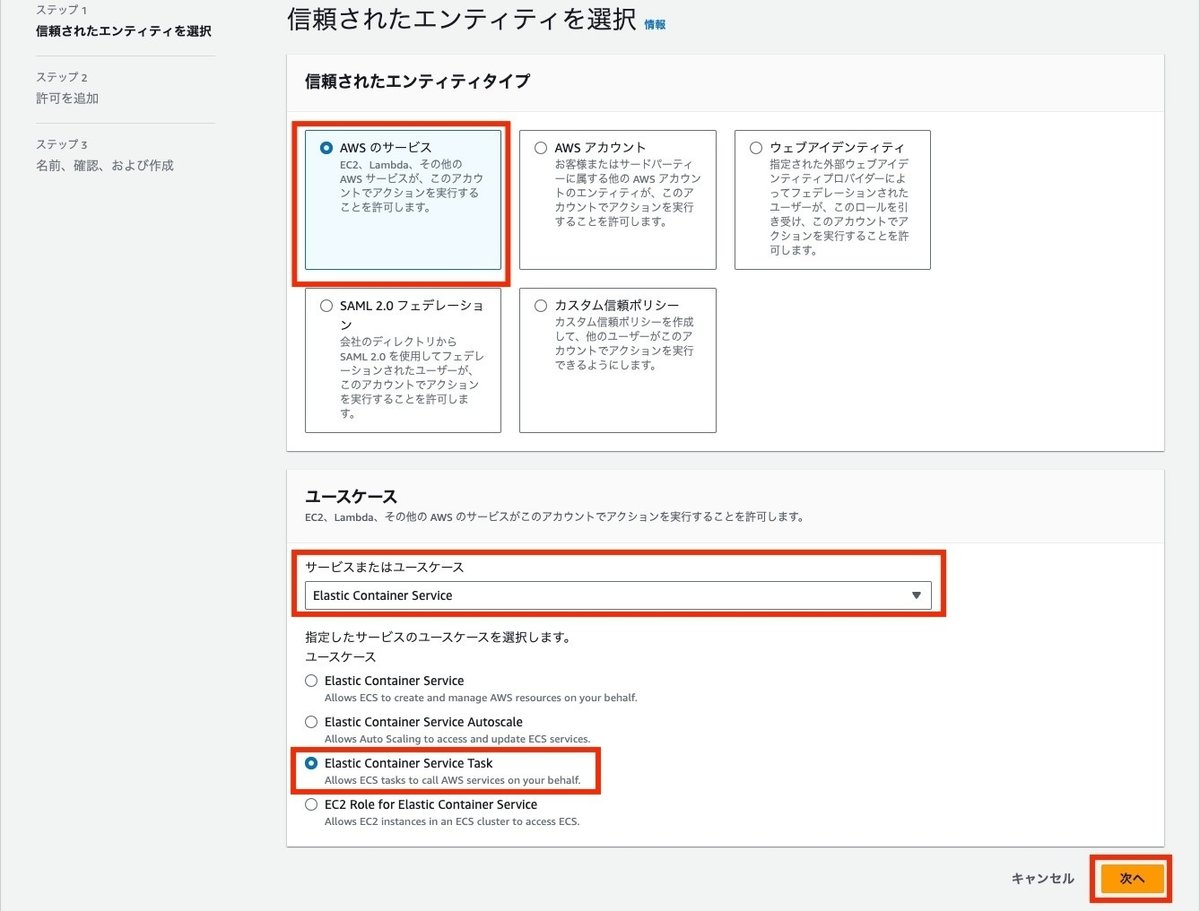
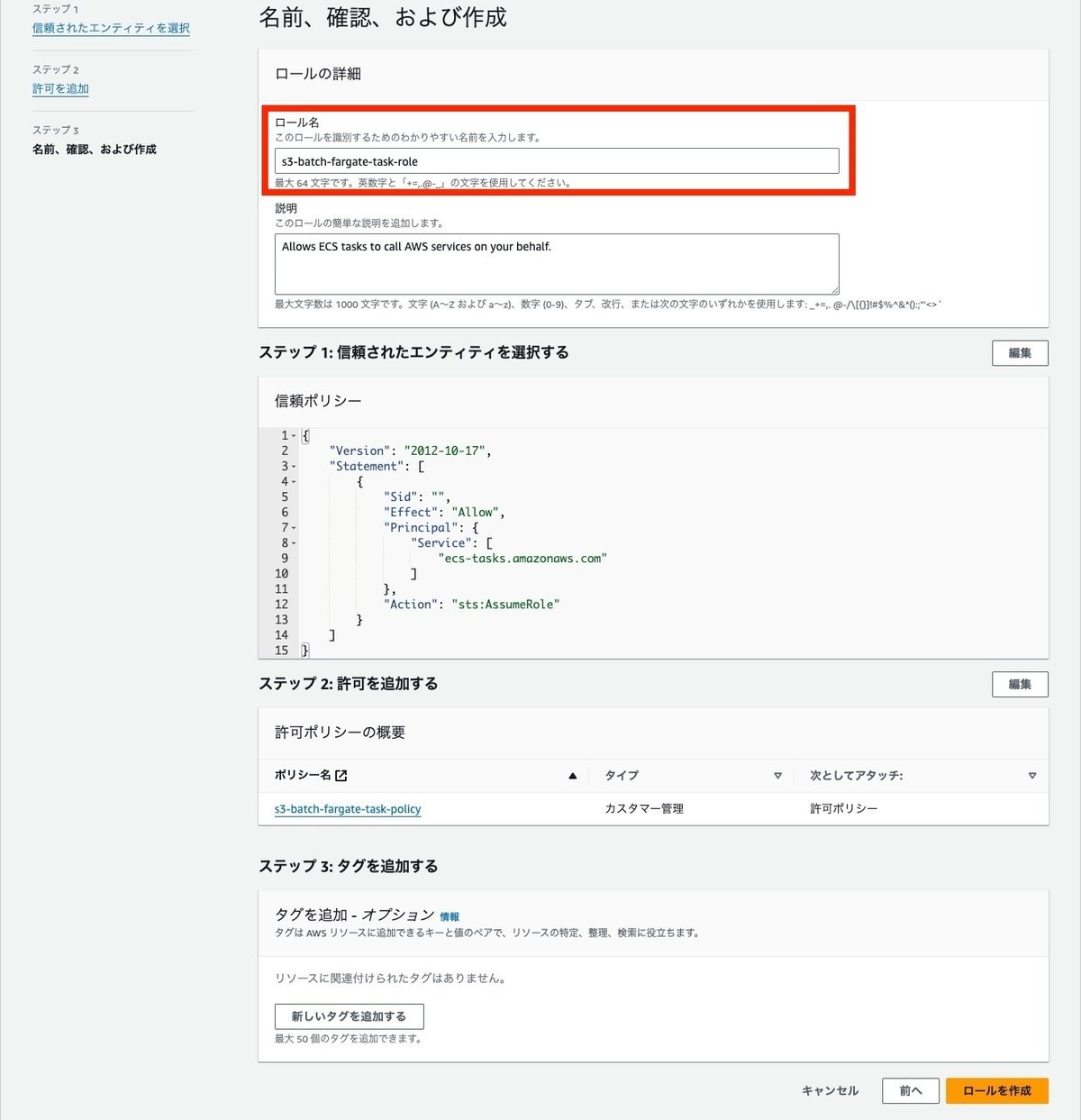
許可ポリシーに、先ほど作成したポリシーを追加します。

ロール名を入力して、内容を確認してロールを作成します。
Fargateのタスク実行用のIAMロールを作成
Fargateのタスク実行用のロールを作成します。これはECSがタスクを実行するためのロールになります。特にアプリ側で必要となる権限などはないため、IAMポリシーの作成は不要です。
IAMロールの信頼されたエンティティタイプは、ECSのタスクを実行するために、Elastic Container Service Taskを選択します。
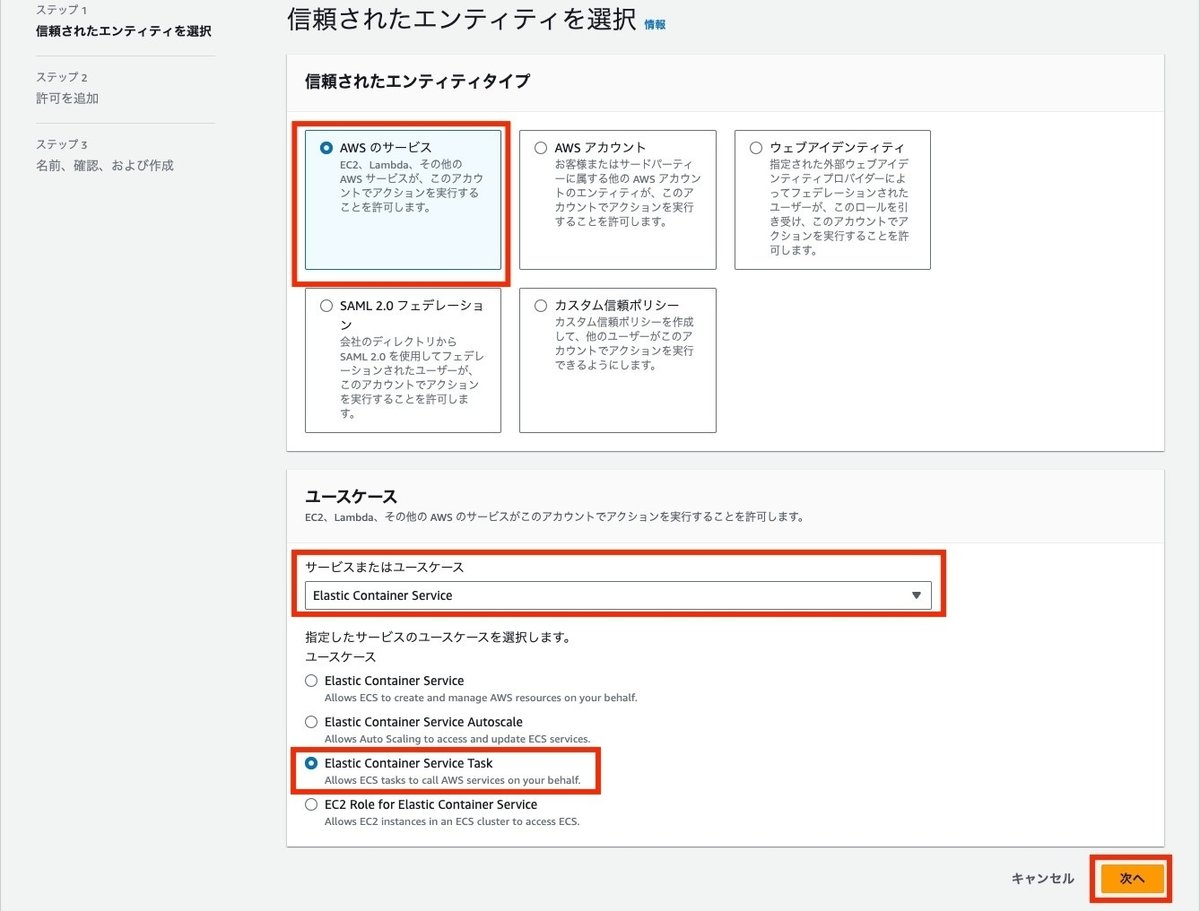
許可ポリシーは、AmazonECSTaskExecutionRolePolicyを追加します。
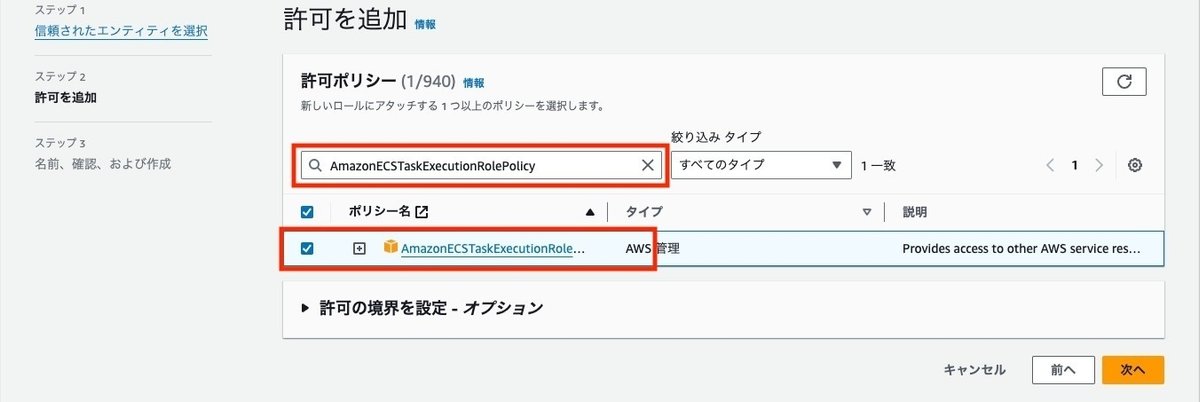
ロール名を入力して、内容を確認してロールを作成します。

ECRの作成
Fargateで利用するコンテナイメージ用のプライベートリポジトリを作成します。リポジトリ名を設定して、イメージスキャンは有効にしておきます。その他は無効にしておきます。

リポジトリを作成したらローカルでイメージを作成して作成したリポジトリにプッシュします。処理としてはS3からダウンロードして、アップロードする簡単なものにしておきます。
import { parseArgs } from 'node:util';
import { GetObjectCommand, PutObjectCommand, S3Client } from '@aws-sdk/client-s3';
import path from 'node:path';
import * as fs from 'node:fs';
type Status = 'START' | 'SUCCESS' | 'FAILED';
interface LogInfo {
status: Status;
bucketName: string;
objectKey: string;
execTime: number;
}
(async function main() {
const start = process.hrtime();
const logInfo: LogInfo = {
status: 'START',
bucketName: '',
objectKey: '',
execTime: 0,
};
try {
const args = process.argv.slice(2);
const options = {
bucketName: {
type: 'string',
multiple: false,
},
objectKey: {
type: 'string',
multiple: false,
},
} as const;
const { values } = parseArgs({ options, args });
if (values.objectKey && values.objectKey.endsWith('/')) {
return;
}
logInfo.bucketName = values.bucketName!;
logInfo.objectKey = values.objectKey!;
const client = new S3Client({ region: 'ap-northeast-1' });
const getCommand = new GetObjectCommand({
Bucket: logInfo.bucketName,
Key: logInfo.objectKey,
});
const response = await client.send(getCommand);
const filename = path.basename(logInfo.objectKey);
const filePath = `/tmp/processed-${filename}`;
await response.Body?.transformToWebStream().pipeTo(
new WritableStream({
write(chunk) {
const decoder = new TextDecoder();
fs.writeFileSync(filePath, decoder.decode(chunk));
},
}),
);
const putCommand = new PutObjectCommand({
Bucket: logInfo.bucketName,
Key: `processed/processed-${filename}`,
Body: fs.createReadStream(filePath),
});
await client.send(putCommand);
logInfo.status = 'SUCCESS';
} catch (e) {
console.error(e);
logInfo.status = 'FAILED';
}
const execTime = process.hrtime(start);
logInfo.execTime = execTime[0] + execTime[1] / 1e9;
console.log(JSON.stringify(logInfo));
})();今回はTypeScriptを使ったのですが、Node.jsでTypeScriptの環境構築については、以下のサイトを参考に構築しています。
Dockerfileはnodeのイメージを利用して、TypeScriptのビルドをして、出来上がったJavaScriptファイルを配置して、実行する定義にします。
FROM public.ecr.aws/docker/library/node:20.13.1-bullseye
WORKDIR /usr/src/app/
COPY . .
RUN npm ci && npm run build && mv ./lib/* . && rm -rf ./lib
CMD ["node", "/usr/src/app/app.js"]あとは、イメージを作成してECRにプッシュします。プッシュのコマンドは、ECRの画面の右上にあるプッシュコマンドを表示ボタンから確認することができます。


コマンドとしては以下の通りですが、私のPCがM1 Macで、FargateのアーキテクチャはX86_64を利用したいため、platformのオプションを入れてビルドしています。
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin {アカウントID}.dkr.ecr.ap-northeast-1.amazonaws.com
docker build -t s3-batch-fargate-repository --platform linux/x86_64 .
docker tag s3-batch-fargate-repository:latest {アカウントID}.dkr.ecr.ap-northeast-1.amazonaws.com/s3-batch-fargate-repository:latest
docker push {アカウントID}.dkr.ecr.ap-northeast-1.amazonaws.com/s3-batch-fargate-repository:latestAWS Batch on Fargate を作成
実際の処理を実行するAWS Batch on Fargateを作成します。
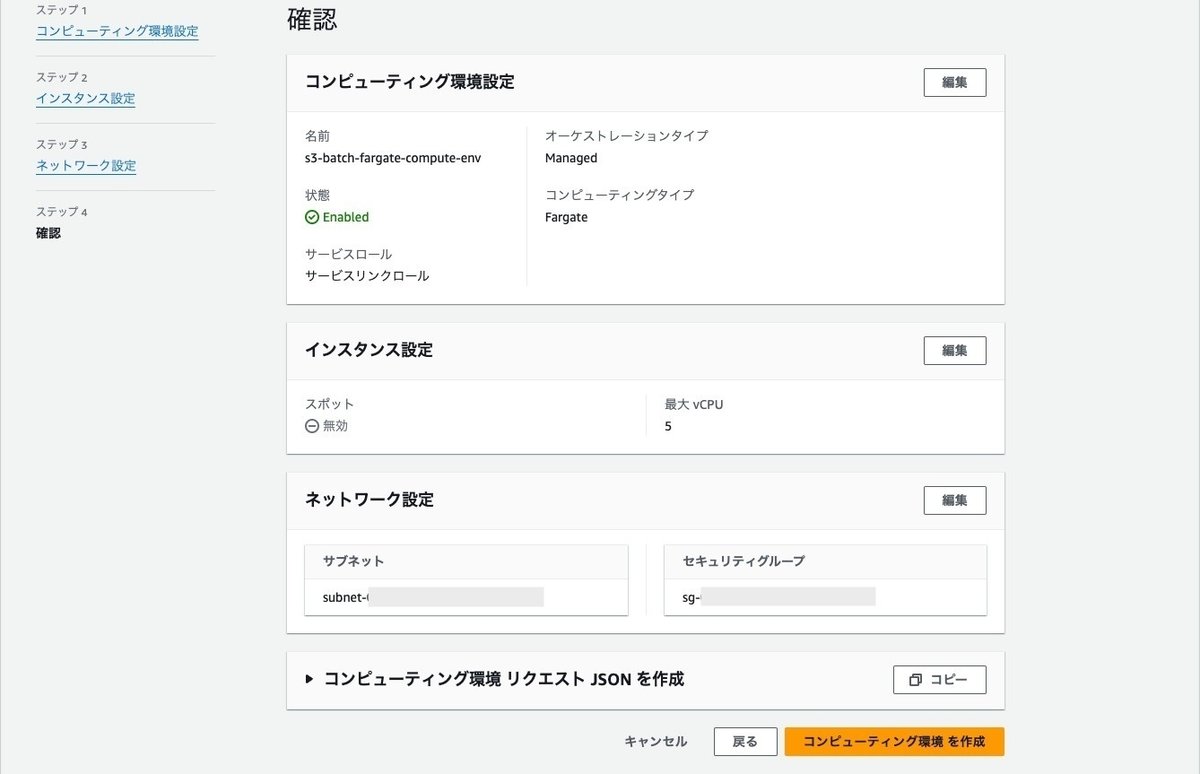
コンピューティング環境の作成
コンピューティング環境の画面で、作成ボタンをクリックします。

コンピューティング環境性っていでFargateを選択して、名前とサービスロールを選択します。
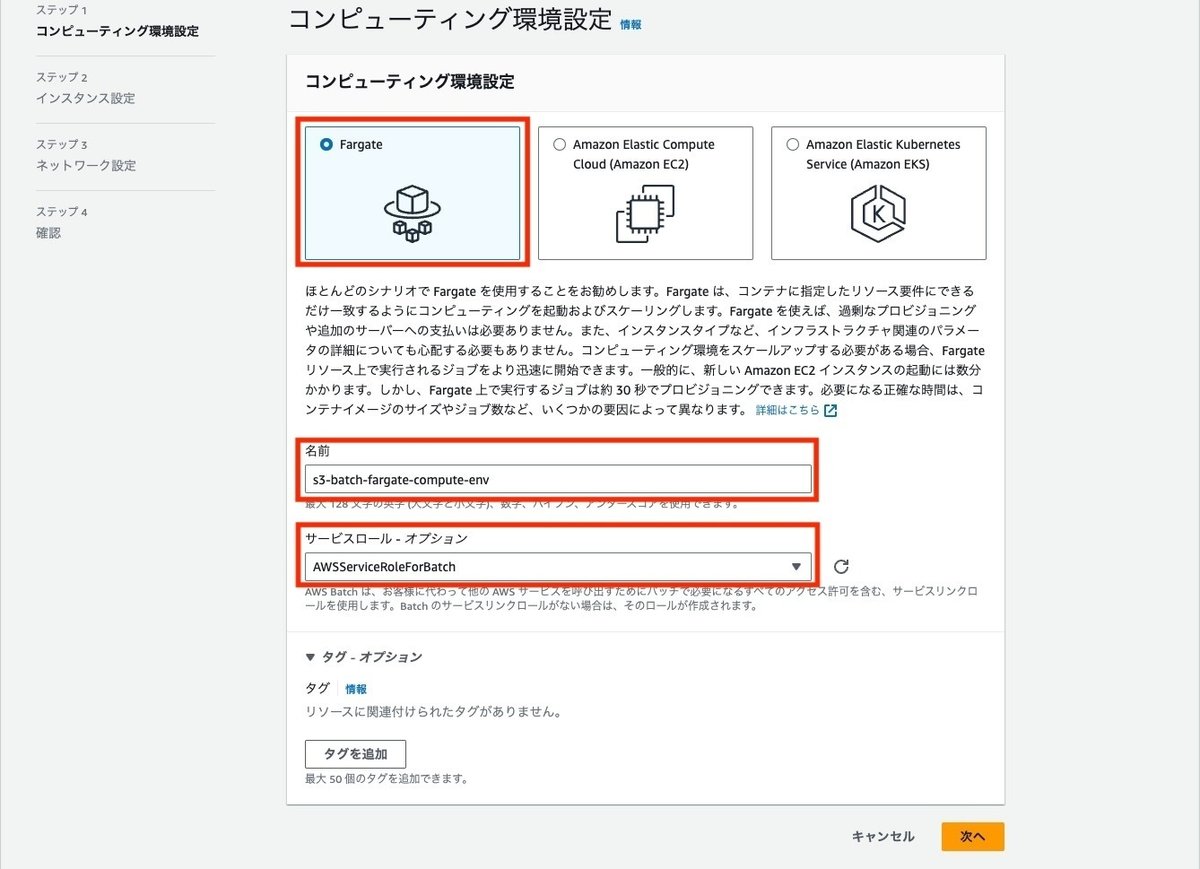
インスタンス設定で最大vCPUを設定します。初めの方に説明しましたが、この値まではFargateのコンテナのvCPU数に応じて、タスクを起動することができます。また、ここでFargateのSpot容量を使うかどうかの設定ができます。
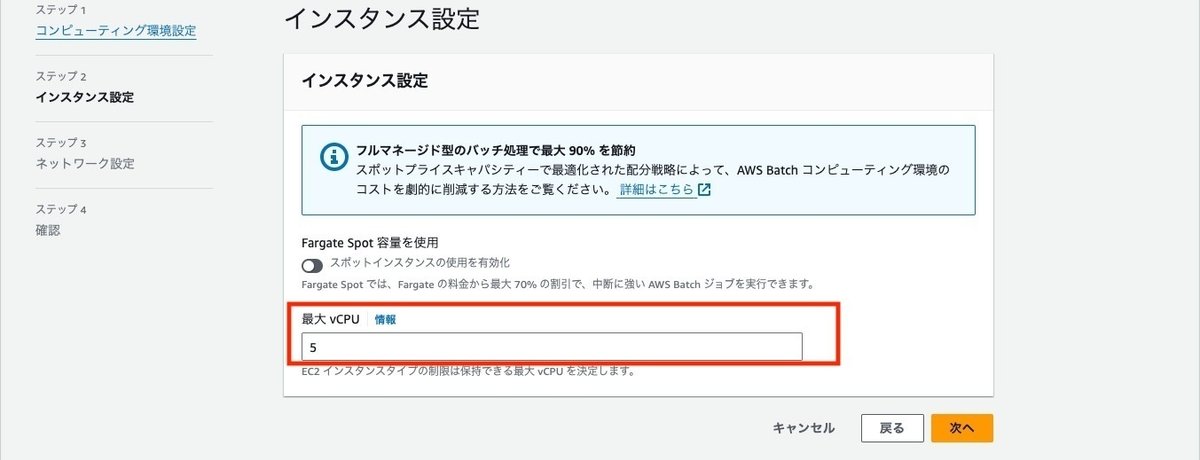
ネットワークは作成したVPC、サブネット、セキュリティグループを設定します。

内容を確認して作成します。
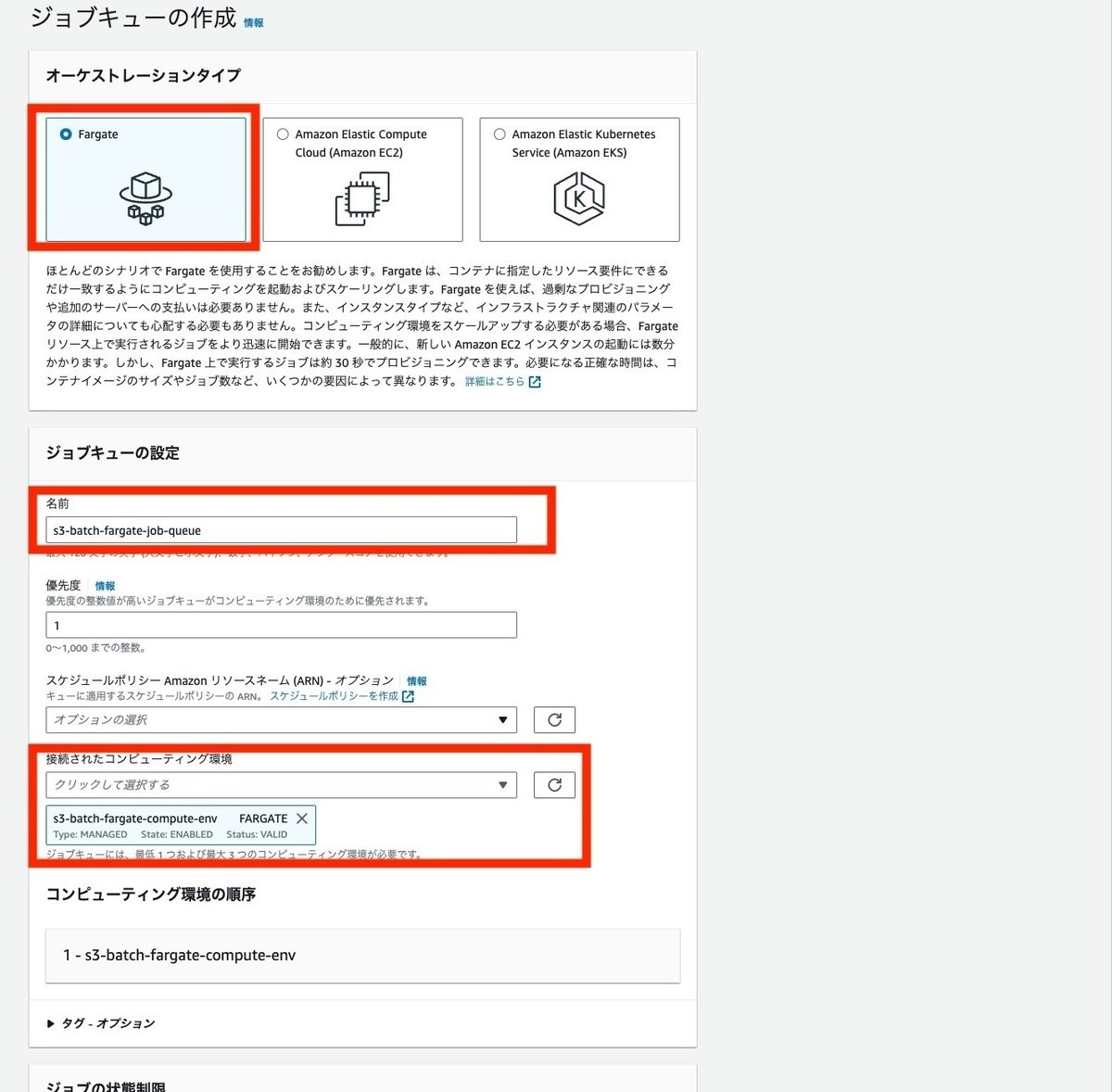
ジョブキューの作成
次にジョブキューを作成します。

ジョブキューでもオーケストレーションタイプは、Fargateを選択します。
名前と接続されたコンピューティング環境に先ほど作成したコンピューティング環境を設定して、作成します。
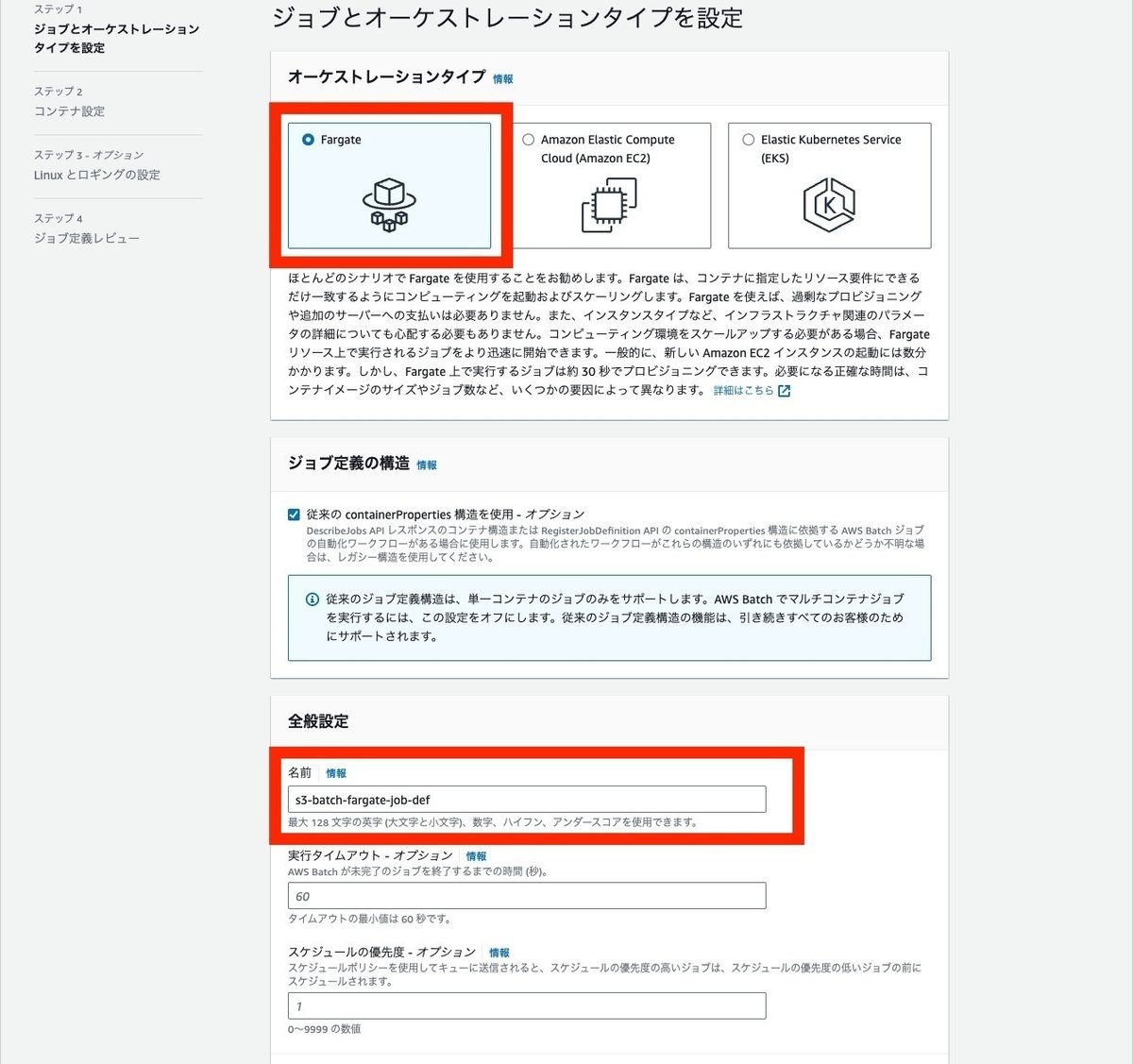
ジョブ定義の作成
次にジョブ定義を作成します。

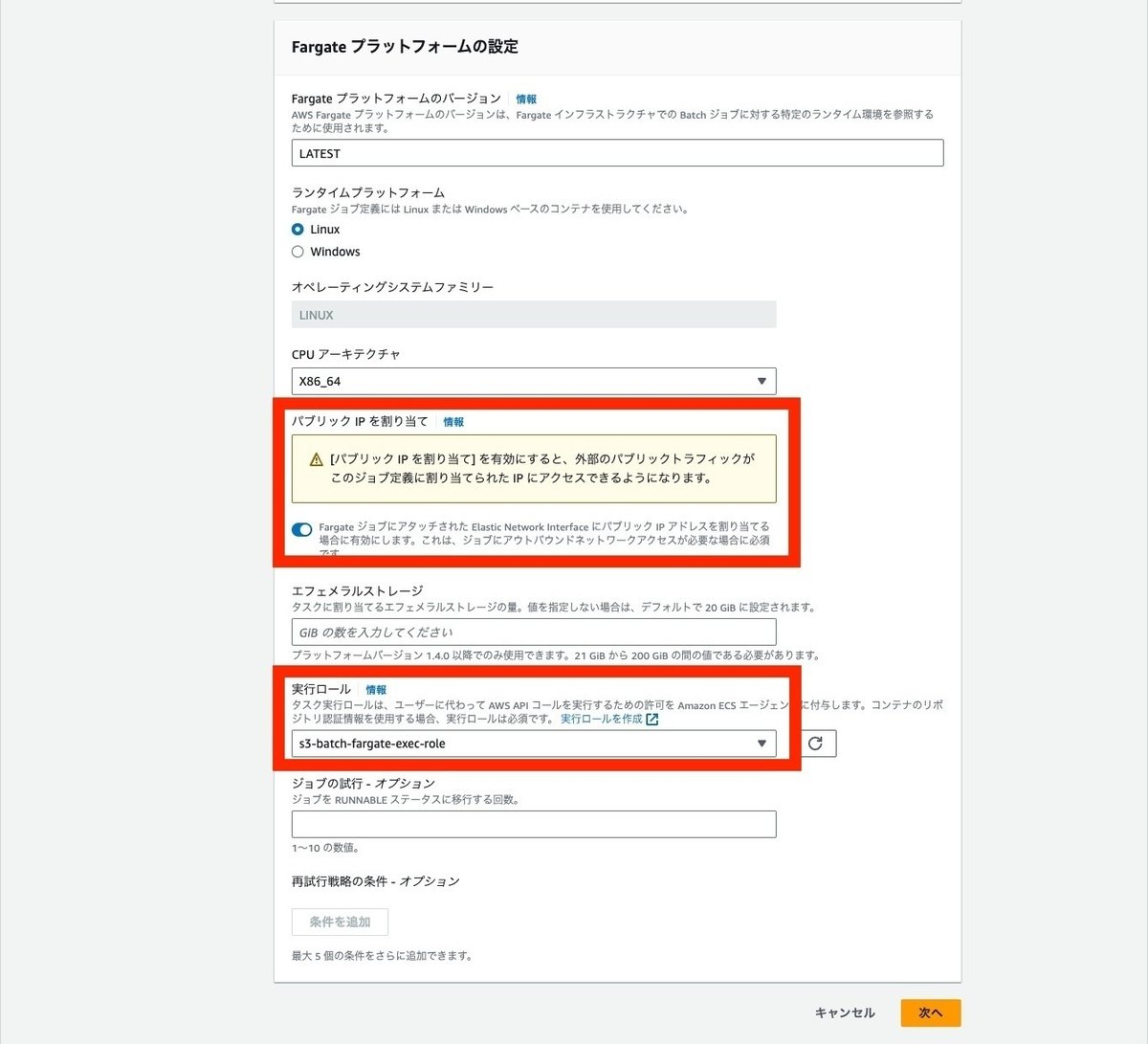
ジョブ定義でもオーケストレーションタイプでFargateを選択します。名前と実行ロールを設定します。パブリックIPの割り当ても、今回はパブリックサブネットで実行しているため、ONにしておきます。
※本来はプライベートサブネットにしてVPCエンドポイントを使って通信するのが望ましいです。
コンテナ設定でイメージに、先ほど作成しプッシュしたイメージのURLのlatestを設定し、コマンドを入力します。

コマンドは以下の通りです。特筆すべきことはRef::xxxという箇所で、この記載が実行時にはAWS Batchのパラメータとして置換されて、値を受け取ることができるようになります。上記画像のパラメータという項目に該当するのですが、今回はEventBridgeの方で入力トランスフォーマの機能を介して、S3イベントの情報を取得して設定するようにしますので、ここではパラメータの項目は設定不要です。
["node","/usr/src/app/app.js","--bucketName","Ref::bucketName","--objectKey","Ref::objectKey"]ジョブロールには、先ほど作成したFargateのタスクロールを設定します。vCPUやメモリは今回はデフォルトのままにしておきます。

ロギングの設定は、awslogsを選択します。この場合のログストリームはデフォルトの/aws/batch/job になります。もし独自のロググループを設定したい場合はロググループを作成して、awslogs-groupというオプションを追加し、作成したロググループを指定することで設定することが出来るようになっています。

awslogsのオプションについては以下に記載があります。
最後にジョブ定義の内容を確認して作成します。

EventBridge用のIAMロール、ポリシーを作成
S3の通知先となるEventBridgeのルールに設定するロールを作成します。今回はAWS Batchを実行するため、それらの許可などが必要になります。
IAMポリシーの作成
IAMポリシーは、作成したAWS Batchのジョブ定義、キューを利用して、バッチ実行を許可する権限とします。
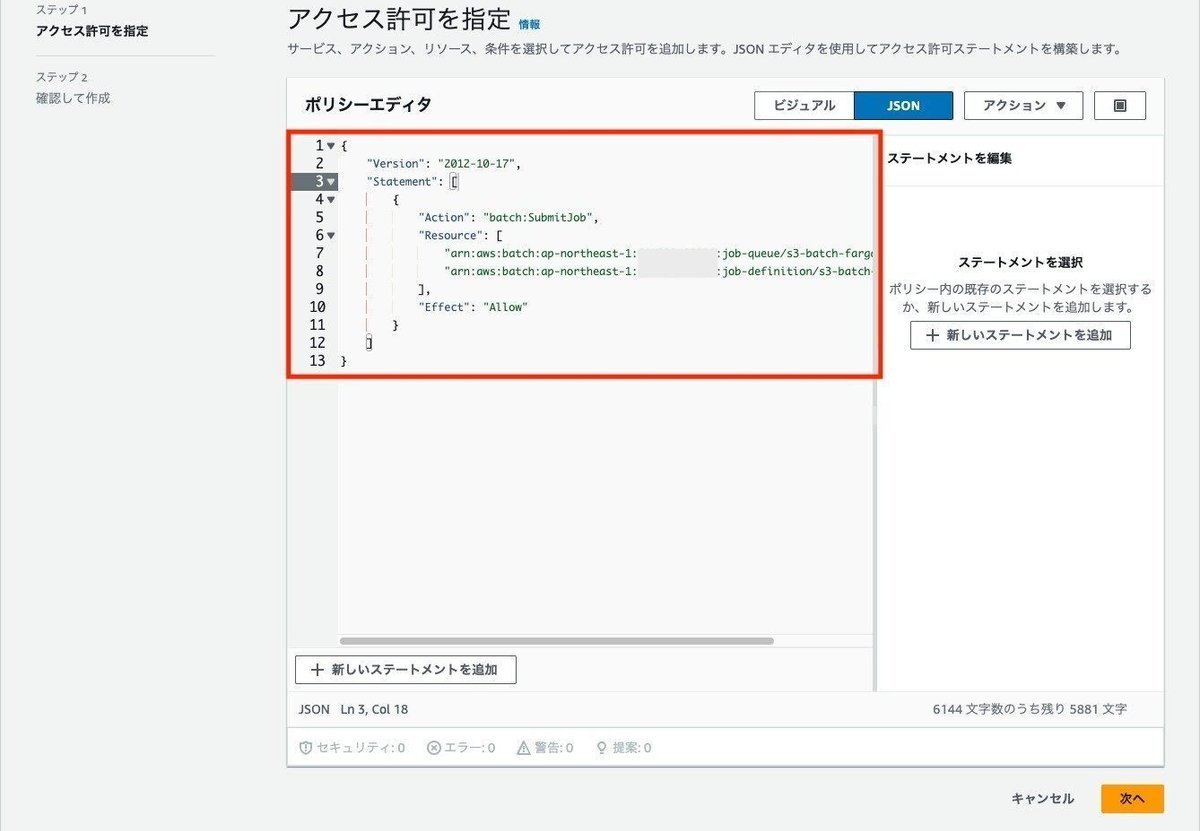
ポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "batch:SubmitJob",
"Resource": [
"arn:aws:batch:ap-northeast-1:{アカウントID}:job-queue/s3-batch-fargate-job-queue",
"arn:aws:batch:ap-northeast-1:{アカウントID}:job-definition/s3-batch-fargate-job-def"
],
"Effect": "Allow"
}
]
}ポリシー名を入力して、内容を確認しポリシーを作成します。

IAMロールの作成
IAMロールの信頼されたエンティティタイプは、カスタム信頼ポリシーを選択して、直接定義を入力します。
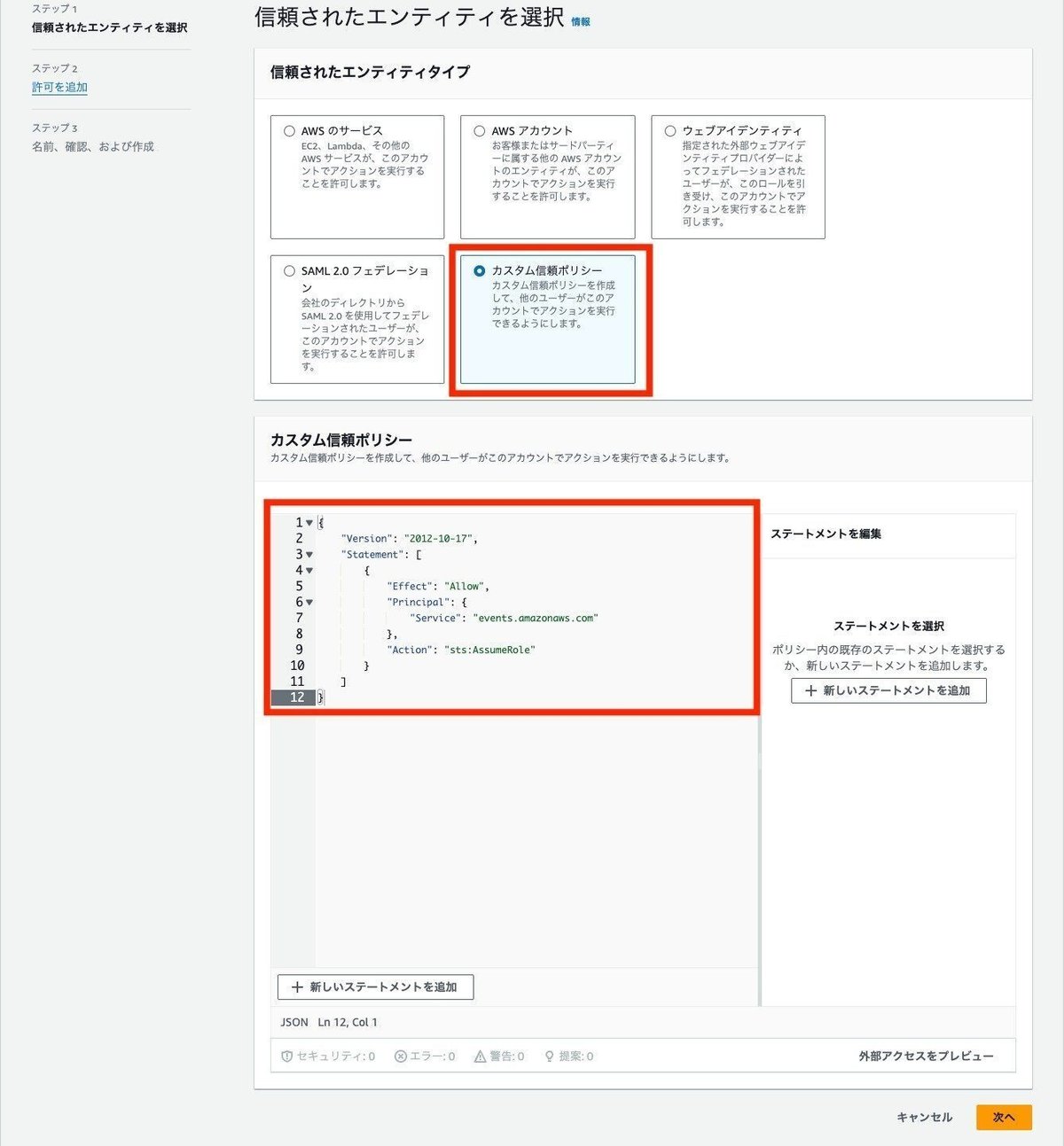
信頼ポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}許可ポリシーに、先ほど作成したポリシーを追加します。

ロール名を入力して、内容を確認してロールを作成します。

S3イベントの通知用のEventBrdigeルールを作成
S3にファイルがアップロードされた際のイベント通知を受け取り、AWS Batchのジョブを実行するEventBridgeのルールを作成します。

ルールの詳細では名前を入力します。

イベントソースとしては、その他を選択します。S3なのでAWSのイベントなのですが、オブジェクトのプレフィクスでのマッチをするためには、その他を選択する必要があるようです。
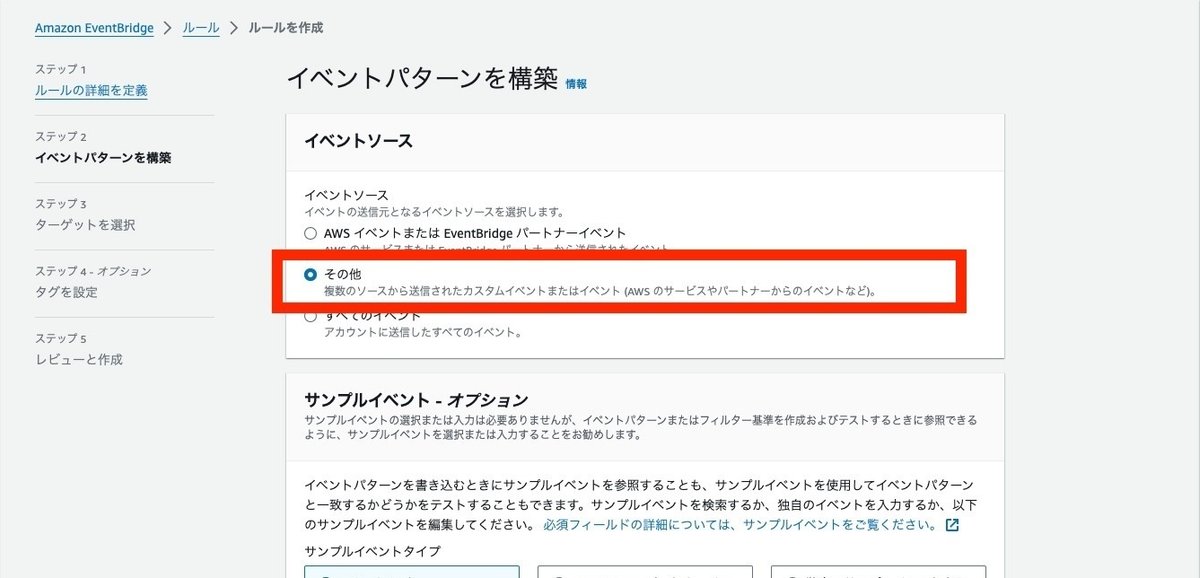
作成メソッドでカスタムパターンが選択されていることを確認して、イベントパターンにイベントの定義を入力します。

イベントパターンは以下の通りで、prefixがoriginalに一致するオブジェクトのみに限定しています。
この通知のルールとプログラム側でのアップロードの関係性は要注意です。仮に、この通知先と同じフォルダ(今回だとoriginal)にプログラム側でファイルをアップロードしてしまうと、それを検知してまたプログラムを実行するという、無限ループが発生して、高額な請求につながってしまいます。そのため、今回のプログラムでは、別で用意しているprocessedフォルダに処理済みファイルはアップロードするようにしています。
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["s3-batch-fargate-bucket"]
},
"object": {
"key": [{
"prefix": "original/"
}]
}
}
}続くターゲットの選択画面では、ターゲットタイプとして、バッチジョブのキューを選択します。下部の追加設定の欄を開いて、ターゲット入力を設定の項目で入力トランスフォーマーを選択し、入力トランスフォーマーを設定ボタンをクリックして入力トランスフォーマーの設定モーダルを開きます。
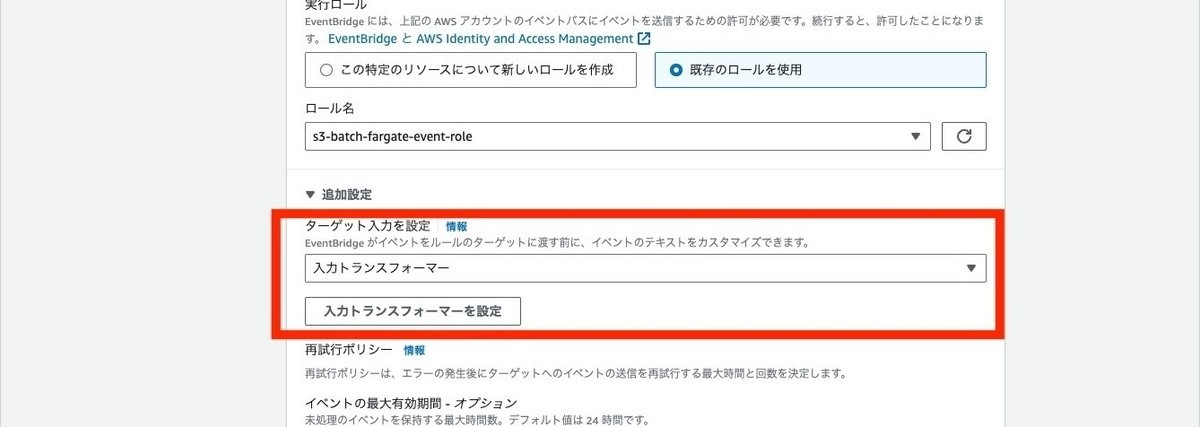
ターゲット入力トランスフォーマーの入力パスにS3イベントから値を取得する定義を入力し、テンプレートにはAWS Batchに渡すパラメータの定義をします。
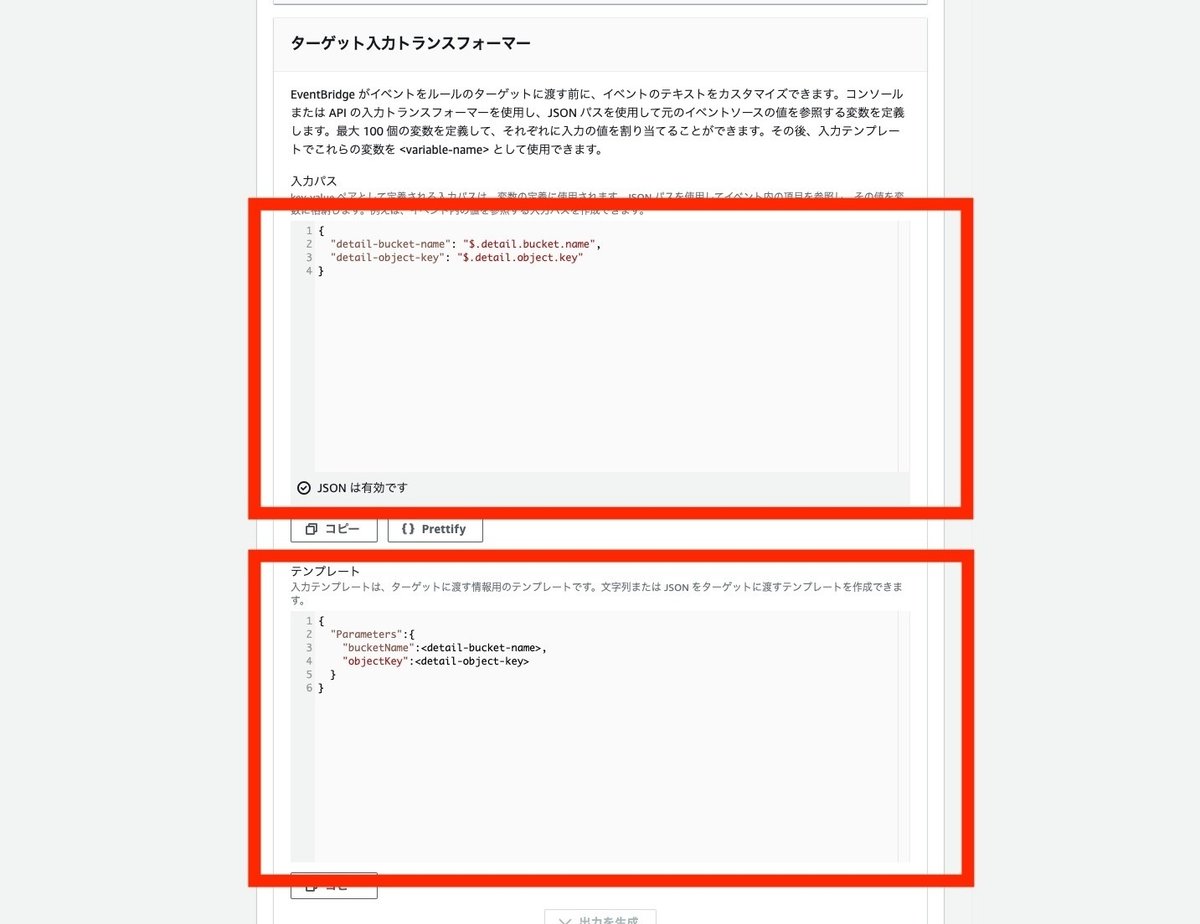
入力パスの設定は以下の通りです。
{
"detail-bucket-name": "$.detail.bucket.name",
"detail-object-key": "$.detail.object.key"
}このS3のイベント構造については、以下に記載があります。
テンプレートの設定は以下の通りです。
{
"Parameters":{
"bucketName":<detail-bucket-name>,
"objectKey":<detail-object-key>
}
}テンプレートについては以下に記載があります。
あとはAWSのサービスのターゲット選択でバッチジョブのキューを選択し、ジョブキューのARN、ジョブ定義のARN、ジョブ名を入力し実行ロールに作成したEventBrige用のロールを選択します。

タグの設定は任意に入力し、最後に設定内容を確認してルールを作成します。

動作確認
動作確認としてS3のoriginalフォルダにファイルをアップロードします。

AWS Batchのジョブで実行されることを確認します。
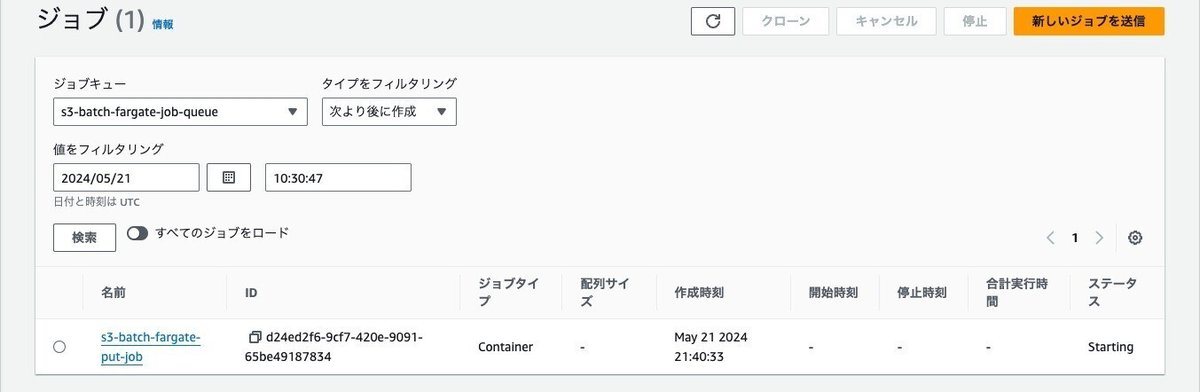
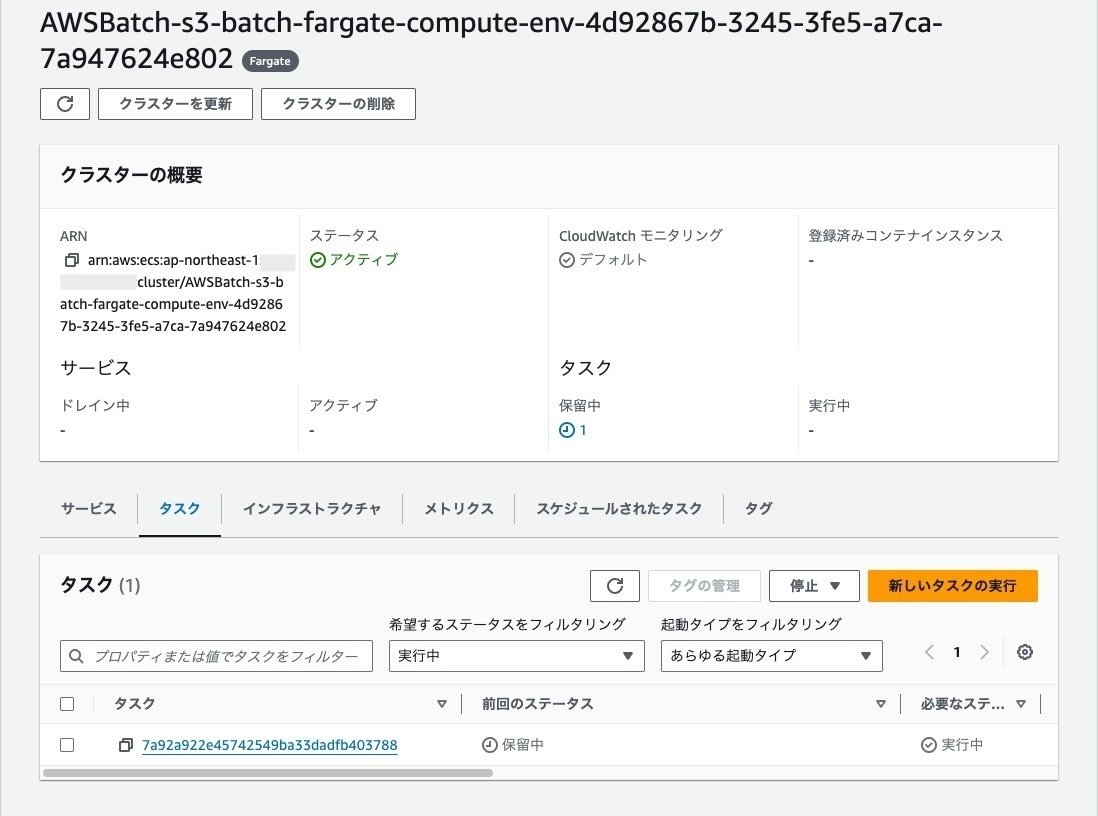
ECSのタスクが実行されていることを確認します。
S3のフォルダにファイルがアップロードされていることを確認します。

リソースのクリーンアップ
EventBridgeのルールの削除
AWS Batch
ジョブ定義の登録解除
ジョブキューの無効化と削除
コンピューティング環境の無効化と削除
ECRのリポジトリの削除
ECSのタスク定義の登録解除と削除
ジョブ定義で登録解除しても、ECSの方では残っているため一応実
IAMロールとポリシーの削除
2つのポリシー削除
3つのロール削除
セキュリティグループの削除
VPCの削除
S3バケットを空にして削除
まとめ
今回はAWS Batchと連携をしましたが、EventBridgeを利用した連携はさまざまなサービスと連携ができるため、覚えておくと引き出しが多くなり良さそうな感じでした。
また、AWS Batchはジョブで、さまざまなことが確認できたり、クローンして少しパラメータを変えて再実行ということも簡単にできるようになっているため、運用上も良さそうでした。デットレターキューも設定ができるため、もしものために残しておくということもできそうです。
IaCも作成したので興味ある方は見てください。