
組織の生産性とサービスの安定稼働をミッションにするチームを立ち上げてからの半年を振り返る

株式会社ヘンリーでSREをしている戸田(@Kengo_TODA)です。2022年の7月にジョインして、組織の生産性とサービスの安定稼働をミッションにする「Platform Group」の立ち上げを行ってきました。この半年間を振り返って、どのような改善が行えて何を課題としているかをまとめてみます。
組織の生産性の向上がミッション
私たちはPlatform Groupを「技術基盤の開発などを通じ組織全体の生産性を上げる」ことをミッションとして立ち上げました。
当時ヘンリーにはフロントエンドやバックエンドの開発を担うエンジニア社員が15名ほどいましたが、生産性の向上に注力していたエンジニア社員はいませんでした。そのためPlatform Groupではビルドスクリプトや開発ワークフローから本番環境のインフラストラクチャ、社員向け資料作成まで幅広い舞台での生産性向上を担いました。
また従業員が価値創造に注力するには、安定したサービスとお客様に安心してご利用いただけることも必要です。SREの目指すSite Reliabilityはもちろん、患者情報などをお預かりする医療機関向けサービスとしての信頼を勝ち取るための活動にも取り組んでいます。
組織の生産性向上
何をもって「生産性が高い」とするかは組織やそのフェーズによって異なると考えています。この半年は現状を掴み課題を知るうえでも、広く使われているFour Keysを採用した生産性の可視化と共有に取り組みました。
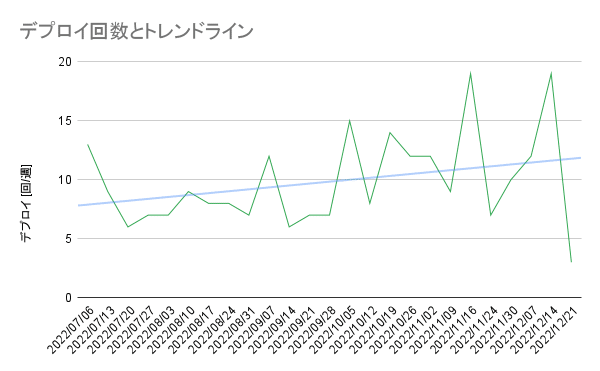
ここではデプロイ回数と変更障害率の変遷をご紹介します。
サービス全体でのデプロイ回数は下図に示すとおり1.5倍に増えてきていますが、チーム間での調整を必要としている関係上このままだと頭打ちになると考えています。調整を無くし各チームが各々の判断でデプロイを行える体制を作る必要があると考えています。
また変更障害率は以下のように推移しています。DORAの調査によるHealthcare業界全体の変更障害率をまずは目標水準とし、これを下回ることを目指しています。
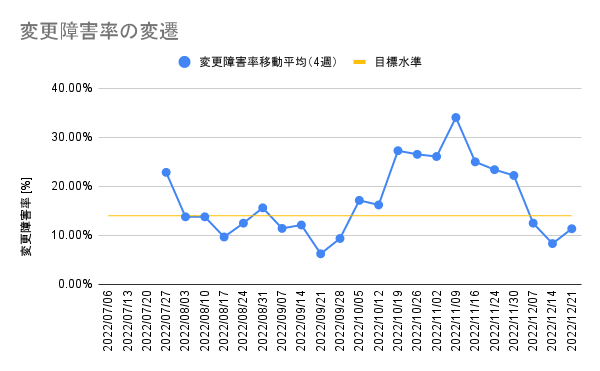
10月から11月の変更障害率がかなり高く出ていることが見て取れます。これは10月下旬にデータ構造を変えたことで、データマイグレーションや検索周りでの不具合が続いたことが原因です。
データの量や特徴に起因する不具合はデプロイ前の動作確認では見つけにくいのが現状で、品質保証のやり方を見直すと同時に、動作確認用のデータをどう準備するかを考えていく必要があると考えています。
開発ワークフローの最適化
ヘンリーではサーバサイドをKotlin、クライアントサイドをTypeScriptで記述しており、その開発ワークフローにはGradle, Yarn, Circle CI, GitHub Actionsを利用しています。PR作成時に実行されるワークフローは概ね10~15分程度で終わりますが、プロジェクトの成長によって所要時間が長くなる傾向にあるため、継続的にパフォーマンスを観察して高速化を行ってきました。
中でも効果が高かったのは、gradle-gcs-build-cacheによるGradle Remote Cacheの導入です。これにより以前実行したビルドの結果を再利用することで、必要最低限のビルドのみ実行可能となりました。Google Cloud Storageの機能によって古いキャッシュが自動で削除されたり、きめ細かいアクセス管理ができるのも嬉しいところです。
今はまだ16分かかっていたビルドを12分に短縮するだけにとどまっていますが、Gradle プロジェクトのサブプロジェクト分割やビルドスクリプトのPrecompiled script plugin化を進めることで更なる高速化効果を期待できそうです。
この他にもDocker BuildKitの導入や社内向けホスティングサイトの提供、不要なワークフローの棚卸しやDetekt拡張の提供などを行ってきました。開発生産性を高く保つことはスタートアップの生命線であり、今後も注力していきます。
サービスの安定稼働
弊社サービスは診療はもちろん、会計や処方箋の印刷にも利用されることから、常時ストレスなくスムーズに利用できることが求められています。
このためお客様が安定してサービスを利用できていることを評価するための指標として、GraphQLエンドポイントのレイテンシを継続的に評価しています。
多くのリクエストに迅速にレスポンスできていれば良し、できていなければCloud Traceで原因を探してNotionに起票しています。またレセプト返戻業務のためのアクセスが毎月上旬に集中することや、どういった時間帯にユーザが電子カルテやレセコンを利用されているかも、こうした監視から見えて来ます。こうした顧客理解を深めることで、今後のデプロイスケジュールの検討や計算機資源の最適化を通じた安定稼働の実現に役立てられるでしょう。
またサービス内で発生したエラーを確認し、UXの改善やノイズとなるエラーの抑制に繋げています。ここ最近で効果が高かったものはApolloクライアントへのRetry Linkの導入で、顧客の手元で発生する通信エラーを6割削減できました。

最後に、安定稼働のためには脆弱性への対応も重要です。Renovateを使って依存を新しく保つと同時に、Container Scanning機能を使ってコンテナに含まれる既知の課題を発見・解決する体制も整えました。他にも有事の対応について規定を整備するなどの取り組みも行いましたが、これについては別の機会にお話できればと思います。
この他にもPostgresの索引最適化やBigQueryのリソース利用最適化、JVMオプションの変更によるGC最適化、ログベースの指標を用いたGC頻度監視などを行ってきました。幸い大きな障害はここ半年では生じていませんので、これを継続できるよう工夫していきます。
まとめ
Platform Groupで実施してきた施策を振り返り、改善された点と残課題の双方を確認しました。開発ワークフローを最適化することでエンジニアの開発体験を、Retry Linkの導入やJVM監視などによって顧客の体験を有意に改善できたと考えています。
一方で各チームが個別にデプロイする体制の構築や、品質保証の支援には大きな課題が認められ、今以上に生産性を高めるにはこれらの改善が急務だと言える状態です。
2023年はこうした課題の実現に向けて動いていく年となります。さっそく第1四半期では、各チームが各々の判断でデプロイを行える体制を作ることを目標としました。
ヘンリーは顧客と同僚の体験を改善していきたい仲間を絶賛採用しております。急拡大するチームを支えるリリース体制を実現したい方、品質保証プロセスの理想を踏まえた開発体制構築に関心のある方は気軽にご連絡ください。お待ちしています!
/assets/images/11564992/original/1a57ddaa-8297-4fd7-a337-88daa2afa974?1671554327)