
Keda を使ったスケーラブルな非同期ワーカーの実装

はじめに
こんにちは! hayashida と申します。
くふうAIスタジオのインフラエンジニア・SRE として、家計簿アプリZaim の開発を担当しています。
今回は、Zaim にて Pod のイベント駆動型オートスケール基盤としてオープンソースである Keda を導入した件について紹介したいと思います。
なぜ必要だったか
前提として、Zaim では大部分のアプリケーションがコンテナ化されておりコンテナオーケストレーションツールとして kubernetes を利用しています。
そして今回起動したかった非同期ワーカーコンテナは SQS のキューにメッセージがセットされたことをトリガーに起動させる必要がありました。
待ち受け Pod を常時起動させておくという選択肢もありましたが、メッセージが 0 の状態で起動させておくのはリソースの無駄で勿体ないのでやりたくありませんでした。
Keda 自体がメッセージの検知のために SQS キューのポーリングを行うので、API リクエスト料金は別途かかるのですが Pod 常時起動のコストよりは低コストであると判断しました。
またメッセージの数に応じて Pod 数の増減(オートスケール)も行う必要があったので、これらの要件を実現するために Keda を導入しました。
Keda の説明
Keda は「Kubernetes Event-driven Autoscaling」の略で、SQS のキューのメッセージだけに留まらず色んなリソースのイベントをトリガーに Pod を起動することが出来ます。
Keda の中では Scaler という概念で書かれていますが下記のような複数のリソースをトリガーに出来ます。
AWS SQS Queue
AWS Kinesis Stream
Elasticsearch
Google Cloud Platform Storage
etc ...
また Cloud Native Computing Foundation から GRADUATED AND INCUBATING PROJECT として認定されており、基本的には Production レベルで使用しても問題ないとされてます。
Keda の詳細
Keda 自身も Pod として kubernetes クラスター上に稼働させる必要があり大きく 3 つの Pod で構成されていてそれぞれの役割は下記のようになります。

実装のプロセス
Keda のインストール
まずは kubernetes クラスターに Keda をインストールします。
今回はマニフェストの作成やバージョン管理を楽にしたかったので、kubernetes 用のパッケージマネージャーである Helm を使ってインストールしました。
また Zaim では CD ツールとして Argo CD を利用しているので
Argo CD Application として Keda をインストールします。
マニフェストは下記のようにしました。
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: keda-helm-production
namespace: argocd
spec:
destination:
namespace: keda
server: 'https://xxxxxxxxxxxxxxxxxxxxx.yl4.ap-northeast-1.eks.amazonaws.com'
project: default
source:
repoURL: 'https://github.com/kedacore/charts.git'
targetRevision: v2.13.2
path: keda
helm:
values: |
watchNamespace: hoge-namespace
syncPolicy:
automated:
prune: true
syncOptions:
- CreateNamespace=true
- ServerSideApply=trueここで忘れずに指定すべきなのが watchNamespace で、デフォルトでは全てのネームスペースをが Keda の監視対象になってしまいます。
今回は特定のネームスペースだけを監視したかったので watchNamespace にて指定しました。
※ネームスペースの説明は本稿とは関係ないので、割愛致します。(詳しくは kubernetes の公式ドキュメントをご参照ください。
TriggerAuthentication を定義して適切な IAM ロールを設定する
今回は SQS キューのメッセージをトリガーにするので、operator などの Keda の各 Pod にキューの情報を読み取るための IAM 権限を付与する必要がありました。
これを実現するために Keda の CRD (CustomResourceDefinition) である TriggerAuthentication を定義しました。
具体的なマニフェストは下記です。
このマニフェストでは、IAM ロールを Pod にバインドしています。
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: hoge-keda-trigger-auth
namespace: hoge-namespace
spec:
podIdentity:
provider: aws
roleArn: 'arn:aws:iam::99999999999:role/hoge-pod-role'要件に応じて、ScaledObject と ScaledJob を適切に使い分ける
Pod をスケールするために、Keda の CRD である ScaledObject あるいは ScaledJob を定義する必要があります。
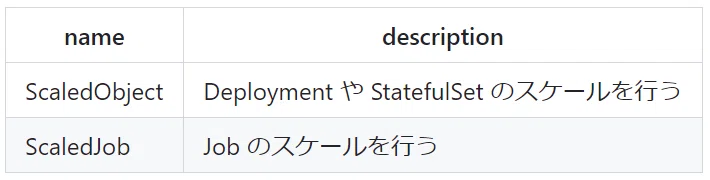
※ Deployment や StatefulSet 及び Job の説明は本稿とは関係ないので、割愛致します。(詳しくは kubernetes の公式ドキュメントをご参照ください。
具体的なマニフェストは下記です。
ScaledObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: hoge-scaledobject
namespace: hoge-namespace
spec:
cooldownPeriod: 300
maxReplicaCount: 5
minReplicaCount: 0
pollingInterval: 30
scaleTargetRef:
name: hoge-deployment
triggers:
- authenticationRef:
name: hoge-keda-trigger-auth
metadata:
awsRegion: ap-northeast-1
identityOwner: pod
queueLength: "5"
queueURL: "https://sqs.ap-northeast-1.amazonaws.com/account_id/QueueName"
type: aws-sqs-queuescaleTargetRef でスケール対象を設定します。
その他 triggers で何をトリガーにするかを設定します。
この例では、type を aws-sqs-queue にしています。
ScaledJob
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: hoge-job
namespace: hoge-namespace
spec:
failedJobsHistoryLimit: 3
jobTargetRef:
backoffLimit: 0
completions: 1
parallelism: 1
template:
spec:
containers:
- command:
- /bin/hello-world
image: ubuntu:latest
name: hoge-job
triggers:
- authenticationRef:
name: hoge-keda-trigger-auth
metadata:
awsRegion: ap-northeast-1
identityOwner: pod
queueLength: "1"
queueURL: "https://sqs.ap-northeast-1.amazonaws.com/account_id/QueueName"
type: aws-sqs-queueScaledObject との違いは jobTargetRef など Job 用の属性がある点です。
要件に応じて、pollingInterval や cooldownPeriod など各種パラメーターをチューニングする

各種パラメーターをワークロードの要件に合わせて適切に設定します。
例えば pollingInterval ですが、仮に SQS キューにメッセージが追加されたときに出来るだけ早くメッセージを処理したい場合は pollingInterval の値を短めにします。
queueLength を適切に設定して、メッセージの量に応じてスケールアウト・スケールインさせる
1 pod につき何個のメッセージを処理させたいかを queueLength にて指定します。
例えば queueLength を 5 に設定した場合、100 個のメッセージがキューに追加されると 20 個の pod が起動されます。
先述の pollingInterval 同様に、出来るだけ早くメッセージを処理したい場合などは queueLength の値を短くしてかつ maxReplicaCount を大きくするように設定します。
運用してみて
運用を開始してみると、幸いなことに現在まで大きな問題は発生していません。
一部 ScaledJob を使うべきケースで ScaledObject を使っていたため問題が起こりました。
例えば、Pod のワークロードが比較的に長めになるような処理を動かす場合
ScaledObject を使った場合、処理が完全に完了していないのに Pod が終了されてしまうという問題が起こりました。
これは ScaledObject が SQS キュー内のメッセージが 0 になったことを検知して cooldownPeriod を経過したら Pod を終了させる仕様になっているためです。
しかし長めのワークロードの場合、メッセージが 0 になっているにも関わらず未だワークロードが終了していないということがあります。
こういったケースでは、ScaledJob の方が適していることが分かりました。
また、Keda には leader election の仕組みが実装されており
operator や metrics-server の冗長化構成も実装出来るようなので
より安定したオートスケール基盤を運用していくために今後はこの leader election の仕組みの有効化も検討していきます。
くふうAIスタジオでは、採用活動を行っています。
当社は「AX で 暮らしに ひらめきを」をビジョンに、2023年7月に設立されました。
(AX=AI eXperience(UI/UX における AI/AX)とAI Transformation(DX におけるAX)の意味を持つ当社が唱えた造語)
くふうカンパニーグループのサービスの企画開発運用を主な事業とし、非エンジニアさえも当たり前にAIを使いこなせるよう、積極的なAI利活用を推進しています。
(サービスの一例:累計DL数1,000万以上の家計簿アプリ「Zaim」、月間利用者数1,600万人のチラシアプリ「トクバイ」等)
AXを活用した未来を一緒に作っていく仲間を募集中です。
ご興味がございましたら、以下からカジュアル面談のお申込みやご応募等お気軽にお問合せください。
この記事が気に入ったらサポートをしてみませんか?