
Pythonを使って2019年度J1チームデータを可視化してみた

下記の記事を読んだら、今年度のJリーグデータを可視化したくなったので、初歩的なPandas、Matplotlib、Seabornを使って、Jリーグのデータを可視化してみました
僕は今シーズンからDAZNにも加入し、毎週欠かさずサガン鳥栖とヴィッセル神戸の試合を観戦しています。
基本的なデータを可視化してみて面白そうなチームがあったら、そのチームの試合も観戦したいですね。
それに、簡単なデータを頭に入れて試合を見ることで、観戦がより面白くなると思います。
==============
まずはJリーグデータの取得からです。Jリーグは基本的なデータを公式サイトに掲載しています。ただ、CSVファイルなどでダウンロードできないので、Web Scrapingを使ってデータを取得しました。
上記のブログでも使用していたread_html()を使用して、Jリーグの順位表のデータをスクレイピング。
Web Scraping
*コードはJupyter notebookの処理をまとめたものです。
*read_html()を使用するためには、lxmlかbeautifulsoup4のどちらかをインストールしてください。
pip install lxml
pip install beautifulsoup4 html5lib
*データはリーグ戦(第8節)までを使用しており、カップ戦などは含んでいません。
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from adjustText import adjust_text
%matplotlib inline
sns.set_style('whitegrid')
matplotlib.rc('font', family="IPAexGothic")
# データ取得
url_ranking = 'https://data.j-league.or.jp/SFRT01/?search=search&yearId=2019&yearIdLabel=2019%E5%B9%B4&competitionId=460&competitionIdLabel=%E6%98%8E%E6%B2%BB%E5%AE%89%E7%94%B0%E7%94%9F%E5%91%BD%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&competitionSectionId=0&competitionSectionIdLabel=%E6%9C%80%E6%96%B0%E7%AF%80&homeAwayFlg=3'
j_ranking = pd.read_html(url_ranking)
# データフレームに変換
j_ranking = pd.DataFrame(j_ranking[0])
# 不必要なカラムを削除
j_ranking.drop(['グラフ','直近試合の勝敗','Unnamed: 12','Unnamed: 13'], axis=1)
Jリーグのデータはきれいにまとまっているので、data cleaningがほとんど必要ないですね。
Jupyter notebookに表示されたランキングが下記になります。
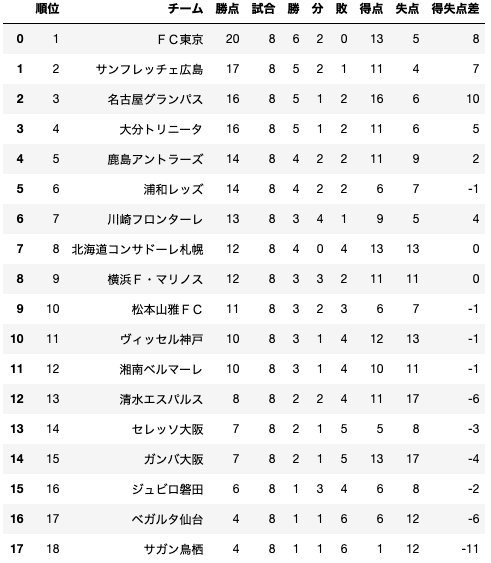
8節を消化した時点では、まだまだ混戦模様ですね。昇格組の大分が好調で、川崎、鹿島は上位につけてはいるものの、まだエンジンがかかってないですね。大型補強の神戸は中位に沈んでいます。広島、名古屋は昨年のように前半戦好調です。
次により詳細なデータをグラフ化していきます。より詳細な情報が必要なので、2019年度のチーム別集計結果をスクレイピング。
# データ取得
url_ranking = 'https://data.j-league.or.jp/SFRT01/?search=search&yearId=2019&yearIdLabel=2019%E5%B9%B4&competitionId=460&competitionIdLabel=%E6%98%8E%E6%B2%BB%E5%AE%89%E7%94%B0%E7%94%9F%E5%91%BD%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&competitionSectionId=0&competitionSectionIdLabel=%E6%9C%80%E6%96%B0%E7%AF%80&homeAwayFlg=3'
j_ranking = pd.read_html(url_ranking)
# データフレームに変換
j_ranking = pd.DataFrame(j_ranking[0])
# indexを指定し不必要な行を削除
j_table.drop(index=18, inplace=True)取得できたデータはこんな感じ。

まずは、各チームの得点数をX軸、とY軸に失点数をプロットしてみましょう。各チームの特徴がよくわかります。
各チームの得点数 vs 失点数
# チーム名、得点数、失点数取得
teams = j_table.loc[:, 'チーム名'].values
x_coords = j_table.loc[:, '得点'].values
y_coords = j_table.loc[:, '失点'].values
plt.figure(figsize=(14, 8))
plt.plot(x_coords, y_coords, 'bo')
plt.title('総得点 vs 総失点', fontsize=22)
plt.xlabel('総得点', fontsize=16)
plt.xticks(fontsize=16)
plt.ylabel('総失点', fontsize=16);
plt.yticks(fontsize=16)
# チーム名のテキストを作成
texts = [plt.text(x_coords[i], y_coords[i], team,fontsize=14) for i, team in enumerate(teams)]
# adjust_textを使用し、テキストの重なりを防ぐ
adjust_text(texts);
plt.savefig('gf_ga.png');

グラフ右下:総得点多く、失点が少ないチームです。
FC東京、名古屋、広島、大分などの上位チームはここに固まっていますね。
昨年王者の川崎は得点が上位チームより少ないです、得点力アップが上位進出には必要ですね。
グラフ右上:総得点は多いが、失点が多いチームになります。現在、下位に沈んでいるチームのガンバ大阪や清水が失点数が1番多いですね。
イニエスタ擁する神戸も失点数が多いです。
鹿島は昌子が抜けた穴が大きいのか、上位陣に比べると失点が多いです。
ガンバ大阪 VSヴィッセルのように、右上に属するチーム同士の対戦は打ち合いの試合になること多そうですね。
グラフ左上:総得点が少なく、失点が多いチーム。
サガン鳥栖とベガルタ仙台の降格圏のチームがここに属します。僕が応援しているサガン鳥栖の危機的な状況がわかりますね。
グラフ左下:総得点、失点ともに少ないチーム。
ここで注目すべき浦和ですね。現在、6位につけており、失点数は少ないが得点も少ない。非常に堅実な勝ち方が特徴的ですね。
各チームのシュート数とゴール数
各チームのシュート数と得点数をグラフにしてみました。
f, ax = plt.subplots(figsize=(14, 8))
# シュート数で表示順番を変更
j_table = j_table.sort_values(['シュート'],ascending=False ).reset_index(drop=True)
# シュート数のPlot作成
sns.set_color_codes("pastel")
sns.barplot(x="シュート", y="チーム名", data=j_table,
label="シュート数", color="b")
# 得点数のプロット作成
sns.set_color_codes("muted")
sns.barplot(x="得点", y="チーム名", data=j_table,
label="得点", color="b")
# タイトルなどの設定
ax.legend(ncol=2, loc="lower right", frameon=True, fontsize=16)
ax.set(xlim=(0, 140),ylabel="チーム",
xlabel="シュート数")
sns.despine(left=True, bottom=True)
plt.title('シュート数と得点数', fontsize=22)
plt.xlabel('シュート数と得点数', fontsize=16)
plt.ylabel('チーム名', fontsize=16);
plt.xticks(fontsize=16);
plt.yticks(fontsize=16);
plt.savefig('num_g_s.png',bbox_inches = 'tight');
シュート数と得点数をのグラフを見てみるとよく分かるんですが、シュート数が多いから得点数が多いわけでもないですし、上位にいるわけでもないんですね。
それを象徴しているのが、現在4位につけている大分トリニータです。
シュート数は最下位に沈む鳥栖と同じだけど、得点数と勝ち点で圧倒しています。
FC東京やサンフレッチェの上位陣もシュート数は多いほうではありませんが、得点数が多いですね。
各チームのゴール率
次に得点数を総シュート数で割ったゴール率を見てみます。シュートがどのくらいの確率でゴールにつなるかを視覚化しました。
# ゴール率カラムをデータフレームに作成
j_table['ゴール率'] = j_table['得点'] / j_table['シュート']
# ゴール率で表示順番をソート
j_table = j_table.sort_values(by='ゴール率')
# 表示チーム数のレンジを取得
my_range=range(1,len(j_table.index)+1)
# 表示設定
my_color=np.where(j_table['チーム名']=='大分トリニータ', 'orange', 'skyblue')
my_size=np.where(j_table['チーム名']=='大分トリニータ', 70, 30)
plt.figure(figsize=(14, 8))
plt.hlines(y=my_range, xmin=0, xmax=j_table['ゴール率'] , color= my_color,)
plt.scatter(j_table['ゴール率'], my_range, color=my_color, s=my_size, alpha=1)
plt.title("ゴール率(ゴール数/シュート数)", loc='center',fontsize=22)
plt.xticks(fontsize=16)
plt.yticks(my_range, j_table['チーム名'],fontsize=16)
plt.xlabel('ゴール率(ゴール数/シュート数)',fontsize=16)
plt.ylabel('チーム',fontsize=16);
plt.savefig('prop_g.png', bbox_inches = 'tight');

現在上位を走ってるチームのゴール率は高いですね。大分トリニータは放ったシュートの約2割以上がゴールになっています。効率的な点の取り方をしてますね。
FC東京や、サンフレッチェも高い数値です。
残念なのは、ガンバ大阪ですね。数値的には上位チームと遜色が無いのに、守備がボロボロのため下位に沈んでいます。
各チームの被シュート数と被ゴール数
f, ax = plt.subplots(figsize=(14, 8))
# 被シュート数で表示順番を変更
j_table = j_table.sort_values(['被シュート'],ascending=False ).reset_index(drop=True)
# 得点数のプロット作成
sns.set_color_codes("pastel")
sns.barplot(x="被シュート", y="チーム名", data=j_table,
label="被シュート数", color="b")
# タイトルなどの設定
sns.set_color_codes("muted")
sns.barplot(x="失点", y="チーム名", data=j_table,
label="失点", color="b")
ax.legend(ncol=2, loc='lower right', borderaxespad=0,fontsize=16)
ax.set(xlim=(0, 120))
sns.despine(left=True, bottom=True)
plt.title('被シュート数と失点数', fontsize=22)
plt.xlabel('被シュート数と失点数', fontsize=16)
plt.ylabel('チーム名', fontsize=16);
plt.xticks(fontsize=16);
plt.yticks(fontsize=16);
plt.savefig('num_g_s_a.png',bbox_inches = 'tight');
被シュート数が多いガンバ大阪、清水、札幌ほど、失点数が多いのが顕著ですね。
逆も然りで、FC東京、広島、川崎など失点が少ないチームはシュートも多く打たれていないです。
川崎フロンターレは守備は安定しているので、ゴール数が増えれば上位争いに食い込めそうです。
各チームの被ゴール率
次に失点数を被シュート数で割ったゴール率を見てみます。相手チームのシュートがどのくらいの確率でゴールにつながるかを、ゴール率と同じように視覚化しました。
# 被ゴール率カラムをデータフレームに作成
j_table['被ゴール率'] = j_table['失点'] / j_table['被シュート']
# 被ゴール率で表示順番をソート
j_table = j_table.sort_values(by='被ゴール率')
my_range=range(1,len(j_table.index)+1)
# 表示設定
my_color=np.where(j_table['チーム名']=='大分トリニータ', 'orange', 'skyblue')
my_size=np.where(j_table['チーム名']=='大分トリニータ', 70, 30)
plt.figure(figsize=(14, 8))
plt.hlines(y=my_range, xmin=0, xmax=j_table['被ゴール率'] , color= my_color,)
plt.scatter(j_table['被ゴール率'], my_range, color=my_color, s=my_size, alpha=1)
plt.yticks(my_range, j_table['チーム名'])
plt.title("被ゴール率(失点/被シュート数)", loc='center',fontsize=22)
plt.xlabel('被ゴール率(失点/被シュート数)',fontsize=16)
plt.ylabel('チーム',fontsize=16);
plt.xticks(fontsize=16)
plt.yticks(fontsize=16);
plt.savefig('prop_g_a.png', bbox_inches = 'tight');

ゴール率でも大分トリニータが一番良い数値を出していましたが、被ゴール率が1番低いのも大分ですね。
昇格組の大分が目立っています。
大分は被シュート数は中位につけていますが、打たれたシュートがゴールにつながっていないようです。相手に良い形でシュートを打たせてないのかもしれません。
広島、東京の上位のチームはシュートまで持っていかれる回数が少ないことが、ゴール率の低さにつながっていますね。
相関関係
シュート数と得点数、被シュート数と失点数の相関関係を見てみましょう。
plt.figure(figsize=(14, 8))
# regplotでデータとlinear regression model fitを表示
sns.regplot(data = j_table, x = 'シュート', y = '得点');
# 表示設定
plt.title('シュート数 vs 得点数', fontsize=22)
plt.xlabel('シュート数', fontsize=16)
plt.ylabel('得点', fontsize=16);
plt.xticks(fontsize=16)
plt.yticks(fontsize=16);
plt.savefig('corr_s.png');
シュート数と得点の相関係数は約0.57と正の相関があり、下記の被シュート数と失点数は、約0.82と強い正の相関がありました。
plt.figure(figsize=(14, 8))
# regplotでデータとlinear regression model fitを表示
sns.regplot(data = j_table, x = '被シュート', y = '失点');
# 表示設定
plt.title('被シュート数 vs 失点数', fontsize=22)
plt.xlabel('被シュート数', fontsize=16)
plt.ylabel('失点', fontsize=16);
plt.xticks(fontsize=16)
plt.yticks(fontsize=16);
plt.savefig('corr_s_a.png');
シュート数と得点数
最後に得点ランキング上位者の成績を可視化してみました。
# データ取得
url_score ='https://data.j-league.or.jp/SFRT09/search?yearFlag=false&competition_id=1&sub_competition_id=§ion_id=0&number=&competition_year_id=2019&competition_year=2019%E5%B9%B4&competitionName=%E6%98%8E%E6%B2%BB%E5%AE%89%E7%94%B0%E7%94%9F%E5%91%BD%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&sub_competition=§ionName=%E6%9C%80%E6%96%B0%E7%AF%80§ion_id=0&sub_error_flag=&sub_competition_flag=1'
j_score = pd.read_html(url_score)
# データフレームに変換
j_score = pd.DataFrame(j_score[0])取得したデータ抜粋。

得点者数は数が多いため、4点以上を取ってるランキング上位者のみにフィルター。
# 4点以上取得してるプレイヤーのみに絞る
j_score_sub = j_score[j_score['得点'] >= 4]まずは、上位者のシュート数と得点数を視覚化してみましょう。
# シュート数でソート
j_score_sub =j_score_sub.sort_values(by='シュート',ascending=False)
# x軸のポジションと、バーの幅を設定
ind = np.arange(len(j_score_sub['シュート']))
width = 0.35
fig, ax = plt.subplots(figsize=(14,8))
# シュート数のバー作成
rects1 = ax.bar(ind - width/2, j_score_sub['シュート'], width,
color='SkyBlue', label='シュート')
# 得点数のバー作成
rects2 = ax.bar(ind + width/2, j_score_sub['得点'], width,
color='IndianRed', label='得点')
# テキストやラベルなどの設定
def autolabel(rects, xpos='center'):
"""
シュート数、得点数のテキストをバーの上に表示
"""
xpos = xpos.lower()
ha = {'center': 'center', 'right': 'center', 'left': 'center'}
offset = {'center': 0.5, 'right': 0.57, 'left': 0.43} # x_txt = x + w*off
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()*offset[xpos], 1.01*height,
'{}'.format(height), ha=ha[xpos], fontsize=12,va='bottom')
autolabel(rects1, "left")
autolabel(rects2, "right")
# テキストやラベルなどの設定
ax.set_xticks(ind)
ax.set_xticklabels( j_score_sub['選手名'])
ax.legend(ncol=2, borderaxespad=0,fontsize=16)
plt.title('シュート数、ゴール数カウント (得点ランキング上位者)', fontsize=22)
plt.xlabel('得点ランキング上位者', fontsize=16)
plt.ylabel('カウント', fontsize=16);
plt.xticks(fontsize=12,rotation = -90);
plt.yticks(fontsize=12);
plt.savefig('count_s_g.png', bbox_inches = 'tight');
plt.show()

札幌のロペス選手、FC東京のオリヴェイラ選手、大分の藤本選手が得点6でランキングのトップを走っていますね。
ロペス選手のシュート数は40近くで札幌の総シュート数が約100なので、チームの40%のシュートを打っています。
札幌の試合見たことないからわかりませんが、ボールをロペス選手に集める戦術なのか、ロペス選手がシュートをかなり積極的に打つタイプなのか、札幌の試合で見てみたいです。
藤本選手、オリヴェイラ選手はシュート数が少ないながら6ゴールを上げており、決定率の高さが伺えます。
シュート決定率
ゴール数をシュート数で割った、シュート決定率を見てみましょう。

大分の藤本選手はシュートの4割がゴールになっており、非常に高い決定率を誇っていますね。
大分は他のチームよりシュート数が少ないので、藤本選手が少ないチャンスをものにしているようです。昇格組の大分の好調ぶりは高い決定率を持つ、藤本選手の働きが大きいですね。
各チームのゴール人数
各チームのゴールを決めたプレイヤーが何人いるかを見てみます。
# 得点を決めている選手が多い順で、チーム名取得
score_counts = j_score['現所属(J最終所属)'].value_counts().index
plt.figure(figsize=(14, 8))
base_color = sns.color_palette()[0]
# countplotで各チームの得点者数を獲得。表示順番を得点者数が多い順にする。
sns.countplot(data = j_score, y = '現所属(J最終所属)',color=base_color, order=score_counts);
# 表示設定
plt.title('各チーム得点者数', fontsize=22)
plt.xlabel('得点者数', fontsize=16)
plt.ylabel('チーム', fontsize=16);
plt.xticks(fontsize=16)
plt.yticks(fontsize=16);
plt.savefig('count_p_g.png', bbox_inches = 'tight');
上位を走る名古屋とサンフレッチェには、これまで7名の得点したプレーヤーがいますね。
名古屋からはストライカーのジョー選手がランキング入りしていますが、他の選手たちも点と取っており、総得点16点でJ1トップにたっています。
対して広島は、ランキングに顔を出す選手は出てきてないけど、多くの選手がスコアーを重ねています。総得点が11点と名古屋とは差がありますが、失点数4という堅守で上位に食い込んでいますね。
昨年王者の川崎は知念選手がランキングに入っているが、得点者数は4人のみで、ゴールを決めてほしい小林選手、レアンドロ・ダミアン選手が、まだあまり点を取れてないことが勝ちきれてない大きな要因そうです。
川崎の守備は硬いだけに、この二人が点数をとりはじめたら川崎は順位をあげてきそうです。
終わり
Jリーグ公式サイトにまだまだデータがあるので、もっと詳細なデータ分析や可視化ができそうです。
各チームのスプリント量や、ポゼッション率、パス数、パス成功率、プレヤーのプレー位置、アシスト数、ゴールの際に右足、左足、頭のどの部位を使ってゴールを決めてるかなど、色々みてみたい。
過去5年分の様々なデータを比較してみても面白そうです。
初歩的なPandas、Matplotlib、Seabornを使って、Jリーグのデータを可視化してみました。
スポーツ記事とか読んでなんとなくわかってることや、数値だけでは入ってこない情報が、可視化することで明確になるんですよね。
興味あるデータがあったら、Pythonを使って可視化していってみたいです。
この記事が気に入ったらサポートをしてみませんか?