
S3のイベント通知でLambdaを実行する

S3のイベント通知で、Lambdaを実行するというよくあるパターンをやってみました。SQSを間に挟むのや、そこからAWS Batchを実行するパターンも合わせてやっていたので、それも別途上げようと思いますが、ひとまず一番シンプルなパターンからです。
処理の流れ
S3バケットにファイルをアップロードする
Lambdaが実行される
Lambdaでファイルをダウンロードする
Lambdaでダウンロードしたファイルを加工する
処理後のファイルを別のS3バケットにファイルをアップロードする
構成図

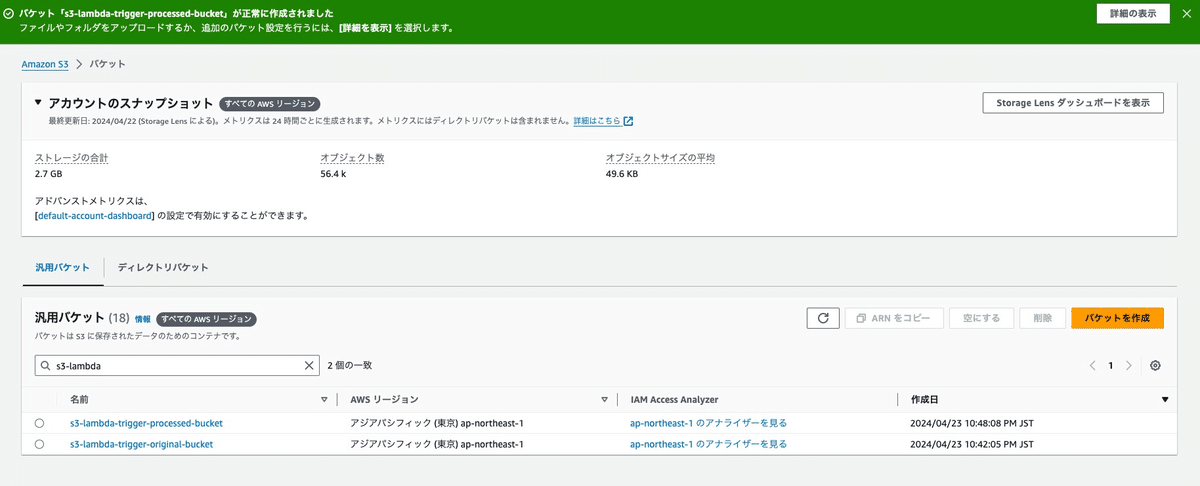
イベント通知用のS3バケットの作成
イベント通知を設定するS3バケットを作成します。バケット名を入力して、それ以外は今回はデフォルトで、バケットを作成します。


処理済みファイル用のS3バケットの作成
Lambdaで処理したファイルをアップロードするバケットを作成します。バケット名を入力して、それ以外は今回はデフォルトで、バケットを作成します。

Lambda用のIAMポリシーとロールの作成
Lambda用のポリシーを作成します。権限としては、以下の2つを設定して次へボタンをクリックします。
イベント通知用のS3バケットに対してs3:GetObjectを付与した権限
処理済みファイル用のS3バケットに対してs3:PutObjectの権限
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::s3-lambda-trigger-original-bucket/*"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3:::s3-lambda-trigger-processed-bucket/*"
}
]
}
ポリシー名を入力して、内容に間違いがないか確認してポリシーを作成ボタンをクリックします。


次にLambda用のロールを作成します。ユースケースはLambdaを選択して次へボタンをクリックします。

AWSLambdaBasicExecutionRoleと先ほど作成したポリシーを選択して次へボタンをクリックします。


ロール名を入力して、内容に間違いがないか確認してロールを作成ボタンをクリックします。


Lambda関数を作成する
関数名を入力し、既存ロールに先ほど作成したロールを設定して、関数の作成ボタンをクリックします。
ランタイムについては、今回はPython3.12を使ってみます。

作成されたら実行を確認するためテストボタンをクリックします。
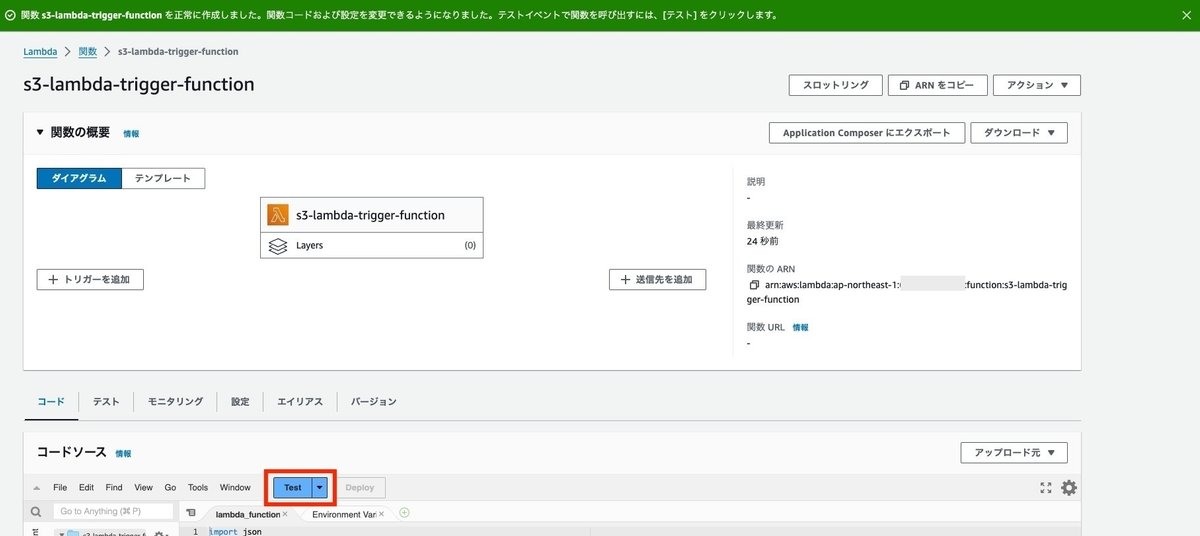
イベント名を入力して、保存ボタンをクリックします。

テストボタンをクリックしてテストを実行し、実行が成功するか確認します。

タイムアウト設定ですが、デフォルトの3秒だとS3とのやり取りでオーバーしてしまう可能性があるため変更しておきます。設定タブをクリックして一般設定の編集ボタンをクリックします。

30秒に変更して保存ボタンをクリックします。

コードについては、今回はテキストファイルの最終行に処理日時を書き込むという単純な処理にして、処理後のファイルは処理済みのS3バケットにアップロードします。
処理済みのS3バケット名は環境変数とかで設定しておいたほうが良いですが、今回はベタ書きでいっちゃいます。
import json
import boto3
import datetime
from datetime import datetime
from zoneinfo import ZoneInfo
PROCESSED_BUCKET_NAME = "s3-lambda-trigger-processed-bucket"
def lambda_handler(event, context):
try:
if "Records" not in event:
return
if "s3" not in event["Records"][0]:
return
s3_info = event["Records"][0]["s3"]
bucket = s3_info["bucket"]["name"]
key = s3_info["object"]["key"]
file_name = key.split("/")[0]
tmp_file_path = f"/tmp/{file_name}"
s3 = boto3.resource("s3")
s3.meta.client.download_file(bucket, key, tmp_file_path)
with open(tmp_file_path, mode="a", encoding="utf-8") as f:
now = datetime.now(ZoneInfo("Asia/Tokyo"))
now_str = now.strftime("%Y/%m/%dT%H:%M:%S.%f%z")
f.write(f"\n{now_str}")
s3 = boto3.client("s3")
s3.upload_file(tmp_file_path, PROCESSED_BUCKET_NAME,
f"processed_{file_name}")
except Exception as e:
print(e)入力したら、Deployボタンをクリックしてデプロイをします。

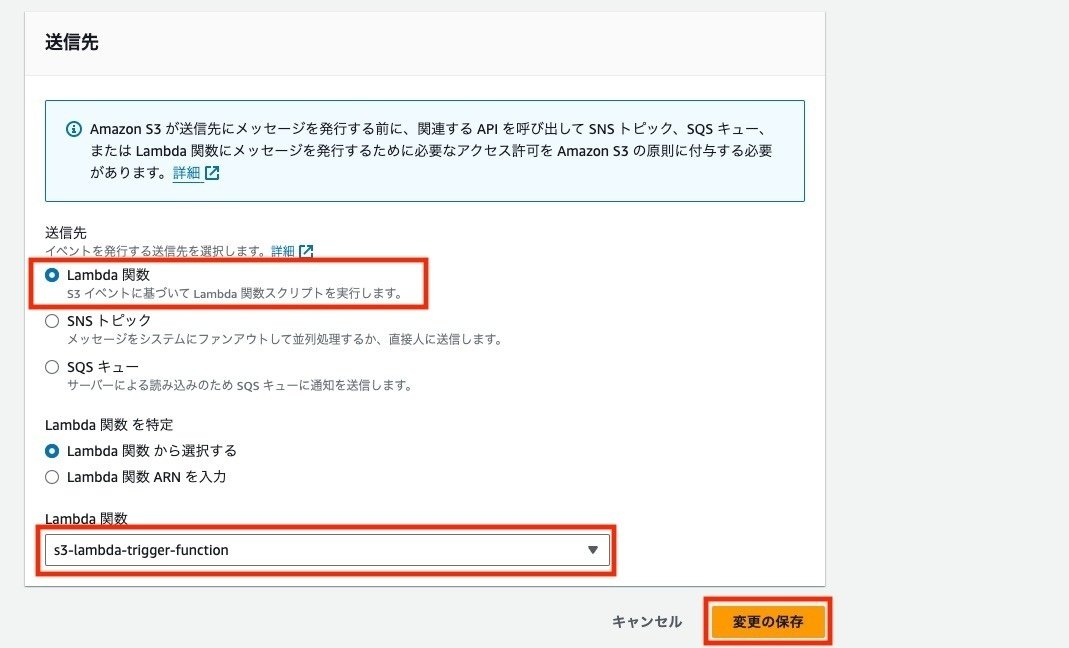
S3バケットにイベント通知を設定
イベント通知用のバケットの詳細画面に入り、プロパティタブを選択します。

イベント通知というブロックがあるので、イベント通知を作成ボタンをクリックします。

イベント名を入力し、サフィックスに「.txt」を設定します。イベントタイプは今回はオブジェクトの作成のPUTのみにしておきます。

送信先でLambda関数を選択して、先程作成したLambda関数を設定します。その他の設定に関してはデフォルトのままとして、変更の保存ボタンをクリックします。

動作確認
動作確認として、イベント通知用バケットにテキストファイルをアップロードします。

ファイルを追加して、アップロードボタンをクリックします。

アップロード用のバケットの詳細画面に入り、処理済みのファイルがアップロードされていることを確認します。ファイルをダウンロードして、日付が追記されていることを確認します。


注意点
同じバケットに配置する場合は、設定によってはイベント通知がループしてしまい、高額な請求につながるため注意が必要です。別バケットにアップロードするのが単純で良いですが、同じバケットにする場合は、プレフィクスを変えて、通知を受け取るプレフィクスを限定することで、回避することは出来ます。
例としては、original/をプレフィクスとして設定しておき、Lambda処理後のアップロード先は、original/以外にすることで、ループになることを避けることが出来ます。

リソースのクリーンアップ
Lambdaの削除
LambdaのCloudWatch Logsのロググループの削除
Lambda用のロールとポリシーの削除
処理済みファイル用のS3バケットを空にして削除
イベント通知用のS3バケットを空にして削除
まとめ
簡単にLambdaを実行できますね。ファイルの加工や解析など、APIのリクエストとしては、少し時間がかかることや、非同期で実施されれば良いことなどは、こういった方法で処理させるというのも1つの選択肢として持っておきたいところです。
IaCも作成したので興味ある方は見てください。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?