
ベイズ推定入門|野球選手の打率を推定したい

今年になって『データ解析のための統計モデリング入門(通称 緑本)』を読みました。
とても読者にやさしく書かれているなと感じる一方、どうしても特に後半が個人的に難しく「もっと理解したいな」と思ったため David Robinson さんが書かれた記事なども参考にしつつ、もう少し自分なりに噛み砕いて考えてみようと思います。
ベイズ推定がよくわかってないことが理解が難しかった大きな原因のひとつだと感じたので、こちらの記事ではベイズ推定の基本的な考え方からまとめて共有できればと思います。
・ ベイズ推定に入門したい方
・ rstan に少し触れてみたい方
・ 緑本を読書中の方
などなど
そんな方々に一緒に楽しんでいただける記事になっているとうれしいです。
ベイズ推定とは
まずはベイズ推定の全体の流れを確認したいと思います。ベイズ推定は大きく以下の流れで作業を進めていきます。むずかしい言葉がたくさん出ているかもしれませんが、あとでひとつずつ説明していきます。

③ の推定量を作成する段階では「ベイズ更新」によって得られた事後分布をもとに MCMC を用いて事後分布に従う乱数を生成し、その乱数をつかって推定量を得ることになります。しかし場合によっては「共役事前分布」と呼ばれる分布を使い、手計算で推定量を作ることも可能です。今回はメインで rstan を用いた MCMC でのベイズ推定を紹介し、その後に共役事前分布を用いた推定量の求め方もご紹介します。
流れをざっくりと確認したところで、具体的な例を見ながらより詳細を把握していきたいと思います。① の「事前分布と尤度の定義」から一緒に確認していきましょう。
① 事前分布と尤度を定義する
ここからは野球の打率$${p}$$の推定を例に取って考えていきます ⚾
■ 事前分布の定義
「事前分布」は分析者の経験をパラメータの推定に反映させるために事前に定義する分布です。特定のパラメータが真実であるという確信度を表すもので、これを確率分布として表現します。今回推定したいのは打率$${p}$$なので、$${p}$$について事前分布を定義します。今回は、例えば成功数$${α}$$・失敗数$${β}$$をパラメータに取り、成功率の分布を表現できるベータ分布$${Beta(α,β)}$$を事前分布として使います。いくつかパラメータ$${α}$$, $${β}$$を変えたベータ分布を並べてみます。

わたしは今回、事前の経験から野球の打率は2割5分くらいになることが多そうだと考えています。そのため平均値が 0.25 となり、分布の形も事前知識
とそれほど大きく乖離のないベータ分布$${Beta(2, 6)}$$を打率$${p}$$の事前分布として選択することにします。このように、もし打率に対して知識があり、事前になんらかの想定ができる場合は$${p}$$の範囲を縛れるように情報を持った分布を設定できます。
以下は選手が複数いる場合の、各選手$${i}$$の打率$${p_i}$$の事前分布の様子です。それぞれに同じ事前分布$${Beta(2, 6)}$$を敷いています。

■ 尤度の定義
「尤度」とは、ある打者についてある打率$${p}$$が真実だったとしたときに今回のようなデータ(打席数$${AB}$$・安打数$${H}$$)が得られる確率のことです。今回、安打数$${H}$$は打席数$${AB}$$と打率$${p}$$からなる二項分布に従うと仮定し、$${H \sim Bin(AB, p)}$$ を尤度として考えます。
真の打率が 0.25, 0.5 の場合の player1 の尤度を考えてみましょう。真の打率が 0.25 のとき 10 打席中 2 安打する確率と、真の打率が 0.5 のとき 10 打席中 2 安打する確率は以下のようになります。

各々の打率が与えられたとき、今のデータがどれだけ起こりやすいか表した指標と考えることができますね。
■ [R] rstanで事前分布と尤度を定義する
さて、事前分布と尤度が以下のように定義できました。これを元にrstanを書いていきたいと思います。
$$
\begin{align*}
\textbf{\small 事前分布} &: \, p \sim Beta(2, 6) \\[5pt]
\textbf{\small 尤度} &: \, H \sim Bin(AB, p)
\end{align*}
$$
今回は player1 の1人分のデータを用いて rstan で打率の推定を行います。まずは rstan パッケージを読み込みます。
library(rstan)
options(mc.cores = parallel::detectCores())
rstan_options(auto_write = TRUE)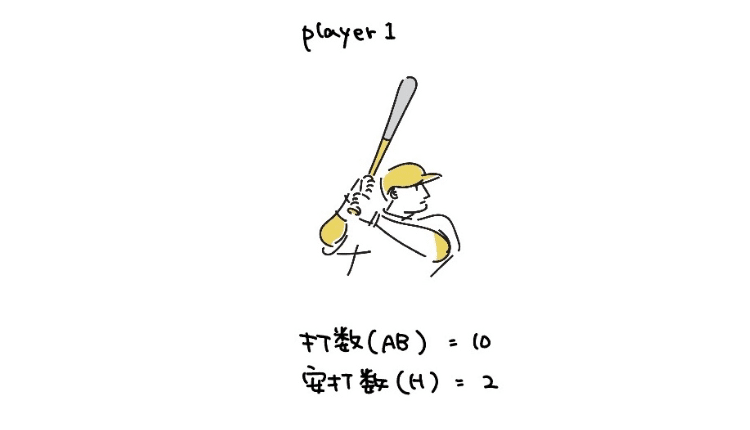
10 打席中 2 安打した人なので、$${AB = 10}$$, $${H = 2}$$をリストとして渡します。また、事前分布のパラメーター$${α_{pre}}$$, $${β_{pre}}$$も一緒に定義しておきます。
# AB: 打席数
# H: 安打数
# alpha_pre: 事前分布(ベータ分布)の α パラメータ
# beta_pre: 事前分布(ベータ分布)の β パラメータ
dat <- list(AB = 10, H = 2, alpha_pre = 2, beta_pre = 6)次にstanコードを記述していきます。今回のstanコードは以下の3ブロックから構成されます。
dataブロック: 外部から受け取るデータ(datの内容)を記述
parametersブロック: 推定するパラメータ(打率$${p}$$)を記述
modelブロック: 事前分布、尤度を記述
stancode <- "
data {
int<lower=0> AB;
int<lower=0> H;
real<lower=0> alpha_pre;
real<lower=0> beta_pre;
}
parameters {
// 事後分布を得たいパラメータ (打率p)
real<lower=0,upper=1> p;
}
model {
// 打率pの事前分布
p ~ beta(alpha_pre, beta_pre);
// 安打数Hにより打率pの尤度を算出する
H ~ binomial(AB, p);
}
"② 事前分布を事後分布へ更新する
事前分布を$${Beta(2,6)}$$と定義したので、ここから実際に選手の安打数・打席数のデータを用いて事前分布を事後分布に更新(ベイズ更新)したいと思います。イメージとしては以下のように選手のデータによって事前分布が更新されます。

打率$${p}$$に$${Beta(2, 6)}$$という事前分布を敷いていました。このベータ分布のパラメータを打席数・安打数のデータからベイズ更新し、その事後分布の平均値(EAP推定量)を打率$${p}$$の推定量とします。
■ ベイズ更新とは
ではどのように事前分布が事後分布に更新されるか見ていきます。
ベイズ更新とは、ベイズルールに則りデータから事前分布を事後分布に更新することです。以下のように事後分布が得られます。

では今回の事前分布と尤度からベイズ更新をしてみましょう。打者 1 人あたりの事前分布と尤度をそれぞれ以下のように置いていました。
$$
\begin{align*}
\textbf{\small 事前分布} &: \, p \sim Beta(2, 6) \\[5pt]
\textbf{\small 尤度} &: \, H \sim Bin(AB, p)
\end{align*}
$$
事前分布と尤度をかけて、それぞれの確率密度関数の$${p}$$に関係するところのみ残すと以下のようになります。
$$
\begin{align*}
\text{事後分布} &\propto \frac{p^{α_{pre}-1}(1-p)^{β_{pre}-1}}{B(α_{pre},β_{pre})} \times {}_{AB} C_{H} \, p^{H} \, (1-p)^{AB-H} \\[15pt]
&\propto p^{α_{pre}-1}(1-p)^{β_{pre}-1} \times p^{H} \, (1-p)^{AB-H}
\end{align*}
$$
つまり今回だと以下のように、打率平均が0.25になるベータ分布$${Beta(2,6)}$$だと考えていた事前分布が実際の選手のデータによって更新されます。

もう少し踏み込んで、試しに打率$${p}$$が 0.25 と 0.5 であるときに選手1 のデータ(打席数$${AB=10}$$, 安打数$${H=2}$$)で更新すると具体的にどのような値になるのか事前分布と尤度の積を計算してみましょう。

$${p=0.25}$$, $${p=0.5}$$の場合の事前分布と尤度の積を計算しました。事前分布・尤度の計算結果をそれぞれ個別に見比べても、この3つだと$${p=0.25}$$の方が正しそうに見えますね。

グラフに落とすとこのようなイメージになります。例えば上の図は事前分布の$${p=0.25, 0.5}$$地点の信念を、真の打率pが0.25, 0.5だったとき 10 打席中 2 安打になる確率で更新した結果を表しています。事前分布をデータで更新するという感覚が少しでも伝わると幸いです。
では実際更新された分布での打率$${p}$$の平均値(EAP推定量)はどうなるのか、この後求めてみましょう。
③パラメータの推定量を求める
事後分布が求められたら マルコフ連鎖モンテカルロ(MCMC)法 で乱数生成を行います。乱数生成を行うことで事後分布に従い、起こりやすさに応じた乱数を得ることができます。そこで得た乱数から今回の場合は平均をとることでパラメータ(打率$${p}$$)のEAP推定量を得ることになります。
今回は事後分布のから得た乱数の平均値を撮るEAP推定量を採用しますが、最頻値(MAP推定量)や中央値を推定量にする場合もあります。
■ [R] rstanで推定量を求める
stan関数に先ほどのstanコードと、dataブロックに渡す1人分のデータを設定し実行します。
fit <- stan(model_code = stancode, data = dat)
print(fit)
打率$${p}$$のEAP推定量として平均0.22、標準偏差0.10という値が得られました。本来 trace plot などで MCMC が収束しているか確認が必要ですが、今回は割愛します。

つまり、事前知識を表現していた事前分布として$${Beta(2, 6)}$$という$${p}$$の平均が 0.25 になる分布を敷いていましたが、選手のデータ(10 打席中 2 安打)でベイズ更新することによって、事後分布での平均が 0.22 へと更新されたということになります。0.25 から 0.22 へ下方修正されることは選手のデータから見ると自然です。
ここまでがMCMCを用いたベイズ推定の一連の流れです。rstanコードが散らばってしまったのでこちらのgistにまとめて置いておきますね。
ここからは、「実は今回の事前分布と尤度の組み合わせは特別なもので、実は手計算でも$${p}$$の推定量を求められる」というお話をしようかと思います。
③別解: 共役事前分布を用いて手計算でパラメータの推定量を求める
先程 MCMC での乱数生成でパラメータの推定量を求めました。しかし今回打率を推定するために用いた分布は「共役事前分布」と呼ばれ、事前分布と事後分布が同じ分布になることが知られています。
$$
\begin{align*}
\text{事後分布} &\propto \frac{p^{α_{pre}-1}(1-p)^{β_{pre}-1}}{B(α_{pre},β_{pre})} \times {}_{AB} C_{H} \, p^{H} \, (1-p)^{AB-H} \\[15pt]
&\propto p^{α_{pre}+H-1}(1-p)^{β_{pre}+AB-H-1}
\end{align*}
$$
$${p}$$に関係する部分以外は定数と考えて、事前分布と尤度の積から打率$${p}$$に関わる部分のみ計算すると事後分布は $${p^{α_{pre}+H-1}(1-p)^{β_{pre}+AB-H-1}}$$、つまり$${Beta(α_{post}, β_{post}) = Beta(α_{pre}+H, β_{pre}+(AB - H))}$$に比例して従っていることがわかります。ベータ分布は理論的によく知られた分布なので手計算でも打率$${p}$$のEAP推定量を求めることができます。
rstan 同様 player1 の打率について考えてみましょう。事前分布は$${p \sim Beta(2, 6)}$$ ($${α_{pre}=2, β_{pre}=6}$$) でしたね。これを安打数$${H = 2}$$と打席数$${AB=10}$$で更新すると以下のようになります。
$$
\begin{align*}&α_{post} = α_{pre} + H = 2 + 2 = 4\\[5pt]
&β_{post} = β_{pre} + (AB - H) = 6 + (10-2) = 14\end{align*}
$$
打率$${p}$$の事後分布として$${Beta(4, 14)}$$が得られました。ここから$${p}$$の期待値と分散を求めてみます。
$$
\begin{align*} &E[p] = \frac{α_{post}}{α_{post} + β_{post}} = 0.222…\\[10pt]
&V[p] = \frac{α_{post}β_{post}}{(α_{post} + β_{post})^2(α_{post} + β_{post} + 1)} = 0.009… \end{align*}
$$
player1 の打率$${p}$$の推定量として平均が0.22…、分散が0.009… (標準偏差が0.12…) という結果が得られました。rstan で求めた打率$${p}$$の推定量ともほぼ一致しています!やったあ 🙌

まとめると、事前分布であるベータ分布と尤度である二項分布の組み合わせは共役事前分布と呼ばれ、事後分布は事前分布と同様のベータ分布になることがわかっています。そのため手計算で打率$${p}$$の推定量を簡単に求めることができました。
今回のベータ分布と二項分布の組み合わせ以外にも共役事前分布として知られているものがいくつかあります。緑本などでも紹介されているので気になったら読んでみてください 😊
最後に
今回はベイズ推定について、MCMCを用いる方法と共役事前分布を用いて推定量を手計算する方法の2通りを試しました。
ベイズ推定は今までしっかり触れたことがなく理解が難しいところも多々ありましたが、自分の事前知識を反映できたりと使いこなせたら柔軟性もあってよさそうだな感じました。次回はもう少し踏み込んで階層ベイズも挑戦できればなと思います。
おまけ
ベイズ推定も初心者ですが野球も初心者なので、野球の例を考えてるうちに実際に試合を見てみたくなり、神宮球場まで観戦してきました。富士山に登った翌日で身体はボロボロでしたが、それも吹き飛ぶくらいとってもおもしろかったです!

野球グランドのサイズって場所によって違うんですね。教えてもらうまで全然気づかなかった。
参考文献
Special Thanks
勉強中や記事を書く際にたくさんアドバイスいただきました。いつもありがとうございます 🐥
utaka233、masaru3n
この記事が参加している募集
統計の本、もしくはわんこにおいしいお菓子を買うのに使わせていただきます( *ˆoˆ* )