

2023年4月の記事一覧

vicuna-13bで embedding vectorの計算 (& GPT・RWKVとの比較)
背景
背景はこちらの記事と同じです
最近は、GPTが流行ってます
しかしGPT-3.5以降はfine tuningが執筆時点でできません
なので、オリジナルデータを学習させるには、少し工夫が必要です
要するに、文章のembedding vectorを計算する必要があります
しかし、GPTのAPIは地味に値段が高いため、pdfが100個くらいあったりすると、破産する恐れが出てきます
目


大規模言語モデル間の性能比較まとめ
StableLMのファインチューニングってできるのかな?と調べたところ、GitHubのIssueで「モデル自体の性能がまだ良くないから、ファインチューニングの段階ではないよ」というコメントがありまして。
その根拠として提示されていた大規模言語モデル間の性能比較シートがとても参考になったので共有したいと思います。
シートの中身を見てみるstablelm-base-alpha-7bは54行目にあり




Google Colab で Cerebras-GPT を試す
「Google Colab」で「Cerebras-GPT」を試したので、まとめました。
1. Cerebras-GPT「Cerebras-GPT」は、OpenAIのGPT-3をベースにChinchilla方式で学習したモデルになります。学習時間が短く、学習コストが低く、消費電力が少ないのが特徴とのことです。
2. Colabでの実行Google Colabでの実行手順は、次のとおりです。
(
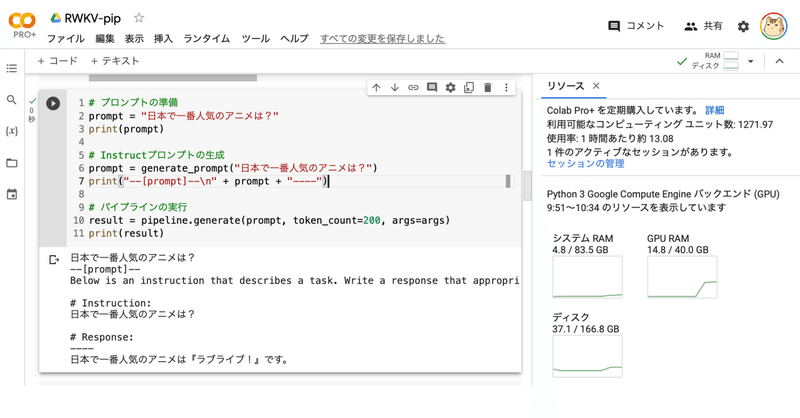

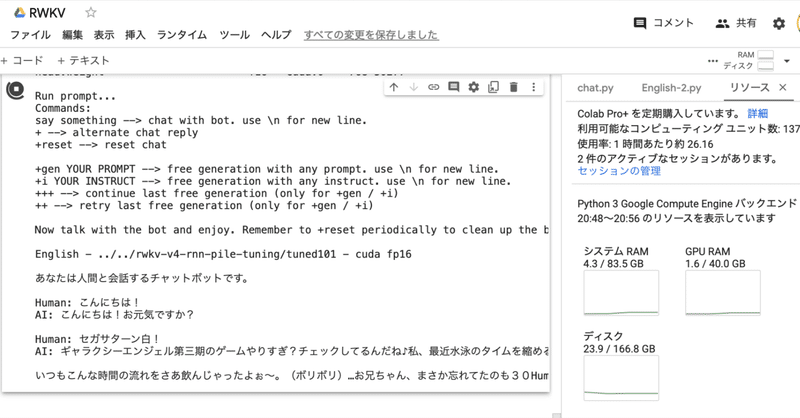
Google Colab で RWKV のファインチューニングを試す
「Google Colab」で「RWKV」のファインチューニングを試したので、まとめました。
前回1. RWKV「RWKV」は、TransformerレベルのLLM性能を備えたRNNです。高性能、高速推論、VRAMの節約、高速学習、長い文脈長、自由な埋め込みを実現しています。
2. データセットの準備今回は、練習用に「あかねと〜くデータセット」の「dataset.txt」を使います。
テキス



フリーの13Bモデル Cerebras-GPT-13BとGPT4-x-Alpacaをローカルで試す
四月に入って、エイプリルフールのネタをHuggingFaceでやるという不届き者も現れたが、いくつか本物のニュースが混じっているから気が抜けない。
Cerebras-GPTは、完全にフリーのGPTモデルを標榜している。
ドスパラ製Memeplexマシン(A6000x2,256GBRAM,20TBHDD)で実際にこの大規模言語モデルをダウンロードして試してみた。
まずは1.3Bモデル
>>>
Alpacaデータセットの日本語版を公開しました
今後ファインチューニングなどで使いたい人がいると思うので自腹で自動翻訳したデータセットを公開します。alpaca_cleanedは現在作業中です